英伟达的旗舰大模型,吞吐量暴打Qwen3.5七倍,技术细节披露!

英伟达的旗舰大模型,吞吐量暴打Qwen3.5七倍,技术细节披露!

Ai学习的老章
发布于 2026-04-24 21:03:12
发布于 2026-04-24 21:03:12
最近英伟达放出了技术报告(arxiv.org/abs/2604.12374),披露了很多细节
本文一起拆解之
简介
Nemotron 3 Super 是英伟达 Nemotron 3 家族的旗舰模型,总参数 1206 亿,每次前向传播只激活 127 亿参数(不含 embedding 是 121 亿)
它融合了三种前沿技术:
- Hybrid Mamba-Attention:用 Mamba-2 块替代大部分注意力层,推理速度起飞
- LatentMoE:全新的混合专家架构,精度和效率双提升
- MTP(Multi-Token Prediction):原生推测解码,不需要外挂 draft model
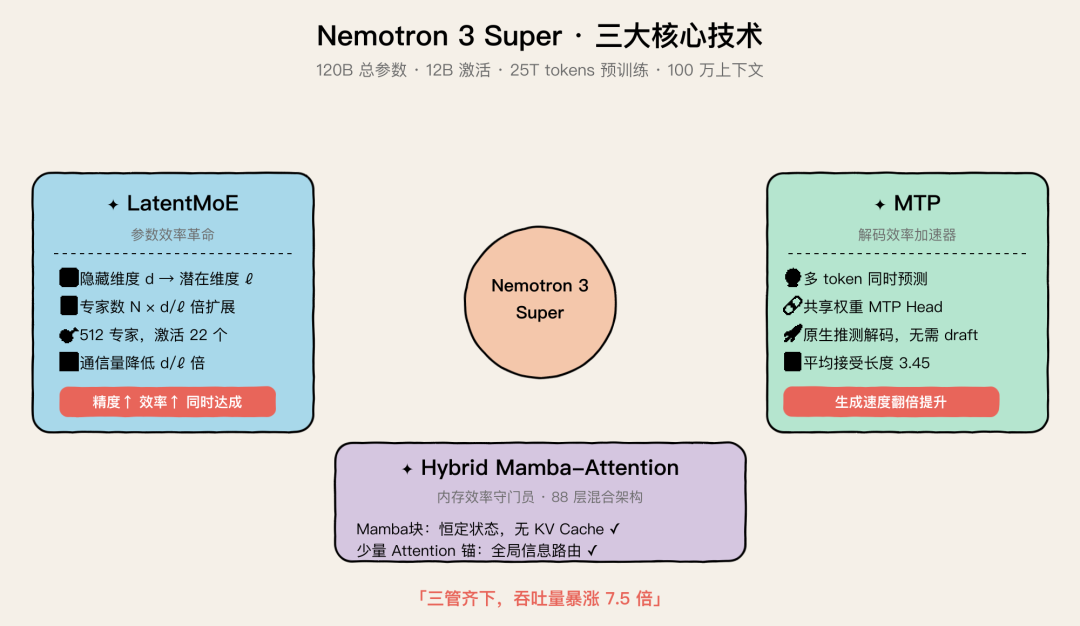
Nemotron 3 Super 三大核心技术:LatentMoE + MTP + Hybrid Mamba-Attention
Nemotron 3 Super 三大核心技术:LatentMoE + MTP + Hybrid Mamba-Attention
用 25 万亿 token 预训练,支持最长 100 万 token 上下文,在常见 benchmark 上和 GPT-OSS-120B、Qwen3.5-122B 打得有来有回,但推理吞吐量分别是它们的 2.2 倍和 7.5 倍。
下图是论文给的精度 - 吞吐量对比,一目了然:
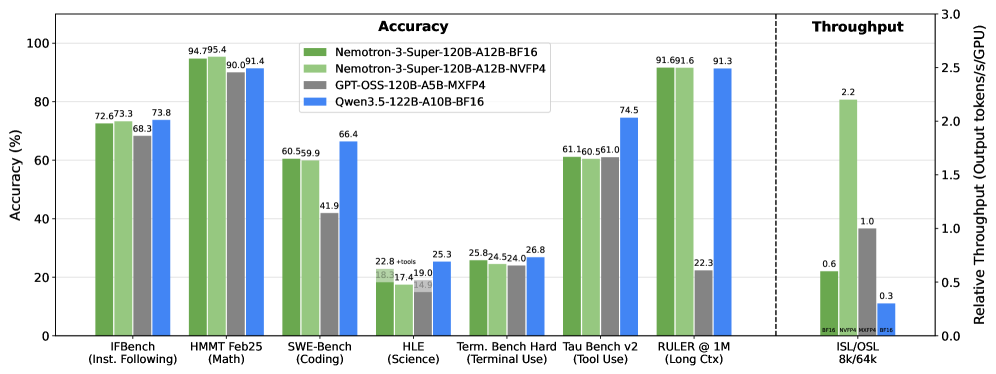
Nemotron 3 Super 精度与吞吐量对比:和 GPT-OSS-120B、Qwen3.5-122B 精度持平,但吞吐量遥遥领先
Nemotron 3 Super 精度与吞吐量对比:和 GPT-OSS-120B、Qwen3.5-122B 精度持平,但吞吐量遥遥领先
LatentMoE:重新设计 MoE 的底层逻辑
我觉得这篇论文最有意思的创新是 LatentMoE
传统 MoE 的问题在哪?
大家都知道 MoE 靠"只激活部分专家"来省计算量。但英伟达指出一个被忽视的问题:现有 MoE 设计几乎只优化了每 FLOP 的精度,忽略了每参数的精度
什么意思呢?在实际部署中,你的成本不只是算力,还有:
- 内存带宽:每个专家权重矩阵是 d×m,读取成本和隐藏维度 d 成正比
- 通信开销:分布式推理时 all-to-all 路由的流量和 d×K 成正比(K 是激活专家数)
所以英伟达的思路是:把隐藏维度 d 压下来。
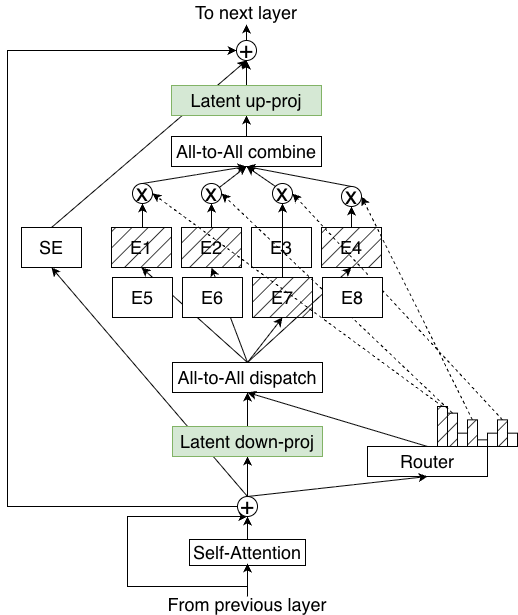
标准 MoE vs LatentMoE 架构对比
标准 MoE vs LatentMoE 架构对比
LatentMoE 的做法:
- 降维:先把 token 从隐藏维度 d 投影到更小的潜在空间 ℓ
- 在低维空间做路由和专家计算:内存读取和通信量直接降低 d/ℓ 倍
- 扩展专家数量:省下来的预算用来增加总专家数 N 和激活专家数 K,同比放大 d/ℓ 倍
- 升维:计算完再投回原始维度
这个 trade-off 非常精妙——维度降了,但专家数增了,总计算量基本不变,精度却更好。因为更多专家的组合空间是指数级增长的
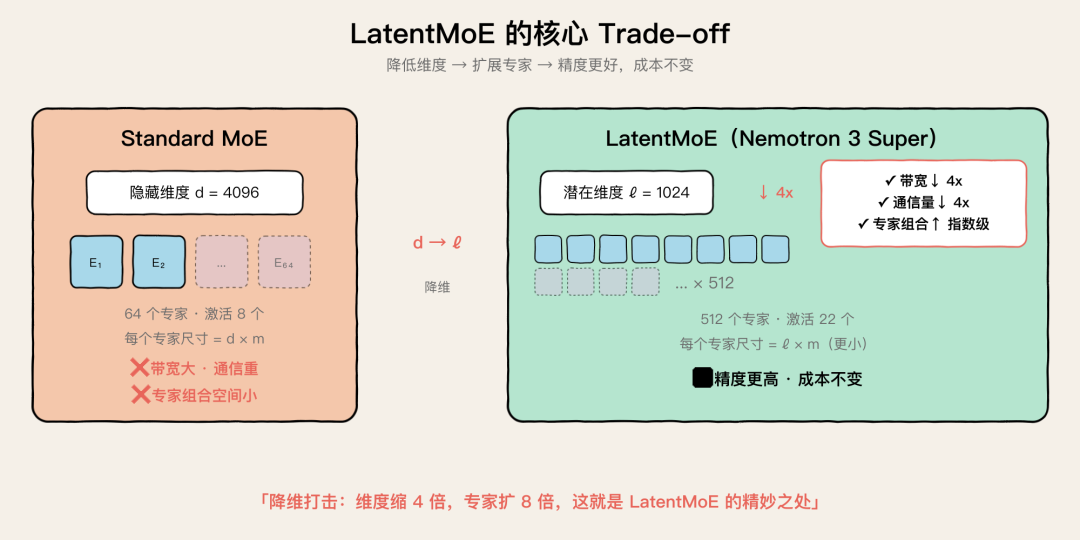
LatentMoE 降维扩专家的核心思路:用 d/ℓ 倍降维换来指数级专家组合空间
LatentMoE 降维扩专家的核心思路:用 d/ℓ 倍降维换来指数级专家组合空间
Nemotron 3 Super 的具体配置:512 个专家,每次激活 22 个,潜在维度 1024。做个对比:DeepSeek V3 是 256 个专家激活 8 个,Qwen3.5 是 128 个专家激活 8 个
Nemotron 的专家数和激活数都大幅领先
MTP:内置的推测解码加速器
MTP(Multi-Token Prediction)也是一大亮点。DeepSeek V3 也用了 MTP,但 Nemotron 3 Super 的实现有一个关键改进:共享权重的 MTP head
传统方式:训练 N 个独立的预测头,分别预测 n+2, n+3, ..., n+N+1 位置的 token。问题是推理时只能生成最多 N 个 draft token
Nemotron 的做法:多个 MTP head 共享参数,让同一个头在训练中见过多种偏移量。这样推理时可以递归地用同一个头生成更长的 draft,接受率衰减更平缓
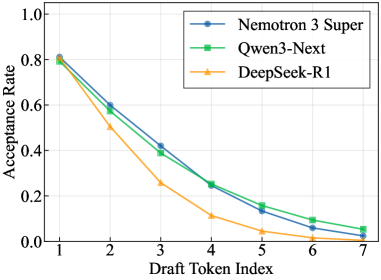
MTP 接受率对比:Nemotron 3 Super 在各个 draft 位置都保持较高接受率
MTP 接受率对比:Nemotron 3 Super 在各个 draft 位置都保持较高接受率
论文用 SPEED-Bench 测的结果:Nemotron 3 Super 平均接受长度 3.45,超过 DeepSeek-R1 的 2.70,和 Qwen3-Next 的 3.33 也有优势。在 Roleplay、RAG、Summarization 这些场景下优势尤其明显
配合 Blackwell 硬件,开启 MTP draft=3 后,在同等用户延迟下,总吞吐量显著提升:
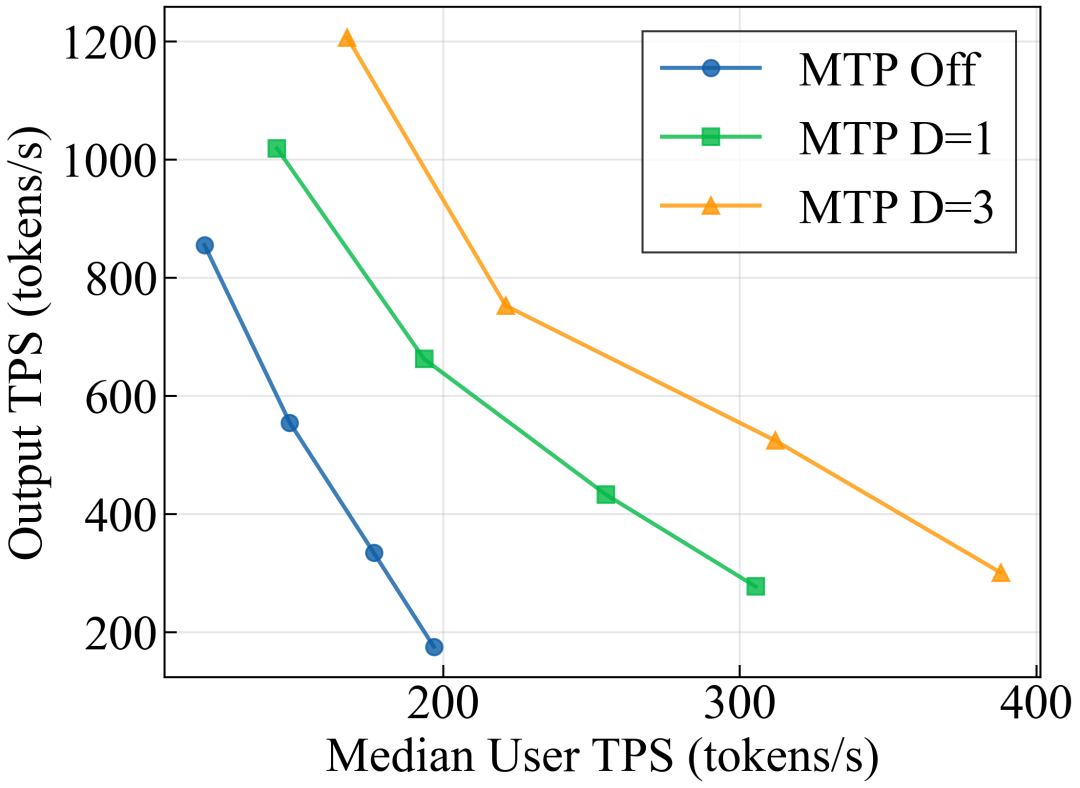
MTP 关闭 vs 开启(draft=1, draft=3)的吞吐量 - 延迟 Pareto 曲线
MTP 关闭 vs 开启(draft=1, draft=3)的吞吐量 - 延迟 Pareto 曲线
Hybrid Mamba-Attention:KV Cache 的终结者
Nemotron 3 Super 的 88 层中,大部分是 Mamba-2 块,只有少量注意力层作为"全局锚点"插入。

Nemotron 3 Super 的层交替模式:Mamba 块 + MoE 层为主,穿插少量 Attention 层
Nemotron 3 Super 的层交替模式:Mamba 块 + MoE 层为主,穿插少量 Attention 层
这么做的好处太明显了:
- Mamba 块没有 KV Cache,生成时状态大小恒定,不随上下文线性增长
- 只在关键位置保留注意力层做长程信息路由
- 注意力层用 GQA(32 query heads, 2 KV heads),进一步压缩
最终效果:支持 100 万 token 上下文,RULER 1M 测试得分 91.64,Qwen3.5-122B 也是 91.33,而 GPT-OSS-120B 只有 22.30
这个差距太大了
NVFP4 预训练:全程 4-bit 精度训练
这是我觉得非常硬核的一点——Nemotron 3 Super 全程用 NVFP4(4-bit 浮点)训练了 25 万亿 token
大多数模型用 BF16 或 FP8 训练,用 FP4 预训练的几乎没有
英伟达在这里踩了不少坑:
层类型 | 精度 | 原因 |
|---|---|---|
大部分线性层 | NVFP4 | 主力精度 |
网络最后 15% 的层 | BF16 | 保证训练稳定性 |
QKV & Attention 投影 | BF16 | 保持注意力层精度 |
Mamba 输出投影 | MXFP8 | NVFP4 下溢太严重 |
MTP 层 | BF16 | 保留多 token 预测能力 |
训练过程中观察到 7% 的权重梯度变成零值,主要是因为 NVFP4 量化把 BF16 下本就很小的梯度(<1e-12)直接下溢为零
但英伟达发现这不影响最终精度——BF16 训练到 10T token 后也会出现类似的零值梯度模式
甚至他们试过在 19T token 处从 NVFP4 切换到 MXFP8,loss 曲线改善了,但下游任务精度没有任何提升
所以最终决定全程 NVFP4,不搞精度升级,这个结论很有价值。
后训练:21 个 RL 环境,强化 Agent 能力
Nemotron 3 Super 的后训练流程分四步:
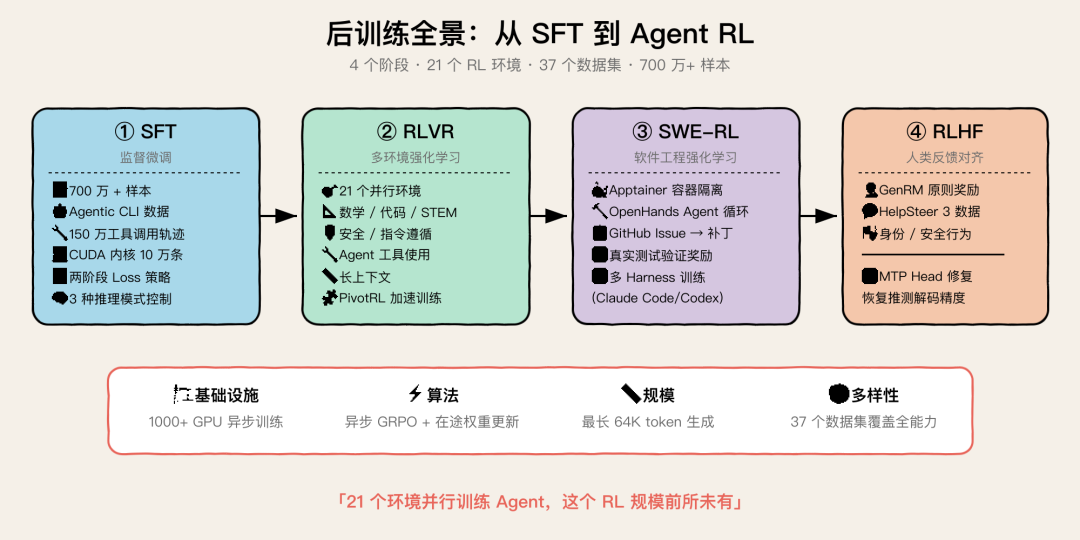
后训练流水线全景:SFT → RLVR → SWE-RL → RLHF → MTP Healing
后训练流水线全景:SFT → RLVR → SWE-RL → RLHF → MTP Healing
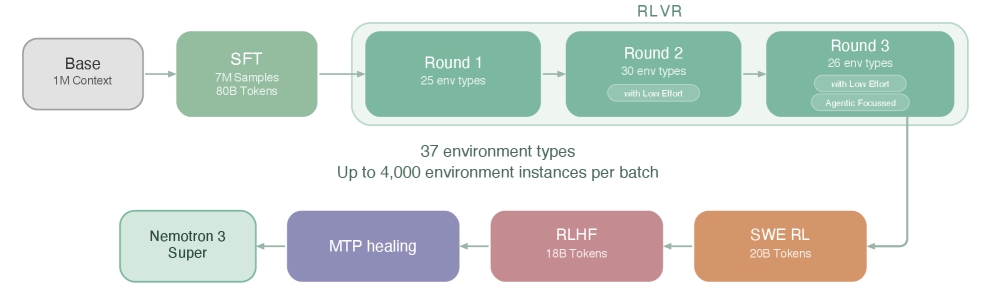
后训练流水线:SFT → RLVR → SWE-RL → RLHF → MTP Healing
后训练流水线:SFT → RLVR → SWE-RL → RLHF → MTP Healing
SFT 阶段:用了超过 700 万样本,大幅扩充了 Agent 任务的数据量。亮点包括:
- 从 SWE-Gym、R2E-Gym 等数据集蒸馏 Qwen3-Coder-480B 的编程轨迹
- 专门生成了 2 万条 Agentic CLI 任务(涵盖 Claude Code、OpenCode、Codex 等多种 harness)
- 合成了 150 万条通用工具调用轨迹
- 新增 CUDA 内核编写/修复/优化数据(10 万条)
RL 阶段:在 21 个环境、37 个数据集上同时训练。这个规模够恐怖的。覆盖数学、代码、STEM、安全、指令遵循、长上下文、Agent 工具使用等全方位能力
比较有意思的是 PivotRL——一种新的 Agent 长程 RL 方法。它复用 SFT 的专家轨迹,只在"策略不确定的关键 turn"上做 RL 训练。比端到端 RL 高效得多,又避免了 SFT 的域外退化问题
SWE-RL 阶段:每个 rollout 在 Apptainer 容器中启动完整的 GitHub 仓库环境,跑 OpenHands agent 循环生成补丁,然后用真实测试验证。为了工具多样性,他们在 OpenHands 里实现了 OpenCode 和 Codex 的 agent class,匹配 Claude Code 和 Codex CLI 的工具格式。
量化推理:FP8 和 NVFP4 双版本
英伟达提供了两个量化版本:
- FP8(W8A8):面向 Hopper 架构 GPU
- NVFP4(W4A4):面向 Blackwell 架构 GPU,用 AutoQuantize 做混合精度搜索
NVFP4 量化的关键技巧:
- 权重用 MSE 最小化选择缩放因子(离线校准,不影响运行时)
- 激活用 max-based 缩放(在线计算,追求效率)
- 敏感层自动提升到 FP8 或 BF16
最终 NVFP4 模型达到 BF16 基线的 99.8% 精度。整个量化过程在单台 B200 8 卡节点上不到 2 小时完成
还有一个很硬核的细节:Mamba 状态缓存量化。直接从 FP32 转 FP16 会导致代码生成任务的冗余度暴涨 40%(生成太多无用 token)。原因是 Mamba 的递归特性会让量化误差逐步累积。英伟达的解决方案是随机舍入(Stochastic Rounding),用 Philox 伪随机数生成器消除系统性偏差。Blackwell GPU 还提供了专用的 PTX 指令来加速这个操作。
Benchmark 成绩单
先看 Base 模型(预训练后、后训练前)的成绩:
任务 | Nemotron 3 Super | Ling-flash-Base-2.0 | GLM-4.5-Air-Base |
|---|---|---|---|
MMLU (5-shot) | 86.01 | 81.00 | 81.00 |
MMLU-Pro (5-shot) | 75.65 | 62.10 | 58.20 |
MATH (4-shot) | 84.84 | 63.80 | 50.36 |
HumanEval (0-shot) | 79.40 | 70.10 | 76.30 |
RULER 128K | 88.26 | 52.03 | 61.70 |
RULER 1M | 71.00 | - | - |
Base 模型阶段就已经全面碾压同级别竞品。
后训练版本 vs Qwen3.5-122B 和 GPT-OSS-120B:
任务 | Nemotron 3 Super | Qwen3.5-122B | GPT-OSS-120B |
|---|---|---|---|
AIME25 | 90.21 | 90.36 | 92.50 |
HMMT Feb25 (with tools) | 94.73 | 89.55 | - |
SWE-Bench (OpenHands) | 60.47 | 66.40 | 41.9 |
RULER 1M | 91.64 | 91.33 | 22.30 |
Arena-Hard-V2 | 73.88 | 75.15 | 90.26 |
说实话,精度上 Nemotron 3 Super 和 Qwen3.5-122B 各有胜负。Qwen 在编程和推理上略强,但 Nemotron 在长上下文和工具使用上更有优势。
真正拉开差距的是推理效率——在 8k 输入 + 64k 输出的设置下,Nemotron 3 Super 比 GPT-OSS-120B 快 2.2 倍,比 Qwen3.5-122B 快 7.5 倍。这才是实际部署时最关键的指标。
总结
Nemotron 3 Super 是英伟达在"效率优先"路线上的集大成之作
三个核心创新——LatentMoE、MTP、Hybrid Mamba-Attention——分别从参数效率、解码效率、内存效率三个维度做了优化,加上 NVFP4 全程训练的探索,整体技术含量很高
优点:
- 推理吞吐量确实是王炸级别,7.5 倍的差距太夸张
- 100 万上下文长度,且长上下文表现极其稳定
- 全部开源(模型权重 + 训练数据 + 训练 recipe),真·业界良心
- NVFP4 全程训练验证了低精度大规模训练的可行性
- Agent 能力突出,21 个 RL 环境训练的深度投入
不足:
- 在纯推理任务(AIME、GPQA)上相比 Qwen3.5 稍有差距
- SWE-Bench 分数落后 Qwen3.5 约 6 个点
- 目前主要针对 NVIDIA GPU 优化(Hopper/Blackwell),其他硬件适配待观察
- 512 个专家的 MoE 结构对显存要求不低,个人部署有门槛
适合谁用:如果你是做大规模 AI 推理服务的,需要在 NVIDIA 硬件上追求极致吞吐量,或者需要超长上下文和 Agent 能力,Nemotron 3 Super 是一个非常值得考虑的选择。
#Nemotron #NVIDIA #LatentMoE #MoE #开源大模型
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号