深度学习将会有一套真正的科学理论

深度学习将会有一套真正的科学理论

DrugIntel
发布于 2026-04-28 13:03:43
发布于 2026-04-28 13:03:43

论文信息
- • 标题:There Will Be a Scientific Theory of Deep Learning
- • arXiv:2604.21691v1 [stat.ML],2026 年 4 月
- • 作者:Jamie Simon、Daniel Kunin、Alexander Atanasov 等 14 人(UC Berkeley、Harvard、NYU、Penn、Flatiron Institute、Stanford 等)
- • 配套社区:learningmechanics.pub
一、为什么要读这篇文章?
深度学习是当今最强大也最神秘的技术。神经网络能以超人水平完成视觉、语言、蛋白质折叠等任务,但我们没有统一的科学框架解释它为何有效。训练方法大多源自试错,超参数调节依赖经验,理论对日常实践几乎没有指导作用。
这篇论文是一篇纲领性宣言,而非普通研究论文。它做了三件事:
- 1. 论证深度学习的科学理论正在涌现;
- 2. 将这一理论命名为"学习力学(Learning Mechanics)";
- 3. 为整个领域画出地图,指出最重要的开放方向。
对于从事 AI 研究的人来说,这张地图极具价值。
二、核心概念:学习力学是什么?
2.1 类比物理力学
"力学"这个名字来自精心设计的类比:
经典力学 | 学习力学 |
|---|---|
物体在物理空间中运动 | 参数在参数空间中更新 |
力与场驱动运动 | 梯度驱动参数更新 |
势能局部极小值(平衡态) | 损失函数局部极小值(收敛态) |
可解析模型:谐振子、氢原子 | 可解析模型:深度线性网络、核方法 |
热力学极限() | 无限宽度 / 深度极限 |
开普勒定律、欧姆定律等经验规律 | 神经网络规模定律、稳定性边缘等 |
相变与重整化群 | 训练中的普遍现象与跨架构通用性 |
这一类比并非修辞,而是实质性的:两门学科解决的核心问题都是运动与交互,因此方法论高度共通。
2.2 七条标准:什么样的理论才算合格?
论文为"学习力学"设定了七条判定标准,这也是评价任何深度学习理论工作的参考框架:
- 1. 基础性(Fundamental):从第一性原理出发,逐步推导,不依赖无法解释的假设;
- 2. 数学性(Mathematical):做出无歧义的定量陈述,而非定性描述;
- 3. 预测性(Predictive):做出可被简单、可重复实验验证的量化预测;
- 4. 综合性(Comprehensive):在同一框架内描述训练动力学、隐层表征和最终权重,但不追求对每个细节的全分辨率刻画;
- 5. 直觉性(Intuitive):以简洁、令人信服的方式揭示深层原因;
- 6. 实用性(Useful):大幅减少超参数调节负担,提供数据集设计工具,为 AI 安全提供理论基础;
- 7. 谦逊性(Humble):明确陈述适用范围,就像经典力学在量子尺度下失效一样。
三、五条核心证据
论文通过五个维度的研究进展,论证"学习力学"的理论骨架已经出现。
证据一:存在可解析求解的简化模型
类比:物理学的谐振子与氢原子
复杂系统的科学进步,往往从少数可以精确求解的简化模型开始。深度学习同样如此。
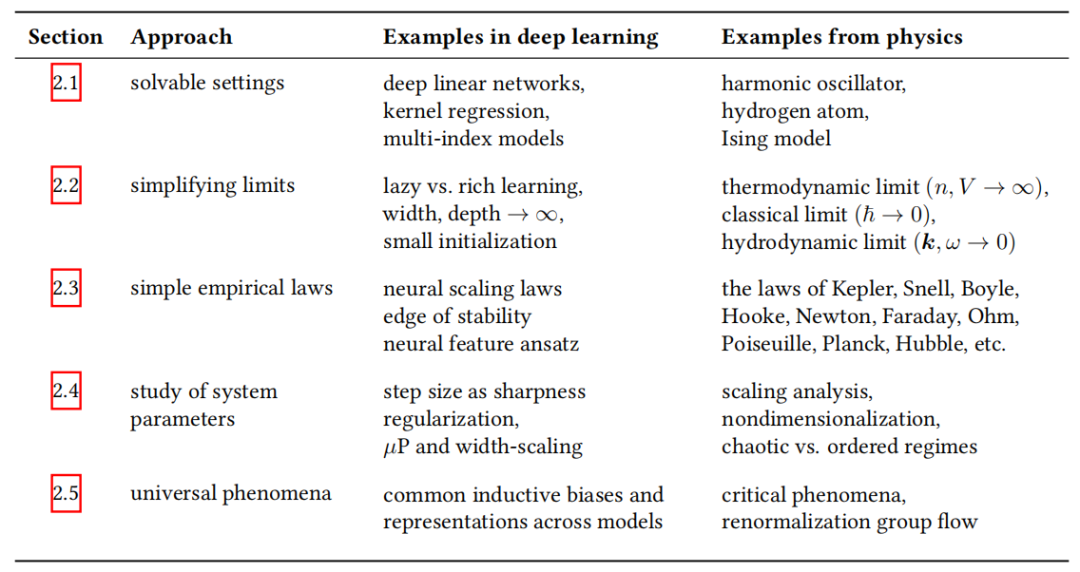
1. 数据线性化:深度线性网络
去掉所有非线性激活函数,得到的模型对输入 是线性的,但对参数 高度非线性:
表面上看这是一个无用的玩具模型,但它保留了深度学习的诸多关键行为:
- • 鞍点主导的损失景观(Baldi & Hornik, 1989)
- • 急剧相变与时间尺度分离的训练动力学(Gissin et al., 2019; Atanasov et al., 2021)
- • 梯度下降的稳定性边缘振荡(Even et al., 2023)
- • 强初始化依赖的归纳偏置(Woodworth et al., 2020; Kunin et al., 2024)
最经典的结果来自 Saxe et al. (2014):在任务对齐初始化和白化输入条件下,梯度流动力学可以精确解耦为独立的伯努利常微分方程,揭示了贪婪低秩偏置(greedy low-rank bias)——网络按奇异值从大到小的顺序,依次学习输入-输出相关矩阵的奇异向量。
这一规律在非线性网络中也有对应:网络倾向于先学习简单模式,再学习复杂模式(Kalimeris et al., 2019; Simon et al., 2023b)。
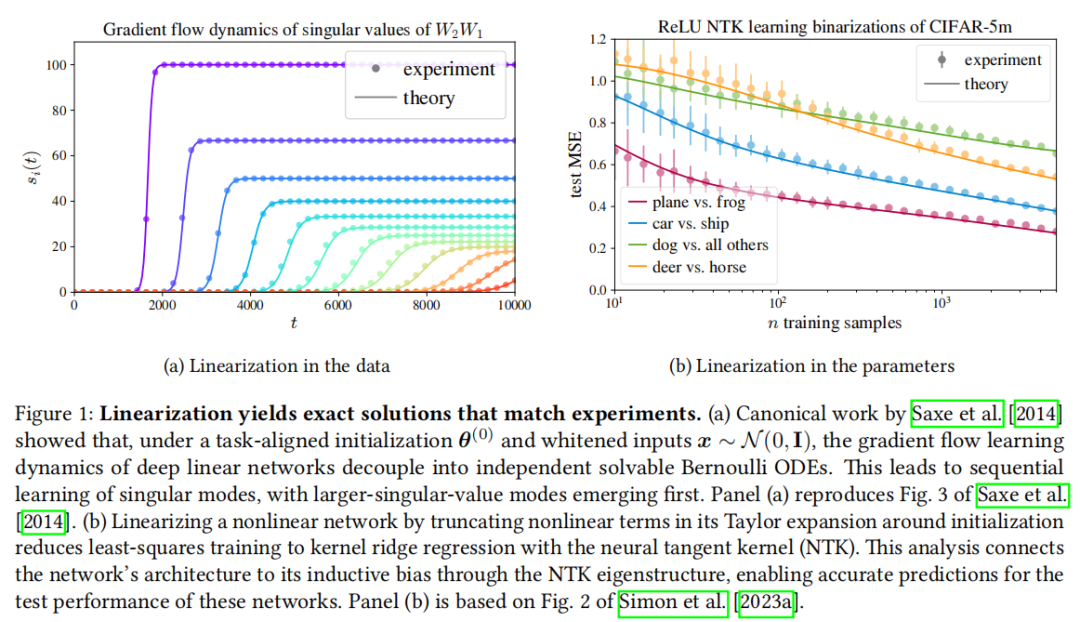
2. 参数线性化:神经切线核(NTK)
对网络在初始参数 处做泰勒展开,截断非线性项:
这等价于以神经切线核(Neural Tangent Kernel, NTK) 做核岭回归(Jacot et al., 2018)。
该框架的价值在于:
- • 架构决定归纳偏置:NTK 的特征结构直接反映了架构选择;
- • 泛化误差可量化预测:结合输入数据分布,可以对任意目标函数的期望泛化误差做精确预测(Simon et al., 2023a);
- • 捕获双下降、规模定律等重要现象(Caponnetto & de Vito, 2007; Atanasov et al., 2024)。
局限性:线性化网络无法捕捉特征学习能力,对样本复杂度的预测往往过于悲观(Ghorbani et al., 2020)。这促使研究者走向真正非线性的玩具模型。
3. 非线性前沿:多指标模型与教师-学生框架
当前理论前沿的核心目标是构造同时保留参数非线性和数据非线性的可解析模型:
- • 多指标模型(Multi-index models):用高斯输入和结构化目标,证明全非线性神经网络在样本效率上优于核方法,因为它能主动学习目标函数的相关特征(Abbe et al., 2022; Damian et al., 2022);
- • 二次激活函数两层网络:最近实现了对精确渐近、训练动力学和规模定律的精确刻画(Erba et al., 2025; Ben Arous et al., 2025);
- • 教师-学生模型:将训练动力学化归为低维汇总统计量的演化(Saad & Solla, 1995; Goldt et al., 2019);
- • 注意力机制的可解析模型(Zhang et al., 2025; Boncoraglio et al., 2025)。
证据二:有洞见的极限揭示基本行为
类比:热力学极限()、经典极限()
现代深度学习模型参数高达数千亿,逐参数建模毫无希望。但复杂系统在有效无穷大时往往呈现出简洁的数学结构。
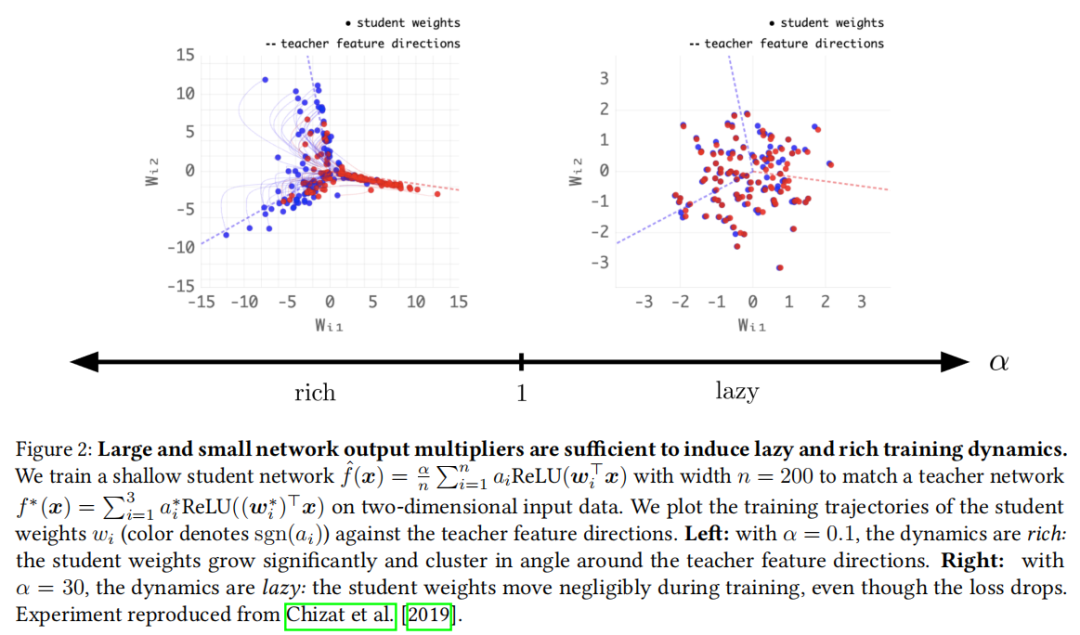
1. 无限宽度极限与懒惰/富特征二分法
无限宽度极限的关键在于:缩放初始权重的方式决定了训练行为的定性类别。
懒惰(Lazy)/ 核 / 线性化 regime:按 初始化(即标准的 LeCun 初始化)时,网络权重在训练中变化微乎其微,但这些微小变化累积后在输出端产生显著效果。训练动力学可以完全用 NTK 描述,但代价是完全没有特征学习。
富特征(Rich)/ 主动 / 特征学习 regime:将最后一层权重额外缩小 倍时(即 μP 参数化),网络必须显著改变权重才能产生有效输出。在此极限下:
- • 隐层特征随训练主动演化,适应输入数据的结构;
- • 神经元发生专业化,形成对不同数据特征的选择性响应;
- • 当初始化规模进一步减小时,出现 Section 1 中的贪婪低秩偏置。
这一懒惰/富特征二分法对有限宽度网络同样成立(Chizat et al., 2019),是理解深度学习的核心框架之一。
工程意义:μP 参数化(Maximal Update Parameterization)已被工业界采纳,用于大模型训练中的超参数迁移(见证据四)。
2. 无限深度极限
类似地,残差网络存在两种无限深度极限:
- • 每层贡献缩小 :残差流随深度平滑演化,类似神经常微分方程(Neural ODE);
- • 每层贡献缩小 :残差流呈随机微分方程(SDE)驱动的扩散过程。
两种极限在 Transformer 等实际架构中收敛到定性不同的解(Dey et al., 2025),目前哪种更贴近实际仍是开放问题。
3. 离散化假说(Discretization Hypothesis)
以上极限背后有一个统一假说:实际有限大小的神经网络,可以理解为无限极限连续体系的噪声离散近似,类似于用有限差分数值求解偏微分方程。
在这个视角下:
- • 增大模型宽度/深度 ≈ 减小空间/时间步长,降低离散化误差;
- • 减小学习率 ≈ 从离散梯度下降逼近连续梯度流;
- • 增大数据集 ≈ 对数据分布的更精确近似。
该假说尚未被严格证明,但已隐式支撑了大量重要工作。
证据三:简洁的经验规律捕捉宏观统计量
类比:开普勒定律、欧姆定律、玻尔兹曼分布
1. 神经网络规模定律(Neural Scaling Laws)
Kaplan et al. (2020) 的核心发现:在给定架构族内,模型的测试损失是计算量 、数据集大小 和参数量 的幂律函数:
这一结果震撼的地方在于:面对数十亿参数、海量数据的复杂系统,损失居然只由三个标量变量决定,且关系如此简洁。
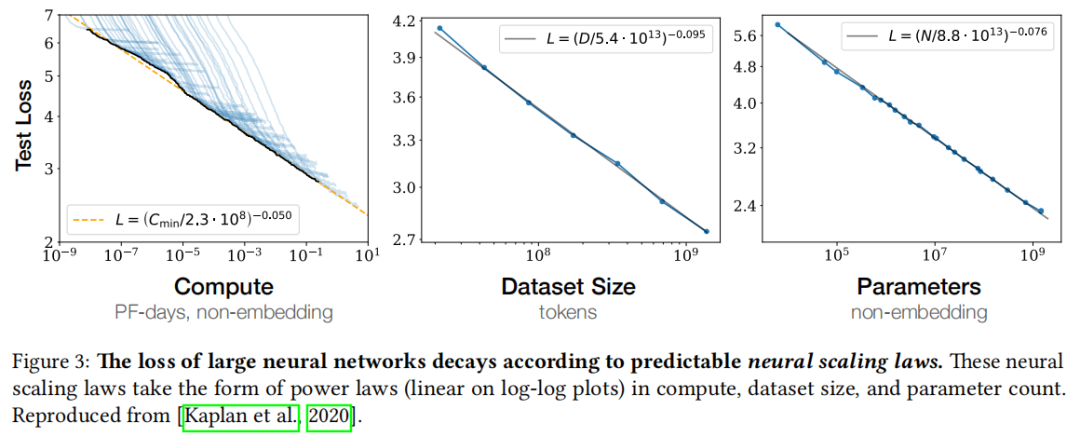
目前仍不清楚为何是幂律,也无法从第一性原理预测具体指数。候选解释包括:
- • 数据流形的维度(Sharma & Kaplan, 2022; Bahri et al., 2024);
- • 特征叠加与任务结构中潜在的幂律(Michaud et al., 2023; Bordelon et al., 2024a);
- • 架构和优化器的细节(Barkeshli et al., 2026)。
预测规模定律指数是论文列出的第 7 个开放方向,也是最有实际价值的理论目标之一。
2. 稳定性边缘(Edge of Stability)
Cohen et al. (2021) 发现,用全批量梯度下降训练神经网络时,损失 Hessian 的最大特征值(即"锐度",sharpness)呈现两个阶段:
- 1. 渐进锐化(Progressive Sharpening):锐度缓慢上升;
- 2. 稳定平台(Edge of Stability):锐度在 附近( 为学习率)稳定,略有振荡。
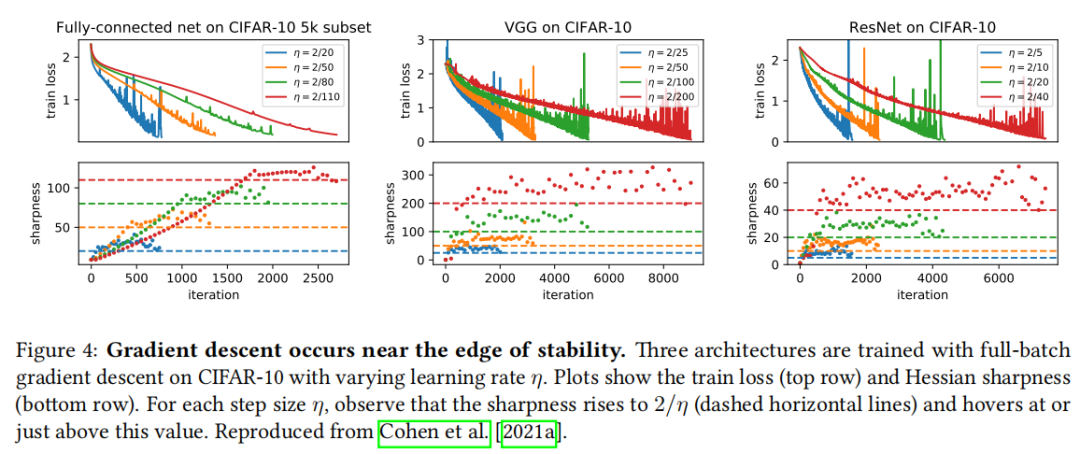
为什么是 ?这正是凸优化中梯度下降保持稳定的临界锐度——超过此值则参数振荡发散。在一般情况下,Damian et al. (2022) 证明,三阶损失曲率的粗粒度性质可以使二阶锐度稳定在该值。
更进一步,Cohen et al. (2025) 表明:在稳定性边缘的训练轨迹,可以分解为一个曲率惩罚梯度流加上不稳定方向上的振荡,并给出了与实验高度吻合的定量预测。
3. 神经坍塌(Neural Collapse)
Papyan et al. (2020) 发现:用交叉熵损失训练 分类器,训练结束时,每个类别最后一层隐层表征的类内方差趋近于零, 个类均值向量构成正则单纯形(regular simplex)。
理论解释:在交叉熵损失加上 L2 正则化的框架下,这是能量最小化的自然构型(Zhu et al., 2021)。
4. 神经特征拟设(Neural Feature Ansatz)
Radhakrishnan et al. (2024) 发现,训练后第一层权重的格拉姆矩阵与平均梯度外积对齐:
这一规律对更深层也有对应形式,为理解网络如何从数据中提取相关特征提供了经验基础。
5. 梯度流守恒律
Saxe et al. (2014) 在线性网络中发现: 在梯度流下守恒。
Kunin et al. (2021) 将其推广:这是**诺特原理(Noether's Theorem)**在深度学习中的实例——参数化的连续对称性对应守恒量。ReLU 网络的重缩放对称性、Batch Norm 前的尺度对称性、注意力机制中 K/Q 矩阵的旋转对称性,都给出了相应的守恒量,这些量在梯度流下精确守恒,在 SGD 下以可预测的方式被破坏。
证据四:超参数可以被解耦和理解
类比:雷诺数判断流体层流/湍流
超参数(学习率、批大小、动量、宽度、深度等)长期以来是深度学习的"黑盒旋钮"。近年来,理论开始系统地解耦它们。
1. 优化超参数:线性缩放规则与 SDE 视角
SGD 的两个超参数(学习率 、批大小 )之间存在近似不变性:同时将 和 翻倍、将步数减半,训练轨迹基本不变(Goyal et al., 2017)。
理论解释:将 SGD 视为随机微分方程(SDE)的离散化(Mandt et al., 2017; Jastrzebski et al., 2017),可以自然推导线性缩放规则,并将其推广到自适应优化器(Adam 的学习率应随 缩放,Malladi et al., 2022)。
2. 隐式曲率正则化
Cohen et al. (2025) 的重要结果:多种优化器的完整训练轨迹,可以用曲率惩罚梯度流精确建模:
其中超参数的作用仅仅是调节曲率惩罚的形式和强度。这意味着我们可以将学习率"积分掉",转而研究更简单的梯度流加曲率惩罚——大大简化了理论分析。
3. μP 与超参数迁移:理论直接改变实践的范例
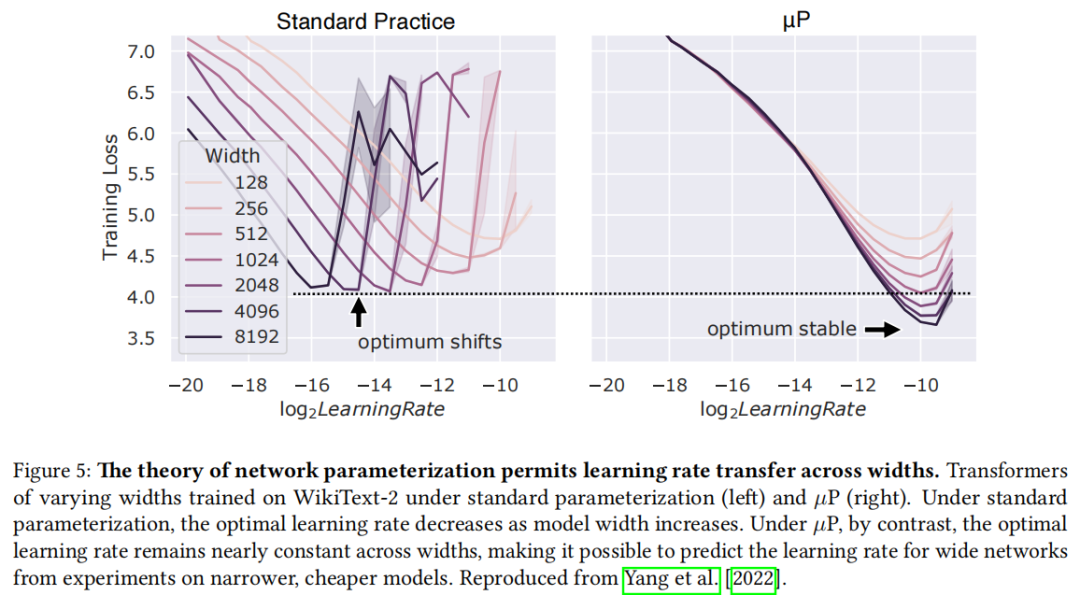
Yang & Hu (2021) 的 Tensor Programs 框架将超参数写为:
通过分析哪些指数 能在无限宽度下保持非平凡的训练行为,得到了两类极限(NTP 对应懒惰,μP 对应富特征),从而唯一确定了所有超参数随宽度的正确缩放方式。
核心工程价值:在 μP 下,最优学习率不随模型宽度变化,因此可以在小模型上调好超参数后零成本迁移到大模型(Yang et al., 2022)。这一结论已被 OpenAI 等机构用于 GPT 系列预训练。
证据五:跨系统的普遍现象
类比:相变与重整化群
1. 通用归纳偏置
ConvNet 与 Transformer 在计算机视觉任务上,当计算量、数据规模和训练方案匹配时,性能趋于相同(Liu et al., 2022; Smith et al., 2023)。在扩散模型中,UNet 和 ViT 在相同噪声输入下生成几乎完全相同的图像(Zhang et al., 2024)。
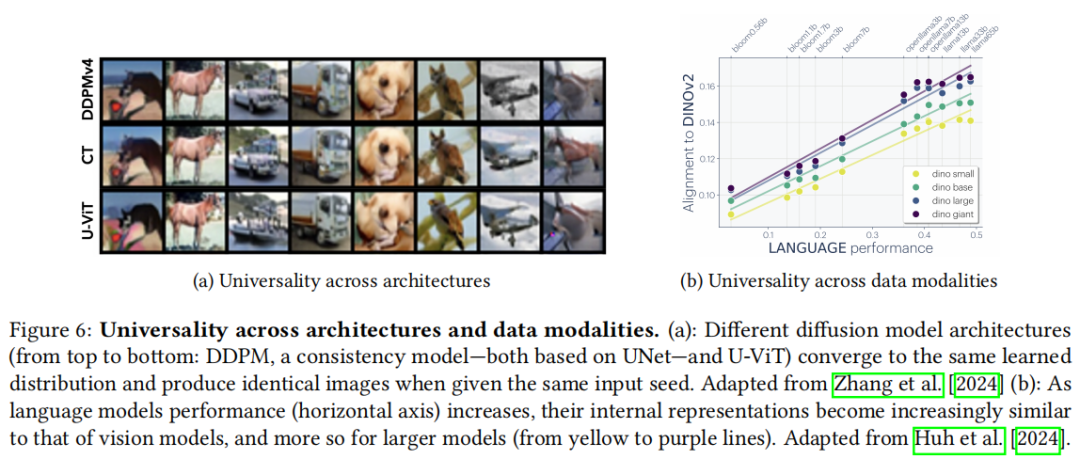
这说明不同架构学到了相同的归纳偏置,而非各自独立的解。
2. 数据的普遍结构
自然图像和音频的功率谱服从幂律;自然语言中词频服从 Zipf 定律;文本和图像都具有层次组合结构。这些跨模态的共同统计特性,是单一学习算法能够泛化到不同领域的根本原因之一。
3. 表征的普遍性(Platonic Representation Hypothesis)
Huh et al. (2024) 发现:随着语言模型性能提升,其内部表征与视觉模型的相似度显著增加,且大模型的相似度更高。不同架构、不同数据集、不同目标函数训练出的大模型,内部表征趋于收敛。
理论解释候选:
- • 在随机特征表示中,这是大数定律的直接推论(Rahimi & Recht, 2007);
- • 在深度线性网络中,可证明源于 SGD 的隐式正则化(Ziyin & Chuang, 2025);
- • 在更广泛的情形下,可能源于数据的普遍结构(Karkada et al., 2026)。
四、与其他理论视角的关系
4.1 学习力学 ⇄ 机制可解释性(核心互补关系)
这是论文着墨最多、也最有前瞻性的部分。
维度 | 机制可解释性 | 学习力学 |
|---|---|---|
目标 | 理解训练好的网络有什么机制 | 理解为何这些机制在训练中涌现 |
方法 | 逆向工程、电路发现 | 第一性原理计算 |
类比 | 生物学 | 物理学 |
当前状态 | 发现了许多有意义的机制,但缺乏数学精确性 | 有严格数学,但语义层面的覆盖有限 |
论文呼吁两个社区深度合作:
学习力学能为可解释性提供:
- • 对"线性表示性"、"稀疏性"、"局部性"、"组合性"等核心假设的数学化与适用条件判定;
- • 对机制如何在训练动力学中涌现的理论解释(如归纳头的形成、Grokking 等)。
可解释性能为学习力学提供:
- • 具体的、有良好定义的理论建模目标(如 Fourier 特征在代数任务中的出现);
- • 将数据结构置于分析核心,弥补经典理论过度依赖简化数据模型的缺陷。
正如"生物学中的一切,只有在进化的光照下才有意义",神经网络的内部机制,可能也只有在产生它的训练动力学的光照下才能被完整理解。
4.2 统计学习理论视角
经典统计学习理论(PAC 学习、Rademacher 复杂度等)提供了最坏情况的泛化界,但这些界对过参数化的深度神经网络几乎无约束力。
学习力学与之的关系:统计视角(隐式偏置向简单函数 + 过参数化使优化容易)提供了正确的高层答案,但要使其精确,必须深入理解训练过程的力学细节。
4.3 信息论视角
信息瓶颈假说(Shwartz-Ziv & Tishby, 2017)认为学习是对数据集的压缩。该视角的洞见可能是正确的,但同样需要对训练力学的精确理解才能落地为具体可测预测。
4.4 统计物理视角
这是与学习力学最直接相关的传统,包括 Hopfield 网络(1982)、感知机的统计力学,一直到现代的平均场理论(Mean-field theory)和副本方法(Replica method)。2024 年诺贝尔物理学奖授予深度学习相关研究,正是对这一传统的认可。
五、十大开放方向
论文列出了预计在未来十年内可以被攻克的开放问题,这是该领域最清晰的研究路线图之一:
方向 | 核心问题 | |
|---|---|---|
1 | 可解析的真正非线性模型 | 能否构造同时保留参数非线性和数据非线性的统一可解析框架? |
2 | 自然数据的理论 | 模型从数据中提取的"充分统计量"是什么?如何从数据统计预测学习行为? |
3 | 隐式复杂度最小化 | 深度学习是否在最小化某种精确定义的函数复杂度?它是 Kolmogorov 复杂度、电路复杂度还是别的什么? |
4 | 特征的形式化定义 | 如何用第一性原理给出"特征"、"电路"、"机制"的数学定义?线性表示性等假设在何条件下成立? |
5 | 离散化假说的证明 | 有限网络能否被严格理解为无限极限的离散近似?收敛速率和误差结构是什么? |
6 | 消除所有超参数 | 超参数的系统解耦程序能走多远?最终还剩什么不可约的超参数? |
7 | 先验预测规模定律指数 | 能否从数据集和架构属性出发,先验地定量预测幂律指数? |
8 | 损失曲率与特征/泛化的关系 | 为何锐度在没有隐式正则化时会上升?曲率正则化如何影响学到的特征和泛化性能? |
9 | 好的优化器理论 | 为何 Adam、Muon 优于 SGD 训练大型语言模型?自适应预条件的作用机理是什么? |
10 | 表征普遍性的精确表述 | 在什么范围内、用什么度量衡量,大模型学到的表征收敛到通用表征?普遍性类(universality class)如何分类? |
六、驳斥常见质疑
论文专门用一节回应了对"深度学习理论可能性"的怀疑,论证严密:
质疑一:研究者努力了几十年,理论依然缺失,为何现在会不同?
答:现代深度学习的实践成功是近年的事,提供了大量新的可研究系统;从物理学到信息论的多样化学者涌入;更重要的是,探索的空间从数学问题转向了经验科学——我们现在有明确的实验可以设计、验证。
质疑二:能理解的都是玩具模型,LLM 理论遥不可及。
答:对基本构件的理解即使不完整,也能立即产生工程价值——规模定律、μP 超参数迁移、基于 NTK 的数据归因,都是例证。"局部理论"可以在没有完整理论的情况下发挥作用。
质疑三:AI 会在人类理解它之前先理解自身。
答:AI 不太可能独立"解决深度学习理论",突破性进展更可能来自人机协作。此外,AI 安全本质上需要人类可解读的理论——否则无法监督和治理。
七、延伸阅读建议
按主题,以下是与本文核心贡献最密切相关的参考文献:
规模定律
- • Kaplan et al. (2020). Scaling Laws for Neural Language Models
- • Hoffmann et al. (2022). Training Compute-Optimal Large Language Models(Chinchilla 规模定律)
无限宽度与 μP
- • Jacot et al. (2018). Neural Tangent Kernel
- • Yang & Hu (2021). Tensor Programs IV: Feature Learning
- • Yang et al. (2022). Tensor Programs V: μTransfer
深度线性网络
- • Saxe et al. (2014). Exact Solutions to the Nonlinear Dynamics of Learning
稳定性边缘
- • Cohen et al. (2021). Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability
- • Cohen et al. (2025). Understanding Optimization in Deep Learning with Central Flows
机制可解释性
- • Olah et al. (2020). Zoom In: An Introduction to Circuits
- • Sharkey et al. (2025). Open Problems in Mechanistic Interpretability
表征普遍性
- • Huh et al. (2024). The Platonic Representation Hypothesis
八、总结
这篇论文最重要的贡献,不是任何一个具体的定理,而是提供了一个共同的科学愿景:
深度学习不只是工程,它是一门等待被理解的自然科学。其理论将像经典力学之于机械工程、热力学之于能源工程那样,成为下一代 AI 系统设计的第一性原理基础。
五条证据——可解析模型、极限分析、经验规律、超参数理论、普遍现象——每一条单独看都已相当有力;汇聚在一起,它们勾勒出一门正在破壳而出的新科学的轮廓。
这门科学还远未完成,但它已经足够真实,足以在此刻认真对待。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号