月之暗面(Moonshot AI)和清华大学最新研究:推理吞吐量暴涨54%

月之暗面(Moonshot AI)和清华大学最新研究:推理吞吐量暴涨54%

Ai学习的老章
发布于 2026-04-24 21:06:56
发布于 2026-04-24 21:06:56
紧跟Kimi K2.6,推一篇有点脑洞的论文,来自月之暗面(Moonshot AI)和清华大学的最新联合研究
一句话说清楚:这论文在搞什么?
把 Prefill(预填充)变成一种跨数据中心的云服务。
听起来有点抽象?我换个说法:以前大模型推理的 Prefill 和 Decode 两个阶段必须待在同一个机房里,因为中间传输的 KVCache 太大了,跨机房根本搬不动
而这篇论文说,新一代混合注意力模型的 KVCache 缩小了十几倍甚至几十倍,我们可以把 Prefill 拆出去、放到另一个机房的高算力集群上跑,然后用普通以太网把 KVCache 传回来做 Decode
这个架构叫做 Prefill-as-a-Service(PrfaaS),实测吞吐量比同构 PD 部署高 54%,比朴素异构方案高 32%

地址 arxiv.org/abs/2604.15039
地址 arxiv.org/abs/2604.15039
为什么要搞跨数据中心?
先说背景
PD 分离(Prefill-Decode Disaggregation)已经是大规模 LLM 推理的标准范式了
Moonshot AI 自家的 Mooncake 系统就是这个方向的先行者,后来跟 vLLM、SGLang、Dynamo 都做了深度合作,把 KVCache 当成 vip 来管理
PD 分离的原理很简单:Prefill 是计算密集型的,Decode 是内存带宽密集型的,两者对硬件的需求完全不同
理论上,我们应该用算力强的芯片专门跑 Prefill,用带宽大的芯片专门跑 Decode——这就是所谓的异构推理
但现实很骨感,问题出在 KVCache 传输上
下图展示了传统单集群 PD 推理(左)和 PrfaaS 跨数据中心推理(右)的对比:
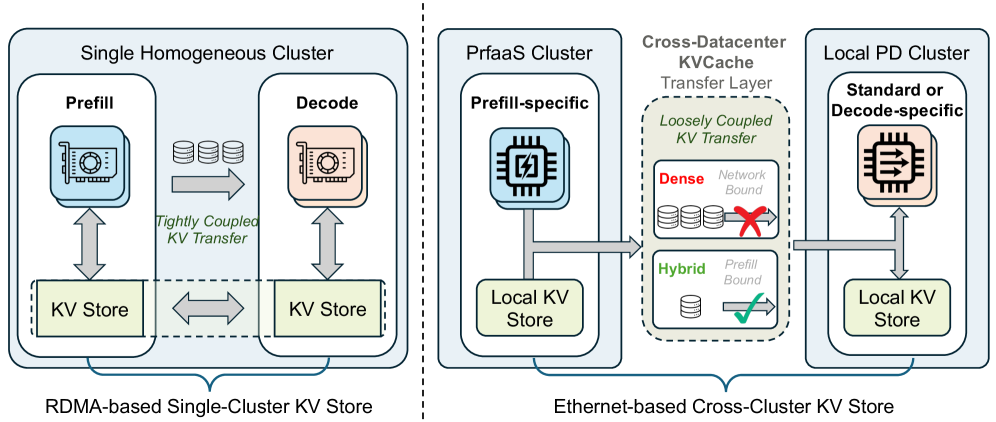
传统PD架构 vs PrfaaS架构
传统PD架构 vs PrfaaS架构
在传统的 Dense Attention 模型里,一个 32K token 的请求,单个 MiniMax-M2.5 实例产生的 KVCache 传输速率高达约 60 Gbps。这什么概念?一台机器的跨数据中心以太网带宽都扛不住。所以 Prefill 和 Decode 必须共享同一个高带宽 RDMA 网络,被死死绑在同一个机房里
下图展示了 MiniMax-M2.5 在不同输入长度下的 KV 吞吐量,可以看到带宽需求有多恐怖:
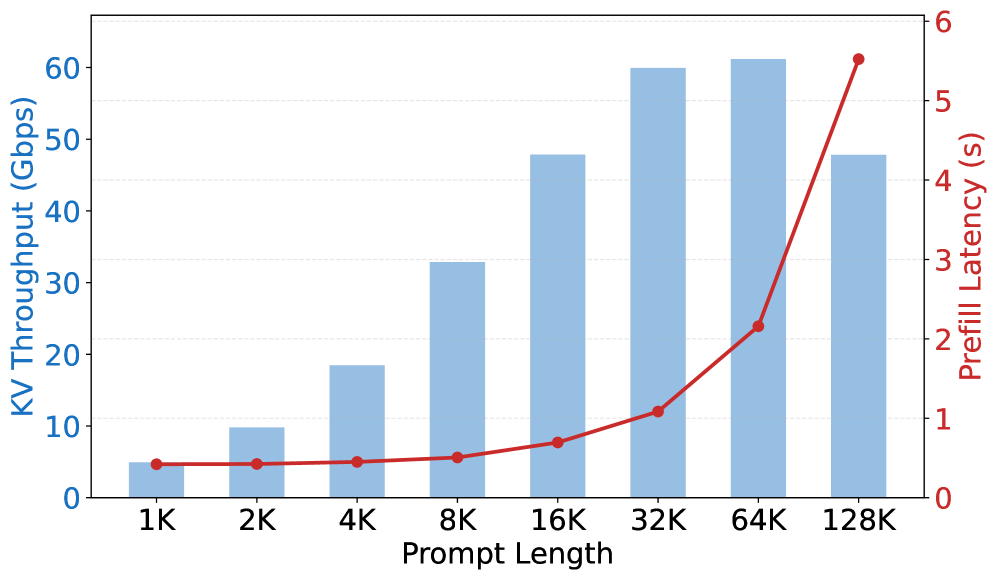
MiniMax-M2.5 KV吞吐量
MiniMax-M2.5 KV吞吐量
这就导致了一个尴尬局面:你想搞异构推理?可以,但你得把不同类型的芯片塞进同一个 RDMA 集群里。这在运维上极其僵化——你连 Prefill 和 Decode 的硬件比例都没法灵活调整
混合注意力模型改变了游戏规则
这篇论文指出了一个关键的转折点:新一代的混合注意力架构,正在从根本上改变 KVCache 的大小
什么是混合注意力?简单说就是在模型里只保留少量的全注意力层(Full Attention),大部分层用线性注意力(Linear Attention)或滑动窗口注意力(SWA)替代。这些层产生的 KVCache 大小是固定的,不会随输入长度线性增长
论文里列出了一组最新的混合注意力模型:
模型 | 架构比例 | KV 吞吐量@32K |
|---|---|---|
MiniMax-M2.5(Dense) | 全 GQA | ~60 Gbps |
Qwen3-235B(Dense) | 全 MLA | ~33 Gbps |
Qwen3.5-397B | 3:1 线性:全注意力 | ~8 Gbps |
MiMo-V2-Flash | 5:1 SWA:全注意力 | ~4.7 Gbps |
Ring-2.5-1T | 7:1 线性:全注意力 | 更低 |
看到了吗?从 60 Gbps 直接降到 4.7 Gbps,降了 13 倍!Ring-2.5-1T 更是靠 MLA + 7:1 混合比例实现了约 36 倍的 KV 内存节省。
这个数量级的变化意味着:KVCache 终于可以用普通以太网跨数据中心传了。
但是!光靠模型架构还不够
论文强调得很清楚:实际工作负载是突发的,请求长度严重不均,前缀缓存分布不平衡,跨集群带宽还会波动。如果傻乎乎地把所有 Prefill 都扔到远端集群,照样会拥塞、排队、利用率低下
模型让跨数据中心传输变得"可能",但要让它"实用",还需要系统层面的精心设计
PrfaaS 的核心设计
PrfaaS 的架构相当优雅,核心思想是 **"选择性卸载"**——只把值得的请求送到远端。
下图是 PrfaaS-PD 的部署拓扑:
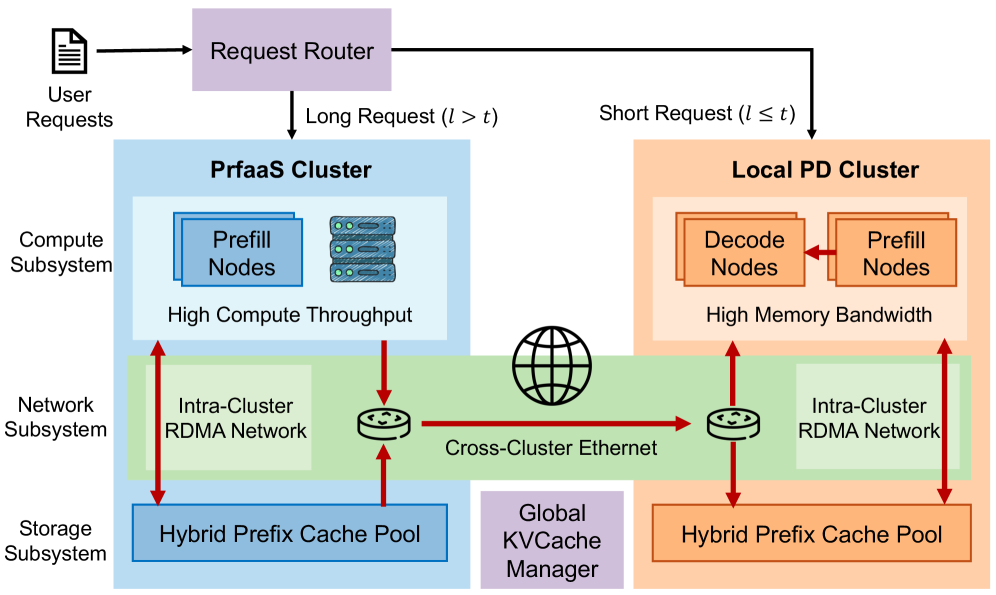
PrfaaS-PD 架构部署图
PrfaaS-PD 架构部署图
整个系统分为三个子系统:
1. 计算子系统
- PrfaaS 集群:高算力硬件(如 H200),专门处理长上下文 Prefill
- 本地 PD 集群:常规硬件(如 H20),负责短请求的 Prefill + 所有请求的 Decode
2. 网络子系统
- 集群内部:RDMA 高带宽互联
- 集群之间:普通以太网(VPC 对等连接或专线)
3. 存储子系统:混合前缀缓存池
这个设计很巧妙。混合注意力模型里有两种不同的 KVCache:
- 线性注意力层的递归状态:大小固定,只能精确匹配复用
- 全注意力层的 KVCache:随长度线性增长,支持前缀部分匹配
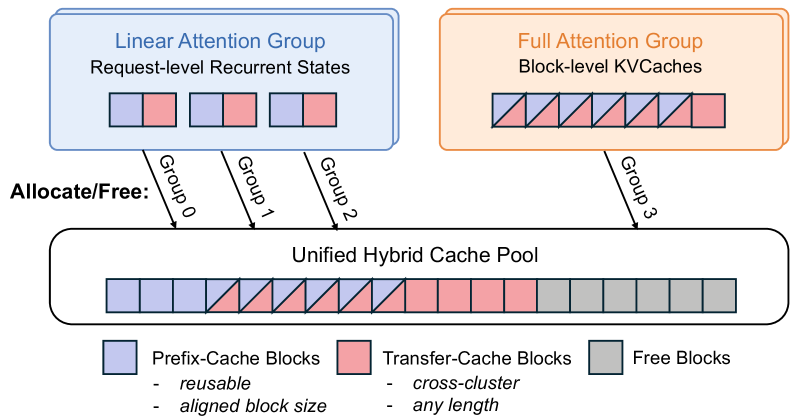
混合前缀缓存池架构
混合前缀缓存池架构
PrfaaS 把这两类 KVCache 分组管理,但共享底层的内存池。缓存块分为两类:前缀缓存块(可跨请求复用)和传输缓存块(传完即丢)。全局 KVCache 管理器维护所有集群的缓存元数据,调度器据此决定请求路由。
关键调度策略:双时间尺度调度
这是论文最硬核的部分。PrfaaS 的调度器分两个层面运作:
短期调度:带宽感知 + 缓存感知路由
设一个长度阈值 t,请求的增量 Prefill 长度(去掉缓存命中的前缀后)超过 t 的,发到 PrfaaS 集群;不超过的,留在本地 PD 集群处理。
为什么这样做?因为短请求的 Prefill 通常是内存瓶颈(不是计算瓶颈),送到高算力集群反而浪费;而且短请求的 KV 吞吐量相对更高,会更快吃满跨集群带宽。
调度器还会实时监控 PrfaaS 集群的出口链路利用率和队列深度:
- 带宽紧张时:各集群的前缀缓存独立评估,尽量减少跨集群传输
- 带宽充裕时:全局最优缓存匹配,甚至允许跨集群缓存迁移
长期调度:流量驱动的资源再分配
本地 PD 集群内的 Prefill/Decode 实例比例可以动态调整。当流量模式变化时,调度器会重新计算最优的 Np/Nd 比例和路由阈值 t。
实验结果:54% 吞吐量提升
论文用内部一个 1T 参数的混合架构模型(基于 Kimi Linear 架构,3:1 KDA:MLA 层比例)做了案例研究。
硬件配置:
- PrfaaS 集群:32 个 H200 GPU(高算力,专跑长上下文 Prefill)
- 本地 PD 集群:64 个 H20 GPU(常规 PD 模式,800 Gbps RDMA)
- 跨集群带宽:约 100 Gbps VPC 网络
- 对比基线:96 个 H20 GPU 的同构 PD 集群
工作负载:
- 输入长度:截断对数正态分布,均值约 27K tokens,范围 128~128K
- 输出长度:固定 1024 tokens
- SLO:40 tokens/s
下图展示了最优参数搜索过程——找到最佳的 Prefill/Decode 分配比和路由阈值:
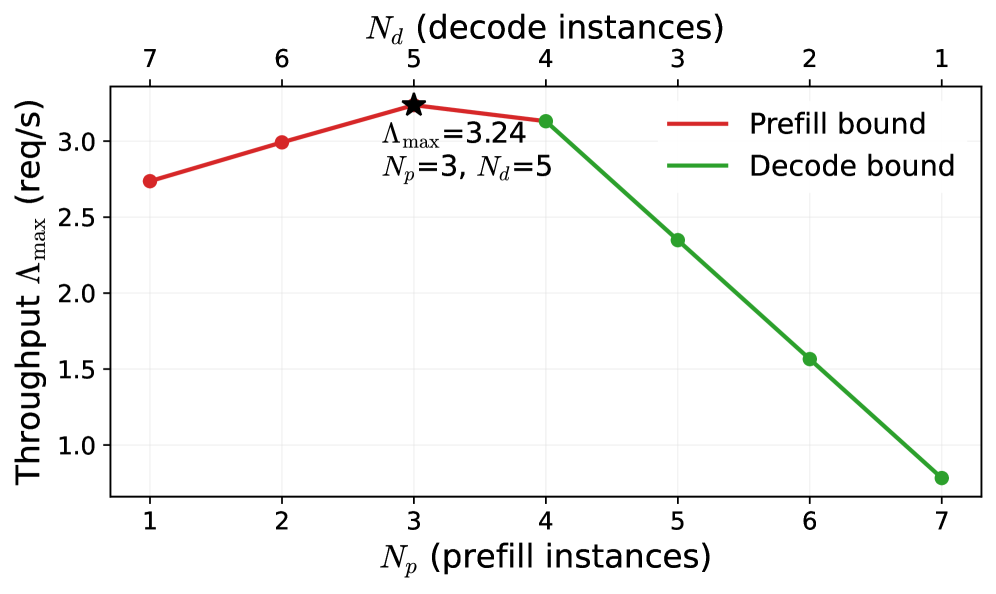
参数搜索过程
参数搜索过程
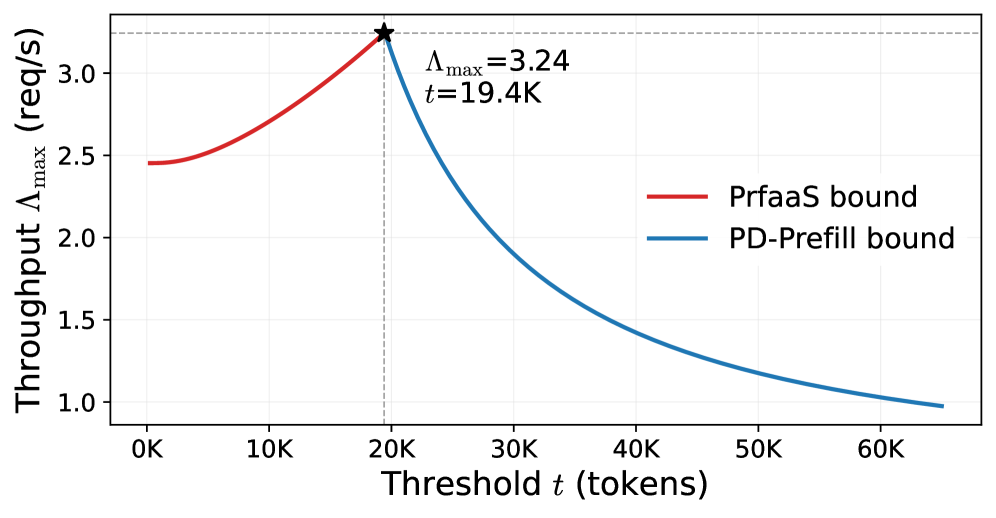
路由阈值搜索
路由阈值搜索
最优配置:
- 路由阈值 t = 19.4K tokens
- 本地 PD 集群:3 个 Prefill 实例 + 5 个 Decode 实例
- 约 50% 的请求(长请求)被卸载到 PrfaaS 集群
核心结果:
指标 | PrfaaS-PD | 同构 PD | 朴素异构 PD |
|---|---|---|---|
吞吐量提升 | 基准 | 低 54% | 低 32% |
P90 TTFT | 基准 | 高 64% | - |
跨集群带宽消耗 | 13 Gbps | 不适用 | 更高 |
最让我惊艳的数字:PrfaaS 集群的平均出口带宽仅 13 Gbps,只占 100 Gbps 以太网链路的 13%。 这说明混合注意力模型的 KVCache 跨数据中心传输不仅可行,而且还有巨大的余量!
而朴素异构方案(不做选择性卸载,所有 Prefill 都扔到 H200)只提升了 16% 吞吐量,被 PrfaaS-PD 的 54% 远远甩在身后。这充分说明了调度策略的重要性——光有异构硬件不够,得有聪明的调度。
对未来的影响
这篇论文背后的信号非常明确:
1. 模型架构正在重塑推理系统设计
Kimi Linear、Qwen3.5、MiMo-V2-Flash、Ring-2.5-1T……新一代模型几乎都在走混合注意力路线。KVCache 的急剧缩小,让跨数据中心推理从"不可能"变成了"值得优化"。
2. 硬件专用化趋势加速
NVIDIA 的 Rubin CPX 专攻 Prefill 吞吐,Groq 的 LPU 专攻 Decode 带宽,Taalas HC1 主打超高内存带宽。PrfaaS 架构让这些异构硬件可以各自独立部署、独立扩缩容,不用硬塞进同一个 RDMA 集群。
3. 大规模部署的成本优化空间巨大
论文指出,即使是万卡级别的部署,PrfaaS 集群的跨数据中心带宽需求也就在 Tbps 量级,现代数据中心完全能承载。这意味着企业可以在算力便宜的地方部署 Prefill 集群,在离用户近的地方部署 Decode 集群。
总结
这篇论文的核心洞察其实很简单:下一代模型的 KVCache 够小了,小到可以跨数据中心传输了。 但光"够小"还不行,还需要选择性卸载、带宽感知调度、缓存感知路由这一套系统设计配合。模型架构和系统设计双管齐下,才能让跨数据中心的异构推理真正落地。
作为 Mooncake 的延续之作,这篇论文继续体现了 Moonshot AI 在推理系统领域的深厚积累。而且论文明确提到了跟 vLLM、SGLang 的合作,说明这些想法很可能会逐步落地到开源推理框架中。
#PrfaaS #KVCache #大模型推理 #MoonshotAI #混合注意力
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号