Qwen3.6-27B 量化版本推荐,本地部署

Qwen3.6-27B 量化版本推荐,本地部署

Ai学习的老章
发布于 2026-04-24 21:08:39
发布于 2026-04-24 21:08:39
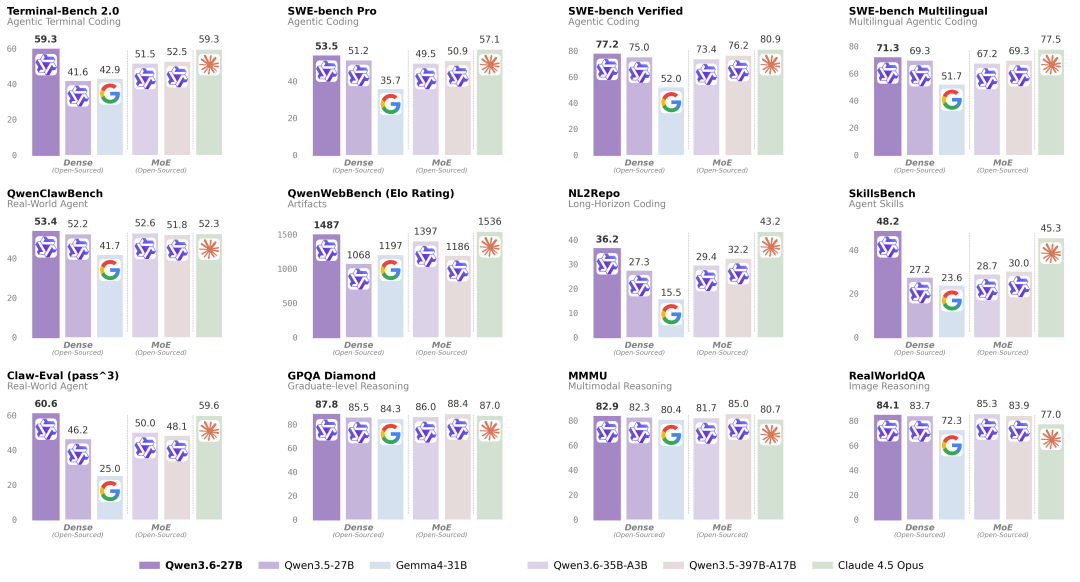
Qwen3.6-35B,量化、蒸馏版本推荐 Qwen3.6-35B 量化版,vLLM本地部署,性能实测
Qwen3.6-27B 开源了,27B 小身板干翻 397B 巨无霸一文讲过 Qwen3.6-27B 原版 FP16 的 27B 模型,文件 55GB,太大了
好消息是 Qwen3.6-27B 开源24小时内,量化版本就已经百花齐放了——FP8、AWQ-INT4、NVFP4、GGUF、MLX,从服务端 vLLM 到 Mac 本地、到消费级显卡,各种部署场景都能找到对应的版本
本文推荐几个 Qwen3.6-27B 量化版本,以及本地部署教程
第一路:vLLM 服务端部署
生产环境的首选,兼顾速度和并发,Qwen3.6 官方推荐 vllm>=0.19.0 起步
1. 官方 FP8 版本(最稳)
Qwen/Qwen3.6-27B-FP8
这是 Qwen 官方自己放出来的 FP8 量化,细粒度 fp8 量化,block size = 128,官方原话:性能指标几乎跟原版一模一样
文件大小比 FP16 原版直接砍半(27B 模型约 27GB 权重),兼容 Transformers / vLLM / SGLang / KTransformers,基本上是零风险选项
启动命令:
vllm serve Qwen/Qwen3.6-27B-FP8 \
--port 8000 \
--tensor-parallel-size 2 \
--max-model-len 262144 \
--reasoning-parser qwen3
要开工具调用加一句:
--enable-auto-tool-choice --tool-call-parser qwen3_coder
想开 MTP(Multi-Token Prediction)推测解码提速:
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
适合谁:两张 A100/H100/L40S 起,追求最稳妥部署的生产环境
2. AWQ-INT4 版本(消费级友好)
cyankiwi/Qwen3.6-27B-AWQ-INT4
社区开发者 cyankiwi 做的 AWQ(Activation-aware Weight Quantization)4bit 量化,文件压到 20GB 左右
这个版本上个周期的 Qwen3.5-35B-A3B 就是他家出的,vLLM 0.19 直接拉起来,单卡 4090 就能跑,双卡可以支撑更大上下文
启动脚本参考:
vllm serve cyankiwi/Qwen3.6-27B-AWQ-INT4 \
--port 8000 \
--max-model-len 65536 \
--gpu-memory-utilization 0.9 \
--reasoning-parser qwen3 \
--trust-remote-code
适合谁:家用消费级卡(4090、3090、5090)、或者两张 4090 想拉高上下文的玩家
3. NVFP4 版本(Blackwell 专属)
英伟达加速版 Qwen3.6-35B,双4090本地部署,性能实测
sakamakismile/Qwen3.6-27B-NVFP4
这个是 Lna-Lab 团队用 NVFP4 格式做的量化——权重 FP4、激活 FP4、scale FP8,真正的 W4A4
关键数据:55.6 GB → 19.7 GB,压缩比 0.35x,vision tower 保留在 BF16,单张 Blackwell GPU 能跑
量化配方很克制,只量化语言模型的 Linear 层:
QuantizationModifier:
targets: [Linear]
ignore: [lm_head, 're:.*visual.*', 're:.*mlp.gate$', 're:.*mlp.shared_expert_gate$']
scheme: NVFP4
启动:
vllm serve sakamakismile/Qwen3.6-27B-NVFP4 \
--max-model-len 8192 \
--gpu-memory-utilization 0.92 \
--dtype auto \
--trust-remote-code
硬性要求:NVIDIA Blackwell GPU(SM 120),vLLM ≥ 0.19
作者在 RTX PRO 6000 Blackwell(96GB)上实测过
适合谁:手里有 5090 / 5090D / RTX PRO 6000 这类 Blackwell 卡的,NVFP4 是目前 Blackwell 架构吃得最香的格式
第二路:GGUF 本地部署(llama.cpp)
GGUF 是 llama.cpp 的亲儿子格式,家用 PC、Mac、甚至 CPU 纯推都能跑
1. Unsloth Dynamic 2.0 GGUF(推荐)
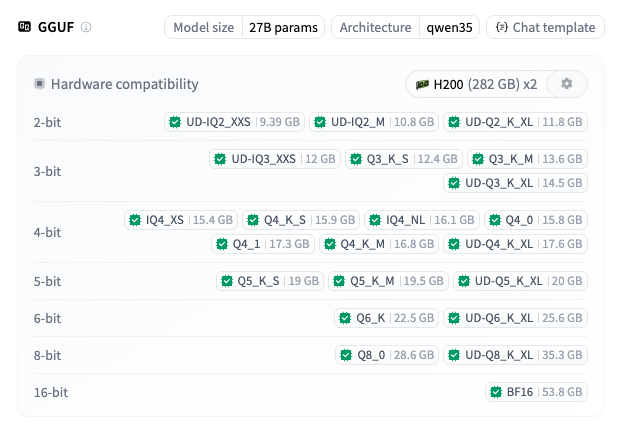
unsloth/Qwen3.6-27B-GGUF
Unsloth 家的 Dynamic 2.0 量化,基于真实世界数据集做校准,关键层做 upcast,同等 bit 数下质量比普通 GGUF 好不少
官方的硬件表直接给出需求(RAM+VRAM 总和,或统一内存):
量化 | 27B 需求 |
|---|---|
UD-Q2_K_XL | 15 GB |
UD-Q4_K_XL | 18 GB |
Q5_K_M | 24 GB |
Q6_K | 30 GB |
Q8_0 | 55 GB |
Unsloth 推荐日常用 UD-Q4_K_XL,24GB RAM 或者 Mac 设备都能流畅跑
⚠️ 两个关键坑位(Unsloth 官方文档明确提醒):
- 不要用 CUDA 13.2,会输出乱码,NVIDIA 正在修
- 目前 Ollama 跑不了 Qwen3.6 GGUF,因为 mmproj 视觉文件是分离的,只能用兼容 llama.cpp 的后端
llama.cpp 启动命令示例:
./llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:UD-Q4_K_XL \
--jinja \
--ctx-size 32768 \
--n-gpu-layers 99
推理参数(非常重要,hybrid reasoning 两种模式不一样):
Thinking 模式(一般任务):temperature=0.6, top_p=0.95, top_k=20, min_p=0.0
Non-thinking 模式(一般任务):temperature=1.0, top_p=0.95, top_k=20, presence_penalty=1.5
2. LM Studio 社区版 GGUF
lmstudio-community/Qwen3.6-27B-GGUF
LM Studio 团队基于 llama.cpp b8883 做的量化。如果你用 LM Studio 作为本地大模型面板,这个版本集成度最好,直接在 LM Studio 里搜索就能下载。
量化质量上,比 Unsloth Dynamic 2.0 略朴素——没有针对关键层 upcast,但胜在工具链集成完整、开箱即用
3. Unsloth UD-MLX-4bit(Mac 专属)
unsloth/Qwen3.6-27B-UD-MLX-4bit
Unsloth 团队也出了动态 MLX 4bit 版本,专门给 Apple Silicon 用。
Unsloth 给了一键脚本:
curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/scripts/install_qwen3_6_mlx.sh | sh
source ~/.unsloth/unsloth_qwen3_6_mlx/bin/activate
python -m mlx_vlm.chat --model unsloth/Qwen3.6-27B-UD-MLX-4bit
Mac Studio / MacBook Pro M 系列,32GB 以上统一内存都能跑
第三路:苹果 MLX 生态
mlx-community/Qwen3.6-27B-nvfp4
mlx-community/Qwen3.6-27B-nvfp4
MLX 社区基于 mlx-vlm 0.4.4 做的 NVFP4 格式 Mac 专用版。跟服务端的 NVFP4 不是一回事——这个是 MLX 格式,走 Apple Silicon 的 Metal。
调用非常简单:
pip install -U mlx-vlm
python -m mlx_vlm.generate \
--model mlx-community/Qwen3.6-27B-nvfp4 \
--max-tokens 100 \
--temperature 0.0 \
--prompt "Describe this image." \
--image <path_to_image>
适合谁:Mac 用户里想吃 MLX 生态的(MLX 在苹果芯片上的性能往往比 llama.cpp-metal 更好)。
怎么选?一张表决定
场景 | 推荐版本 | 核心原因 |
|---|---|---|
生产部署(双卡 A100/H100) | 官方 FP8 | 原汁原味,几乎无损 |
消费级单卡(4090/3090) | cyankiwi AWQ-INT4 | 15GB 能装下,vLLM 直接跑 |
Blackwell 卡(5090/RTX PRO 6000) | sakamakismile NVFP4 | 充分利用 FP4 算力 |
Windows/Linux PC + 24GB 显存 | Unsloth UD-Q4_K_XL | 动态量化质量最好 |
用 LM Studio 做面板 | lmstudio-community GGUF | 工具链集成最好 |
Mac Studio / MacBook | Unsloth MLX-4bit 或 mlx-community nvfp4 | 走 MLX 吃满 Metal |
低配机器 + 大内存 | Unsloth UD-Q2_K_XL | 15GB 就能跑 |
几个通用注意事项
- Qwen3.6-27B 是 dense 模型,不是 MoE。跟 Qwen3.6-35B-A3B 不一样,后者是 3B 激活的 MoE,跑起来更快。27B dense 的优势是能力更稳定、没有专家路由的不确定性
- 上下文默认 262K。OOM 的话把
--max-model-len/--ctx-size降下来,但 Unsloth 建议至少保 128K 来保住 thinking 能力 - hybrid reasoning 两种模式参数差异大。写代码用 thinking 模式 + temp=0.6,写文用 non-thinking + temp=1.0,别搞混
- Ollama 暂时跑不了,等 Ollama 适配 mmproj 分离结构
下篇文章咱们聊聊 Qwen3.6-27B 的另一个神奇版本,推理风格有大变化
#Qwen3.6 #本地部署 #vLLM #GGUF #量化
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号