架构师手册:OpenSpec + Superpowers 打造一人极简开发工作流实战指南
原创
架构师手册:OpenSpec + Superpowers 打造一人极简开发工作流实战指南
原创
术哥
发布于 2026-04-25 00:52:21
发布于 2026-04-25 00:52:21
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 88 篇,AI 编程最佳实战「2026」系列第 20 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
封面图
你画完架构图,发给开发团队,然后等排期、等评审、等联调。一个看板管理系统的需求,从你脑中成型到真正跑起来,少则两周。
但如果我告诉你,一个架构师配上 OpenSpec 和 Superpowers 这两个开源工具,30 分钟就能从零搭出一个带测试的看板系统:不是 demo,是带 CRUD、带数据库、带单元测试的可用系统。
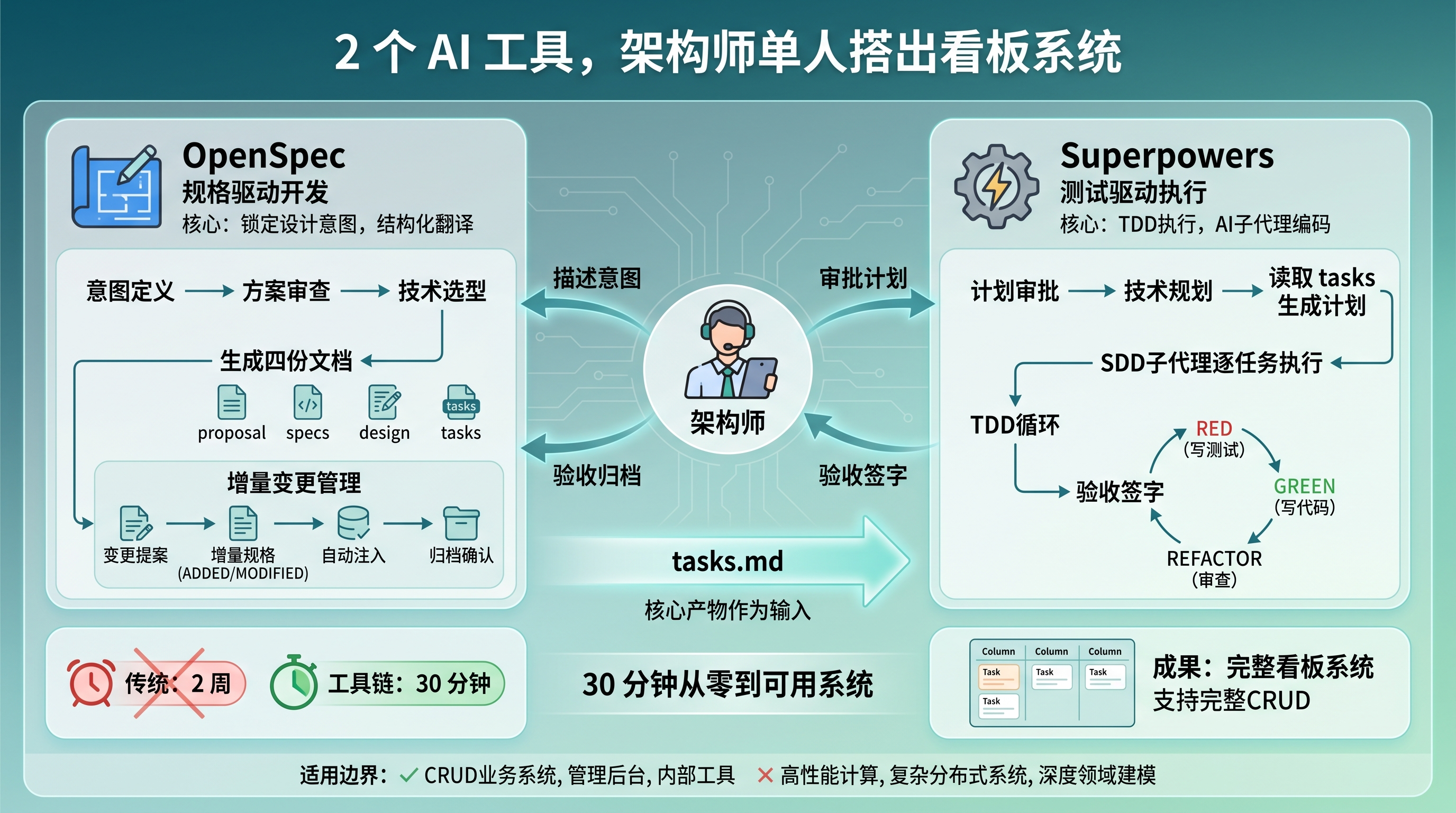
OpenSpec 负责锁定你的设计意图,把模糊的想法翻译成结构化的规格文档。Superpowers 负责 TDD 执行,让 AI 子代理按照规格写代码、跑测试。架构师只做两件事:定义意图、审批方案。
这篇文章会带你走完整个流程。从第一行命令到最后的验收签字,每一步都有真实命令和代码。
一、两把武器,各自管什么
联动流程图
先搞清楚这两个工具的分工,不然后面容易晕。
1.1 OpenSpec:锁定意图,管理变更
OpenSpec(npm 包 @fission-ai/openspec,当前 v1.2.0)做的是规格驱动开发。核心逻辑很简单:写代码之前,先让 AI 帮你把需求翻译成结构化的规格文档。
它的工作流是三步走:
propose → apply → archive
| | |
v v v
创建产物 实现任务 合并规格每次你发起一个需求(叫 propose),OpenSpec 会自动生成四份文档:
- proposal.md — 为什么要做、做什么
- specs/ — 具体的需求规格,用 Given/When/Then 格式描述场景
- design.md — 技术方案,包括架构决策和风险点
- tasks.md — 任务清单,拆分到可执行粒度
这四份文档之间有依赖关系(DAG):specs 依赖 proposal,tasks 依赖 specs + design。换句话说,OpenSpec 会帮你把事情想清楚再动手。
1.2 Superpowers:TDD 落地,子代理执行
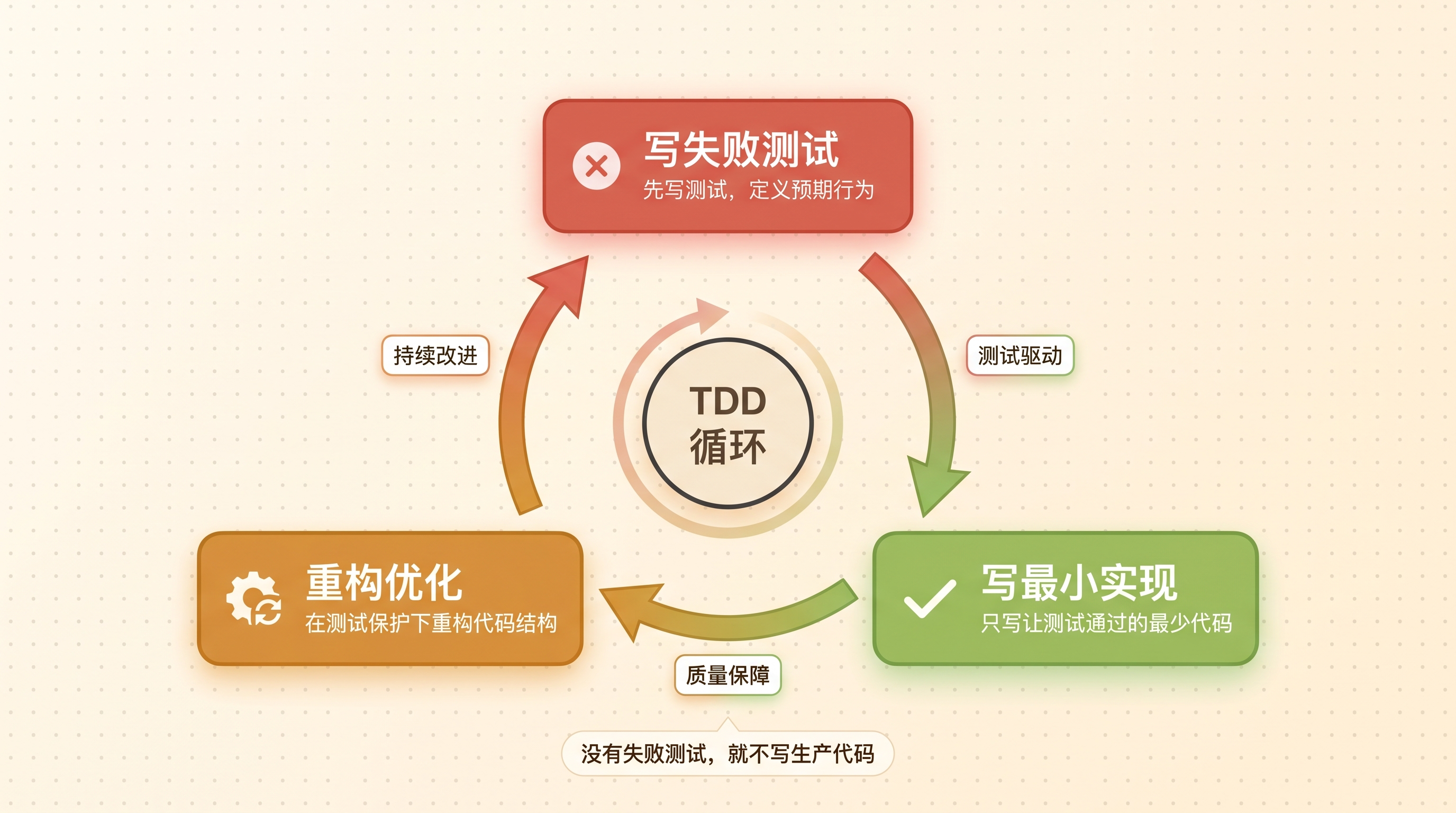
Superpowers(v5.0.7)做的是测试驱动执行。它不是让 AI 直接写代码,而是强制走一套结构化流程:头脑风暴 → 写计划 → TDD 执行 → 代码审查。
它有个核心设计叫 SDD(Subagent-Driven Development,子代理驱动开发)。每个任务由三个角色协作完成:
- Implementer(实现者) — 写代码、写测试、跑测试
- Spec Compliance Reviewer(规格审查员) — 逐行对比代码和规格是否一致
- Code Quality Reviewer(质量审查员) — 规格通过后,审查代码质量
执行循环是严格的 TDD 铁律:没有失败测试,就不写生产代码。
1.3 联动逻辑
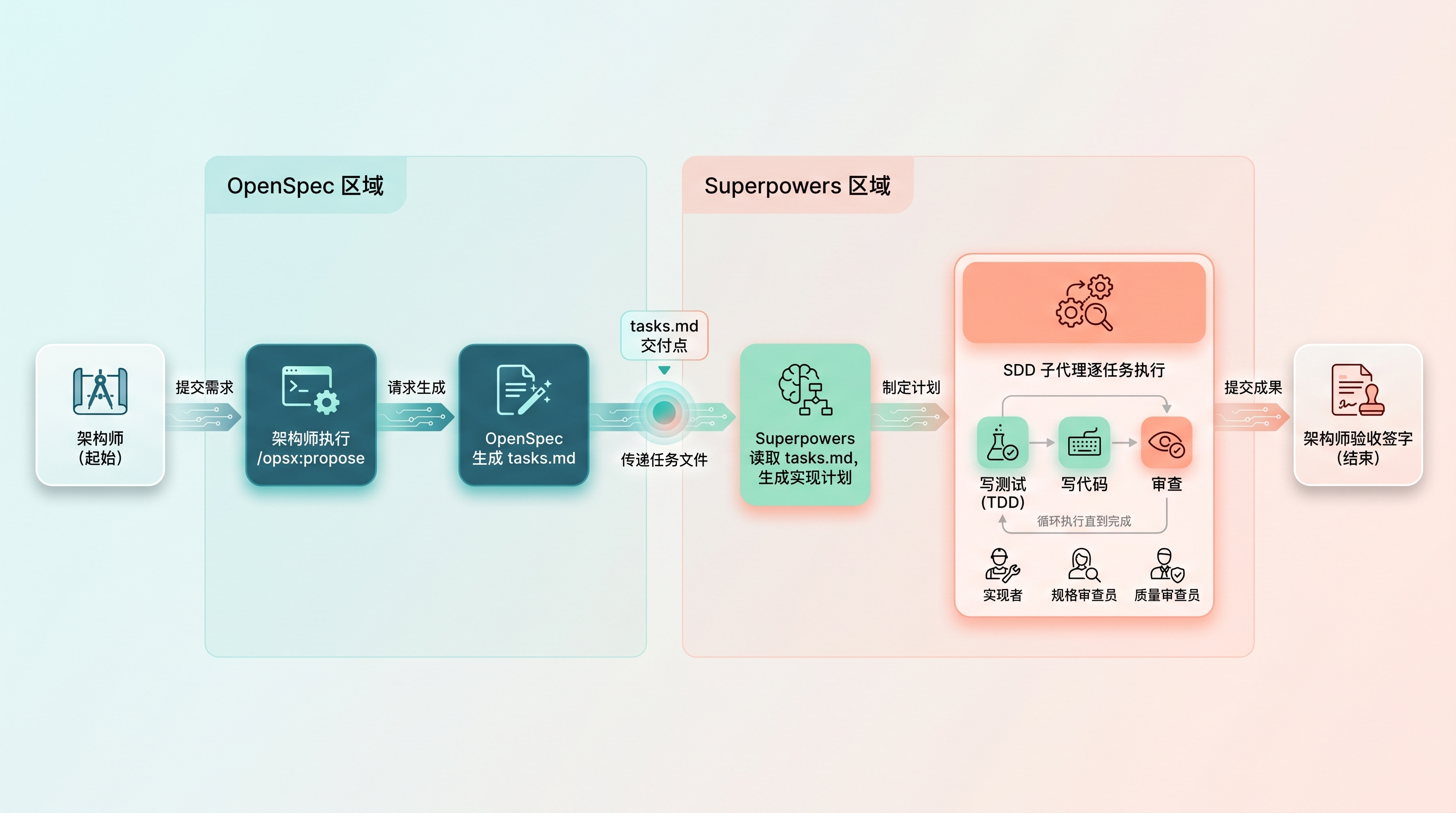
先说清楚一个事实:OpenSpec 和 Superpowers 是两个独立项目,彼此不知道对方的存在。 它们之间没有 API 集成,也没有文件格式的约定。
两个工具各自都有完整的闭环:
- OpenSpec 的闭环:
/opsx:propose→/opsx:apply(自己实现代码)→/opsx:archive - Superpowers 的闭环:brainstorming(自动触发)→ writing-plans(自动跳转)→ subagent-driven-development(自动执行)→ finishing-a-development-branch(收尾)
所谓"联动",是架构师把两个闭环串起来——用 OpenSpec 做规格定义(它擅长这个),用 Superpowers 做代码实现(它擅长 TDD 和代码审查),跳过 OpenSpec 自己的 /opsx:apply。
[OpenSpec 负责] [Superpowers 负责]
/opsx:propose
↓
生成 proposal / specs / design / tasks
↓
架构师审查文档 brainstorming(自动触发)
↓ ↓
架构师将文档内容作为上下文, writing-plans → 自动生成实现计划
告诉 AI "按照这些规格来实现" ↓
↓ subagent-driven-development
手动桥接 ──────────────────→ (子代理逐任务执行 TDD)
↓
finishing-a-development-branch
↓
架构师回到 OpenSpec 执行 ←────── 实现完成
/opsx:archive架构师在整个流程中做四件事:描述意图、审查方案、桥接传递上下文、验收并归档。两个工具之间的衔接,靠的是架构师在同一个 Claude Code 会话里操作——先跑 OpenSpec 的命令,再让 Superpowers 接手实现,最后回到 OpenSpec 归档。
维度 | OpenSpec | Superpowers |
|---|---|---|
关注点 | 规格定义、变更管理 | TDD 执行、代码质量 |
核心产物 | proposal → spec → tasks | plan → code → review |
变更管理 | 增量规格(ADDED/MODIFIED/REMOVED) | Git worktree + 分支 |
测试策略 | Given/When/Then 场景定义 | RED-GREEN-REFACTOR 严格循环 |
二、实战一:从 0 到 1 搭建基础看板
看板系统效果图
场景很明确:实现一个看板管理系统,包含 Column(看板列)和 Task(任务卡片)两个实体的 CRUD。后端用 Go + SQLite,前端用 React + TypeScript。
2.1 Step 1:意图捕获
架构师要做的第一件事,就是告诉 OpenSpec 你想做什么。
在 Claude Code 中执行:
/opsx:propose "创建看板管理系统,包含 Column(name, position) 和 Task(title, description, status) 实体"这条命令执行后,OpenSpec 会自动生成一套完整的规划文档。先看 proposal.md 的关键内容:
# Proposal: Kanban Board System
## Summary
Build a kanban board management system with two core entities:
Column and Task, supporting full CRUD operations.
## Motivation
Need a lightweight project management tool that supports
task organization across customizable columns.然后是 specs/ 目录下的需求规格:
## ADDED Requirements
### Requirement: Column CRUD
The system SHALL support creating, reading, updating,
and deleting board columns.
#### Scenario: Create a new column
- GIVEN no column exists with the name "Todo"
- WHEN the user creates a column with name "Todo"
and position 1
- THEN the column is persisted with the correct
name and position
#### Scenario: Reorder columns
- GIVEN two columns exist: "Todo" (position 1),
"Done" (position 2)
- WHEN the user updates "Todo" position to 2
- THEN "Todo" has position 2 and "Done" shifts
to position 1
### Requirement: Task CRUD
The system SHALL support creating, reading, updating,
and deleting tasks within columns.
#### Scenario: Create a task in a column
- GIVEN a column "Todo" exists
- WHEN the user creates a task with title "Setup DB"
- THEN the task is linked to "Todo" column
with status "todo"最后是 tasks.md 拆分好的任务清单:
# Tasks: Kanban Board System
## Task 1: Database Schema & Models
Create SQLite schema and Go models for Column and Task.
## Task 2: Column API Endpoints
Implement RESTful CRUD endpoints for columns.
## Task 3: Task API Endpoints
Implement RESTful CRUD endpoints for tasks.
## Task 4: Frontend Kanban Board
Build React components for board display and interaction.到这里,架构师需要做的是审查这四份文档。如果需求描述不准确,直接改 proposal 重新生成;如果任务拆分粒度不对,手动调整 tasks.md。
2.2 Step 2:技术规划与桥接
需求文档就绪后,该进入实现了。这里有个选择:你可以直接执行 /opsx:apply 让 OpenSpec 自己实现代码。但如果你想要严格的 TDD 流程和代码审查,就轮到 Superpowers 接手了。
触发 Superpowers 的 brainstorming:在同一个 Claude Code 会话中,直接告诉 AI 你的实现意图。Superpowers 安装后会自动注入一个 SessionStart 钩子,AI 在检测到你要做创造性工作时,会自动激活 brainstorming 技能——不需要手动输入任何命令。
你只需要像这样对话:
请帮我实现这个看板系统,技术栈用 Go + SQLite + React。
我已经用 OpenSpec 定义好了需求,规格文档在 openspec/changes/create-kanban/ 目录下。AI 会自动加载 brainstorming 技能,进入苏格拉底式提问流程:
- 探索项目上下文 — AI 检查现有文件、文档、最近提交
- 逐个提问 — 确认目的、约束、成功标准(一次只问一个问题)
- 提出 2-3 个方案 — 带权衡分析和推荐
- 分段展示设计 — 每段 200-300 字,逐段确认
- 写设计文档 — 保存到
docs/superpowers/specs/YYYY-MM-DD-<topic>-design.md - 自检 — 检查占位符、矛盾、歧义、范围
- 用户审批 — 架构师确认设计文档
注意:brainstorming 过程中,AI 会读取会话上下文。因为前面已经执行了 /opsx:propose,OpenSpec 生成的 proposal、specs、tasks.md 的内容都在上下文里。架构师不需要手动复制粘贴,但需要确认 AI 理解了这些规格。
brainstorming 完成后,AI 自动跳转到 writing-plans 技能——同样不需要手动输入命令。
writing-plans 读取的是 brainstorming 产出的设计文档(docs/superpowers/specs/ 目录),而不是 OpenSpec 的 openspec/changes/ 目录。但因为两个阶段都在同一个会话里,OpenSpec 的规格内容已经在 AI 的上下文窗口中了。
生成的计划文档长这样:
# Kanban Board Implementation Plan
> **For agentic workers:** REQUIRED SUB-SKILL:
> Use superpowers:subagent-driven-development
**Goal:** Build a kanban board with Column and Task CRUD,
backed by SQLite, served via Go REST API, rendered in React.
**Architecture:** Three-tier - SQLite storage layer,
Go HTTP API layer, React SPA frontend.
**Tech Stack:** Go 1.22, SQLite3, gorilla/mux,
React 18, TypeScript, React Testing Library
### Task 1: Database Schema & Models
**Files:**
- Create: `internal/models/column.go`
- Create: `internal/models/task.go`
- Create: `internal/db/schema.sql`
- Test: `internal/models/column_test.go`
- Test: `internal/models/task_test.go`
- [ ] Step 1: Write failing tests for Column model
- [ ] Step 2: Run test to verify it fails (RED)
- [ ] Step 3: Write minimal Column model implementation
- [ ] Step 4: Run test to verify it passes (GREEN)
- [ ] Step 5: Repeat for Task model
- [ ] Step 6: Commit
### Task 2: Column API Endpoints
...架构师审完这份计划,觉得没问题,告诉 AI "go" 就行。
2.3 Step 3:TDD 执行
计划通过后,AI 自动激活 subagent-driven-development 技能——同样不需要手动输入命令。计划文档的头部明确声明了:
> **For agentic workers:** REQUIRED SUB-SKILL:
> Use superpowers:subagent-driven-developmentAI 读到这行,自动切换到子代理驱动模式。
RED 阶段 — 写失败测试:
子代理先写 Column 模型的测试(internal/models/column_test.go):
package models
import (
"database/sql"
"os"
"testing"
_ "github.com/mattn/go-sqlite3"
)
func setupTestDB(t *testing.T) *sql.DB {
t.Helper()
db, err := sql.Open("sqlite3", ":memory:")
if err != nil {
t.Fatalf("Failed to open test db: %v", err)
}
schema, err := os.ReadFile("../../internal/db/schema.sql")
if err != nil {
t.Fatalf("Failed to read schema: %v", err)
}
if _, err := db.Exec(string(schema)); err != nil {
t.Fatalf("Failed to exec schema: %v", err)
}
return db
}
func TestCreateColumn(t *testing.T) {
db := setupTestDB(t)
defer db.Close()
col := &Column{Name: "Todo", Position: 1}
err := col.Create(db)
if err != nil {
t.Fatalf("Create column failed: %v", err)
}
if col.ID == 0 {
t.Error("Expected non-zero ID after create")
}
}
func TestGetColumn(t *testing.T) {
db := setupTestDB(t)
defer db.Close()
col := &Column{Name: "In Progress", Position: 2}
col.Create(db)
got, err := GetColumn(db, col.ID)
if err != nil {
t.Fatalf("GetColumn failed: %v", err)
}
if got.Name != "In Progress" {
t.Errorf("Expected name 'In Progress', got '%s'", got.Name)
}
}
func TestListColumns(t *testing.T) {
db := setupTestDB(t)
defer db.Close()
(&Column{Name: "Todo", Position: 1}).Create(db)
(&Column{Name: "Done", Position: 3}).Create(db)
cols, err := ListColumns(db)
if err != nil {
t.Fatalf("ListColumns failed: %v", err)
}
if len(cols) != 2 {
t.Errorf("Expected 2 columns, got %d", len(cols))
}
}运行测试——报错,因为 Column 结构体和方法还没写。这就对了,RED 通过。
GREEN 阶段 — 写最小实现:
子代理创建数据库 schema(internal/db/schema.sql):
CREATE TABLE IF NOT EXISTS columns (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
position INTEGER NOT NULL DEFAULT 0
);
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT DEFAULT '',
status TEXT NOT NULL DEFAULT 'todo',
column_id INTEGER NOT NULL,
FOREIGN KEY (column_id) REFERENCES columns(id)
);然后写 Column 模型(internal/models/column.go):
package models
import "database/sql"
type Column struct {
ID int64 `json:"id"`
Name string `json:"name"`
Position int `json:"position"`
}
func (c *Column) Create(db *sql.DB) error {
result, err := db.Exec(
"INSERT INTO columns (name, position) VALUES (?, ?)",
c.Name, c.Position,
)
if err != nil {
return err
}
id, _ := result.LastInsertId()
c.ID = id
return nil
}
func GetColumn(db *sql.DB, id int64) (*Column, error) {
c := &Column{}
err := db.QueryRow(
"SELECT id, name, position FROM columns WHERE id = ?", id,
).Scan(&c.ID, &c.Name, &c.Position)
if err != nil {
return nil, err
}
return c, nil
}
func ListColumns(db *sql.DB) ([]*Column, error) {
rows, err := db.Query(
"SELECT id, name, position FROM columns ORDER BY position",
)
if err != nil {
return nil, err
}
defer rows.Close()
var cols []*Column
for rows.Next() {
c := &Column{}
rows.Scan(&c.ID, &c.Name, &c.Position)
cols = append(cols, c)
}
return cols, nil
}运行测试——全部通过。GREEN 达成。
Task 模型走同样的流程,这里展示最终的实现(internal/models/task.go):
package models
import "database/sql"
type Task struct {
ID int64 `json:"id"`
Title string `json:"title"`
Description string `json:"description"`
Status string `json:"status"`
ColumnID int64 `json:"column_id"`
}
func (t *Task) Create(db *sql.DB) error {
result, err := db.Exec(
`INSERT INTO tasks (title, description, status, column_id)
VALUES (?, ?, ?, ?)`,
t.Title, t.Description, t.Status, t.ColumnID,
)
if err != nil {
return err
}
id, _ := result.LastInsertId()
t.ID = id
return nil
}
func ListTasksByColumn(db *sql.DB, columnID int64) ([]*Task, error) {
rows, err := db.Query(
`SELECT id, title, description, status, column_id
FROM tasks WHERE column_id = ?`, columnID,
)
if err != nil {
return nil, err
}
defer rows.Close()
var tasks []*Task
for rows.Next() {
t := &Task{}
rows.Scan(&t.ID, &t.Title, &t.Description,
&t.Status, &t.ColumnID)
tasks = append(tasks, t)
}
return tasks, nil
}API 层(internal/api/column_handler.go):
package api
import (
"database/sql"
"encoding/json"
"net/http"
"kanban/internal/models"
)
type ColumnHandler struct {
DB *sql.DB
}
func (h *ColumnHandler) Create(w http.ResponseWriter, r *http.Request) {
var col models.Column
if err := json.NewDecoder(r.Body).Decode(&col); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
if err := col.Create(h.DB); err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(http.StatusCreated)
json.NewEncoder(w).Encode(col)
}
func (h *ColumnHandler) List(w http.ResponseWriter, r *http.Request) {
cols, err := models.ListColumns(h.DB)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(cols)
}每个任务完成后,Spec Compliance Reviewer 会逐行对比代码和 Superpowers 自己的实现计划是否一致。通过后,Code Quality Reviewer 再审一轮代码质量。两轮审查都过了,这个任务才算完成。
TDD 循环图
你在项目中用过类似的 AI 辅助开发方案吗?欢迎在评论区聊聊实际体验。
三、实战二:增量迭代与变更管理
基础看板跑起来了。现在产品经理说:给卡片加个优先级,High 显示红色,Medium 显示黄色,Low 显示绿色。
传统做法是改数据库、改模型、改 API、改前端、改测试——至少牵涉五个文件。看看 OpenSpec + Superpowers 怎么处理。
3.1 Step 1:变更提案
架构师发起增量更新:
/opsx:propose "在 Task 实体中增加 Priority 字段(High/Medium/Low,默认 Medium);前端 Card 组件需根据优先级渲染边框颜色"OpenSpec 不会重新生成整套文档。它只生成增量规格:
## MODIFIED Requirements
### Requirement: Task Entity
The system SHALL support a Priority field on Task entities.
#### Scenario: Create task with explicit priority
- GIVEN a column "Todo" exists
- WHEN the user creates a task with priority "High"
- THEN the task is persisted with priority "High"
#### Scenario: Create task with default priority
- GIVEN a column "Todo" exists
- WHEN the user creates a task without specifying priority
- THEN the task defaults to priority "Medium"
## ADDED Requirements
### Requirement: Priority-Based Card Styling
The system SHALL render task cards with colored borders
based on priority level.
#### Scenario: High priority card display
- GIVEN a task with priority "High" exists
- WHEN the kanban board is rendered
- THEN the task card displays a red border同时生成增量 tasks.md(只包含变更相关的任务):
# Tasks: Add Priority to Tasks
## Task 1: Add Priority field to Task model and DB schema
## Task 2: Update Task API to handle Priority field
## Task 3: Update frontend Card component for priority colors
## Task 4: Update existing tests to cover Priority logic3.2 Step 2:审查增量规格
注意:/opsx:propose 生成的增量 specs 目前还在 openspec/changes/add-priority/specs/ 目录下,不会自动合并到主 specs。它们只是这个变更自己的 delta 描述。合并要等到最后 archive 阶段。
架构师现在要做的是审查增量规格和 tasks.md,确认变更范围合理、场景覆盖完整。审查通过后,继续实现。
3.3 Step 3:自动化注入
这是关键环节。架构师审查完增量规格后,在同一个 Claude Code 会话中告诉 AI "按照新的增量规格来实现"。因为 OpenSpec 的增量 tasks.md 已经在会话上下文中,Superpowers 的子代理会基于这些上下文来注入变更。
后端变更 — 数据库 Schema:
-- 变更:新增 priority 列
ALTER TABLE tasks ADD COLUMN priority TEXT NOT NULL DEFAULT 'medium';
-- 更新后的完整 schema
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT DEFAULT '',
status TEXT NOT NULL DEFAULT 'todo',
priority TEXT NOT NULL DEFAULT 'medium',
column_id INTEGER NOT NULL,
FOREIGN KEY (column_id) REFERENCES columns(id)
);后端变更 — Task 模型:
// 变更 diff
type Task struct {
ID int64 `json:"id"`
Title string `json:"title"`
Description string `json:"description"`
Status string `json:"status"`
+ Priority string `json:"priority"` // 新增字段
ColumnID int64 `json:"column_id"`
}
func (t *Task) Create(db *sql.DB) error {
result, err := db.Exec(
`INSERT INTO tasks (title, description, status, priority, column_id)
- VALUES (?, ?, ?, ?)`,
+ VALUES (?, ?, ?, ?, ?)`,
- t.Title, t.Description, t.Status, t.ColumnID,
+ t.Title, t.Description, t.Status, t.Priority, t.ColumnID,
)
// ...
}
// 新增:校验 Priority 合法性
func isValidPriority(p string) bool {
return p == "high" || p == "medium" || p == "low"
}前端变更 — TypeScript 类型:
// types/task.ts
export interface Task {
id: number;
title: string;
description: string;
status: string;
priority: "high" | "medium" | "low"; // 新增
columnId: number;
}前端变更 — Card 组件样式:
// components/TaskCard.tsx
import React from "react";
import { Task } from "../types/task";
const priorityColors: Record<Task["priority"], string> = {
high: "#ef4444", // 红色
medium: "#f59e0b", // 黄色
low: "#22c55e", // 绿色
};
export const TaskCard: React.FC<{ task: Task }> = ({ task }) => {
return (
<div
style={{
borderLeft: `4px solid ${priorityColors[task.priority]}`,
padding: "12px",
borderRadius: "4px",
backgroundColor: "#fff",
marginBottom: "8px",
}}
>
<h4>{task.title}</h4>
<p>{task.description}</p>
<span style={{ color: priorityColors[task.priority] }}>
{task.priority.toUpperCase()}
</span>
</div>
);
};测试变更 — 覆盖 Priority 逻辑:
func TestCreateTaskWithPriority(t *testing.T) {
db := setupTestDB(t)
defer db.Close()
// 先创建一个 Column
col := &Column{Name: "Todo", Position: 1}
col.Create(db)
// 测试显式指定 priority
t.Run("explicit priority", func(t *testing.T) {
task := &Task{
Title: "Bug fix", Status: "todo",
Priority: "high", ColumnID: col.ID,
}
err := task.Create(db)
if err != nil {
t.Fatalf("Create task failed: %v", err)
}
got, _ := GetTask(db, task.ID)
if got.Priority != "high" {
t.Errorf("Expected priority 'high', got '%s'", got.Priority)
}
})
// 测试默认 priority
t.Run("default priority", func(t *testing.T) {
task := &Task{
Title: "Refactor", Status: "todo",
ColumnID: col.ID,
}
task.Create(db)
got, _ := GetTask(db, task.ID)
if got.Priority != "medium" {
t.Errorf("Expected default 'medium', got '%s'", got.Priority)
}
})
// 测试非法 priority
t.Run("invalid priority rejected", func(t *testing.T) {
task := &Task{
Title: "Hack", Status: "todo",
Priority: "urgent", ColumnID: col.ID,
}
err := task.Create(db)
if err == nil {
t.Error("Expected error for invalid priority")
}
})
}子代理跑完测试,RED → GREEN 循环完成。Spec Compliance Reviewer 对比实现计划和实际代码,确认 Priority 的三个场景(显式指定、默认值、非法值)都覆盖了。通过。
所有任务完成后,Superpowers 自动进入 finishing-a-development-branch 技能——验证测试、选择合并或保持分支。这一步也是自动触发,不需要手动输入命令。
3.4 Step 4:验收与归档
实现完成后,回到 OpenSpec 做验收。
如果项目启用了 expanded workflow(通过 openspec config profile 配置),可以执行 /opsx:verify 做三维度的自动检查——完整性(任务是否都完成)、正确性(实现是否匹配规格意图)、一致性(设计决策是否反映在代码中)。
如果用的是默认 core profile,没有 /opsx:verify 命令。架构师需要手动审查代码和测试,确认变更符合增量规格中的场景定义。
验收通过后,执行归档:
/opsx:archive add-priorityarchive 命令会提示:增量 specs 还没有同步到主 specs,是否现在同步?选择是——delta specs 合并到 openspec/specs/,变更文件夹移动到 openspec/changes/archive/ 目录。下一轮迭代又可以开始了。
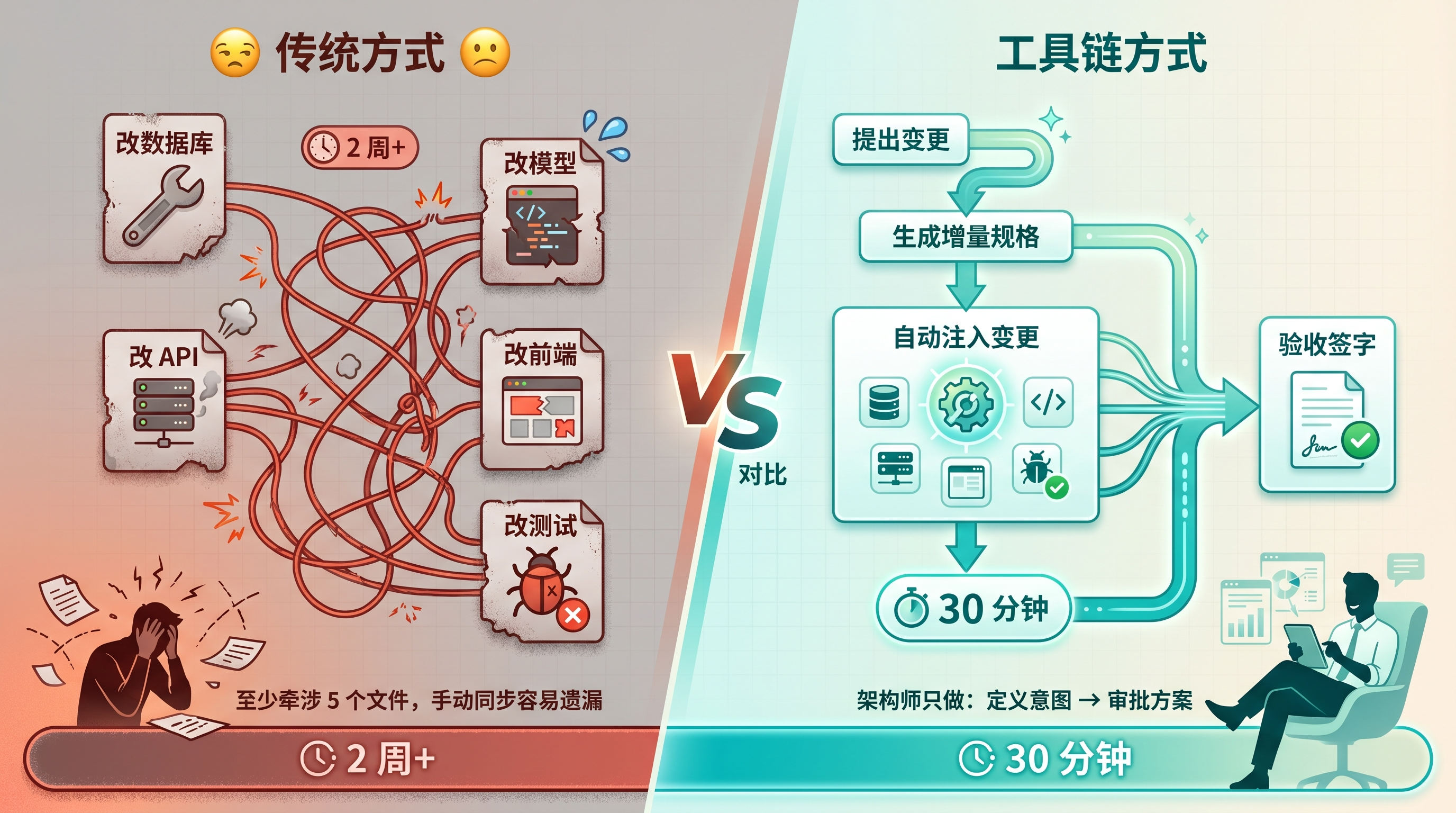
增量迭代对比图
四、架构师的权力清单
整个流程下来,架构师需要签字的关键节点:
节点 | 什么时候 | 架构师做什么 | 工具 |
|---|---|---|---|
意图定义 | 每轮迭代开始 | 执行 | OpenSpec |
方案审查 | propose 之后 | 审查 proposal、spec、design、tasks | OpenSpec |
桥接传递 | 规划阶段 | 在同一会话中触发 brainstorming,确认 AI 理解了 OpenSpec 规格 | Superpowers(自动触发) |
计划审批 | brainstorming 之后 | 审查 writing-plans 输出的实现计划 | Superpowers(自动跳转) |
验收签字 | 执行之后 | expanded profile 用 | OpenSpec |
归档确认 | 验收通过后 |
| OpenSpec |
说白了,架构师不再写代码,但每个关键决策点都需要你的判断。AI 可以自动生成文档和代码,但需求是否准确、方案是否合理、实现是否达标——这些判断只有人能做。
总结:一人即团队
OpenSpec + Superpowers 的组合,本质上做了一件事:把架构师从执行层解放出来,让你只做决策。
以前一个看板系统需要:一个架构师画图、一个后端写 API、一个前端搭界面,协同排期加调试,少说一两周。现在架构师一个人,用两轮 propose + execute,就能从需求到代码到测试全部搞定。
但话说回来,这套模式有适用边界。
适合的场景:CRUD 类业务系统、管理后台、内部工具、独立开发者的 Side Project。这类系统的特点是需求明确、技术栈标准、变更模式可预测。
不太适合的场景:高性能计算、复杂的分布式系统、需要深度领域建模的业务(比如交易系统、推荐算法)。这些场景的决策点太多太密,AI 生成的规格和代码很难一次到位,反而需要大量返工。
工具链再好,也只是放大器。它能放大一个架构师的产出,但不能替代架构师的判断力。如果你的设计本身有问题,AI 只会帮你更快地产出有问题的代码。
必须说明的一点:这篇文章的工作流是从两个项目的官方文档(README、docs 目录、SKILL.md 源码)推导出来的理论组合流程,不是跑通全流程后的实录。文中的代码(Go 模型、React 组件、测试用例)是为了演示完整度而编写的示例,不是实际运行中 AI 生成的产物。
说几个你实际操作时大概率会碰到的问题:
- 上下文传递不是硬保证。 Superpowers 的 brainstorming 能否准确"接住"OpenSpec 的
/opsx:propose产物,取决于 AI 的上下文窗口大小和会话管理策略。会话太长、中间插入其他对话,都可能导致上下文丢失。 - 两个工具在同一会话中共存有边界情况。 技能触发优先级、上下文互相污染、命令冲突这些情况,文章没有覆盖。实际使用中可能需要清一次上下文再切换工具。
- 增量 propose 的质量不可控。 OpenSpec 的
/opsx:propose在已有项目上做增量更新时,delta specs 写得好不好,取决于 AI 对现有 specs 的理解程度。复杂项目里,你可能需要手动修改 AI 生成的增量规格。
建议:如果你想复现这套流程,先分别把两个工具各自的闭环跑通——OpenSpec 自己跑完 propose → apply → archive,Superpowers 自己跑完 brainstorming → writing-plans → subagent-driven-development。两个都熟了,再尝试组合。不要上来就串联,排查问题会很痛苦。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号