云端重构教学信息流:基于Qclaw多模态引擎的教师备课与复杂教学图文萃取实战全指南
原创
云端重构教学信息流:基于Qclaw多模态引擎的教师备课与复杂教学图文萃取实战全指南
原创
用户12452298
发布于 2026-04-30 14:45:18
发布于 2026-04-30 14:45:18
电子科技大学成都学院开放源子社团成员-邓宏玲
概述
在当前高校与中小学的教学备课、课后复盘及教研交流中,教师群体每天都要面对呈指数级增长的“教学类非结构化数据”。无论是历年沉淀的包含密集公式与图文排版的扫描版教辅资料、老教师手写的经典教案原稿,还是课堂上实时拍下的结构杂乱的黑板板书、实验操作步骤照片,亦或是教研活动中收集的字迹各异的听课笔记、学生手写作业错题集,这些信息大多以“图像”“PDF”“手写文稿”的死板形态存在。传统的数字化手段,往往依赖基础的OCR工具、办公软件转换或手机拍照提取文字,难以适配教学场景的特殊需求,效率低下且易出现排版混乱、公式错误。
#教育AI实践研究者 李知予
引言:教学非结构化数据的效率破局
在当前高校与中小学的教学备课、课后复盘及教研交流中,教师群体每天都要面对呈指数级增长的“教学类非结构化数据”。无论是历年沉淀的包含密集公式与图文排版的扫描版教辅资料、老教师手写的经典教案原稿,还是课堂上实时拍下的结构杂乱的黑板板书、实验操作步骤照片,亦或是教研活动中收集的字迹各异的听课笔记、学生手写作业错题集,这些信息大多以“图像”“PDF”“手写文稿”的死板形态存在。传统的数字化手段,往往依赖基础的OCR工具、办公软件转换或手机拍照提取文字,然而,这些老旧的方案通常只能进行机械的字符转录,面对教学场景中复杂的图文穿插(如教案中的知识点配图、板书上的公式与例题结合)、跨页连写的教学术语,以及需要进行逻辑梳理的错题解析、实验步骤图时,极易出现语意断层、排版崩溃,甚至是公式、数值的严重错误。
在这个效率为王的教学大背景下,Qclaw凭借其卓越的多模态大语言模型(VLM)底层架构,为打破教育场景中的“教学信息孤岛”提供了一种颠覆性的全新解法。它不仅能够“看清”图片和长文档上的每一个像素字符,更能够像资深教师一样“读懂”其中的教学逻辑、知识点脉络,提取核心教学信息,并按照教师期望的备课、复盘格式输出最终结果。然而,纵观当前的网络分享,多数关于Qclaw的讨论仅仅停留在“输入一段话、得到一段回答”的浅层闲聊式测评上,严重低估了其作为一款开源生产力工具的核心潜能,尤其缺乏针对其最硬核的“多模态视觉与长文本处理”能力,适配教育教学场景的可复用部署方案。
本次技术分享,我将完全摒弃基础的、毫无营养的体验测评,直接深入系统底层。文章将从云端服务器计算环境的硬核搭建入手,带领大家一步步完成Qclaw多模态解析链路的完整闭环部署。更为重要的是,我们将针对教育教学中最典型的“备课资料深度拆解”与“学生错题自动化归档”这两大极具痛点属性的真实场景,构建切实可用的定制化处理工作流。这不仅仅是一次软件安装教程,更是一套成熟的教学数据处理方法论。希望这篇超硬核的技术随笔,能为广大教育领域开源爱好者、正苦于备课效率低下的教师群体,以及有教学数字化转型诉求的教研工作者们,提供一份极具参考价值、字字珠玑的架构蓝图与避坑指南。
第一步:云端基座构建与底层计算资源的极客重塑
要让Qclaw发挥出真正的高端多模态解析能力,摆脱教师个人办公电脑算力不足、网络环境不稳定以及无法24小时待机的物理束缚,将其部署在云端服务器上是实现“随时随地备课、跨教研小组协同”的先决条件。在这一环节,底层资源的规划与网络架构的梳理至关重要。
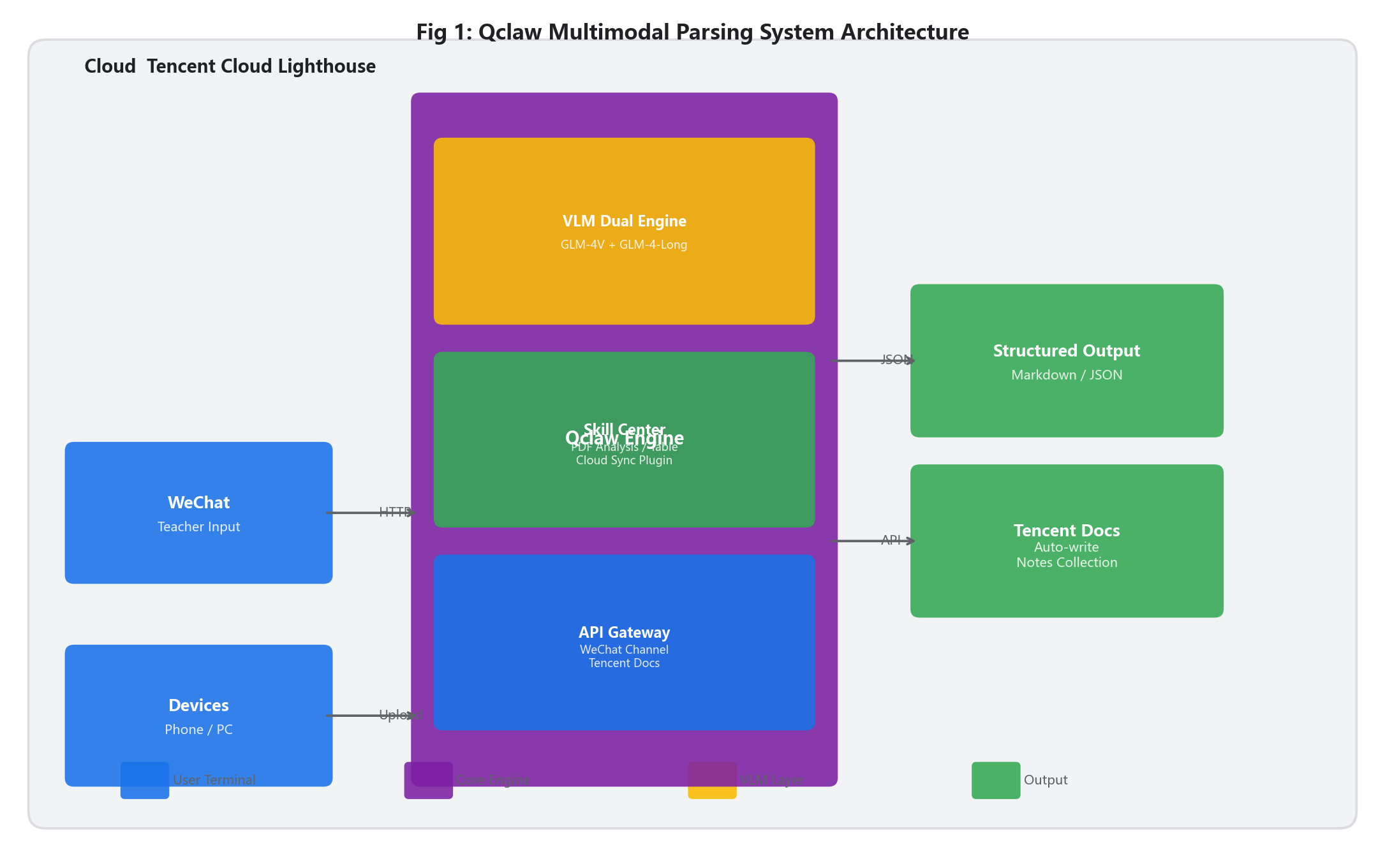
首当其冲的是算力节点的基座考量。必须明确的是,多模态任务与纯文本的对话任务有着天壤之别。尤其是涉及大规模教学PDF(如整套教辅资料、历年真题集)切分处理与高清教学图像(如实验步骤图、板书照片)特征提取的工作时,系统在瞬间需要将海量的像素张量加载到内存中,这对服务器的瞬时内存吞吐量与CPU计算峰值有着极高的要求。在本次项目落地中,我们摒弃了传统的重资产云主机,转而选用了具备高可用性、高性价比的腾讯云轻量级应用服务器(Lighthouse)作为运行载体。为了防止在解析长达数百页的教辅资料或多张高清实验照片时发生内存溢出(OOM)从而导致服务宕机,在计算资源的选择上,强烈建议优先考虑至少4GB以上的运行内存规格(本次实战采用2核4G6M组合)。同时,必须为存储节点配置充足的高速固态空间(至少60GB SSD),以应对海量教学文档缓存文件、错题照片、板书图像的频繁读写与持久化存储需求。
接下来是镜像部署与网络拓扑优化。为了最大化降低初期的环境搭建摩擦力,避免陷入无休止的Python依赖冲突、底层C++视觉处理库(如OpenCV、Tesseract组件包库、PDF渲染引擎等)编译报错的泥潭,直接挂载官方提供的集成了全量依赖的Qclaw专属发行版镜像(Multimodal专用版)无疑是最优解。通过一键初始化,系统底层环境将被完美还原,教师无需具备专业的编程能力,也能快速完成基础部署。
此外,服务器的实例启动后,切忌立刻进行跑测。首要且极其关键的一步是进入云服务器的控制台,配置严密的安全组网络规则。我们需要放行Qclaw运行所需的特定API通信端口(如8080端口用于服务监听,443端口用于HTTPS加密传输),以确保后续教师的手机、办公电脑能够与云端的解析中枢实现无延迟、高并发的数据握手。同时,基于教学数据(如学生错题、备课资料)的私密性,建议限制SSH端口的访问IP,筑牢教学数据的安全防线,避免敏感信息泄露。
第二步:解析引擎的核心参数调优与视觉神经元接入
当云端骨架搭建完毕,这台服务器还仅仅是一具空壳。我们需要为Qclaw注入“灵魂”,即为其配置强大的视觉模型基座、便捷的交互通信网关,以及专为教学场景打造的处理插件。这一阶段的参数调优,将直接决定最终产出结果的精准度,直接影响备课效率与错题归档的准确性。
最核心的环节是视觉大模型(VLM)与长文本引擎的接入。在多模态解析的语境下,纯文本的大模型面对教学图片时相当于“盲人”。我们在Qclaw的后台管理面板中,接入了国内顶尖的智谱GLM-4V(负责多模态视觉感知)与GLM-4-Long(负责百万级上下文处理)双引擎作为推理底座。GLM-4V针对中文教学场景的复杂图文环境进行了深度训练,它不仅能够精准捕获图片中微小的像素差异(如手写教案中的小字批注、错题中的细微修改痕迹),更能“理解”长图中各个知识点、公式、表格、例题之间的空间拓扑关系,这为后续完美还原教案结构、错题排版奠定了算力基础。而GLM-4-Long引擎则充当了“教学知识海绵”,能够一口气吞咽下整套教辅资料、历年真题集,在处理超长教学PDF时游刃有余,避免出现知识点遗漏、上下文断裂的问题。
紧接着是全平台触达的交互网关设定。在忙碌的教学工作中,教师不可能随时带着电脑、打开网页去上传文件。为了实现真正的“备课提效”,我们将Qclaw的交互终端无缝桥接至了教师常用的应用——微信(或企业微信)通道中。这一架构设计的精妙之处在于,教师只需在手机上完成“拍摄板书/转发教辅PDF/拍摄学生错题给机器人助手”这一最符合日常教学习惯的动作,远端的云主机即可瞬间捕获图像流或文档字节,并在后台开启静默解析进程。几秒钟后,高度结构化、排版精美的知识点、公式、错题解析或教案摘要就会直接被推回至微信聊天窗口。这种极度下沉、零学习成本的交互范式,才是将AI工具推向教师群体全员普及的关键,真正实现“随手拍、随手解析、随手用”。
最后,为了应对教育教学场景中极其严苛的图文解析需求,我们在Qclaw的技能中心(Skill Center)定向加载了多款重磅实战组件。其中,'qclaw-pdf-teaching-analyzer'组件专为解析超长篇的教学PDF(教辅、真题、教案合集)打造,其内置了先进的分块阅读(Chunking)机制与跨文档向量检索(RAG)能力,能够精准提取每章节的核心知识点、重难点,完美打破了传统大模型记忆遗忘的桎梏;'vision-teaching-table-pro'组件则专精于教学图像中复杂表格、公式的还原,能将模糊板书里的公式、错题表格、实验数据原封不动地转化为可二次编辑的Markdown语法或Word格式,方便教师直接插入备课课件;而'tencent-docs-teaching-sync'云端协同插件,则负责将解析完成的核心教学数据(如知识点汇总、错题集)通过API直接写入教研组共享文档,彻底打通教学信息流转的最后一公里,实现跨教师、跨班级的教学资源协同。
第三步:双轨实战场景的极限萃取深度演练
在底座与引擎全部轰鸣运转后,我们将通过两大最为硬核的真实教学痛点场景,深度剖析Qclaw在多模态萃取领域的降维打击能力,让每一位教师都能直观感受到技术带来的备课效率飞跃。
【场景A:备课利器——海量教学资料的“精准拆解”】
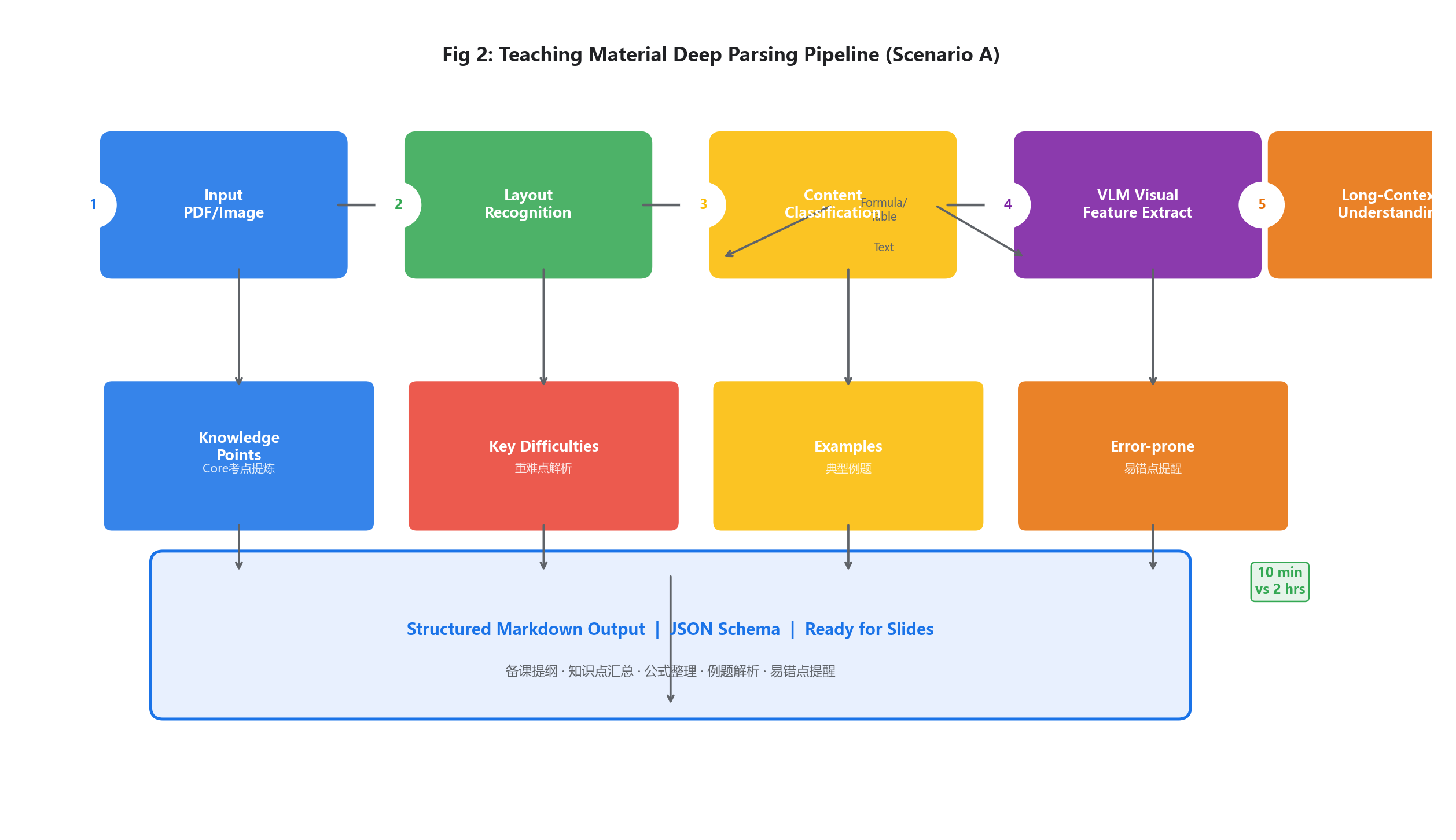
痛点溯源:对于中小学及高校教师而言,备课的核心痛点之一就是需要花费大量时间梳理海量教学资料,包括历年教辅、真题集、老教师手写教案、学术期刊中的教学研究文章等。这些资料往往篇幅冗长,排版复杂(如双栏排版的学术教学论文、图文穿插的教辅资料),中间还穿插着大量复杂的公式、例题解析、知识点表格。如果用传统的OCR工具或办公软件转换,要么出现排版混乱、公式错乱,要么无法提取知识点逻辑,教师需要花费大量时间重新整理、校对,严重拖慢备课进度,占用大量休息时间。
实战解析流:我们通过部署好的Qclaw构建了专门的教学资料自动化剖析工作流。当我们将一份最新的50页高中数学教辅PDF(包含公式、例题、知识点注解)发送给云端的Qclaw时,系统并没有进行低智的、逐字逐句的机械转录。相反,底层的教学PDF分析组件首先利用视觉版面识别技术,精确拆解了文档的排版逻辑,将图片、公式、例题、知识点注解彻底剥离并结构化存储,区分出“基础知识点”“重难点解析”“典型例题”“易错点提醒”四大模块。随后,长文本模型介入,它如同一位资深教研组长,敏锐地识别出了文档的教学层级树,并瞬间提炼出每章节的核心考点、易错点,以及例题与知识点的对应关系。
更令人惊叹的黑科技在于其对教学插图与公式的理解力。面对文中复杂的数学公式、几何图形、实验示意图,系统通过视觉大模型API直接提取了公式的推导逻辑、图形的核心要素,甚至识别出了例题的解题步骤与易错点标注。最终,Qclaw生成了一份逻辑严密、条理清晰的Markdown格式备课提纲,包含知识点汇总、公式整理、例题解析、易错点提醒,教师只需在此基础上稍作修改,即可快速生成课件。这已经超越了传统的文档转换工具,这是一种跨越格式障碍、跨越繁琐整理的深层次教学信息提纯,让教师能够在10分钟内完成原本需要2小时的资料梳理工作,堪称备课加速的核武器。
【场景B:教研助手——学生错题与手写作业的“自动化归档”】
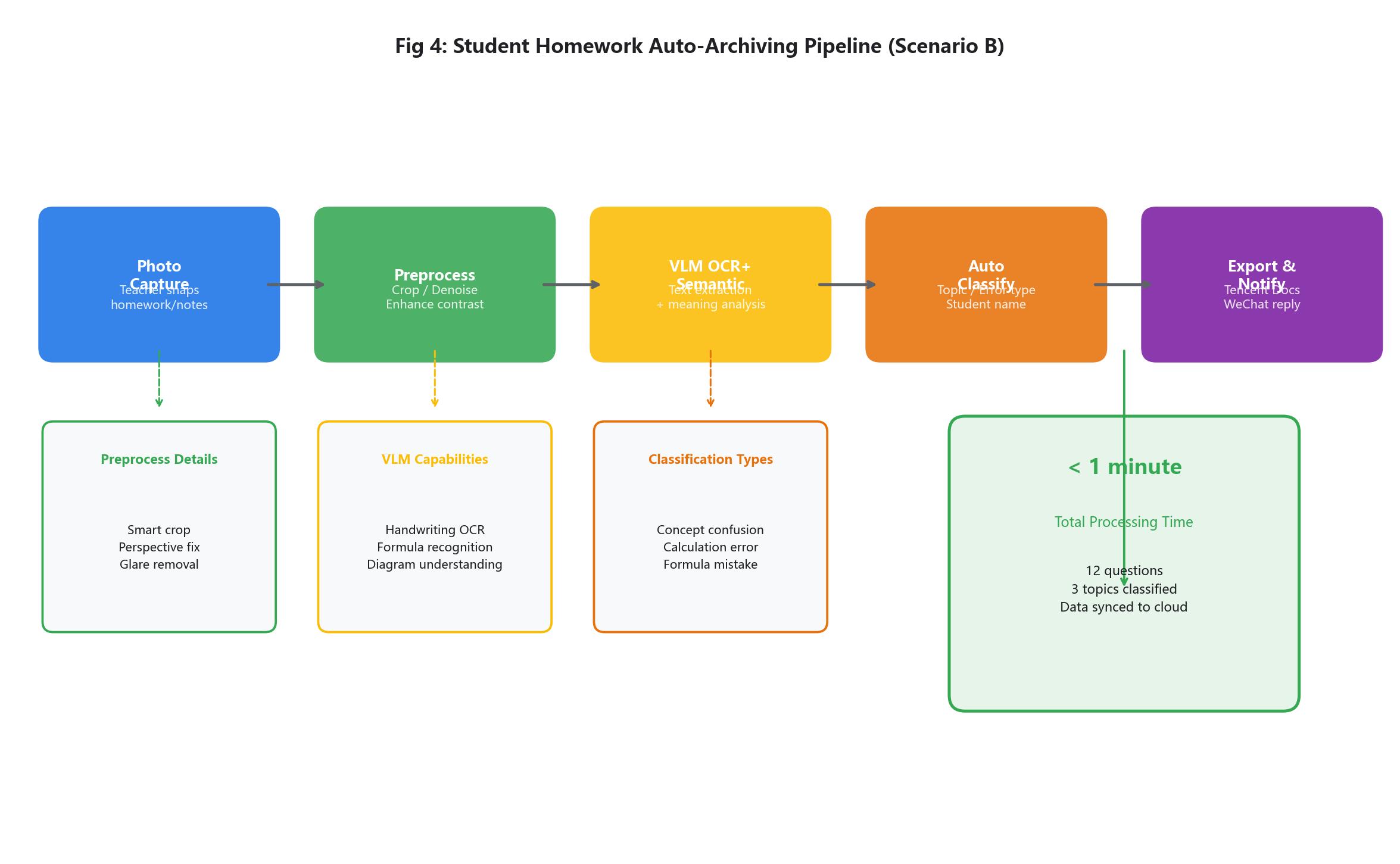
痛点溯源:对于一线教师而言,课后批改作业、整理学生错题集是一项极其繁琐且耗时的工作。尤其是文科的手写主观题、理科的公式错题,学生字迹各异、错题标注混乱,教师需要逐题抄写错题、整理错误原因、分类归档,不仅耗费大量精力,还容易出现错题遗漏、分类错误的问题,难以快速掌握学生的知识薄弱点,影响教研针对性。
实战解析流:在这个场景下,我们将Qclaw转化为了一位不知疲倦、火眼金睛的教研助手。操作极其简单:教师只需将学生的手写作业、错题本平铺在桌面上,用手机拍下一张高清照片发送给微信里的Qclaw助手,即可批量解析多篇作业、多个错题。系统接收到这复杂的图像流后,首先进行智能透视裁剪、去反光处理与色彩对比度增强,清晰还原手写字迹与错题标注。紧接着,强大的视觉模型组件开始进行OCR与语意理解的交叉验证。它不仅准确抓取了每道错题的题目内容、学生的手写答案、错误修改痕迹,更是精准识别出了错题对应的知识点、错误类型(如概念混淆、计算失误、公式记错)。
对于字迹极其潦草的手写主观题(如语文作文批注、政治论述题答案),Qclaw凭借优秀的中文手写体泛化能力,不仅准确识别了文字,还理解了学生的答题逻辑与错误要点。随后,内置的'tencent-docs-teaching-sync'协同插件被唤醒,这些原本零散在图片各个角落的错题信息被自动提取、分类,按照“知识点分类”“错误类型”“学生姓名”三大维度,瞬间被整齐划一地写入到教研组腾讯文档里的“学生错题汇总表”的对应单元格中。最后,Qclaw还贴心地在微信端回复了一句:“已成功解析12道错题,涵盖3个知识点,其中概念混淆类5道、计算失误类4道、公式记错类3道,数据已同步至云端错题集,请教师核对并针对性备课。”从一堆杂乱无章的手写作业照片,到一份井然有序、分类清晰的结构化错题集,全程耗时不到1分钟,真正将教师从繁琐的错题整理工作中解放出来,专注于教研与针对性教学。
第四步:高阶架构调优策略与生产环境部署沉淀
在完成了一系列的震撼演示并进入长期的稳定运行期后,我们教研团队并没有停止探索。在这个过程中,我们也沉淀了几条关于如何突破系统瓶颈、提升解析精度的极其宝贵的实战高阶调优经验,毫无保留地分享给各位教育工作者与开源爱好者。
第一条准则,永远不要忽视物理世界的输入质量,图像预处理至关重要。虽然我们搭载的VLM视觉大模型有着极强的容错率和纠错能力,但在教师上传教学图片(板书、作业、教案)前,若能通过提示要求大家保证环境光源均匀、避免极其强烈的反光覆盖关键文字、公式区域,并且图片分辨率保持在1080P以上,系统的识别置信度与一次性成功率将呈指数级上升。垃圾进,垃圾出(Garbage in, garbage out)的铁律在AI时代依然适用,尤其是教学场景中,公式、小字批注的识别精度直接影响备课与教研效果。
第二条准则,善用Prompt Engineering(提示词工程)进行硬核约束。当我们的目标是要求Qclaw输出极其严谨的教学数据(如错题分类、知识点汇总、教案提纲)时,切忌使用模糊的自然语言请求。我们必须在后台设定严格的System Prompt(系统级提示词),甚至利用JSON Schema强制规范大模型的输出格式。例如要求其“仅输出包含错题题目、知识点、错误类型、解析步骤的JSON数组,严禁包含任何解释性的自然语言废话”。这种强规则约束能够有效避免AI产生大段无用的过渡句,为后续将其直接桥接进入自动化教学工作流(如直接导入备课课件、错题管理系统)扫清所有格式障碍。
第三条准则,警惕超长文本处理时的“内存泄漏”与“上下文遗忘”效应。在面对页数破百的超级教辅资料、真题集时,大模型往往会出现顾此失彼的情况,导致知识点遗漏、错题分类错误。我们在实战中发现,适度调大文档解析组件中的Chunk Size(文本分块大小)可以保留更多的上下文语义关联,减少断章取义;但同时,这也会带来服务器算力的急剧消耗与Token成本的直线上升。因此,利用之前安装的'memory-hygiene'(长会话记忆清理插件),在每次完成一套教辅资料或一个班级的错题解析后自动释放上下文缓存池,是保障云端服务器轻装上阵、长期稳定不宕机的必杀技。
结语:开启多模态协同与教学提效的崭新纪元
回望整个基于腾讯云轻量级服务器架构的Qclaw多模态处理引擎搭建之旅,其最深远的价值,绝对不仅仅是我们又在手机里增加了一个可以随时聊天的智能机器人。其真正的划时代意义在于,我们作为普通的教育工作者与开发者,凭借着开源社区的力量,真正掌握并落地了一套将教学场景中极其复杂、模糊、非结构化的图文信息,以前所未有的高效率转化为结构化教学生产力的超级工业流水线。
从云端算力基座的严谨选型,到双核大模型引擎的无缝嵌入;从破解多格式、多排版、密布公式的长篇教学资料的梳理壁垒,到轻松收纳、自动化归档学生手写作业与错题集,Qclaw展现出了令人生畏的强大场景泛化适应性与实战执行力。它真真切切地将教师们从繁杂枯燥的重复性体力劳动中解脱了出来,让我们可以把宝贵的时间与脑力,倾注到更具创造力的备课、教研与学生培养之中。
星星之火,可以燎原。相信这份涵盖了从底层环境拓扑规划、核心参数深度调优,到两大垂直教学场景极限落地的纯原创超长篇技术剖析指南,能够成为各位教育领域极客、开源技术追随者、一线教师们在AI浪潮中提升教学效率的坚实装甲与跳板。让我们共同期待,未来会有更多饱含想象力、深具教育情怀的实战应用生态在这个开源平台上落地生根、开花结果,用技术的代码重塑教学与教研的信息流向,助力教育数字化转型!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号