EUPE + YOLO26:轻量化工业检测新思路

EUPE + YOLO26:轻量化工业检测新思路

javpower
发布于 2026-04-28 13:18:43
发布于 2026-04-28 13:18:43
EUPE + YOLO26:轻量化工业检测新思路
在工业检测场景里,大图小目标这个问题几乎无处不在。焊点缺陷、PCB 焊线、精密零件表面划痕——目标可能只占图片的几百甚至几十个像素。
之前的 DINOv3 + YOLO26 方案解决了一部分问题。但今天想聊聊另一个选择:EUPE + YOLO26。

PCB AOI 工业视觉检测:焊点、缺陷检测是大图小目标的典型场景
PCB AOI 工业视觉检测:焊点、缺陷检测是大图小目标的典型场景
什么是 EUPE?
EUPE 是 Meta 在 2026 年初放出来的 Efficient Universal Perception Encoder(arXiv:2603.22387)。名字听着复杂,核心就一句话:一个编码器,多种任务都能用。
EUPE 的核心原理:先放大,再缩小
这是 EUPE 和传统蒸馏方法最大的区别。
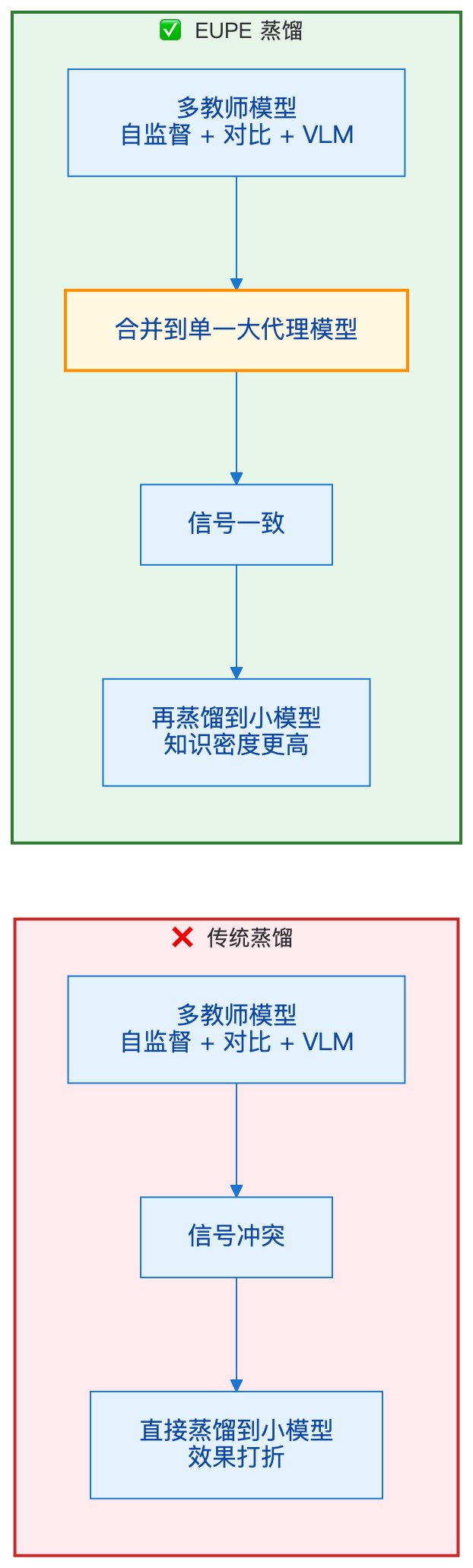
具体来说,EUPE 蒸馏自多个领域专家模型:
- 自监督视觉特征(类似 DINOv3)
- 对比学习特征(类似 SigLIP)
- VLM 语义对齐特征
这些知识先合并到一个大代理模型,再通过精心设计的蒸馏策略压缩到小模型。
EUPE 的架构设计
EUPE 基于标准 ViT,但有几处关键改进:
# EUPE-ViT-S 配置示例
embed_dim=384, depth=12, num_heads=6, ffn_ratio=4
n_storage_tokens=4, mask_k_bias=True
norm_layer="layernormbf16" # BF16 归一化
关键技术点:
- RoPE(Rotary Position Embedding)—— 更好的位置编码
- LayerScale —— 训练稳定性
- Storage Tokens(4个)—— 类似 DINOv3 的中间 token
- mask_k_bias —— attention mask 优化
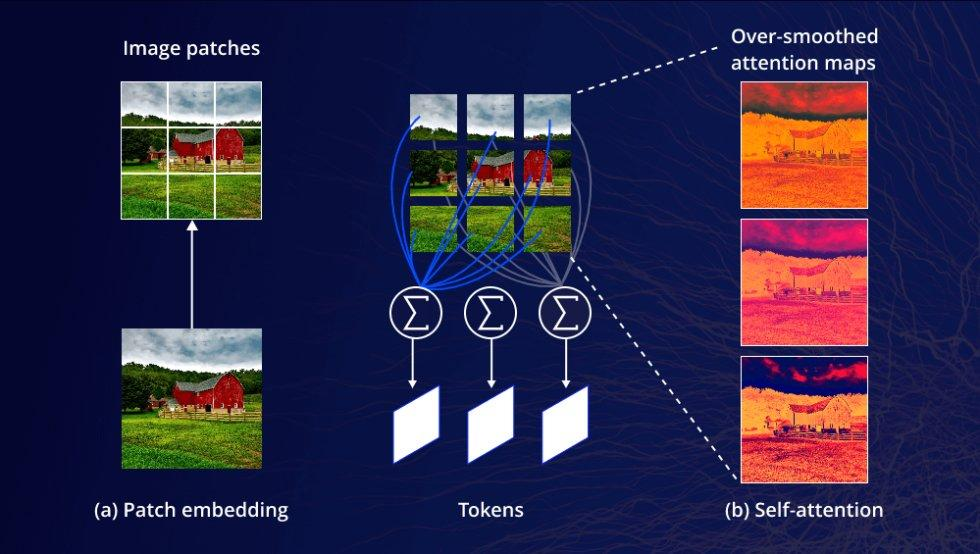
ViT Patch Embedding 原理:图像分块 → Token 化 → 自注意力计算
ViT Patch Embedding 原理:图像分块 → Token 化 → 自注意力计算
为什么 EUPE 的小模型也能很强?
普通 ViT-S(21M)从零训练,效果远不如 ViT-B(86M)。
但 EUPE-ViT-S 不同:它的大代理模型已经学会了如何压缩多任务知识到一个小的表示空间。相当于把"多任务能力"提前压缩进了小模型结构。
这就是为什么 EUPE-ViT-S(21M)能接近 ViT-B(86M)的原因——不是模型变大了,而是知识密度更高了。
模型规模对比
模型 | 参数量 | 特点 |
|---|---|---|
EUPE-ViT-T | 6M | 极致轻量,边缘部署首选 |
EUPE-ViT-S | 21M | 平衡之选,推荐 |
EUPE-ViT-B | 86M | 高精度,和 DINOv3 同级别 |
对比竞品:
- DINOv3:ViT-S 效果一般,需要 ViT-B(86M)才够看
- 单 YOLO26:无预训练,需要大量数据
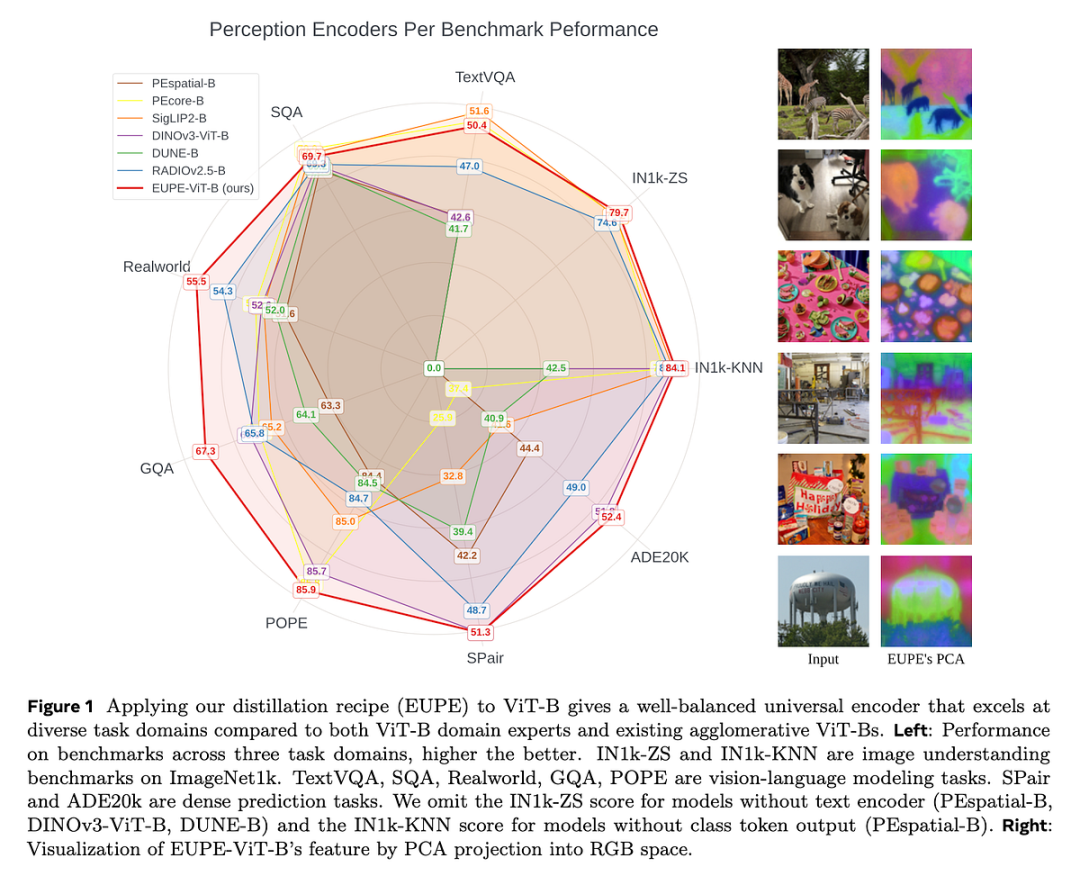
EUPE 性能雷达图:在多个基准任务上达到均衡的强表现
EUPE 性能雷达图:在多个基准任务上达到均衡的强表现
为什么 EUPE 可能更适合工业检测?
1. 语义特征更强
DINOv3 是纯自监督,特征空间偏向几何/纹理。但工业缺陷检测有时候需要语义理解——比如判断"这是划痕还是压痕",纯几何特征有时候不够用。
EUPE 继承的 SigLIP 对比学习信号,让特征空间天然带有更强的语义判别性。少样本 fine-tuning 时,这个优势更明显。
2. 小模型就能用
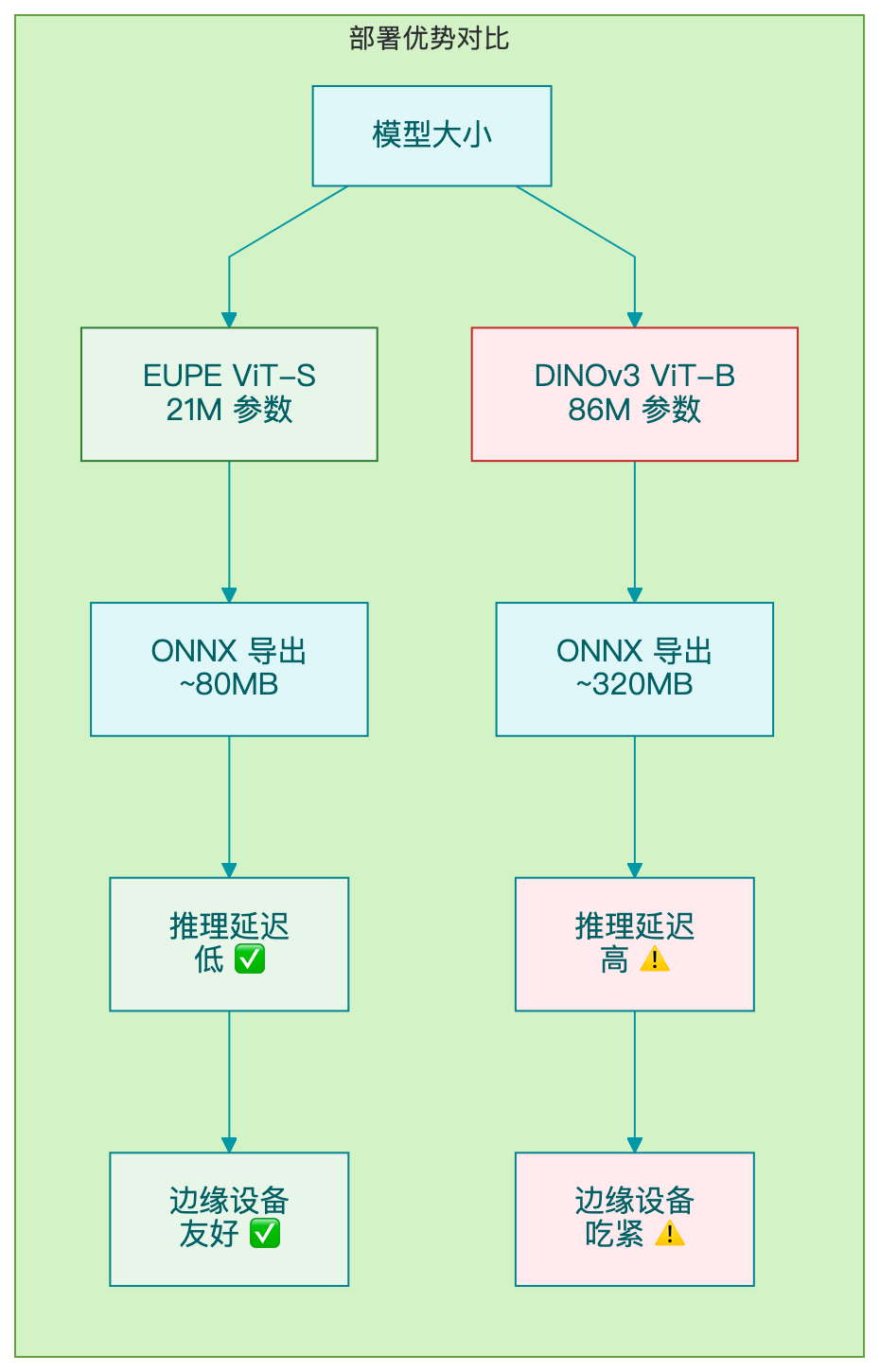
DINOv3 想达到好效果,通常需要 ViT-B (86M)。但 EUPE-ViT-S (21M) 就能接近 ViT-B 的精度。
这意味着什么?
- 推理速度更快(21M vs 86M,快 4 倍)
- 显存占用更低(边缘设备友好)
- ViT-T (6M) 可以在移动端/嵌入式实时运行
3. 单 backbone 多任务潜力
EUPE 的特征同时适用于检测、分割、分类。如果以后想加个缺陷分类头,不需要双模型,共享同一个 backbone 就行:
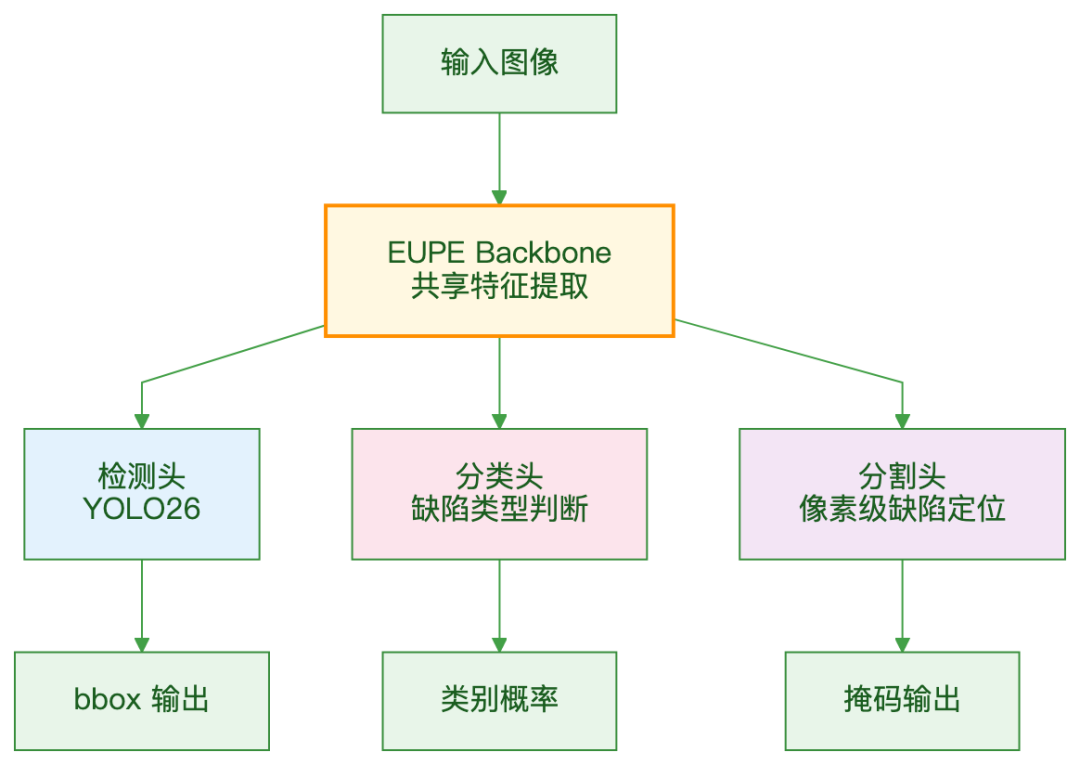
整体框架
和 DINOv3 + YOLO26 一样的思路:

区别只在特征提取层。
EUPE 特征怎么用
EUPE 输出的是标准 ViT 特征:[B, N, C],其中 N = H×W + 5(5 是 cls token + 4 个 storage tokens)。
def forward(self, x):
feat = self.eupe.forward_features(x)
patch_tokens = feat['x_norm_patchtokens'] # [B, N, C]
B, N, C = patch_tokens.shape
H = W = int(N ** 0.5)
patch_tokens = patch_tokens.reshape(B, H, W, C).permute(0, 3, 1, 2).contiguous()
# 多尺度生成
c2 = patch_tokens # 40x40 (P3)
c3 = F.avg_pool2d(c2, kernel_size=2) # 20x20 (P4)
c4 = F.avg_pool2d(c3, kernel_size=2) # 10x10 (P5)
neck_feats = self.neck([c2, c3, c4])
return self.detect(neck_feats)
注意:EUPE 的 patch tokens 输出格式和 DINOv3 不同:
- DINOv3:用
get_intermediate_layers(n=4)取多层,输出包含 cls token - EUPE:用
forward_features()返回 dict,需要取x_norm_patchtokens
多尺度 Neck
通过 FPN 风格融合生成 P3/P4/P5:
def forward(self, x):
c2, c3, c4 = x
f8 = self.proj8(c2) # 192/384/768 -> 256
f16 = self.proj16(c3) # -> 512
f32 = self.proj32(c4) # -> 512
# 跨尺度融合:用 avg_pool 而非 stride 卷积,保留更多空间信息
down_8to16 = F.avg_pool2d(f8, kernel_size=2, stride=2)
n16 = self.fuse16(torch.cat([f16, down_8to16], dim=1))
down_16to32 = F.avg_pool2d(n16, kernel_size=2, stride=2)
n32 = self.fuse32(torch.cat([f32, down_16to32], dim=1))
return [f8, n16, n32] # P3, P4, P5
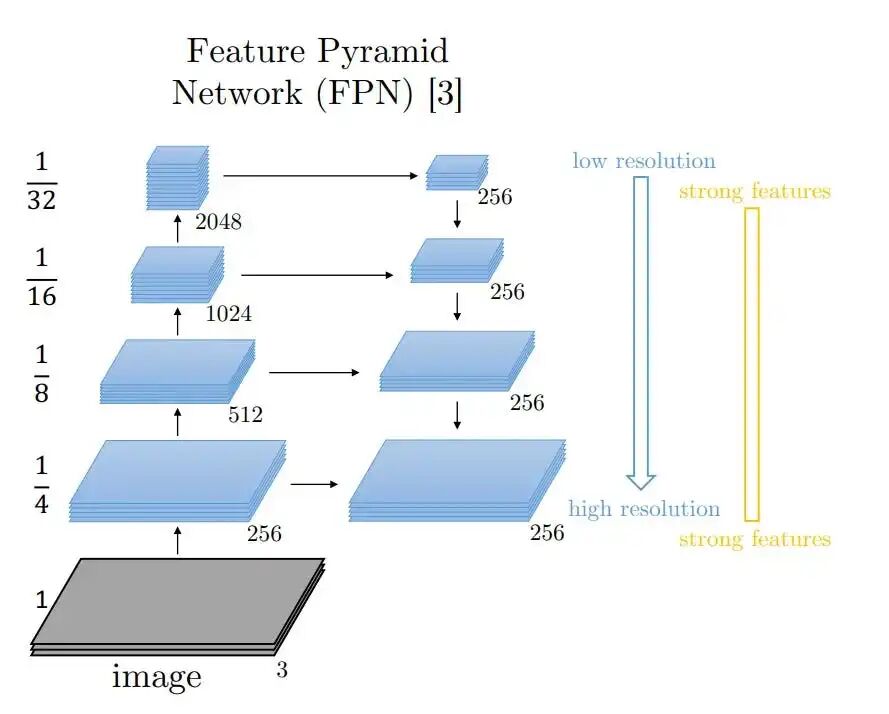
FPN 特征金字塔网络:多尺度特征融合,低分辨率强语义 + 高分辨率强空间
FPN 特征金字塔网络:多尺度特征融合,低分辨率强语义 + 高分辨率强空间
和 DINOv3 + YOLO26 的核心对比
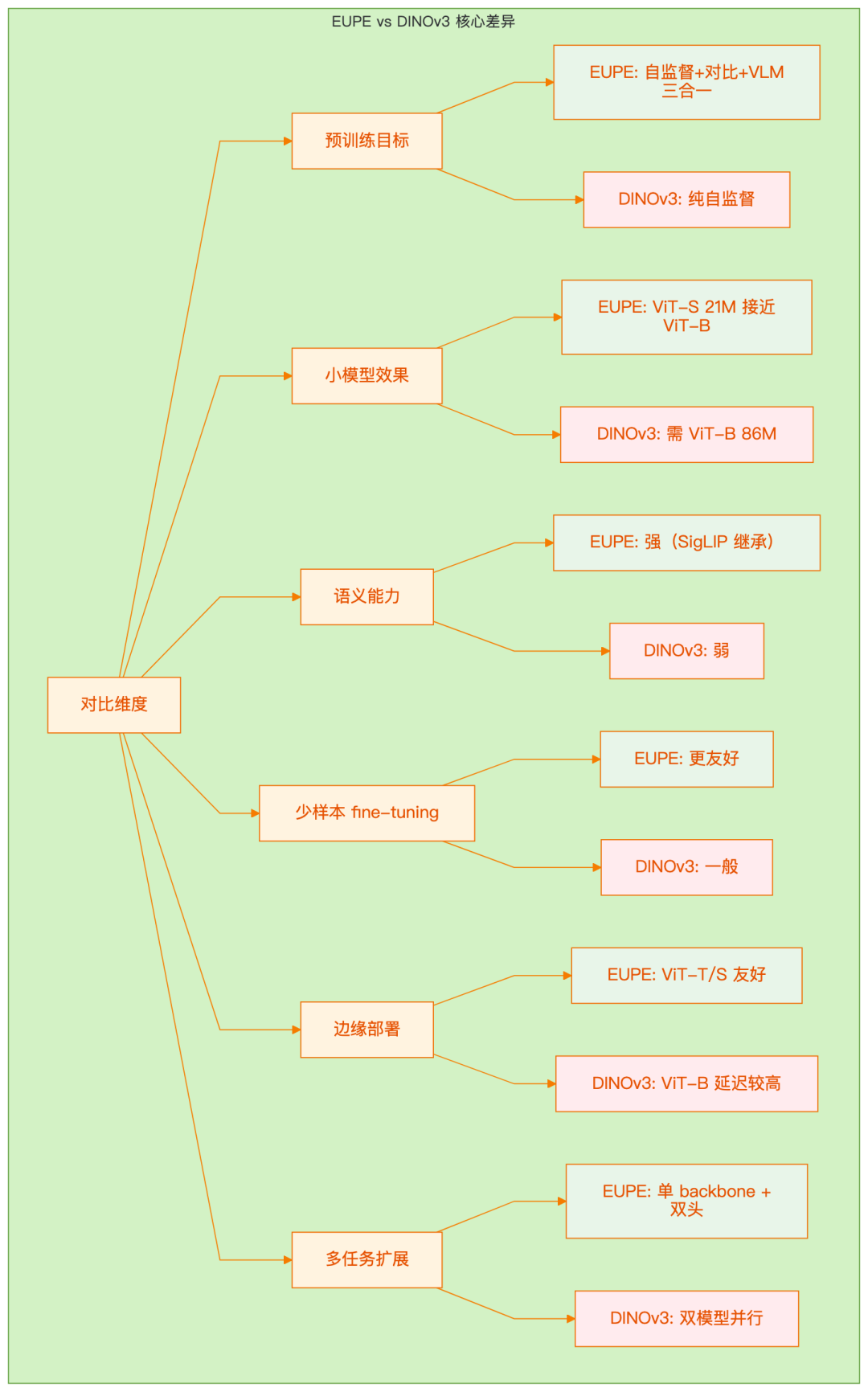
维度 | EUPE + YOLO26 | DINOv3 + YOLO26 |
|---|---|---|
预训练目标 | 自监督 + 对比 + VLM 三合一 | 纯自监督 |
小模型效果 | ViT-S 21M 即可接近 ViT-B | ViT-B 86M 才够 |
语义能力 | 强(SigLIP 继承) | 弱 |
少样本 fine-tuning | 更友好 | 一般 |
边缘部署 | ViT-T/S 友好 | ViT-B 延迟较高 |
多任务扩展 | 单 backbone + 双头 | 双模型并行 |
训练配置的一点经验
冻结策略
EUPE 默认不冻结(freeze=0),因为它的特征本身已经很强。但数据量少时可以适当冻结:
# 冻结前 freeze_eupe 层
if freeze_eupe > 0:
for param in model.eupe.parameters()[:freeze_eupe * 8]:
param.requires_grad = False
学习率
比 DINOv3 可以稍微大一点,因为 EUPE 的特征更鲁棒:
- 全部可训练:
lr0 = 0.0005 ~ 0.001 - 冻结 backbone:
lr0 = 0.0001 ~ 0.0003
数据增强
工业图像的增强要保守一点。mosaic 和 mixup 建议调小或关闭,它们可能会破坏缺陷的局部形态:
mosaic: 0.3 # 或 0
mixup: 0.1
部署
导出 ONNX 的方式完全一样:
model.export(
format='onnx',
imgsz=[640, 640],
dynamic=False,
half=True # FP16 加速
)
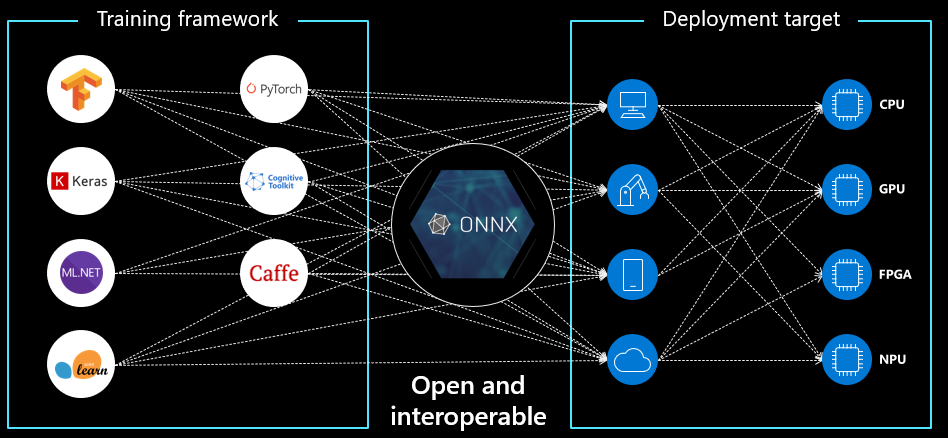
ONNX 跨平台部署:训练框架 → ONNX → 多种边缘设备
ONNX 跨平台部署:训练框架 → ONNX → 多种边缘设备
EUPE 的优势在部署端更明显:ViT-S (21M) 导出后比 ViT-B (86M) 小 4 倍,推理更快。
结语
EUPE + YOLO26 不是一个「替代」DINOv3 的方案,而是另一个选择。
如果你受限于算力、数据量、或者需要更强的语义能力,EUPE 值得尝试。如果你的场景纯粹是大图小目标检测且数据量充足,DINOv3 依然是个好选择。
可以在实际数据上做个对比实验,再决定用哪个。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号