Transformer架构详解:从原理到应用的全面指南

Transformer架构详解:从原理到应用的全面指南

烟雨平生
发布于 2026-04-28 20:20:42
发布于 2026-04-28 20:20:42

01. 引言:什么是Transformer?
Transformer是2017年由Google在论文《Attention is All You Need》中提出的一种深度学习架构,它彻底改变了自然语言处理(NLP)领域。在Transformer出现之前,大多数NLP模型主要依赖于循环神经网络(RNN)或卷积神经网络(CNN),但这些模型在处理长序列时存在严重的长距离依赖弱化、串行计算效率低下的核心痛点,CNN也受固定卷积窗口限制,无法全域捕捉文本关联语义。
Transformer摒弃传统循环、卷积核心结构,完全依托注意力机制搭建全新网络架构,从根源上解决了传统RNN/CNN模型的局限性,能够高效捕捉超长序列全局关联特征,同时支持全维度并行高速计算。它最初定向适配机器翻译序列转换任务研发落地,后续快速全场景适配各类NLP细分任务,更是当下GPT、BERT、DeepSeek全系国产大模型在内,所有主流通用大语言模型的底层核心底座架构。
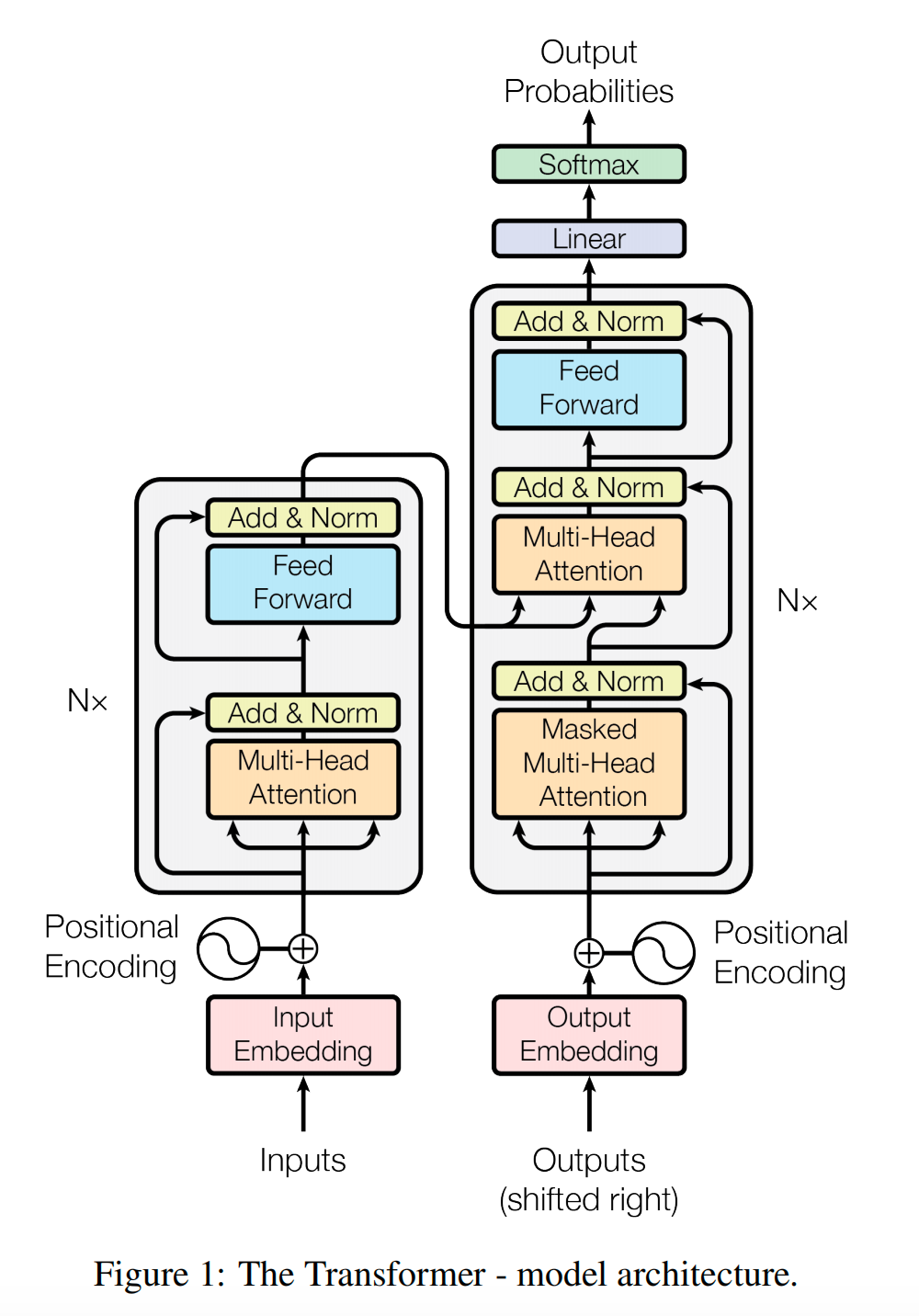
02. 核心原理:自注意力机制
Transformer的核心创新是自注意力机制(Self-Attention Mechanism),打破传统模型序列距离束缚,模型处理文本、向量等序列任意单个元素时,可直接全域联动关联序列内所有其他元素,自主研判语义关联强弱,全域抓取上下文有效特征,无远距离信息衰减问题。
2.1 自注意力机制的数学原理
自注意力机制通过联动计算查询向量(Query)、键向量(Key)、值向量(Value)三组核心可学习向量,量化研判序列两两元素间语义贴合度,精准锚定各元素权重占比。其标准计算公式如下:

各参数释义:
- Q(查询矩阵):定位当前元素待匹配的目标语义特征;
- K(键矩阵):承担全序列所有元素语义特征标识、锚定作用;
- V(值矩阵):承载序列全部原始语义、细节核心有效特征;
- d_k:键向量维度,引入根号缩放系数,规避高维向量内积数值过大,引发Softmax梯度饱和问题;
- Softmax:将相似度分值统一换算为0-1区间有效权重,完成归一化。
整套公式核心逻辑:先全域测算序列任意位置双向语义相似度,再完成数值缩放降噪优化,归一化输出注意力权重,最后依托权重加权聚合全局特征,输出融合完整上下文语义的高质量表征向量。
2.2 多头注意力机制
为突破单路注意力特征提取单一短板,Transformer引入多头注意力机制(Multi-Head Attention)。其核心逻辑并非简单拆分输入向量,而是将Q、K、V三组矩阵同步线性投影拆解为多组独立特征子空间,每个注意力头各司其职、并行独立完成全域自注意力计算,最后拼接所有多头输出特征,搭配线性层完成跨头特征融合补强。
这种精细化并行设计,可同步抓取语法语序、语义关联、指代呼应、逻辑关联等多维度隐性特征,全方位强化模型上下文理解、语义建模综合能力,适配复杂场景文本解析与生成需求。
03. Transformer架构详解
工业级基于完整版Transformer架构的模型,采用对称双核心模块化设计,核心由编码器(Encoder)、解码器(Decoder)两大独立模块构成,两大模块均遵循同质层堆叠搭建逻辑,层级数量可按需适配任务灵活调配,适配各类长短序列AI落地场景。
3.1 编码器结构
单层标准编码器为双核心子层串联闭环结构,适配语义理解类全场景任务:
- 多头自注意力层:采用双向全域无掩码注意力逻辑,序列所有位置互相可视、全域联动,深度挖掘双向上下文隐性语义关联;
- 前馈神经网络层:双层全连接结构,原生搭配ReLU激活函数,主流工业落地场景中多迭代适配GeLU激活函数,兼顾算力效率与特征拟合精度。
两大核心子层外围统一标配残差连接(Residual Connection)+ 前置层归一化(Layer Normalization)双防护机制,从根源上缓解深层模型梯度消失、梯度爆炸难题,保障多层堆叠深层Transformer模型稳定高效训练收敛。
3.2 解码器结构
单层标准解码器适配文本自回归生成场景,增设专属交互子层,共计三大核心功能子层,各司其职闭环联动:
- 掩码多头自注意力层:同源适配编码器多头注意力核心逻辑,叠加专属上三角掩码屏蔽机制,强制阻断当前生成位置偷看后续未生成文本信息,严守自回归逐序生成底层逻辑;
- 编码器-解码器交叉注意力层:是序列到序列(seq2seq)任务核心创新,依托交叉注意力,实时调取编码器全域输入上下文特征,联动约束解码器生成逻辑,保障输出内容贴合原始输入语义;
- 前馈神经网络层:结构与编码器完全同源,保障整体架构算力均衡、训练节奏稳定。
解码器全端子层同样覆盖残差连接与层归一化,适配深层堆叠、大参数量工业化训练落地需求。
3.3 位置编码
核心补充:自注意力机制本身仅能计算语义关联,无天然时序、语序感知能力,无法自主判别文本先后逻辑顺序,必须人工外置注入精准位置时序信息。Transformer原生标配正弦余弦位置编码,依托固定频率三角函数,为序列每一个下标位置生成唯一专属时序编码:

各参数释义:
- pos:文本序列真实绝对排列位置;
- i:特征维度分组专属索引;
- d:模型全局统一基础维度。
该原生位置编码轻量化无额外算力开销,天然适配任意超长序列延伸拓展,自带精准相对位置关联特征,无需单独专项训练,后续所有大模型进阶位置编码方案,均以此为基础迭代优化而来。
04. Transformer的应用与变体
4.1 原始应用:机器翻译
Transformer初始研发定向适配中英、英德跨语种机器翻译场景,依托完整编码器-解码器seq2seq架构,在WMT 2014国际权威英德翻译数据集上刷新同期最优效果,正式奠定序列建模标杆地位,拉开AI大模型工业化迭代序幕。
4.2 BERT:基于编码器的模型
2018年Google推出BERT(Bidirectional Encoder Representations from Transformers)模型,仅保留Transformer原生编码器模块,舍弃解码器结构,依托双向全域注意力机制,深度挖掘双向上下文联动语义,全方位赋能语言理解类AI任务。
BERT核心两大预训练任务:
- 掩码语言模型(Masked Language Model, MLM):随机遮蔽文本中部分核心词汇,驱动模型依托全域上下文精准预判缺失词汇,夯实语义理解底座能力;
- 下一句预测(Next Sentence Prediction, NSP):智能研判两段独立文本是否为连贯上下文关联关系,强化语句层级逻辑建模能力,后续落地中多按需优化迭代。
4.3 GPT:基于解码器的模型
OpenAI推出GPT全系列生成式大模型,架构逻辑与BERT形成精准互补,仅复用Transformer标准解码器核心模块,舍弃编码器结构,全程采用自回归逐token生成范式,前置海量文本通用预训练,可零适配生成逻辑连贯、语义通顺的长段优质文本内容。
GPT系列迭代紧扣Transformer底层架构,稳步扩容优化:
- GPT-1(2018):初代轻量化落地,验证解码器Transformer生成式预训练可行性;
- GPT-2(2019):适度扩容参数量,优化上下文联动能力,提升长文本生成连贯性;
- GPT-3(2020):千亿级超大参数量,首次落地上下文In-context Learning泛化能力;
- GPT-4(2023):架构小幅迭代升级,新增多模态适配能力,同步兼容文本、图像双轨输入解析。
4.4 其他主流变体
- T5(Text-to-Text Transfer Transformer):创新统一全品类NLP任务范式,全部转化为文本输入-文本输出标准化格式,大幅降低行业落地适配成本;
- ViT(Vision Transformer):将图像切分为等价序列小块,把计算机视觉任务转化为标准序列建模任务,打通CV与NLP底层架构壁垒;
- Transformer-XL:针对性优化长文本,新增相对位置编码与片段循环机制,解决超长上下文语义割裂、信息断层难题;
- Reformer:搭载可逆层结构与稀疏注意力机制,大幅压缩超长序列算力、显存综合消耗。
05. Transformer的优势与局限性
5.1 核心优势
- 并行高速计算能力:彻底摆脱RNN串行逐点计算桎梏,一次性全域并行处理完整序列,训练、推理双环节算力效率翻倍提升;
- 全域长距离依赖建模:依托自注意力直接联动序列任意位置元素,无梯度链式衰减问题,超长文章语义建模能力碾压传统循环模型;
- 可视化可解释性:注意力权重可实时热力图可视化呈现,直观溯源模型重点关注核心段落、关键词,便于技术人员调优迭代、故障排查;
- 全域通用适配性:架构兼容性极强,轻量化微调后可无缝适配NLP、计算机视觉、语音交互、多模态生成全场景AI任务,是全域通用AI核心底座。
5.2 局限性
- 算力复杂度偏高:原生自注意力计算复杂度随序列长度平方级攀升,面对百万级超长文本、高清长序列图像,算力、显存成本压力陡增;
- 海量数据强依赖:Transformer原生大参数量属性,必须依托海量优质标注预训练数据才能释放最优性能,小样本、小众行业场景极易出现过拟合问题;
- 位置时序建模短板:原生正弦位置编码仅能基础标注顺序,对复杂长文本精细化相对语序、深层逻辑时序建模能力不足;
- 生成侧固有瑕疵:纯解码器架构自回归生成过程中,易出现内容重复、逻辑断层、事实性幻觉等行业共性问题,需额外对齐优化。
06. 理论落地实战:标准Transformer与DeepSeek-V4核心联动解析
前面全文完整拆解了2017年原版Transformer全套底层理论、核心结构、优缺点及行业变体。很多新手看完理论仍有困惑:当下我们日常商用的国产大模型,和书本里的Transformer到底有什么关系?现在我们直接理论联系真实工业大模型,以国内主流顶尖商用大模型DeepSeek-V4为例,手把手拆解:DeepSeek-V4为什么就是套壳升级版Transformer?它保留了哪些原生核心原理?又针对性优化了哪些原版短板?看完本节,彻底告别纸上谈兵,一眼看懂所有商用大模型底层底牌。
6.1 核心一句话定性:DeepSeek-V4本质是什么?
DeepSeek-V4是深度求索推出的新一代工业化混合专家大语言模型,核心定位:纯解码器Transformer架构 + 海量工程硬核优化。全程不用编码器,仅依托Transformer解码器完成全流程自回归文本生成。所有炫酷的百万长上下文、超强推理、高速生成能力,全都不是凭空创新,而是在2017年原版Transformer基础上,针对性补强短板、扩容优化而来。吃透前面的Transformer理论,就等于吃透了DeepSeek-V4八成底层逻辑。
6.2 同源对标:DeepSeek-V4完全保留的Transformer核心底层
无论大模型迭代多少次、参数量扩容多少倍,底层核心刚需框架永远不变,DeepSeek-V4全程完整沿用:
第一,自注意力核心计算公式完全不变。DeepSeek-V4所有语义计算、上下文联动,全程沿用原版缩放点积注意力公式,所有优化都是外围提速增效,底层语义匹配原理和标准Transformer一模一样。
第二,多头注意力并行机制完全不变。依旧是多注意力头分头并行抓取多维特征,最后拼接融合输出,同步兼顾语法、语义、逻辑多维度建模,和原生多头逻辑完全同源,保障语义理解精度不打折。
第三,掩码自回归约束完全不变。文本生成全程沿用三角掩码机制,严格阻断模型偷看后续未生成token,坚守自回归逐字生成底层逻辑,保障输出文本语序通顺、逻辑合规。
第四,残差连接+层归一化双防护完全不变。深层堆叠几十层网络后,全程靠这套经典机制稳住梯度、防止训练崩盘,保障万亿级大参数量模型可稳定训练、高效收敛,是DeepSeek-V4深层网络的安全基石。
第五,位置信息刚需逻辑不变。原版用正弦余弦编码补顺序,DeepSeek-V4迭代升级为RoPE(旋转位置编码Rotary Position Embedding),本质目的完全一致:都是给无语序感知的注意力机制强制注入文本时序信息,适配超长序列语序建模。
6.3 针对性攻坚:DeepSeek-V4精准优化Transformer三大原生痛点
标准Transformer理论完美,但工业化落地有三大痛点:长文本算力爆炸、深层网络训练不稳、超大参数量算力浪费。DeepSeek-V4针对性硬核改造,精准补齐短板:
一是优化注意力机制,破解平方级算力难题。原版注意力序列越长算力越贵,根本跑不动百万级长文档。DeepSeek-V4搭载CSA压缩稀疏注意力+HCA重度压缩混合注意力,叠加原生DSA(DeepSeek Sparse Attention)动态稀疏注意力核心模组联动协同,同时在Transformer核心投影器线性变换层嵌入专属Token维度压缩算子,超长段落按需压缩智能合并、重点段落精细计算,把算力成本压到原版的20%以内,完美实现百万token超长上下文流畅对话、长文档全域解析。
二是升级残差结构,适配万亿级深层大模型。原版普通残差堆叠过深易梯度漂移、训练崩盘。DeepSeek-V4升级mHC多路强化超连接,约束深层信号稳定传输,让超大参数量模型能安全叠加更多网络层,推理能力、逻辑研判能力同步翻倍提升。
三是搭载MoE混合专家架构,告别算力浪费。标准Transformer每层全参数激活,算力冗余严重。DeepSeek-V4采用动态专家调度,总参数量拉满保障能力,每次推理仅激活少量核心专家网络,兼顾超强AI能力与低成本落地,性价比远超传统稠密Transformer模型。
6.4 落地认知升华:学透Transformer,就能玩转所有国产大模型
不管是DeepSeek-V4、文心一言、通义千问,还是GPT全系、LLaMA开源模型,底层统一全是升级版Transformer。所有市面宣传的新技术、新能力,全都不是颠覆重构,只是在自注意力、解码器、位置编码、残差连接这些基础模块上,做提速、稳压、扩容、降噪的工程优化。
只要你吃透本文前面的标准Transformer原理,再结合本节DeepSeek-V4实战对照,就能瞬间看懂所有商用大模型底层逻辑,不被花哨宣传名词误导,既能懂理论原理,又能落地看懂真实工业级大模型,真正做到学以致用、知行合一。
07. 结论与展望
Transformer架构的落地与迭代,是现代深度学习里程碑式的技术突破,从根源上解决了传统RNN、CNN序列建模的核心短板,筑牢了全域大语言模型、多模态通用AI的统一底层底座。十余年间,它从小众机器翻译专用架构,全面渗透至智能对话、长文办公、代码生成、多模态创作、行业智能赋能等全场景AI赛道,成为AI产业不可替代的核心基础架构,全程支撑大模型工业化规模化落地。
结合前文理论拆解与DeepSeek-V4实战落地交叉核验可明确:当下主流国产商用大模型无一是凭空重构底层架构,全部沿用标准Transformer原生核心范式。DeepSeek-V4作为标杆级工业化大模型,完整复用自注意力核心公式、多头并行计算、掩码自回归约束、残差+层归一化稳梯度、时序位置编码五大基础核心能力,严格贴合2017年原版Transformer底层理论逻辑,仅针对原生架构工业化痛点做定向工程优化,完美印证Transformer通用适配、可迭代升级的核心优势。
同时,DeepSeek-V4的全套升级方案,精准对标标准Transformer三大原生短板闭环攻坚:依托CSA压缩稀疏注意力+HCA重度压缩混合注意力,破解原生注意力序列平方级算力爆炸难题,稳稳支撑百万Token超长上下文低耗推理;自研mHC流形约束超连接强化残差链路,解决深层堆叠梯度漂移、训练易崩盘问题,适配万亿级超大参数量安全训练;沿用成熟MoE混合专家调度架构,摒弃传统稠密Transformer全量冗余算力激活模式,兼顾顶尖智能推理能力与低成本落地性价比,补齐原生模型算力浪费、落地门槛高的短板,所有优化均贴合工业真实业务刚需。
放眼行业全域攻坚方向,当前科研与工程团队正持续深耕Transformer轻量化迭代赛道,围绕降低注意力算力开销、弱化数据依赖、优化精细化位置时序建模、压缩生成事实幻觉四大核心方向,持续迭代稀疏注意力、进阶混合专家架构、新型旋转位置编码、对齐强化学习等配套优化方案。后续以DeepSeek系列为代表的新一代衍生Transformer模型,会进一步实现低能耗、强逻辑、零幻觉、轻量化全维度升级,全面适配端侧便携AI、垂直行业专属私域大模型、全域多模态智能体交互等全新场景。
综上,吃透标准Transformer全套底层原理,结合DeepSeek-V4这类标杆模型完成理论联动实操复盘,是每一位AI从业者、技术爱好者跟上大模型前沿迭代、读懂国产商用大模型底层逻辑的必备核心能力,也是深耕AI应用开发、模型调优、行业落地的基础必修课。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号