小盒子跑大模型:英伟达 Jetson 内存优化,边缘 AI 也能玩转大模型

小盒子跑大模型:英伟达 Jetson 内存优化,边缘 AI 也能玩转大模型

GPUS Lady
发布于 2026-04-24 20:51:15
发布于 2026-04-24 20:51:15

现在生成式 AI 越来越火,大家都想把大模型搬到机器人、自动驾驶、智能摄像头这类边缘设备上,不用依赖云端也能本地运行。但边缘设备有个大难题:内存太小,大模型动不动就占好几 GB,很容易跑崩、卡顿。
英伟达 Jetson 就是专门做边缘 AI 的硬件平台,最近官方给出了一套五层内存优化法,按这套方法操作,最多能省出10–12GB 内存,让小内存的 Jetson 也能流畅跑大语言模型、多模态模型。
一、优化前核心认知
- 核心痛点:边缘设备内存严格受限,CPU/GPU 共享内存,低效使用会导致卡顿、延迟、系统崩溃。
- 优化目标:在不损失核心功能的前提下,释放内存给 AI 推理(大模型、多摄像头、传感器融合)。
- 适用平台:Jetson Orin NX、Jetson Orin Nano、IGX 系列。
- 总内存收益:底层优化≈1GB,推理管线≈412MB,模型量化≈5~10GB。
二、第一层:BSP 与 JetPack 底层优化(基础层)
BSP(板级支持包)+JetPack 是边缘 AI 的系统底座,通过关闭无用服务 + 释放预留内存,最高可回收897MB。
2.1 关闭图形桌面与 UI 服务(最高省 865MB)
适用于无显示器的无头部署(机器人、工业设备),命令直接执行:
# 设置系统默认启动为多用户无图形模式
sudo systemctl set-default multi-user.target
# 重启生效
sudo reboot2.2 关闭非必要网络 / 日志服务(最高省 32MB)
按需关闭无用后台服务,替换<service-name>为目标服务:
sudo systemctl disable <service-name>- 蓝牙:
bluetooth - 日志冗余服务:
systemd-journald(按需) - 网络管理:
NetworkManager(无联网需求时)
2.3 Carveout 预留内存优化(释放硬件预留内存)
Carveout 是开机为硬件引擎预留的内存,Linux 无法访问,无显示 / 无摄像头时可完全关闭,释放约101MB。
2.3.1 关闭显示相关 Carveout(无显示器场景)
- 编辑文件:
Linux_for_Tegra/bootloader/generic/BCT/tegra234-mb1-bct-misc-p3767-0000.dts - 在
/misc/carveout/节点添加以下代码,将显示相关内存设为 0MB:
aux_info@CARVEOUT_BPMP_DCE {
pref_base = <0x0 0x0>;
size = <0x0 0x0>;
alignment = <0x0 0x0>;
};
aux_info@CARVEOUT_DCE_TSEC {
pref_base = <0x0 0x0>;
size = <0x0 0x0>;
alignment = <0x0 0x0>;
};
aux_info@CARVEOUT_DCE {
pref_base = <0x0 0x0>;
size = <0x0 0x0>;
alignment = <0x0 0x0>;
};
aux_info@CARVEOUT_DISP_EARLY_BOOT_FB {
pref_base = <0x0 0x0>;
size = <0x0 0x0>;
alignment = <0x0 0x0>;
};
aux_info@CARVEOUT_TSEC_DCE {
pref_base = <0x0 0x0>;
size = <0x0 0x0>;
alignment = <0x0 0x0>;
};编辑Linux_for_Tegra/bootloader/tegra234-mb2-bct-common.dtsi,关闭 DCE 集群:auxp_controls@3 {
enable_init = <0>;
enable_fw_load = <0>;
enable_unhalt = <0>;
reset_vector = <0x40000000>;
};删除文件中/mb2-misc/auxp_ast_config@6和@7节点。- 禁用显示设备:反编译 dtb→禁用
display@13800000→重新编译。 - 重新刷机生效。
2.3.2 关闭摄像头相关 Carveout(无摄像头场景)
- 同路径文件,在
/misc/carveout/添加:
aux_info@CARVEOUT_CAMERA_TASKLIST {
pref_base = <0x0 0x0>;
size = <0x0 0x0>;
alignment = <0x0 0x0>;
};
aux_info@CARVEOUT_RCE {
pref_base = <0x0 0x0>;
size = <0x0 0x0>;
alignment = <0x0 0x0>;
};编辑tegra234-mb2-bct-common.dtsi,关闭 RCE 集群:
auxp_controls@2 {
enable_init = <0>;
enable_fw_load = <0>;
enable_unhalt = <0>;
};重新刷机生效。
三、第二层:内核与用户空间优化(系统层)
3.1 内核优化:关闭冗余 SWIOTLB
Jetson Orin 自带硬件 IOMMU,SWIOTLB 完全冗余,可调整大小释放内存:
# 内核启动参数设置SWIOTLB为4MB(默认更大)
swiotlb=2048计算方式:总大小(字节)=swiotlb值×2048。
3.2 用户空间 CPU 内存优化
3.2.1 检测高内存进程
用procrank工具查看真实内存占用(PSS 为物理内存):
git clone https://github.com/csimmonds/procrank_linux.git
cd procrank_linux/
make
sudo ./procrank3.2.2 关闭冗余进程
无头部署可直接关闭以下进程,释放大量内存:
- 图形:
gnome-shell、Xorg - 音频:
pulseaudio - 无用后台:
nvargus-daemon(无摄像头)、docker(无容器)
3.3 用户空间硬件内存(NvMap)优化
查看 CUDA / 多媒体缓冲区内存占用:
sudo cat /sys/kernel/debug/nvmap/iovmm/clients关闭 GUI 相关进程(gnome-shell、Xorg),释放 GPU 缓冲区内存。
四、第三层:推理管线优化(DeepStream)
针对视频 / 传感器推理管线,最高省 412MB,适合视觉 AI 场景:
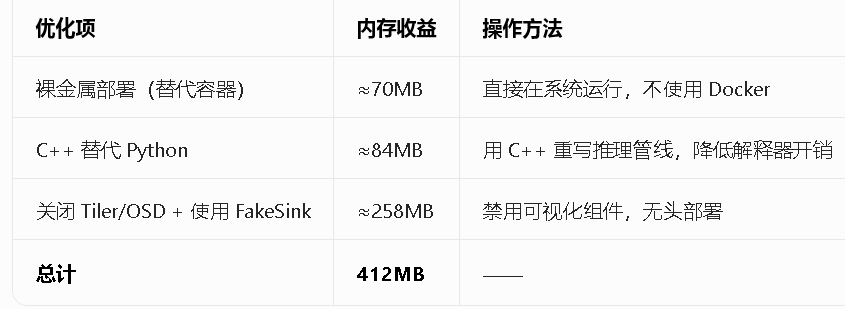
核心命令(DeepStream):
# 禁用OSD/Tiler,使用FakeSink无显示输出
disable-osd=1
disable-tiler=1
sink1=fakesink五、第四层:推理框架优化(大模型边缘部署)
边缘大模型推荐轻量推理框架,优化 KV 缓存与内存:
- vLLM:高吞吐,分页注意力机制,适合大模型批量推理。
- SGLang:灵活可编程,适配自定义推理流程。
- Llama.cpp:极致内存优化,支持 INT4/NVFP4 量化,Jetson 首选。
- TensorRT Edge-LLM:NVIDIA 官方优化,低延迟。
优化关键:调整 GPU 内存利用率参数,找到最小内存占用 + 目标性能的平衡点。
六、第五层:模型量化优化(收益最大!)
量化是边缘大模型内存优化核心,用低精度数据类型替换高精度,最高省 10GB。
6.1 量化选择原则
- 从高精度→低精度逐步测试(FP16→FP8→INT4→NVFP4)。
- 保留任务最低精度,满足准确率即可。
- 精度损失严重时,用量化感知蒸馏(QAD) 恢复。
6.2 实测内存收益

6.3 推荐量化格式
- 平衡精度:FP16、FP8
- 极致节省:W4A16、INT4、NVIDIA NVFP4(硬件加速)
七、硬件加速器卸载优化(降低 GPU 负载)
Jetson 自带专用加速器,卸载非核心任务,释放 GPU 内存 / 算力:
- ISP:处理摄像头数据,替代 GPU 图像处理。
- NVENC/NVDEC:硬件编解码视频,降低 CPU/GPU 占用。
- PVA:可编程视觉加速器,处理低功耗视觉任务(运动检测、目标跟踪)。
使用方式:通过 cuPVA SDK 调用 PVA,GPU 专注大模型推理。
八、实战案例:8GB Jetson Orin Nano 跑多模态 AI
8.1 设备配置
Jetson Orin Nano 8GB,无云端依赖,运行:
- 4-bit 量化视觉大模型(Cosmos-Reason2-2B)
- 语音识别(faster-whisper)
- 语音合成(Kokoro TTS)
- 机器人 SDK + 网页仪表盘
8.2 优化组合
- 无头部署,关闭图形桌面 + 显示 Carveout。
- Llama.cpp 部署 VLM,替代 Python 重型框架。
- 4-bit 量化模型,CTranslate2/ONNX Runtime 优化推理。
- 关闭所有无用服务,释放内存给 AI pipeline。
8.3 结果
8GB 内存设备流畅运行全链路多模态 AI。
九、优化步骤总结(直接照做)
- 无头部署,关闭图形桌面与无用服务。
- 无显示 / 摄像头时,关闭对应 Carveout 预留内存。
- 内核关闭 SWIOTLB,用户空间关闭高内存进程。
- 推理管线用 C++、裸金属、禁用可视化组件。
- 大模型用 Llama.cpp/TensorRT,做 INT4/W4A16 量化。
- 用硬件加速器卸载任务,释放 GPU 资源。
十、注意事项
- Carveout 优化后必须重新刷机,操作前备份数据。
- 量化前测试准确率,避免业务精度不达标。
- 无头部署禁止关闭必要服务(如 SSH、网络)。
- 优化后测试稳定性,重点检查延迟与系统负载。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号