踩坑!你的MySQL突然卡死无响应?90%DBA都踩过连接数爆满运维坑

踩坑!你的MySQL突然卡死无响应?90%DBA都踩过连接数爆满运维坑

俊才
发布于 2026-04-28 13:13:27
发布于 2026-04-28 13:13:27
谁没遇到过MySQL突然卡死的情况?尤其是业务高峰期,监控告警疯狂刷屏,应用接口全部超时,用户投诉不断,DBA手忙脚乱登录服务器,却发现连MySQL都进不去。没错,这大概率就是连接数爆满在搞鬼!
作为运维圈高频爆发的故障,连接数爆满堪称“新手DBA的噩梦、老DBA的常客”,据统计90%的DBA都在这上面栽过跟头。要么紧急重启凑活了事,要么盲目调参越改越糟,最后导致业务中断时间拉长,背锅又挨骂。
为什么会出现连接数爆满?紧急情况下怎么10分钟恢复?如何从根源避免再踩坑?本文就来探讨一下,全程干货,建议收藏,下次卡死直接照做!
一、MySQL卡死,真的是“连接数满了”吗?
很多人一看到MySQL无响应,就断定是连接数爆满,但其实有两种情况容易混淆,先排查清楚再动手,避免做无用功:
- 第一种:真连接数爆满。MySQL的max_connections参数达到上限,新的连接请求被直接拒绝,应用报错「Too many connections」,这是最常见的情况;
- 第二种:假连接数爆满。连接数没到上限,但大量连接处于“Sleep”状态(空闲未释放),或者被慢查询、锁等待阻塞,导致有效连接被占满,新连接无法接入,表现和真爆满完全一致。
这里要分清两个关键指标,很多DBA都搞混了:
- Threads_connected:已建立但未关闭的连接总数,包含空闲的Sleep连接,相当于“已占用的连接名额”;
- Threads_running:正在执行SQL的连接数,不包含等待I/O的连接,真正反映MySQL的负载压力。如果这个值接近max_connections,才是真的资源过载。
用两条简单SQL就能快速排查,哪怕MySQL快卡死,也能通过socket直连执行(后面会说):
-- 查看当前连接数
SHOW STATUS LIKE 'Threads_connected';
-- 查看连接数上限
SHOW VARIABLES LIKE 'max_connections';
-- 查看连接状态分布(区分空闲和活跃连接)
SHOW STATUS LIKE 'Threads_%';
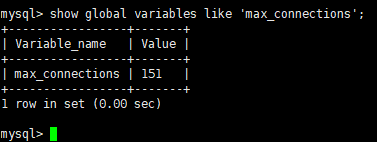
补充一个知识:MySQL 5.7/8.0的max_connections默认值只有151,这个数值对于中小业务都不够用,更别说高并发场景。这也是连接数爆满频发的核心原因之一,很多DBA忘了调这个基础参数!
二、90%DBA踩坑的4个常见原因
连接数爆满不是偶然,背后往往是“配置+代码+运维”的三重漏洞,这4个原因最常见,看看你有没有踩过:
1. 基础配置踩坑:max_connections设置不合理
这是最入门也最容易忽略的坑。很多DBA部署MySQL时,直接用默认配置,max_connections=151,一旦遇到流量突增(比如促销、爬虫),瞬间就被打满。
更坑的是,有些新手DBA发现爆满后,盲目把max_connections调到1000、2000,却不考虑服务器内存。MySQL每个连接会占用一定内存(约2-4MB),连接数太多会导致内存耗尽,MySQL直接崩溃,得不偿失。
2. 连接泄漏:应用“借了不还”,连接被白白占用
这是高频元凶!应用代码中,申请MySQL连接后,因为异常、遗漏,没有释放连接,导致连接一直处于“占用”状态,慢慢堆积,最终占满所有名额。
真实场景:某电商平台的订单接口,try-catch异常路径中没有释放连接,一旦出现异常,连接就会“失联”,随着异常请求增多,不到1小时就把连接数占满,MySQL直接卡死。
还有一种情况是ORM框架误用、嵌套事务未释放,尤其是Python、PHP等脚本语言,没有使用连接池,每次请求都新建连接,用完不关闭,高并发下直接爆掉连接数。
3. 慢查询/锁等待:连接被“堵死”,新连接进不来
有时候连接数没到上限,但大量连接被慢查询、锁等待阻塞,无法释放,导致新连接无法接入,表现为MySQL卡死。
比如:某报表查询未加索引,全表扫描耗时10分钟,这个连接会一直占用,若有100个这样的查询,哪怕max_connections=200,也会被堵死;还有热点行更新导致的行锁冲突,大量连接等待锁释放,同样会造成连接堆积。
4. 连接池配置不当:“帮倒忙”的连接池
很多DBA知道用连接池(比如HikariCP、Druid)复用连接,但配置不当反而会加剧问题:比如连接池的max-active(最大活跃连接)设置过大,多个微服务的连接数总和超过MySQL的max_connections,直接把数据库打满;或者连接池没有开启泄漏检测,连接泄漏后无法及时回收。
这里提醒一句:连接池不是越大越好,过大的连接池会导致MySQL线程竞争激烈,反而降低性能,合理的大小需要结合服务器配置和业务并发量计算。
三、 快速恢复MySQL
一旦遇到MySQL卡死、连接数爆满,别慌,按这4步来,先恢复业务,再排查根因(所有操作前,记得通知业务方,避免误操作影响扩大):
第一步:紧急登录MySQL(避开连接限制)
连接数爆满时,普通账号可能登不进去,这时候用socket直连(不依赖TCP连接池),直接登录root账号:
# 不同系统socket路径可能不同,常见路径如下
# CentOS:/var/lib/mysql/mysql.sock
# Ubuntu:/var/run/mysqld/mysqld.sock
mysql -u root -p -S /var/lib/mysql/mysql.sock
如果还是登不进去,先查看MySQL进程是否存活,避免是进程崩溃:ps aux | grep mysqld | grep -v grep
ss -tlnp | grep 3306 # 查看3306端口是否监听
第二步:清理无效连接(最快止血)
大多数连接数爆满场景,都是大量Sleep空闲连接占用名额,清理这些连接是最快的恢复方式,执行以下SQL批量清理(超时30秒的空闲连接,可根据实际调整):
-- 用游标生成kill命令
SELECT CONCAT('KILL ', ID, ';')
FROM INFORMATION_SCHEMA.PROCESSLIST
WHERE COMMAND = 'Sleep' AND TIME > 30
INTO OUTFILE '/tmp/kill_sleep.sql';
SOURCE /tmp/kill_sleep.sql;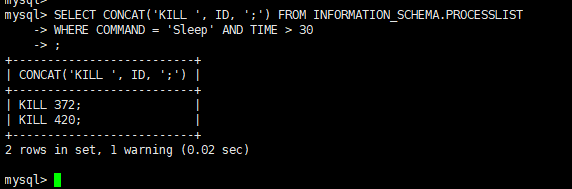
也可以用Shell脚本一键清理,避免手动执行繁琐:
#!/bin/bash
# 清理超时30秒的空闲连接
SOCKET="/var/lib/mysql/mysql.sock"
THRESHOLD=30
mysql -u root -p"你的密码" -S "$SOCKET" -N -e"
SELECT CONCAT('KILL ', ID, ';')
FROM INFORMATION_SCHEMA.PROCESSLIST
WHERE COMMAND = 'Sleep' AND TIME > $THRESHOLD;
" | mysql -u root -p"你的密码" -S "$SOCKET"
echo "已清理超时空闲连接";
第三步:临时调大连接数(应急用,别长期依赖)
清理完无效连接后,如果还是不够用,临时调大max_connections,无需重启MySQL,动态生效:
-- 临时调整为500(根据服务器内存调整,别太大)
SET GLOBAL max_connections = 500;注意:这个设置重启MySQL后会失效,只是应急手段,后续必须结合根因调整,否则还会爆满。
第四步:定位异常连接(避免复发)
恢复业务后,一定要排查是谁在占用连接,避免下次再出问题,执行以下SQL定位:
-- 按IP统计连接数,定位哪个服务占用过多
SELECT SUBSTRING_INDEX(host, ':', 1) AS ip, COUNT(*) AS cnt
FROM INFORMATION_SCHEMA.PROCESSLIST
GROUP BY ip ORDER BY cnt DESC;
-- 查看慢查询连接(执行时间超过3秒)
SELECT * FROM INFORMATION_SCHEMA.PROCESSLIST
WHERE COMMAND = 'Query' AND TIME > 3 ORDER BY TIME DESC;
-- 按用户统计连接数,排查异常用户
SELECT user, COUNT(*) AS cnt
FROM INFORMATION_SCHEMA.PROCESSLIST
GROUP BY user ORDER BY cnt DESC;
四、 根治方案:5个配置+规范,彻底避开连接数坑
紧急恢复只是“救火”,想要彻底避免连接数爆满,必须做好这5点,从根源上解决问题:
1. 合理设置max_connections(核心配置)
不要盲目调大,也不要用默认值,计算公式参考:max_connections = 服务器可用内存(MB)÷ 单个连接占用内存(MB) - 预留内存(20%)
举例:服务器可用内存8GB(8192MB),单个连接占用4MB,预留20%内存,max_connections = 8192×0.8 ÷4 = 1638,建议设置为1500(留有余量)。
永久生效配置(修改my.cnf/my.ini,重启MySQL):
[mysqld]
max_connections = 1500
# 同时设置连接超时时间,自动回收空闲连接
wait_timeout = 120 # 非交互连接超时(单位:秒)
interactive_timeout = 120 # 交互连接超时(单位:秒)
2. 强制使用连接池,规范配置
所有应用必须使用连接池(推荐HikariCP或Druid),实现连接复用,避免频繁创建/销毁连接(连接创建是重量级操作,耗时且耗资源):
- HikariCP(SpringBoot默认,轻量高效):核心配置maximum-pool-size(最大连接数)建议设置为20-50,根据业务并发调整,同时开启泄漏检测
- Druid(企业级,功能全面):配置maxActive=30,minIdle=5,同时开启监控,实时查看连接池状态,及时发现泄漏
关键原则:多个微服务连接同一个MySQL时,所有服务的连接池最大连接数总和,必须小于MySQL的max_connections。
3. 优化慢查询,减少连接阻塞
- 开启MySQL慢查询日志,定位耗时超过1秒的SQL,加索引、优化SQL结构(避免全表扫描、嵌套子查询)
- 禁止在事务中调用HTTP/RPC接口、循环处理大量数据,避免长事务占用连接
- 定期优化表结构,更新统计信息,避免执行计划走错导致慢查询
4. 开启监控告警,提前预警
不要等卡死了才发现问题,用监控工具(Prometheus + AlertManager + Grafana)监控以下指标,设置告警阈值:
- 连接数使用率:Threads_connected / max_connections > 70% 告警;
- 活跃连接数:Threads_running > 50 告警(根据服务器配置调整);
- 慢查询数量:每秒慢查询数>5 告警。 手把手搭建基于Prometheus + Grafana的高效且全面的数据库监控体系(附部署指南)
同时,定期查看MySQL错误日志,及时发现连接数相关异常:
tail -100 /var/log/mysql/error.log | grep -i "too many connections"5. 规范代码,避免连接泄漏
- 代码中必须在finally块中释放连接,或使用try-with-resources自动释放(Java);
- 定期做代码审查,检查ORM框架使用是否规范,避免嵌套事务未释放;
- 脚本语言(PHP/Python)必须使用连接池,禁止每次请求新建连接后不关闭。
五、 总结
很多DBA踩坑,不是技术不行,而是陷入了思维误区,这3个误区一定要避开:
- 误区1:“调高max_connections就万事大吉”。忽略内存限制,反而会导致MySQL内存耗尽崩溃
- 误区2:“连接池越大越好”。过大的连接池会导致MySQL线程竞争激烈,性能下降,反而更容易卡顿
- 误区3:“不监控,等出事再处理”。连接数爆满都是慢慢堆积的,提前监控预警,才能避免业务中断
MySQL连接数爆满,看似是突发故障,实则是“长期忽视基础配置+代码不规范”的必然结果。作为DBA,与其事后救火,不如事前预防。把max_connections调合理、用对连接池、做好监控,就能避开这个90%的人都踩过的坑。
最后想问一句:你遇到过MySQL连接数爆满的问题吗?当时是怎么解决的?评论区分享你的踩坑经验,帮更多DBA避坑~
关注我,后续分享更多MySQL运维干货,避开所有运维坑!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号