DeepSeek-V4 技术报告深度解析


当前大语言模型面临一个根本性的矛盾:
- 1. 测试时扩展(Test-Time Scaling)要求模型能处理越来越长的推理链:ChatGPT o1、DeepSeek-R1 等推理模型已经证明,让模型"想得更久"能显著提升性能。
- 2. 但原始注意力机制的计算复杂度是 O(n2)O(n^2)O(n2)——序列长度 nnn 每翻一倍,计算量翻四倍。
- 当 nnn 达到百万级时,这堵"计算墙"根本翻不过去。
如何在保持注意力机制表达力的前提下,
将其计算复杂度从 O(n2)O(n^2)O(n2) 降到可接受的水平,从而使百万 Token 上下文在工程上可行?
DeepSeek-V4 技术报告讲述了使用哪些技术创新和工程优化做到了这一点:
混合注意力(CSA+HCA)降计算量、mHC 保信号稳定、Muon 优化器加速收敛、全栈工程优化。
摘要
两个模型定位:
DeepSeek-V4-Pro | DeepSeek-V4-Flash | |
|---|---|---|
总参数 | 1.6T | 284B |
激活参数 | 49B | 13B |
定位 | 旗舰版,追求最强性能 | 轻量版,追求性价比 |
概念:总参数 vs 激活参数。 MoE 架构下,所有专家的参数加起来是总参数,但每个 Token 只会激活其中一小部分(由路由器决定),这就是激活参数。 总参数决定"知识储备上限",激活参数决定"每次推理的计算成本"。
三大架构创新:
- 1. 混合注意力(CSA + HCA):论文核心的贡献,
- 2. 流形约束超连接(mHC):改进层间信息传递
- 3. Muon 优化器:改进训练过程
关键效率数字(百万 Token 上下文,与 V3.2 对比):
指标 | V4-Pro | V4-Flash |
|---|---|---|
单 Token 推理 FLOPs | 27% | 10% |
KV 缓存大小 | 10% | 7% |
V4-Pro 的激活参数(49B)比 V3.2(约 37B)还多,但计算量反而降至 27%。 这说明效率提升完全来自架构设计,而非单纯的模型缩小。 这是一个非常重要的方法论启示——通过架构创新而非参数削减来实现效率提升。
引言
核心论证逻辑是三步走:
Step 1:推理模型建立了测试时扩展的新范式 → 需要更长的上下文
Step 2:原始注意力的 O(n2)O(n^2)O(n2) 复杂度是硬瓶颈 → 长上下文不可行
Step 3:因此,高效长上下文是突破测试时扩展天花板的关键
测试时扩展(Test-Time Scaling) 传统范式是"训练时扩展"——用更多数据和算力训练更大的模型。 测试时扩展是另一种思路——模型训练好后,在推理时投入更多计算(例如让模型生成更长的思维链),也能获得更好的性能。 模型在生成答案时,通过多次采样、自我纠错、展开推理链或进行更深入的搜索(如树搜索、思维树等),投入更多推理时间计算,从而获得更准确、更合理的输出。 DeepSeek-R1 和 OpenAI o1 就是这一范式的代表。但更长的思维链意味着更长的上下文,这就撞上了注意力的 O(n2)O(n^2)O(n2) 瓶颈。
创新之处:DeepSeek-V4 不是在"长上下文"和"高效率"之间做取舍,而是通过架构层面的重新设计,让两者同时成立。
这与之前的工作(如单纯增大上下文窗口但承受巨大计算开销)有本质区别。
架构
DeepSeek-V4 的架构保留了 V3 的 Transformer + MoE + MTP 框架,新增了三大组件。
继承自 V3 的设计
混合专家模型(MoE)
概念回顾:MoE(Mixture of Experts)将前馈网络(FFN)替换为一组"专家"网络。
每个 Token 由路由器(Router)分配给少数几个专家处理。DeepSeekMoE 的特色是:
- • 细粒度路由专家:专家数量多但每个较小(如 256 个,中间维度 2048)
- • 共享专家:1 个共享专家,所有 Token 都经过它
- • 每个 Token 激活 k 个路由专家(V4 中 k=6k=6k=6)
为什么需要共享专家? 路由专家各自专精不同知识领域,但有些知识是所有 Token 都需要的(如基本语法、通用语义)。 共享专家承担这类"公共知识"的角色,避免每个路由专家都要学习这些基础能力。
V4 相对 V3 的调整:
- 1. 亲和度激活函数:Sigmoid → Sqrt(Softplus)动机:Sigmoid 的输出在 0-1 之间,且两端梯度趋近于 0(饱和区),容易导致路由梯度消失。Sqrt(Softplus) 在正区间梯度不会消失,且输出范围更灵活,有助于更精细的专家分配。
- 2. 哈希路由:前几层用按 Token ID 的哈希函数决定路由,而非学习型路由器动机:浅层主要处理低级特征(如字符级模式),不需要复杂的路由决策。哈希路由省掉了浅层路由器的计算开销和训练不稳定风险。这呼应了"不是每层都需要同等复杂度的路由"这一设计哲学。
- 3. 移除路由目标节点数量限制动机:V3 限制了每个设备上最多接收的 Token 数量(防止负载不均),但这人为约束了路由自由度。V4 通过重新设计并行策略解决了负载均衡问题,因此解除了这个限制。
多 Token 预测(MTP)
概念:传统语言模型每次只预测下一个 Token。
MTP 在主预测头之外增加辅助预测头,同时预测未来多个 Token(V4 中深度为 1,即预测下一个 Token 的辅助头)。
为什么 MTP 有用? 两个好处:① 训练信号更密集——每个位置提供多个梯度信号; ② 推理时可选择性地用 MTP 头做推测解码(Speculative Decoding),加速生成。
V4 继续沿用 V3 的 MTP 配置。
流形约束超连接(mHC)
背景:从残差连接到超连接
残差连接(Residual Connection):xl+1=xl+Fl(xl)\mathbf{x}_{l+1} = \mathbf{x}_l + F_l(\mathbf{x}_l)xl+1=xl+Fl(xl)
这是 Transformer 的标配。
信息从第 lll 层传到第 l+1l+1l+1 层时,直接把输入 xl\mathbf{x}_lxl 加到输出上。
好处是梯度可以"跳过"中间层直接回传(缓解梯度消失),但坏处是信息传递只有一条路径,且"加"操作是固定的。
超连接(Hyperconnection, HC):Xl+1=BlXl+ClFl(AlXl)\mathbf{X}_{l+1} = \mathbf{B}_l \mathbf{X}_l + \mathbf{C}_l F_l(\mathbf{A}_l \mathbf{X}_l)Xl+1=BlXl+ClFl(AlXl)
HC 做了两个升级:
- 1. 把残差流从 ddd 维扩展到 nhc×dn_{hc} \times dnhc×d 维(多车道)
- 2. 用可学习矩阵 Al,Bl,Cl\mathbf{A}_l, \mathbf{B}_l, \mathbf{C}_lAl,Bl,Cl 替代固定的"加"操作
创新:HC 把残差宽度与隐藏大小解耦了。 隐藏大小 ddd 影响层内计算量,残差宽度 nhcn_{hc}nhc 影响层间信息传递的丰富度。 这是一个独立的缩放轴——你可以在不增加层内计算的前提下,让层间信息传递更丰富。
但 HC 有一个致命问题:堆叠多层后训练容易数值爆炸/崩溃。
原因很简单:Bl\mathbf{B}_lBl 是无约束的矩阵,它的谱范数(最大奇异值)可能大于 1,意味着信号每经过一层就可能被放大,堆叠多层后指数级增长。
mHC 的核心创新:流形约束
mHC 的解法非常优雅:把 Bl\mathbf{B}_lBl 约束到双随机矩阵流形(Birkhoff 多面体)上。
概念:双随机矩阵。 一个矩阵 M∈Rn×n\mathbf{M} \in \mathbb{R}^{n \times n}M∈Rn×n 如果满足:① 每行元素之和为 1;② 每列元素之和为 1;③ 所有元素非负。这样的矩阵就是双随机的。
为什么双随机约束有效? 三个数学性质:
- 1. 谱范数 ≤ 1:双随机矩阵的最大奇异值不超过 1,因此 ∥Bl∥2≤1\|\mathbf{B}_l\|_2 \leq 1∥Bl∥2≤1,信号不会在传递中被放大——这是"非扩张映射"。
- 2. 乘法封闭性:两个双随机矩阵的乘积仍然是双随机矩阵。这意味着无论堆叠多少层 mHC,∏lBl\prod_l \mathbf{B}_l∏lBl 仍然是非扩张的——这是深层堆叠的稳定性保证。
- 3. 行/列和为 1:信息在传递过程中"守恒",不会凭空消失或产生——每个输出维度都是输入维度的凸组合。
如何实现约束?Sinkhorn-Knopp 算法:
- 1. 先生成无约束的原始参数 B~l\tilde{\mathbf{B}}_lB~l
- 2. 取指数确保正性:M(0)=exp(B~l)\mathbf{M}^{(0)} = \exp(\tilde{\mathbf{B}}_l)M(0)=exp(B~l)
- 3. 交替执行行归一化和列归一化 20 次迭代
- 4. 收敛到双随机矩阵
教授点评:Sinkhorn-Knopp 算法是矩阵论中的经典方法,最初用于最优传输问题。DeepSeek 把它引入到深度学习的层间连接设计中,这是一个很好的跨领域知识迁移。20 次迭代是经验值——理论上迭代次数越多越精确,但边际收益递减。
动态参数化
mHC 的 Al,Bl,Cl\mathbf{A}_l, \mathbf{B}_l, \mathbf{C}_lAl,Bl,Cl 不是固定参数,而是根据输入动态生成的:
B~l=αlres⋅Mat(X^lWlres)+Slres\tilde{\mathbf{B}}_l = \alpha_l^{res} \cdot \text{Mat}(\hat{\mathbf{X}}_l \mathbf{W}_l^{res}) + \mathbf{S}_l^{res}B~l=αlres⋅Mat(X^lWlres)+Slres
其中:
- • 动态分量:X^lWlres\hat{\mathbf{X}}_l \mathbf{W}_l^{res}X^lWlres——由当前输入决定
- • 静态分量:Slres\mathbf{S}_l^{res}Slres——固定的偏置
- • 门控因子:αlres\alpha_l^{res}αlres——初始化为小值,让训练初期接近静态行为
创新:动态参数化的意义在于——不同输入需要不同的层间信息传递方式。 对于简单输入,可能只需要"直通"(类似普通残差连接);对于复杂输入,可能需要更精细的混合策略。 门控因子初始化为小值是一个重要的工程技巧,确保训练初期 mHC 接近恒等映射(不破坏已稳定的训练动态),随着训练推进逐渐增加动态调整的幅度。
对 A 和 C 的约束
- • Al=σ(A~l)\mathbf{A}_l = \sigma(\tilde{\mathbf{A}}_l)Al=σ(A~l):Sigmoid 确保非负且 ∈ (0, 1)
- • Cl=2σ(C~l)\mathbf{C}_l = 2\sigma(\tilde{\mathbf{C}}_l)Cl=2σ(C~l):Sigmoid 后乘 2,范围 ∈ (0, 2)
为什么 C 的范围是 (0, 2)? 允许 C 略大于 1,使层输出在必要时可以"放大"残差流中的某些分量。这是一个设计选择——如果也限制到 (0, 1),模型可能缺乏足够的表达能力。
mHC 的总开销:论文报告 mHC 的墙钟时间开销仅为流水线阶段的 6.7%,非常轻量。
早在2月份,有猜测DS在官网灰度了mHC训练的模型:春节前这波“偷袭”!DeepSeek 没官宣,但偷偷点了什么技能?。
当时有朋友反馈:“1M是很爽,反应速度也是超快。但是性情大变。写作风格也完全不一样了。比较郁闷。还挑我毛病说我打字打错了,还阴阳我。“
现在正式官宣,应该是解决了创新后带来的问题。
混合注意力:CSA + HCA
最核心的创新。
问题背景
标准自注意力的计算复杂度:
FLOPs∝n⋅n⋅d=n2d\text{FLOPs} \propto n \cdot n \cdot d = n^2 dFLOPs∝n⋅n⋅d=n2d
其中 nnn 是序列长度,ddd 是头维度。当 n=106n = 10^6n=106(百万 Token)时,这个数字大得无法承受。此外,KV 缓存的内存占用也线性增长:O(n⋅d)O(n \cdot d)O(n⋅d)。
已有方案及其局限:
方案 | 思路 | 局限 |
|---|---|---|
稀疏注意力(如 Longformer) | 每个 Token 只关注局部窗口 | 丢失长程依赖 |
线性注意力(如 Linformer) | 用低秩近似替代完整注意力 | 精度损失较大 |
FlashAttention | 优化注意力计算的内存访问 | 不改变计算复杂度 |
分块注意力(如 NSA) | 分块+稀疏选择 | 压缩率有限 |
DeepSeek-V4 的方案是两级压缩:
CSA(轻度压缩 + 稀疏选择)和 HCA(重度压缩 + 稠密注意力),交替使用。
压缩稀疏注意力(CSA)
CSA 的流水线:压缩 → 索引选择 → 核心注意力
第 1 步:压缩键值条目
CSA 计算两组 KV 条目 Ca,Cb\mathbf{C}_a, \mathbf{C}_bCa,Cb 及对应压缩权重 Za,Zb\mathbf{Z}_a, \mathbf{Z}_bZa,Zb。然后每 mmm 个 Token 的 KV 条目根据压缩权重加权合并为一个"压缩条目"。
概念:为什么要两组 KV(a 和 b)? 这是 CSA 的一个精巧设计——重叠压缩。每个压缩条目 CiComp\mathbf{C}^{Comp}_iCiComp 不仅来自第 mimimi 到第 m(i+1)−1m(i+1)-1m(i+1)−1 个 Token 的 Ca\mathbf{C}_aCa,还来自第 m(i−1)m(i-1)m(i−1) 到第 mi−1mi-1mi−1 个 Token 的 Cb\mathbf{C}_bCb。也就是说,相邻压缩条目之间有 mmm 个 Token 的信息重叠。
创新:重叠压缩解决了"硬边界"问题。 如果不重叠,第 mmm 个和第 m+1m+1m+1 个 Token 虽然在原文中相邻,却被分到了不同的压缩块,信息联系被人为切断。 重叠让边界处的信息得以保留,减少了压缩带来的信息损失。 实际压缩率为 1m\frac{1}{m}m1(因为每个压缩条目覆盖 2m2m2m 个原始 Token,但相邻条目共享 mmm 个,所以净压缩是 mmm 个原始 Token → 1 个压缩条目)。
概念:压缩权重 Z\mathbf{Z}Z。 不是简单地取平均,而是让模型学习"哪些 Token 更重要,应该在压缩条目中占更大权重"。Softmax 归一化确保权重和为 1。 可学习的位置偏置 B\mathbf{B}B 让模型能考虑位置信息(例如,一个压缩块中间的 Token 可能比边缘的更重要)。
第 2 步:闪电索引器(Lightning Indexer)用于稀疏选择
压缩后,序列长度从 nnn 降到 nm\frac{n}{m}mn。但 nm\frac{n}{m}mn 仍然可能很大(百万 Token / 4 = 25 万)。
CSA 进一步用闪电索引器做稀疏选择,只保留 top-k 个最相关的压缩条目。
索引器的核心计算:
It,s=∑h=1nhIwt,hI⋅ReLU(qt,hI⋅KI,sComp)I_{t,s} = \sum_{h=1}^{n_h^I} \mathbf{w}^I_{t,h} \cdot \text{ReLU}(\mathbf{q}^I_{t,h} \cdot \mathbf{K}^{Comp}_{I,s})It,s=h=1∑nhIwt,hI⋅ReLU(qt,hI⋅KI,sComp)
概念拆解:
- • qt,hI\mathbf{q}^I_{t,h}qt,hI:查询 Token ttt 的第 hhh 个索引器头的查询向量
- • KI,sComp\mathbf{K}^{Comp}_{I,s}KI,sComp:第 sss 个压缩块的索引器键
- • ReLU(⋅)\text{ReLU}(\cdot)ReLU(⋅):与标准注意力的 Softmax 不同,这里用 ReLU 产生非负的相似度分数
- • wt,hI\mathbf{w}^I_{t,h}wt,hI:可学习的头权重,让不同头的贡献可以不同
- • It,sI_{t,s}It,s:Token ttt 与压缩块 sss 的索引分数
创新分析:闪电索引器与标准注意力有几个关键区别:① 用 ReLU 而非 Softmax——不需要对所有块分配概率,只关心"哪些块足够相关";② 多头 + 加权聚合——比单头的点积更灵活;③ 低秩设计——查询先压缩到 dcd_cdc 维再升维,大幅减少参数量。
概念:低秩设计。查询 Token 先通过 WDQ\mathbf{W}^{DQ}WDQ 降维到 dcd_cdc(查询压缩维度),再通过 WIUQ\mathbf{W}^{IUQ}WIUQ 升维到索引器查询。这比直接从 ddd 维映射到 cI⋅nhIc_I \cdot n_h^IcI⋅nhI 维的参数量少得多(d⋅dc+dc⋅cInhId \cdot d_c + d_c \cdot c_I n_h^Id⋅dc+dc⋅cInhI vs d⋅cInhId \cdot c_I n_h^Id⋅cInhI,当 dc≪dd_c \ll ddc≪d 时差距显著)。而且这个低秩表示在后续的注意力查询中复用,一举两得。
第 3 步:共享键值多查询注意力(Shared-KV MQA)
选好 top-k 压缩条目后,执行核心注意力。
这里有一个重要设计:压缩 KV 条目同时充当 Key 和 Value(MQA 模式)。
概念:MQA(Multi-Query Attention)。标准多头注意力中,每个头有独立的 K 和 V。MQA 中,所有头共享同一组 K 和 V,只有 Q 是每个头独立的。这大幅减少了 KV 缓存的大小——在推理时,不需要为每个头存一份 KV。
创新分析:在 CSA 中使用共享 KV 的 MQA 是一个自然的选择——压缩条目已经是信息的浓缩版本,让不同头共享同一组浓缩信息,同时用各自的查询向量去"解读"它,既节省内存又不损失太多表达能力。
第 4 步:分组输出投影
注意力输出 ot∈Rcnh\mathbf{o}_t \in \mathbb{R}^{c n_h}ot∈Rcnh 的维度可能很大(c=512,nh=64c=512, n_h=64c=512,nh=64 → 32768 维)。
直接投影到 ddd 维(7168)计算量大。
分组策略:把 nhn_hnh 个头分成 ggg 组,每组先投影到 dgd_gdg 维中间表示(dg<cnhgd_g < \frac{c n_h}{g}dg<gcnh),再合并投影到 ddd 维。
创新:这是对标准注意力输出投影的"瓶颈"优化。 本质上是在输出投影中插入了一个低秩瓶颈——先降维再合并升维。在注意力头数很多时效果显著。
重度压缩注意力(HCA)
HCA 与 CSA 的核心区别:
CSA | HCA | |
|---|---|---|
压缩率 | m=4m = 4m=4 | m′=128m' = 128m′=128 |
压缩后是否稀疏选择 | 是(top-k) | 否(全量注意力) |
KV 组数 | 2(a、b,重叠压缩) | 1(无重叠) |
定位 | "精读"——保留更多细节 | "泛读"——极端压缩换速度 |
创新:为什么 HCA 不做稀疏选择? 因为 m′=128m' = 128m′=128 的压缩率已经把序列长度降到了原来的 1128\frac{1}{128}1281——百万 Token 只剩约 7800 个压缩条目。 这个量级已经足够小,全量注意力的计算量可接受,而且全量注意力能避免稀疏选择可能遗漏的重要信息。
CSA 和 HCA 交替使用的动机:不同层需要不同粒度的长程信息。 浅层可能只需要大致的背景上下文(用 HCA),深层需要更精确的相关信息(用 CSA)。 这种"粗细搭配"的设计兼顾了效率和精度。
其他设计细节
查询和 KV 条目归一化
在核心注意力之前,对查询的每个头和 KV 条目的唯一头额外做 RMSNorm。
动机:防止注意力 logits(即 q⋅k\mathbf{q} \cdot \mathbf{k}q⋅k 的值)爆炸。当向量范数很大时,点积值可能非常大,导致 Softmax 输出接近 one-hot(注意力坍缩到单个位置),梯度消失。RMSNorm 把向量归一化到单位范数附近,有效防止了这个问题。
创新之处:正因为可以直接在查询和 KV 上做 RMSNorm,DeepSeek-V4 不需要在 Muon 优化器中使用 QK-Clip 技术(一种额外的裁剪策略)。这是架构设计和优化器选择的协同——架构层面解决了问题,优化器层面就不需要补丁。
部分旋转位置编码(RoPE)
只对查询和 KV 向量的最后 64 维应用 RoPE,其余维度不加位置编码。
概念:RoPE(Rotary Position Embedding)。RoPE 通过旋转向量来编码位置信息——相同位置的两个向量内积最大,距离越远内积越小。这是目前最流行的位置编码方案。
创新分析:部分 RoPE 是一个重要设计。在 CSA/HCA 中,KV 条目同时充当 Key 和 Value。如果对整个向量加 RoPE,那么注意力输出(Value 的加权和)会携带绝对位置信息,这不是我们想要的——我们希望输出携带的是相对位置信息。解决方案:① 只在部分维度加 RoPE,未加的部分不携带位置信息;② 对注意力输出也应用反向 RoPE,"抵消"掉绝对位置编码,留下相对位置编码。
滑动窗口附加分支
每个查询 Token 除了关注压缩 KV 条目外,还额外关注最近的 nwin=128n_{win} = 128nwin=128 个未压缩 Token。
动机:压缩过程不可避免地丢失局部细节。而语言建模中,紧邻的上下文通常最重要。滑动窗口分支保证了局部信息的完整保留——无论压缩多么激进,"眼前"的内容一定是原汁原味的。
注意力锚点(Attention Sink)
引入可学习的汇聚 logits {z1′,…,znh′}\{z'_1, \ldots, z'_{n_h}\}{z1′,…,znh′},加到 Softmax 分母上:
sh,i,j=Exp(zh,i,j)∑kExp(zh,i,k)+Exp(zh′)s_{h,i,j} = \frac{\text{Exp}(z_{h,i,j})}{\sum_k \text{Exp}(z_{h,i,k}) + \text{Exp}(z'_h)}sh,i,j=∑kExp(zh,i,k)+Exp(zh′)Exp(zh,i,j)
概念:注意力锚点。这个技术最初由 StreamingLLM 提出。问题场景:在流式推理中,当上下文不断增长时,注意力分布可能出现异常——第一个 Token 或某些特定位置吸引大量注意力(成为"汇聚点"),如果强制逐出这些 Token,模型输出会崩溃。锚点通过给每个头一个可学习的"垃圾桶"选项,让模型可以把不需要的注意力分配给锚点,而不是强制分配给某个真实 Token。
创新分析:在压缩注意力场景下,注意力锚点还有另一个好处——它允许注意力分布的总和小于 1(因为分母多了 Exp(zh′)\text{Exp}(z'_h)Exp(zh′)),模型可以"选择不关注"某些压缩块,这对稀疏注意力更自然。
效率总结
以 BF16 GQA8(头维度 128)为基线,DeepSeek-V4 的 KV 缓存仅为基线的约 2%。
成果:2% 这个数字令人震撼。 百万 Token 下,GQA8 基线的 KV 缓存约 106×128×2×210^6 \times 128 \times 2 \times 2106×128×2×2(层数×头维度×K+V×BF16 字节)≈ 数百 GB。 V4 降至约 2% 即数 GB——这从"放不进 GPU 内存"变成了"放得下",是质变而非量变。
Muon 优化器
背景
AdamW 是当前最主流的优化器,
核心思想是:对每个参数维护一阶动量和二阶动量(梯度的移动平均和梯度平方的移动平均),自适应地调整每个参数的学习率。
Muon 的思路完全不同:对梯度矩阵做正交化,强制每次更新的方向互相垂直。
Muon 的算法
对每个权重 W ∈ R^(n×m):
1. G_t = 计算梯度
2. M_t = μM_{t-1} + G_t // 累积动量
3. O'_t = HybridNewtonSchulz(μM_t + G_t) // Nesterov + 正交化
4. O_t = O'_t · √max(n,m) · γ // 重缩放
5. W_t = W_{t-1}·(1-ηλ) - ηO_t // 权重衰减 + 更新概念:正交化。 给定矩阵 M=UΣVT\mathbf{M} = \mathbf{U}\Sigma\mathbf{V}^TM=UΣVT(SVD 分解),正交化是指求 UVT\mathbf{U}\mathbf{V}^TUVT——去掉奇异值的影响,只保留方向信息。 Newton-Schulz 迭代是一种近似正交化的方法,不需要显式做 SVD。
概念:Nesterov 技巧。 标准动量用 μMt−1+Gt\mu M_{t-1} + G_tμMt−1+Gt 计算更新方向。Nesterov 改为 μMt+Gt=μ(μMt−1+Gt)+Gt\mu M_t + G_t = \mu(\mu M_{t-1} + G_t) + G_tμMt+Gt=μ(μMt−1+Gt)+Gt——"先往前看一步,再决定方向"。 这通常比标准动量收敛更快。
混合 Newton-Schulz 迭代
两个阶段:
- • 前 8 步:系数 (3.4445,−4.7750,2.0315)(3.4445, -4.7750, 2.0315)(3.4445,−4.7750,2.0315)——快速逼近正交
- • 后 2 步:系数 (2,−1.5,0.5)(2, -1.5, 0.5)(2,−1.5,0.5)——精确稳定在正交
创新:单一系数的 Newton-Schulz 迭代在收敛速度和精度之间有 trade-off——激进系数收敛快但可能振荡,保守系数稳定但慢。 混合策略是两全其美:先用激进系数快速逼近,再切换到保守系数做精修。 这种"粗调+精调"的思想在优化算法中很常见(如学习率预热+余弦退火),但具体应用到 Newton-Schulz 迭代上是新的。
哪些用 Muon,哪些用 AdamW?
- • Muon:大部分权重(MoE 专家、注意力投影等矩阵参数)
- • AdamW:嵌入层、预测头、mHC 静态偏置/门控因子、RMSNorm 权重
创新:Muon 适合矩阵参数(因为正交化操作是矩阵级的),不适合向量参数(如偏置)或低维参数(如 RMSNorm 的缩放因子)。 这个分配策略是合理的。
基础设施
架构创新决定了理论上限,工程实现决定了能否落地。
DeepSeek-V4 的基础设施工作有两个特点:全栈自研和软硬件协同设计。
专家并行中的细粒度通信-计算重叠
问题
MoE 的专家并行(Expert Parallelism, EP)中,Token 需要在 GPU 之间传送(Dispatch),计算完后还需要传回(Combine)。
通信和计算如果串行执行,通信延迟会严重拖慢整体速度。
基本事实
在单个 MoE 层内,通信总时间 < 计算总时间。
这意味着如果把通信和计算重叠(流水线化),计算始终是瓶颈,通信可以被"隐藏"。
细粒度波次调度
把专家分成小波次(wave),每个波次:
- • 当前波次的 Token 正在被计算
- • 下一波次的 Token 正在被传输(Dispatch)
- • 上一波次的结果正在被发回(Combine)
三件事同时进行,形成细粒度流水线。
创新:粗粒度重叠(整个 MoE 层级)的问题是需要等待所有专家完成通信后才能开始计算,长尾延迟严重。 细粒度波次调度把等待粒度从"整个层"降到"一小波专家",大幅减少了空闲时间。 这对 RL rollout 等小批量场景尤其重要(小批量下长尾效应更严重)。
给硬件厂商的建议
论文喊话硬件厂家四条非常务实的建议:
- 1. 计算-通信比比绝对带宽更重要:论文推导了通信可完全隐藏的充要条件 C/B≤Vcomp/VcommC/B \leq V_{comp}/V_{comm}C/B≤Vcomp/Vcomm。
- 对于 V4-Pro,这个阈值是 6144 FLOPs/Byte,即每 GBps 带宽可隐藏 6.1 TFLOP/s 计算。超过这个阈值再增加带宽只是浪费硅片面积。
- 2. 功耗预算:极致内核融合让计算、内存、网络同时满负荷,GPU 可能撞功耗墙而降频。建议硬件设计为这种全并发场景预留功耗余量。
- 3. 通信原语:当前硬件的跨 GPU 通知延迟太高,只能用"拉取"模式。如果未来硬件能提供更低延迟的信令机制,"推送"模式会更自然高效。
- 4. 激活函数:SwiGLU 涉及指数运算(Sigmoid 门控)和逐元素乘法,是 GEMM 后处理的性能负担。建议设计更简单的激活函数。
创新:这些建议反映了一个趋势——软件团队不再只是"适配硬件",而是主动向硬件团队提出需求。 这是软硬件协同设计的深化。 尤其第 1 条建议非常反直觉——业界普遍认为"带宽越多越好",但论文用数学证明了存在一个平衡点,超过它增加带宽的边际收益为零。
TileLang
TileLang 是一种用于编写高性能计算内核的领域特定语言(DSL)。
为什么需要自研 DSL? DeepSeek-V4 的架构包含大量非常规操作(CSA 压缩、闪电索引器、mHC 的 Sinkhorn 迭代等),这些操作在 PyTorch/CUDA 的标准算子库中没有对应实现。 用纯 CUDA 写太底层、开发效率低;用 PyTorch 写太高层、性能不够。TileLang 在两者之间找到了平衡。
三个关键特性:
- 1. 宿主代码生成:减少 CPU 端的内核启动开销(从数百微秒降到不到 1 微秒)
- 2. Z3 SMT 求解器:自动分析张量索引的形式整数约束,辅助编译器优化
- 3. 数值精度优先:默认禁用快速数学优化,确保逐位可复现性
批次不变性和确定性
概念:批次不变性——同一个 Token,无论它在批次中的第几个位置,输出必须逐位相同。
为什么这很重要? 标准 CUDA 内核为了最大化 GPU 利用率,会根据批次大小调整并行策略(如 split-KV 把一个序列的注意力计算分配到多个 SM 上)。 这导致同一个 Token 在不同批次大小下可能产生不同的数值结果。对于训练-推理一致性、调试和 A/B 测试,这是不可接受的。
DeepSeek 的解法:
- • 注意力:双内核策略(小批量用单 SM 内核,大批量用多 SM 内核,但保证结果一致)
- • 矩阵乘法:用 DeepGEMM 替换 cuBLAS
确定性训练:同样的输入和随机种子,训练过程产生完全相同的结果。
为什么需要确定性? 非确定性训练中,如果出现 loss spike,你无法判断是 bug 还是数值随机性导致的。 确定性训练让问题可复现、可调试。 代价是通常要牺牲一些性能(不能用原子操作,需要分配额外缓冲区)。 DeepSeek 通过独立累积缓冲区和确定性归约实现了确定性,且性能损失可控。
FP4 量化感知训练
量化感知训练(QAT):在训练过程中模拟量化带来的精度损失,让模型提前适应,这样部署时用低精度权重不会掉精度。
DeepSeek-V4 对两部分做 FP4 量化:
- 1. MoE 专家权重:FP32 主权重 → FP4 存储 → FP8 计算关键发现:FP4 → FP8 的反量化是无损的。因为 FP8(E4M3)比 FP4(E2M1)多 2 个指数位,动态范围更大。只要 FP4 量化后的值在 FP8 的可表示范围内,反量化就是精确的。这意味着 QAT 流水线可以完全复用 FP8 训练框架——训练时用 FP8,存储时用 FP4,中间无损转换。
- 2. CSA 索引器的 QK 路径:QK 激活以 FP4 存储、加载和相乘,加速长上下文下的注意力分数计算。
创新分析:FP4 用于索引器 QK 路径是一个巧妙的选择——索引器只负责"粗筛"(判断哪些压缩块相关),不需要高精度。用 FP4 加速这一步对最终精度影响极小,但能显著减少长上下文下的注意力计算量。
训练框架
几个关键适配:
- 1. Muon + ZeRO 的兼容:Muon 需要完整梯度矩阵做正交化,而 ZeRO 通过分片减少内存。
- DeepSeek 设计了混合 ZeRO 桶分配策略,并用量化梯度减半通信量。
- 2. mHC 的低成本实现:mHC 的动态参数化涉及大量小矩阵运算。通过融合内核 + 选择性检查点 + 调整 DualPipe 流水线,将开销限制在 6.7%。
- 3. 压缩注意力的上下文并行:传统 CP 按序列维度切分,但 CSA/HCA 的压缩操作跨边界。
- 两阶段通信:先传跨边界的未压缩 KV,再做全收集。
推理框架
异构 KV 缓存管理
DeepSeek-V4 的 KV 缓存包含多种类型:压缩 KV 条目(CSA/HCA)、未压缩尾部 Token、滑动窗口 Token、索引器键。每种类型大小不同、更新规则不同。
创新:传统推理框架的 KV 缓存是同构的(所有 Token 的 KV 条目大小相同),管理简单。 DeepSeek-V4 的异构 KV 缓存管理更复杂,但这是混合注意力架构的必然代价。 论文把 SWA 和未压缩尾部 Token 视为"状态空间模型"——大小固定、只取决于当前位置——从而可以预分配固定大小的缓存池,简化管理。
磁盘 KV 缓存存储
对于共享前缀的请求(如相同的系统提示词),把前缀的 KV 缓存存到磁盘,新请求直接复用。
三种 SWA 缓存策略:
- • 完整 SWA 缓存:零计算冗余,但存储密集
- • 周期性检查点:可调节的存储-计算权衡
- • 零 SWA 缓存:零存储,但需更多重计算
创新:这三种策略本质上是在存储和计算之间做 trade-off。实际部署中可以根据 GPU 内存大小和请求模式动态选择。
预训练数据构建
训练数据量:超过 32T Token(约 32 万亿)
数据构成:
- • 数学和编程语料:核心组成,决定了推理和编码能力的上限
- • 网页文本:过滤了 AI 生成的批量内容和模板化内容(缓解模型崩溃风险)
- • 多语言语料:扩大对不同文化长尾知识的覆盖
- • 长文档:科学论文、技术报告等反映独特学术价值的材料
- • 智能体数据:训练中期加入,增强编码和工具使用能力
模型崩溃(Model Collapse)。 如果训练数据中包含 AI 生成的文本,模型会在这些文本上"过拟合"到自己风格的输出,导致多样性下降、质量退化,形成正反馈循环。 过滤 AI 生成内容是当前预训练数据工程的标准做法。
创新:训练中期引入智能体数据是一个有意思的设计选择。 传统做法是在后训练阶段才引入特定能力的数据。 在预训练中期就引入智能体数据,意味着模型在预训练阶段就建立了编码和工具使用的基本能力,后训练只需要在此基础上强化。 这可能是 V4 在代码智能体任务上表现突出的原因之一。
模型配置
DeepSeek-V4-Pro 的关键配置:
配置项 | 值 | 设计考量 |
|---|---|---|
层数 | 61 | 更深 → 更强的层级表示 |
隐藏维度 | 7168 | 更宽 → 更大的表示容量 |
路由专家数 | 384 | 更多专家 → 更细的知识分工 |
每专家中间维度 | 3072 | 每个专家的计算量 |
每 Token 激活专家数 | 6 | 平衡计算成本和能力 |
CSA 压缩率 | 4 | 每 4 个 Token 压缩为 1 个 |
HCA 压缩率 | 128 | 每 128 个 Token 压缩为 1 个 |
滑动窗口 | 128 | 保留最近 128 个 Token 的完整信息 |
训练稳定性
这是大模型训练中最"痛苦"的部分。
问题:训练万亿参数 MoE 模型时,会随机出现 loss spike(损失突然飙升),导致模型输出崩溃。
简单回滚可以临时恢复,但不能防止再次发生。
根因分析:loss spike 与 MoE 层的异常值相关,路由机制会加剧异常值的产生,形成恶性循环。
前瞻路由(Anticipatory Routing)
核心思想:在步骤 ttt,用参数 θt\theta_tθt 做特征计算,但路由索引用上一步的参数 θt−Δt\theta_{t-\Delta t}θt−Δt 计算。
为什么"滞后"的路由反而更好? 想象路由和骨干网络是两个互动的系统。如果它们同步更新,可能形成正反馈循环——异常路由 → 异常特征 → 更异常的路由。 把路由更新"滞后"一步,就打破了这种同步耦合,异常值来不及被路由放大就被下一步的更新修正了。
创新:前瞻路由的本质是解耦路由决策和特征计算的时间尺度。 这和控制系统中的"采样-保持"策略类似——在控制信号更新时保持执行器不变,避免高频振荡。 论文报告这个技巧以可忽略的开销避免了 loss spike,且不影响最终性能。
SwiGLU 截断
对 SwiGLU 激活函数的输出做硬截断:线性分量限制在 [-10, 10],gate 分量上限 10。
意外:这个技巧非常"工程化"——没有优雅的数学推导,就是发现超过某个阈值的激活值是异常的、有害的,直接截掉。 但效果确实好。这也反映了当前大模型训练的一个现实:我们对训练动态的理解还远远不够,很多有效的方法是经验性的。
后训练流程
总体框架:专家训练 → 在线策略蒸馏
这是一个两阶段范式:
第一阶段:训练多个领域专家(数学、编码、智能体、指令遵循等)。每个专家 = 监督微调(SFT)+ 强化学习(GRPO)。
第二阶段:通过在线策略蒸馏(OPD)把所有专家的能力整合到一个统一模型中。
我们在使用模型时,感觉到模型在解题,写代码,复杂任务多步骤执行方面有所提升,
相对于早期就只会对话不可同日而语,就是后训练阶段的功劳。
概念对比:OPD vs 传统方法
方法 | 思路 | 局限 |
|---|---|---|
权重合并 | 多个专家权重的加权平均 | 不同专家的参数空间不对齐,合并后性能退化 |
混合 RL | 所有领域的奖励信号混合训练 | 不同领域的奖励可能冲突 |
OPD | 学生在自己生成的轨迹上学习教师的输出分布 | 计算成本高,但效果最好 |
专家训练
推理力度(Reasoning Effort):三个模式
模式 | 特征 | 温度 | 上下文窗口 |
|---|---|---|---|
Non-think | 直觉响应,无显式推理 | 1.0 | 8K |
Think | 有意识的推理过程 | 1.0 | 128K |
Think Max | 推理推到极致 | 1.0 | 384K |
推理力度。这个概念对应的是"测试时计算量"的分配策略。 Non-think 模式几乎不花额外计算在推理上,直接给答案; Think 模式允许模型花更多 Token 思考; Think Max 强制模型做最详尽的推理。 这和 OpenAI o1/o3 的 low/medium/high reasoning effort 是同一思路,但 DeepSeek 把它做成了三个独立训练的专家,而非通过单一模型的温度/长度控制实现。
创新:三个模式分别训练专家,而非用同一个模型调节参数,这意味着每个模式都可以独立优化到最佳状态。 Think Max 的专家在 RL 训练时用了更大的长度惩罚和上下文窗口,确保它能在长推理链上稳定优化。 这种"分治"策略比"一刀切"更灵活。
生成式奖励模型(GRM):
传统 RLHF 流程:训练一个标量奖励模型(人类标注的偏好数据)→ 用奖励模型指导策略优化。
DeepSeek-V4 的做法:不训练标量奖励模型,而是用生成式奖励模型——让模型自己生成评估判断,然后对 GRM 本身也做 RL 优化。
感觉这才是模型自己训练自己,比GPT-5.5官方稿里提到用GPT-5.4优化了某个步骤的算法,是模型自己训练自己,差距立判。
创新:标量奖励模型有两个问题: ① 需要大量人工标注;② 标量分数信息量有限(只知道"好/坏"的程度,不知道"为什么好/为什么坏")。 GRM 让模型生成详细的评估理由,信息量远大于一个分数。 更关键的是,GRM 本身也通过 RL 优化——模型同时在学习"做题"和"批改",两种能力互相促进。
交错思考(Interleaved Thinking):
V3.2:新用户消息到达时丢弃之前的思考痕迹 → 每轮从零开始推理
V4:工具调用场景下保留所有思考痕迹 → 跨轮次累积推理
创新分析:这个优化只有在百万 Token 上下文窗口下才有意义——之前的模型"想保留也保留不了"(上下文窗口不够大)。V4 的长上下文能力使得"保留所有思考"成为可能,这是架构能力解锁新应用模式的典型案例。
快速指令(Fast Instructions):
把辅助任务(意图识别、搜索触发等)编码为特殊 Token,附加到输入序列中,复用已有的 KV 缓存。
创新分析:传统做法是调用独立的小模型做辅助判断,需要重新预填充输入(冗余计算)。快速指令把辅助任务嵌入到主模型的推理过程中,零额外预填充开销。这是"统一模型做所有事"vs"多模型协作"两种范式的折中——用同一个大模型,但通过特殊 Token 触发不同行为模式。
在线策略蒸馏(OPD)
数学公式:
LOPD(θ)=∑i=1Nwi⋅DKL(πθ∥πEi)\mathcal{L}_{OPD}(\theta) = \sum_{i=1}^{N} w_i \cdot D_{KL}(\pi_\theta \| \pi_{E_i})LOPD(θ)=i=1∑Nwi⋅DKL(πθ∥πEi)
逆 KL 散度 DKL(πθ∥πEi)D_{KL}(\pi_\theta \| \pi_{E_i})DKL(πθ∥πEi)。KL 散度衡量两个分布的差异。注意这里学生 πθ\pi_\thetaπθ 在前(逆 KL),而非教师 πEi\pi_{E_i}πEi 在前(正 KL)。 逆 KL 是"模式寻求"(mode-seeking)——学生倾向于精确匹配教师的某个模式; 正 KL 是"模式覆盖"(mode-covering)——学生试图覆盖教师的所有模式,可能分散注意力。 在蒸馏场景下,逆 KL 让学生更专注于教师最擅长的领域。
"在线策略"。 学生模型从自己生成的轨迹上学习(而非从固定的数据集上学习)。 这意味着学生的训练数据分布与其当前策略一致,避免了分布偏移问题。
完整词汇表 logit 蒸馏:
先前工作通常把完整词汇表的 KL 损失简化为 Token 级估计(只采样一个 Token 计算 KL),节省计算但梯度方差高。
DeepSeek-V4 保留完整 logit 分布计算 KL 损失,梯度更稳定。
创新:这是一个"精度换效率"的经典 trade-off。 DeepSeek 选择了精度——因为他们有十多个教师模型,高方差的梯度估计在多教师场景下会放大不稳定性。 完整词汇表蒸馏的计算成本更高,但换来了更稳定的训练和更忠实的知识传递。
RL 和 OPD 基础设施
几个值得关注的工程创新:
可抢占 Rollout 服务:
GPU 集群使用可抢占调度器,高优先级任务可以抢占低优先级任务的 GPU。
为防止生成请求被中断后丢失进度,实现了 Token 粒度的预写日志(WAL)——每生成一个 Token 就立即写入 WAL,被抢占后可以从最后一个完成的 Token 恢复。
DSec 沙箱平台:
用 Rust 写的三个组件(API 网关、主机代理、集群监控器),管理数十万个并发沙箱实例。
这是评估代码智能体和训练工具使用能力的必要基础设施——模型生成的代码需要在安全的隔离环境中执行和验证。
创新:DSec 的规模(数十万并发沙箱)反映了当前 RL 训练对执行环境的需求量级。 每个 RL rollout 可能涉及多次工具调用和代码执行,成千上万的并行 rollout 需要同样数量级的沙箱实例。 这是后训练基础设施中容易被忽视但至关重要的环节。
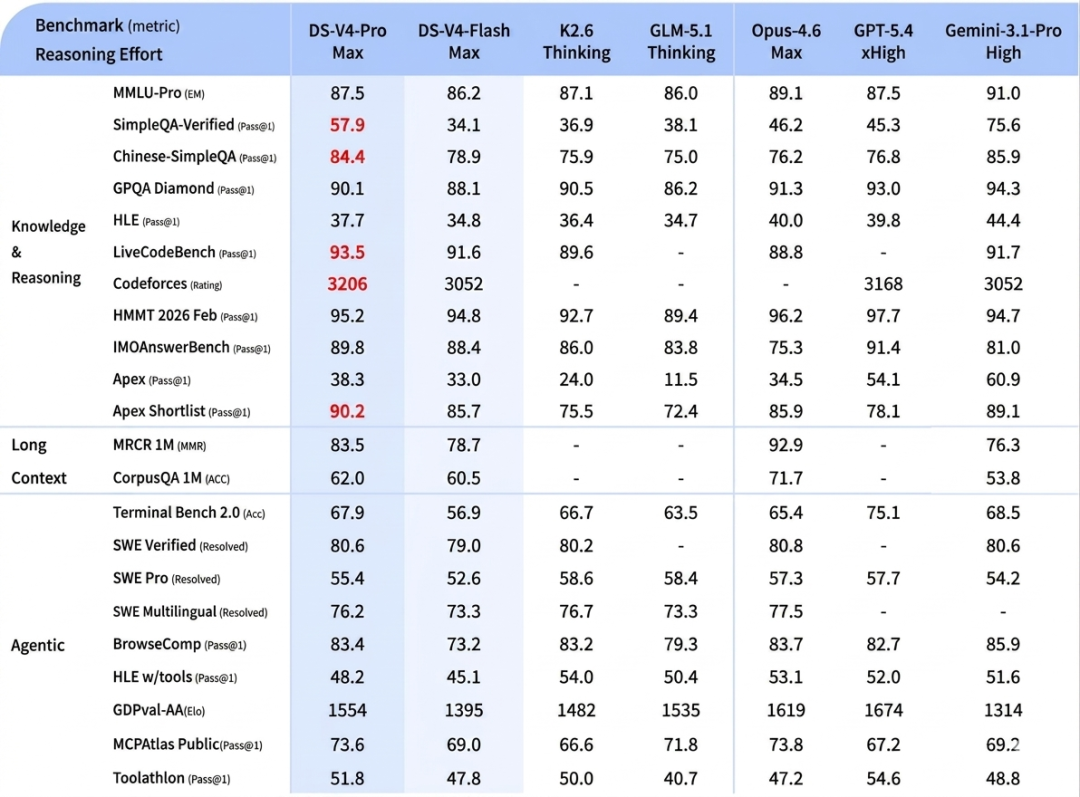
核心基准结果
知识维度:
基准 | V4-Pro Max | 最强闭源(Gemini-3.1-Pro) | 差距 |
|---|---|---|---|
SimpleQA-Verified | 57.9 | 75.6 | -17.7 |
Chinese-SimpleQA | 84.4 | 85.9 | -1.5 |
MMLU-Pro | 87.5 | 91.0 | -3.5 |
推理维度:
基准 | V4-Pro Max | 表现 |
|---|---|---|
Codeforces Rating | 3206 | 开源首次匹敌闭源,人类选手排名第 23 |
LiveCodeBench | 93.5 | 超越所有对手(包括闭源) |
HMMT 2026 Feb | 95.2 | 竞赛数学顶级水平 |
Apex Shortlist | 90.2 | 所有模型中最高 |
结论:知识维度与闭源的差距仍然明显(尤其是 SimpleQA-Verified 差了 17.7 个百分点),这反映了训练数据质量和知识密集度的差距。 但在推理维度,DeepSeek-V4- Pro Max 已经非常接近甚至在某些任务上超越了闭源模型。 这说明推理能力更多取决于架构和训练方法,而知识能力更多取决于数据。
百万 Token 上下文:
- • MRCR 1M:83.5(超越 Gemini-3.1-Pro 的 76.3,仅次于 Opus 4.6 的 92.9)
- • 检索性能在 128K 内高度稳定,128K 后有下降但百万 Token 处仍强劲
结论:128K 内的稳定性说明 CSA/HCA 的压缩在中等长度下几乎没有精度损失。 128K 后的下降是预期的——压缩率越高,信息损失越大,越长的上下文积累越多损失。 但整体水平仍然非常强,证明混合注意力方案的有效性。
再放一下官方公布榜单测试的成绩,红色是领先的领域。
Agent 和推理能力大幅提升,达到领先水平。
这个方向跟 GLM-5.1 更新时技术团队的思路是一致的:让大模型能真实的干活:
8小时从零构建Linux桌面 |最强开源模型 GLM-5.1
真实世界任务
中文写作:功能写作胜率 62.7% vs Gemini-3.1-Pro 34.1%
白领任务:不败率 63% vs Opus-4.6-Max
代码智能体:超越 Sonnet 4.5,接近 Opus 4.5
教授点评:标准化基准和真实世界表现之间总是有 gap。DeepSeek 的内部指标(中文写作、白领任务、代码智能体)更能反映产品的实际用户体验。这些指标上 V4-Pro 的表现比标准化基准更亮眼,可能是因为:① 后训练的 OPD 流程更偏重实用性而非刷榜;② 中文场景的优化更充分。
核心贡献总结
- 1. CSA + HCA 混合注意力:首个在百万 Token 上下文下实现 90%+ KV 缓存压缩的实用方案
- 2. mHC:解决了超连接在深层堆叠时的不稳定性问题,为残差连接的升级提供了可行路径
- 3. Muon 优化器:在大规模 MoE 训练中验证了矩阵级正交化的有效性
- 4. 全栈工程优化:从内核到框架到推理部署,每个环节都有创新
局限
- 1. 架构复杂度高:CSA + HCA + mHC + MoE + MTP + 滑动窗口 + 注意力锚点……组件太多,不够优雅
- 2. 训练稳定性的原理未明:前瞻路由和 SwiGLU 截断是经验性的,缺乏理论解释
- 3. 知识维度仍有差距:与最先进的闭源模型在事实性知识上差距明显
未来方向
- 1. 架构精简——将复杂设计提炼到最核心的形式
- 2. 新维度的稀疏性——如稀疏嵌入
- 3. 低延迟长上下文——让百万 Token 交互更实时
- 4. 长程多轮智能体任务
- 5. 多模态能力
- 6. 更好的数据策展和合成策略
总结: DeepSeek-V4 的核心方法论是以长上下文效率为北极星指标,围绕它做架构-优化-工程的协同创新。 这种"一个核心问题驱动全栈创新"的研究范式值得学习。 同时,论文坦诚地承认了架构复杂性和理论理解不足的问题。
附录:核心概念索引
概念 | 定义 |
|---|---|
MoE | 混合专家模型,每个 Token 只激活部分专家 |
MTP | 多 Token 预测,同时预测未来多个 Token |
HC | 超连接,扩展残差流宽度并用可学习矩阵混合 |
mHC | 流形约束超连接,将 HC 的残差映射约束到双随机矩阵流形 |
Birkhoff 多面体 | 双随机矩阵的集合,行/列和为 1 且元素非负 |
Sinkhorn-Knopp | 交替行列归一化算法,用于投影到双随机矩阵流形 |
CSA | 压缩稀疏注意力,轻度压缩 + top-k 稀疏选择 |
HCA | 重度压缩注意力,极端压缩 + 稠密注意力 |
闪电索引器 | CSA 中的稀疏选择模块,用多头 ReLU 点积计算索引分数 |
MQA | 多查询注意力,所有头共享 KV |
RoPE | 旋转位置编码,通过旋转向量编码位置信息 |
注意力锚点 | 可学习的汇聚 logits,允许注意力分布总和小于 1 |
Muon | 矩阵正交化优化器,对梯度做 Newton-Schulz 正交化 |
Newton-Schulz | 近似正交化的迭代算法,无需显式 SVD |
EP | 专家并行,将 MoE 专家分布到不同 GPU |
QAT | 量化感知训练,在训练中模拟量化精度损失 |
FP4 | 4 位浮点数格式,MXFP4 子字节格式 |
GRPO | 组相对策略优化,DeepSeek 的 RL 算法 |
GRM | 生成式奖励模型,用生成式判断替代标量打分 |
OPD | 在线策略蒸馏,学生从自己的轨迹上学习教师的分布 |
逆 KL 散度 | 模式寻求的 KL 散度方向,适合蒸馏 |
前瞻路由 | 用上一步的路由决策指导当前步的计算,解耦路由和特征更新 |
SwiGLU 截断 | 对 SwiGLU 激活值做硬截断,防止异常值 |
DSec | DeepSeek 弹性计算沙箱平台 |
论文地址:
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号