DeepSeek V4 vs GPT-5.5,我感觉我这篇写的还行~ 理完之后,我更期望昇腾超节点搞快点了!!

DeepSeek V4 vs GPT-5.5,我感觉我这篇写的还行~ 理完之后,我更期望昇腾超节点搞快点了!!

做棵大树
发布于 2026-05-06 10:15:20
发布于 2026-05-06 10:15:20
蹭个 deepseekv4 和 gpt 的热点
2026年4月24日,AI圈彻底炸了!
就在OpenAI凌晨刚扔出GPT-5.5的几个小时后,DeepSeek这边也官宣了——V4预览版正式上线,并且同步开源。两款重磅模型"撞车"发布,直接把话题推向了高潮。
一边是OpenAI憋的大招,号称“自GPT-4.5以来首个完全重训练的基础模型”;
另一边是DeepSeek的 “源神归位”,1.6万亿参数的MoE架构开源巨无霸,百万Token上下文直接成标配。
这俩到底谁更强?架构有什么区别?普通人/开发者该怎么选?价格差多少?今天这篇文章,尽量用大白话给大家讲清楚。
一、先搞清楚这俩“选手”的基本面
DeepSeek V4:开源界的“参数怪兽”
DeepSeek这次不是发一个模型,而是发了一对:

版本 | 总参数 | 激活参数 | 上下文长度 | 定位 |
|---|---|---|---|---|
V4-Pro | 1.6万亿 | 490亿 | 100万Token | 性能旗舰,对标闭源顶级模型 |
V4-Flash | 2840亿 | 130亿 | 100万Token | 轻量高速,极致性价比 |
这里有个概念要解释一下:“总参数”和“激活参数”。
你可以把 MoE(混合专家) 架构理解成一家大医院,里面有384个科室(专家),但病人来看病时,系统只会智能地挑选其中6个最相关的科室来会诊。1.6万亿总参数就是全院所有医生的知识总和,但490亿激活参数才是真正参与这次诊断的医生数量。
这意味着什么?知识储备极其丰富,但实际看病成本可控。这也是DeepSeek能把价格打下来的核心原因 。
GPT-5.5:闭源界的“智能体特工”
OpenAI这次没公布具体参数规模,但官方强调这是完全推倒重建的模型——不是在前代基础上修修补补,而是从预训练目标到损失函数全部重写,核心设计理念就一个字:Agent(智能体)。
简单说,GPT-5.5的目标不是“更好地聊天”,而是 “更好地替你干活” ——理解复杂目标、调用工具、自我检查、穿越模糊地带,把多步骤任务执行到底。
GPT-5.5也分版本:
- 标准版:面向ChatGPT Plus/Pro用户,API定价输入30输出(每百万Token)
- Pro版:开启并行测试时计算,价格直接飙到输入180输出
二、架构差异:一个“精打细算”,一个“大力出奇迹”
DeepSeek V4的“省钱黑科技”
V4这次在架构上下了血本,核心解决一个问题:百万Token上下文太烧钱了,怎么让它便宜又好用?
他们搞了一套混合注意力机制,名字听起来很唬人——CSA(压缩稀疏注意力)+ HCA(重度压缩注意力)。白话解释:
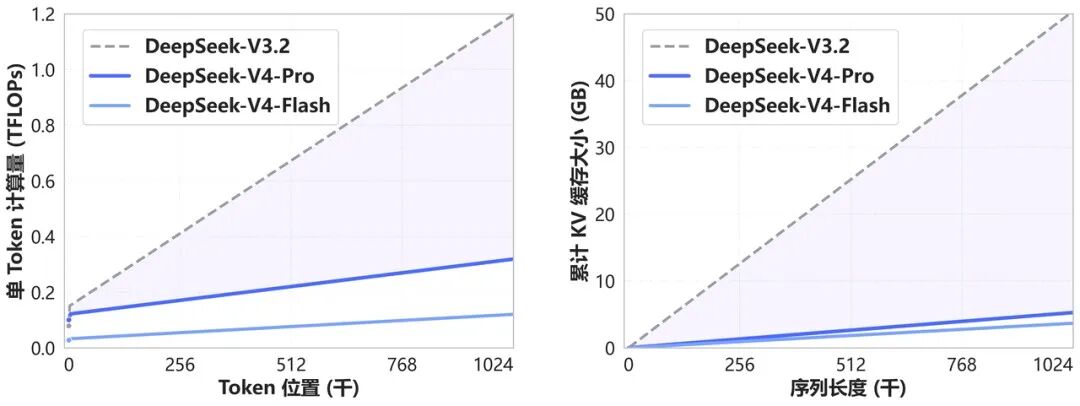
DeepSeek-V4 和 DeepSeek-V3.2 的计算量和显存容量随上下文长度的变化
“以前处理长文本,模型要一个字一个字地“回头看”,上下文越长,回头看的工作量呈指数级爆炸。DeepSeek的做法是:先把长文本"压缩成摘要",再让模型看摘要,而不是看全文。 ”
效果有多夸张?在100万Token的上下文下:
- V4-Pro的计算量仅为前代V3.2的27%
- KV缓存(显存占用)仅为V3.2的10%
- V4-Flash更狠,计算量仅10%,缓存仅7%
换句话说,以前处理100万字可能要烧100块钱,现在只要27块甚至10块。这就是DeepSeek敢把"百万上下文"作为所有官方服务标配的底气。
另外,V4还引入了 mHC(流形约束超连接) 来强化残差连接,以及 Muon优化器 来提升训练稳定性。这些技术细节太硬核,普通用户不用深究,知道它们让模“更深更稳”就行 。
GPT-5.5的“全模态统一”
GPT-5.5的架构关键词是Omnimodal(全模态)。这是OpenAI第一个真正统一处理文本、图像、音频、视频的模型——不是像之前那样“一个主模型+几个外挂适配器”,而是所有模态共享同一套参数池。
这意味着你可以扔给它一段代码截图、一段语音指令、一个视频演示,它能跨模态理解并关联推理。比如:“这段视频里的UI动效,用React怎么实现?”
此外,GPT-5.5采用强化学习驱动的内部思维链——模型在给出答案前,会先“内心独白”一番,尝试不同策略、识别错误并调整。Pro版甚至支持并行测试时计算,同时探索多条推理路径,选最优解 。
三、性能PK:谁才是真正的“六边形战士”?
由于两款模型同日发布,第三方独立横评尚未出炉,以下数据均来自官方发布或权威媒体整理 :
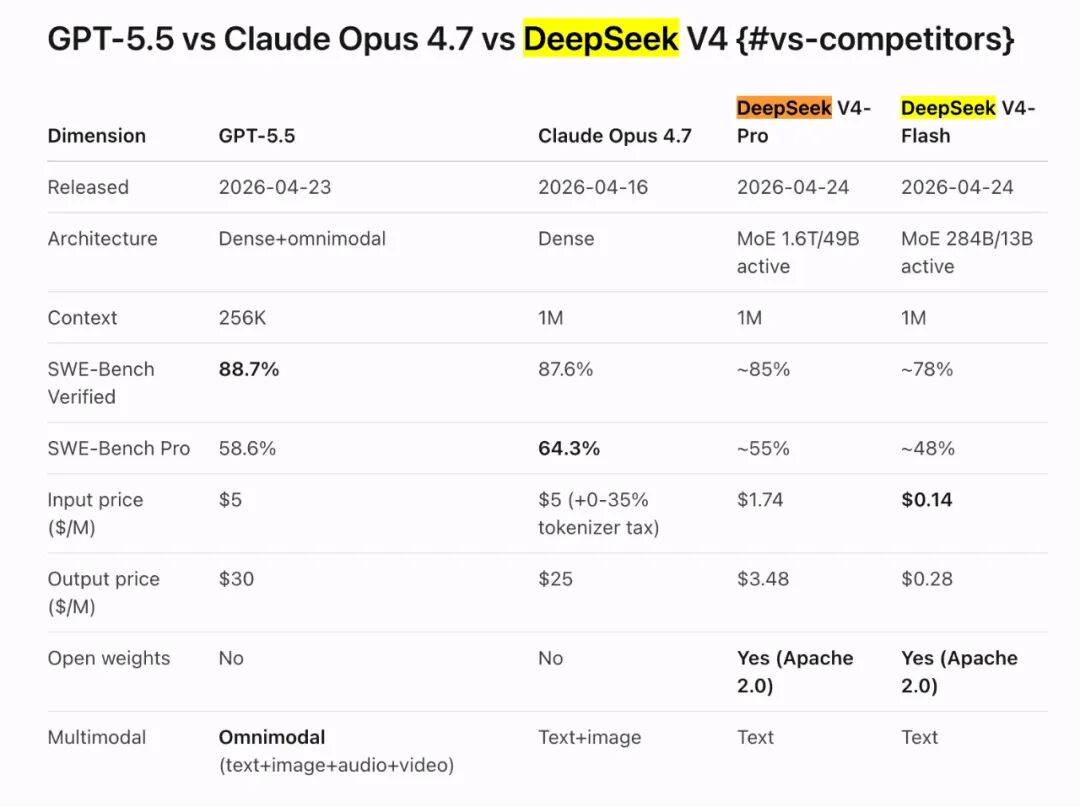
编程能力:各有千秋
基准测试 | DeepSeek V4-Pro | GPT-5.5 | 说明 |
|---|---|---|---|
SWE-Bench Verified | ~85% | 88.7% | 解决真实GitHub Issue的能力,GPT-5.5略胜 |
SWE-Bench Pro | ~55% | 58.6% | 更难版本,Claude Opus 4.7以64.3%领跑 |
Terminal-Bench 2.0 | 67.9% | 82.7% | 复杂命令行工作流,GPT-5.5优势明显 |
Codeforces Rating | 3206 | 未公布 | 竞赛编程,V4-Pro登顶 |
LiveCodeBench | 93.5% | 未公布 | 实时编程挑战,V4-Pro领先 |
白话解读:写算法竞赛题,DeepSeek V4很强;处理复杂的工程化任务(多文件协作、工具链调用),GPT-5.5更稳。
知识推理:互有胜负
基准测试 | DeepSeek V4-Pro | GPT-5.5 | 说明 |
|---|---|---|---|
MMLU-Pro | 87.5% | 92.4% | 综合知识,GPT-5.5领先 |
GPQA Diamond | 90.1% | 93.6% | 研究生级别科学问答,GPT-5.5胜 |
AIME 2026 | ~94% | 未公布 | 数学竞赛,V4-Pro接近顶尖 |
Chinese-SimpleQA | 84.4% | 未公布 | 中文知识问答,V4-Pro领先 |
白话解读:通用知识储备GPT-5.5更全面;但中文场景和特定数学推理,DeepSeek V4不虚。
智能体能力:GPT-5.5的“主场”
这是GPT-5.5最引以为傲的维度:
- GDPval(综合工作智能指数):GPT-5.5达84.9%
- OSWorld-Verified(计算机操作):**78.7%**——模型能在真实电脑环境里自主操作
- Tau2-bench Telecom(客服场景):**98%**(无调优直接测试)
- 实测连续自主运行:第三方开发者亲测7小时以上稳定工作
DeepSeek V4在Agentic Coding评测中达到开源最佳水平,官方坦承“交付质量接近Claude Opus 4.6非思考模式,但仍与思考模式存在一定差距” 。
白话解读:如果你需要AI 独立干完一整个项目(比如“帮我搭建一个电商网站,从数据库设计到前端部署”),GPT-5.5更像一个能加班的资深工程师;DeepSeek V4则像一个能力不错但需要偶尔指导的中级工程师。 ps: 大树是基于评测分数举例子,当然,如果任务简单,其实也不会有差距基本
四、上下文窗口:100万 vs 25.6万,不只是数字游戏
模型 | 最大上下文 | 等效处理量 |
|---|---|---|
DeepSeek V4(双版本) | 100万Token | ~800页PDF / 50万行代码 |
GPT-5.5 | 25.6万Token(标准)/ 100万(API未确认) | ~200页PDF / 13万行代码 |
DeepSeek直接把百万上下文作为标配,这不是炫技,而是实打实的工程突破。得益于CSA/HCA的压缩技术,处理百万Token的成本和延迟被压到了可接受范围。
实际影响:
- 整本《三体》第一部:约30万字,V4可以一次性塞进去分析,GPT-5.5得分批处理
- 中等规模项目代码库:约50万行,V4能一次性载入做全局重构,GPT-5.5需要“一段一段看”
- 多轮Agent会话:长对话中V4的优势会越来越明显,不用频繁“失忆”
五、价格对比:这不是差距,是“鸿沟”,我反正更支持 deepseek hh
这是最让人清醒的部分:
模型 | 输入价格($/百万Token) | 输出价格($/百万Token) | 相对GPT-5.5倍数 |
|---|---|---|---|
GPT-5.5 标准版 | $5.00 | $30.00 | 1×(基准) |
GPT-5.5 Pro版 | $30.00 | ~$180.00 | 6× |
DeepSeek V4-Pro | ~$1.74 | ~$3.48 | 0.35× / 0.12× |
DeepSeek V4-Flash | $0.14 | $0.28 | 0.03× / 0.009× |
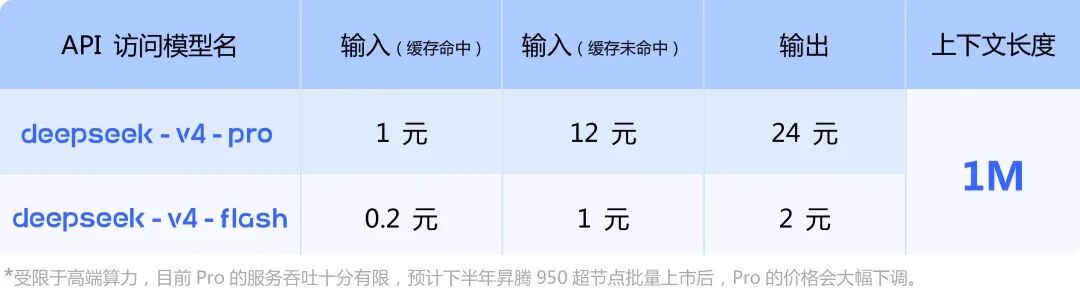
翻译成人话:
- V4-Flash的输入价格仅为GPT-5.5的1/35,输出价格仅为1/107
- 处理同样任务,GPT-5.5花100块,V4-Flash只要3块
- 缓存命中场景下,V4-Flash输入仅需$0.03/百万Token,是GPT-5.5的1/166
有网友算了一笔账:如果Uber用DeepSeek V4代替Claude Opus 4.7,2026年的AI预算可以从撑4个月变成撑7年 。
当然,OpenAI的定价逻辑是 单价高但总成本低 ——GPT-5.5完成同样任务消耗的Token更少,幻觉率降低60%,实际账单可能没数字看起来那么夸张。
但对中小企业和个人开发者来说,V4-Flash的价格几乎是“白送”级别。
而且,官方的贴图还说了 昇腾 950 超节点上市后,pro 的价格会答复下调!!!
六、开源 vs 闭源:这不是技术问题,是“自由”问题
维度 | DeepSeek V4 | GPT-5.5 |
|---|---|---|
开源状态 | ✅ 完整开源(MIT协议,权重+技术报告) | ❌ 完全闭源 |
本地部署 | ✅ 可下载到Hugging Face/ModelScope,自己跑 | ❌ 只能用OpenAI API |
数据隐私 | ✅ 可私有化部署,数据不出境 | ❌ 必须传至OpenAI服务器 |
定制微调 | ✅ 可基于自有数据微调 | ❌ 仅能通过API调用 |
硬件绑定 | 华为昇腾+NVIDIA双支持 | NVIDIA Blackwell深度绑定 |
DeepSeek V4的开源不是 “放个小模型意思一下”,而是1.6万亿参数的旗舰直接开源。这意味着:
- 医院、金融机构可以把模型部署在本地,满足HIPAA/GDPR合规
- 学术团队可以研究模型内部机制、做安全审计
- 创业公司可以基于V4微调出自己的专属模型,不用从零训练
GPT-5.5则走“闭源精品”路线,靠品牌溢价和企业服务赚钱。NVIDIA内部超10000名员工已率先使用,Databricks宣布深度合作 。
七、白话总结:你该怎么选?
选 DeepSeek V4,如果你:
- 预算敏感:Flash版的价格几乎等于免费,Pro版也只有GPT-5.5的1/3
- 需要长文本:要一次性处理整本书、整个代码库、超长合同
- 重视数据隐私:需要本地部署或私有化定制
- 做中文内容:中文知识问答表现优异
- 信仰开源:想要可审计、可修改、不被厂商锁定的AI基础设施
选 GPT-5.5,如果你:
- 追求极致Agent能力:需要AI独立运行数小时完成复杂项目
- 多模态刚需:需要模型同时理解文本、图像、音频、视频
- 企业级合规:已在OpenAI生态内,需要Databricks等企业集成
- 不差钱:愿意为那3-5%的性能提升支付35倍溢价
- 做前沿探索:需要模型协助科学研究(比如GPT-5.5已帮助发现Ramsey Numbers的新证明)
最佳实践:混合路线(成年人全都要)
最理性的方案可能是分层使用:
- 20%的复杂任务(核心代码架构、关键决策)→ GPT-5.5
- 80%的常规任务(文档处理、客服、代码生成)→ DeepSeek V4-Flash
这样既能享受 frontier 质量,又能把成本压到原来的1/10甚至1/50 。
八、最后收个尾:这不是输赢,是两条路
DeepSeek V4和GPT-5.5的同日发布,像极了智能手机早期"安卓 vs iOS"的格局:
- DeepSeek V4是“高配安卓旗舰”:开放、便宜、可折腾、长上下文是杀手锏
- GPT-5.5是 “Pro Max”系列:封闭、贵、省心、Agent体验是护城河
DeepSeek官方很坦诚:V4的能力 “大约滞后前沿闭源模型3到6个月” 。但这不重要——它用架构创新证明了一件事:超长上下文不必靠暴力算力,开源模型也能定义新的游戏规则。
而GPT-5.5则证明了另一件事:当AI从"聊天工具"升级为"自主生产力平台"时,企业愿意为"不用全程盯防"支付高价。
2026年的AI竞赛,已经不再是"谁参数更多"的单一维度比拼,而是效率 vs 智能体自主、普惠开源 vs 闭源精品、芯片自主 vs 生态绑定的多维战争。
作为普通用户和开发者,我们或许是最大的赢家——因为选择权,从未如此丰富。
你选谁呢?大树自己大概率是 deepseek 做主力,gpt 为辅了
如果这篇文章对你有一点启发:
- 💬 欢迎在 评论 区聊聊你的看法,批评指正文章内容
- 👍 点个爱心,让我知道这类内容有人看,我也好更好的选择创作方向
- 🔁 转发/收藏备用 如果内容有用,可以转发或者收藏备用~
你的每次互动,都是我继续写实战内容的动力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号