GSD 框架最佳实战:31 个专业 Agent、69 个命令,6 步解决 AI 编码上下文腐烂
原创
GSD 框架最佳实战:31 个专业 Agent、69 个命令,6 步解决 AI 编码上下文腐烂
原创
运维有术
发布于 2026-04-24 00:14:04
发布于 2026-04-24 00:14:04
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 83 篇,AI 编程最佳实战「2026」系列第 17 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
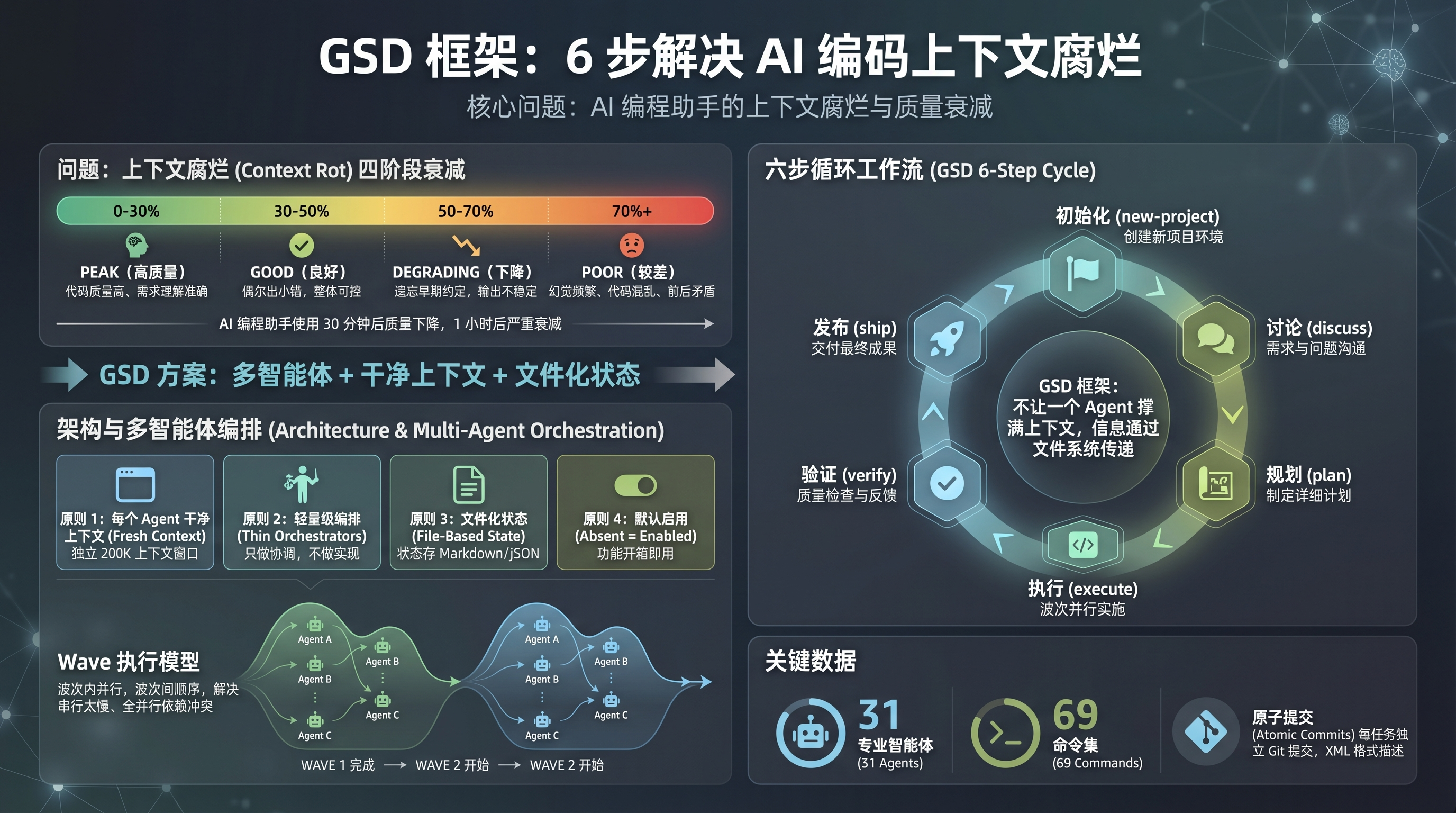
GSD 框架信息图封面
用 AI 编程助手写代码,前 10 分钟生成的代码质量很高。30 分钟后开始出现幻觉,1 小时后连变量命名风格都对不上了。
这不是模型能力不行。根源是 context rot(上下文腐烂):AI 的上下文窗口被信息填满后,生成质量急剧下滑。
GSD(Get Shit Done)就是冲着这个问题来的。它用 31 个专业 Agent、69 个命令和一套文件化状态管理,把 AI 编程从单线程对话拉到多 Agent 并行工程。下面拆解原理和实战用法。
1. 上下文腐烂:AI 编程的隐形瓶颈
1.1 什么是 context rot
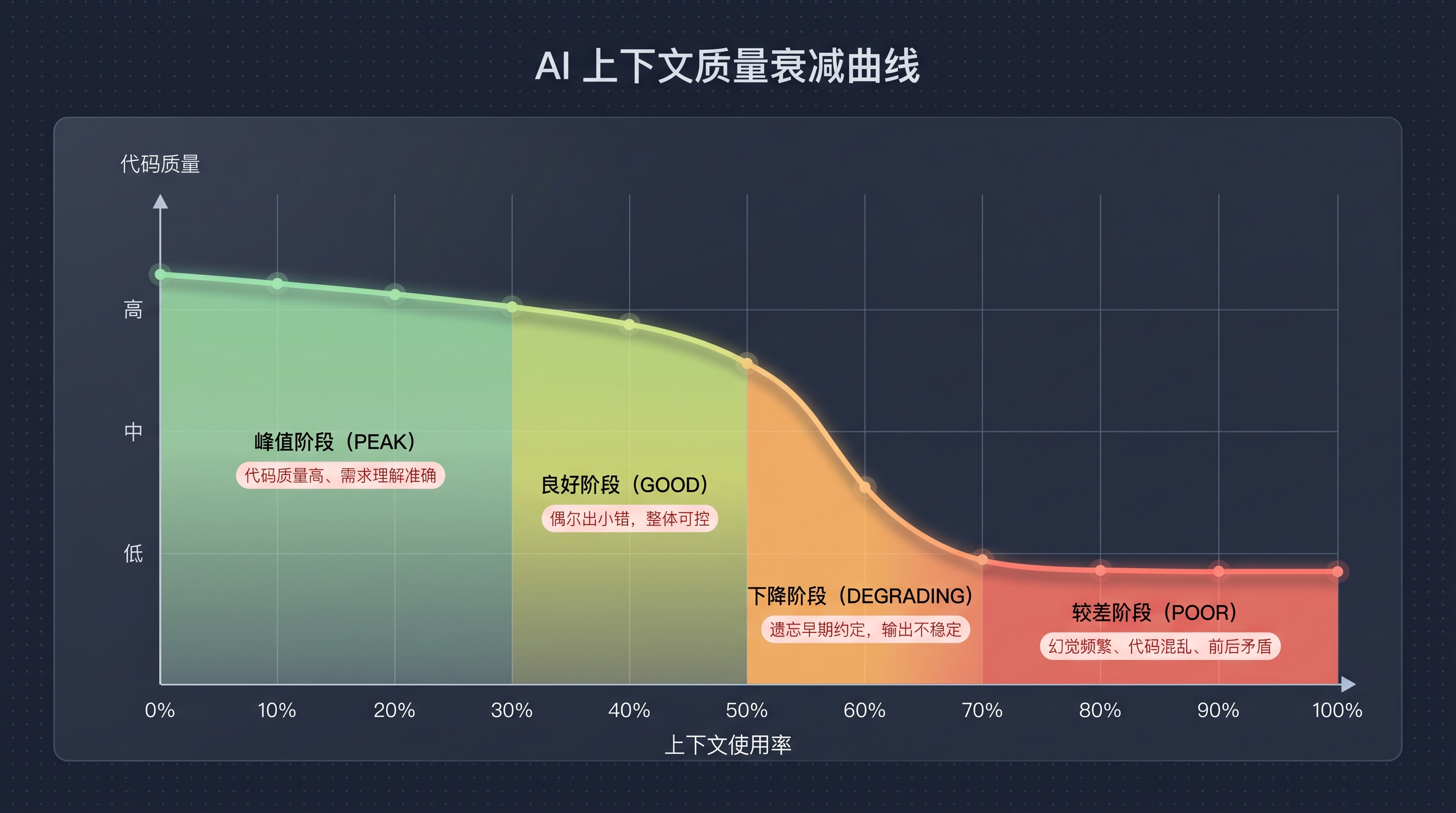
AI 上下文质量衰减曲线
GSD 官方把上下文质量衰减分为四个阶段:
上下文使用率 | 质量等级 | 实际表现 |
|---|---|---|
0-30% | 峰值(PEAK) | 代码质量高、需求理解准确 |
30-50% | 良好(GOOD) | 偶尔出小错,整体可控 |
50-70% | 下降(DEGRADING) | 遗忘早期约定,输出不稳定 |
70%+ | 较差(POOR) | 幻觉频繁、代码混乱、前后矛盾 |
本质上,大模型的注意力机制在处理长上下文时,对早期信息的权重逐渐降低。你一开始说用 TypeScript + Prisma,到 70% 上下文占用的时候,它可能开始给你写 Python + SQLAlchemy。
传统的应对方式就是手动清空上下文、重新解释项目背景。但这套流程效率很低,而且你自己也容易遗漏关键信息。
GSD 的思路不一样:不让一个 Agent 撑满整个上下文窗口,而是把任务拆分给多个 Agent,每个 Agent 都拿到干净的上下文。信息通过文件系统传递,不通过上下文窗口累积。
1.2 CLI 工具层
GSD 的底层是 gsd-tools.cjs,包含 19 个领域模块,覆盖了从文件操作到安全校验的各种工具函数。这些模块被上层的 Agent 和编排器调用,Agent 不需要自己实现基础能力:读文件、校验路径、解析 JSON 都有现成的工具。
SDK 层(TypeScript 编写)则封装了 PhaseRunner、ContextEngine、PromptBuilder 等核心组件。如果你想在 GSD 的基础上做二次开发,SDK 提供了标准化的扩展接口。
2. GSD 工作流全貌
2.1 六步循环
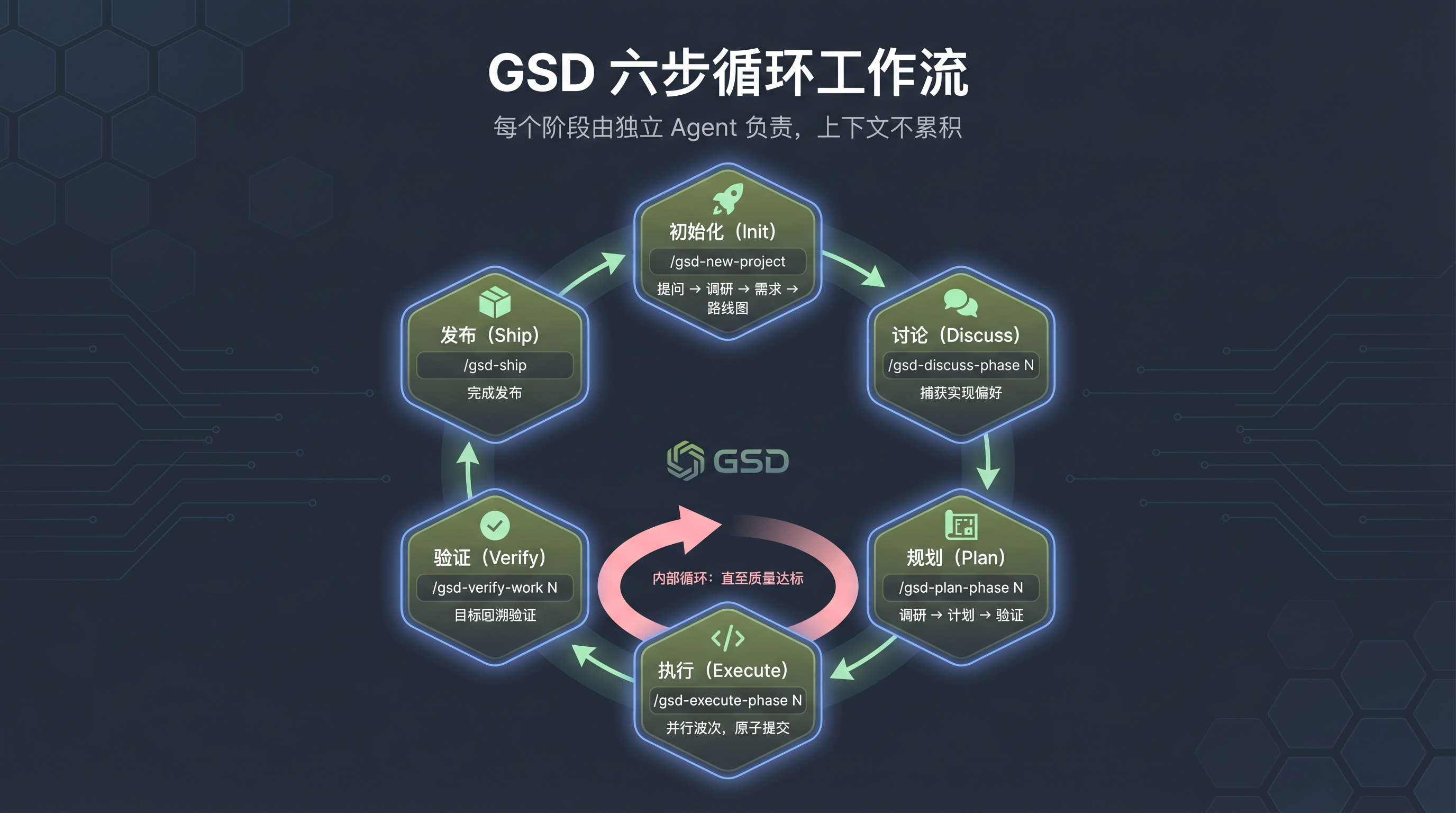
GSD 六步循环工作流
GSD 把一个完整项目的开发周期拆成六个阶段,形成闭环:
/gsd-new-project → 初始化(提问 → 调研 → 需求 → 路线图)
/gsd-discuss-phase N → 讨论(捕获实现偏好)
/gsd-plan-phase N → 规划(调研 → 计划 → 验证)
/gsd-execute-phase N → 执行(并行波次,原子提交)
/gsd-verify-work N → 验证(目标回溯验证)
/gsd-ship → 发布每个阶段结束后自动流转到下一个。执行和验证环节可以循环多次,直到质量达标。这个设计的核心思想是:每个阶段由独立 Agent 负责,上下文不累积。
2.2 四个核心设计原则
GSD 的整个架构建立在四条原则之上:
Fresh Context Per Agent — 每个 Agent 都获得一个干净的上下文窗口,不存在前一个 Agent 的垃圾信息污染下一个的问题。
Thin Orchestrators — 编排器只做协调和调度,不做具体实现。它们本身很轻量,不会吃掉大量上下文空间。
File-Based State — 所有项目状态存在 .planning/ 目录的 Markdown 和 JSON 文件里。人类可以直接阅读、编辑、Git 版本控制。即使所有 Agent 退出,状态也不会丢失。
Absent = Enabled — 功能默认启用,不需要额外配置。减少了初始化的复杂度。
这四条原则是相互支撑的:文件化状态是 Fresh Context 的前提——Agent 能从文件中读到上下文,才不需要在上下文窗口里堆信息。Thin Orchestrator 保证了编排器本身不会成为瓶颈。Absent = Enabled 降低了上手门槛。
3. 多 Agent 编排架构
这是 GSD 区别于其他 AI 编程工具的核心设计。
3.1 Orchestrator → Agent 模式
GSD 把协调和执行彻底分开。编排器(Orchestrator)负责调度,Agent 负责干活。
阶段 | 编排器职责 | Agent 职责 |
|---|---|---|
Research | 协调调研方向、呈现结果 | 4 个调研者并行调研技术栈、功能、架构、陷阱 |
Planning | 验证计划质量、管理迭代 | Planner 创建计划、Checker 验证、循环直到通过 |
Execution | 分组波次、追踪进度 | 执行器并行实现,各自拥有 200K 干净上下文 |
Verification | 呈现结果、路由下一步 | 验证器检查代码库是否达成目标 |
Research 阶段的设计值得关注:4 个 Agent 同时出发,分别调研技术栈选型、功能需求、架构方案和已知陷阱。每个 Agent 都是独立的上下文窗口,不会被其他 Agent 的调研方向干扰。
Planning 阶段用了类似对抗训练的思路——一个 Agent 负责写计划,另一个 Agent 专门挑毛病。计划被打回就修改,循环迭代直到 Checker 放行。这个机制避免了自己写的计划自己觉得没问题的盲区。
3.2 Wave 执行模型
执行阶段的并行策略是另一个亮点。计划按依赖关系分组为波次(Wave)。同一波次内并行执行,波次之间顺序执行:
Wave 1 (parallel) Wave 2 (parallel) Wave 3
Plan 01 Plan 02 → Plan 03 Plan 04 → Plan 05
User Product Orders Cart Checkout
Model Model API API UIWave 1 创建 User Model 和 Product Model,两个没有依赖关系,并行跑。Wave 2 依赖 Wave 1 的结果,所以排在第二波。Wave 3 的 Checkout 依赖前面所有组件,排在收尾。
这直接解决了两个矛盾:串行执行太慢,全并行又会导致依赖冲突。
4. XML 提示格式与上下文工程
4.1 结构化任务描述
GSD 用 XML 格式描述每个任务,而不是自然语言提示词:
<task type="auto">
<name>Create login endpoint</name>
<files>src/app/api/auth/login/route.ts</files>
<action>Use jose for JWT...</action>
<verify>curl -X POST localhost:3000/api/auth/login returns 200</verify>
<done>Valid credentials return cookie, invalid return 401</done>
</task>这种格式在工程上有几个明确的好处:
<files>标签精确告诉 Agent 要操作哪些文件,减少误改<verify>标签内置验证条件,Agent 干完活会自动检查<done>标签定义完成标准,防止 Agent 画蛇添足
对比用自然语言写 请帮我创建一个登录接口,要用 JWT,文件在 src/app/api/auth/login/route.ts,XML 格式的指令精确度高了一个量级。
4.2 原子 Git 提交
每个任务完成后,GSD 立即创建一个独立的 Git 提交。
这不是简单的随手 commit。原子提交的好处是:如果某个任务引入了 bug,你可以精确 revert 那一个提交,不影响其他任务的成果。在多 Agent 并行执行的场景下,这一点很关键——没有原子提交,一个 Agent 的错误可能连带破坏其他 Agent 的工作。
4.3 文件系统状态
所有状态存储在项目根目录的 .planning/ 中,Markdown 和 JSON 格式:
- PLAN.md — 当前阶段的执行计划,包含 XML 格式的任务描述
- SUMMARY.md — 项目摘要,包含架构决策、技术栈选择、约束条件
- STATE.md — 全局状态,记录当前所处阶段和里程碑进度
这些文件可以被 Git 追踪。团队成员拉取代码后,能看到完整的项目规划和执行进度。
4.4 安全防护
GSD 在 Agent 执行层面内置了多层防护:
- 路径遍历防护 — Agent 不能读写项目目录之外的文件
- 提示注入检测 — 识别并拦截外部输入中的恶意指令
- 安全 JSON 解析 — 防止通过畸形 JSON 触发异常
- Shell 参数验证 — 执行命令前校验参数合法性
Hook 系统还包含上下文监控功能——当上下文使用到 35% 和 25% 剩余时,分别触发警告和强提醒,防止 Agent 在不知不觉中耗尽上下文。
5. 实战:用 GSD 跑通一个完整 Phase
5.1 安装
npx get-shit-done-cc@latest一行命令搞定。GSD 支持 Claude Code、Cursor、Windsurf、Copilot、Gemini CLI、Cline、OpenCode 等十几个平台,完整列表在官方文档里有。以下以 Claude Code 为例演示。
5.2 初始化项目
在 Claude Code 中输入:
/gsd-new-projectGSD 会开始提问:项目目标是什么?技术栈怎么选?它会派出 4 个调研 Agent 并行收集信息(技术栈、功能、架构、陷阱各一个),然后生成需求文档和路线图。
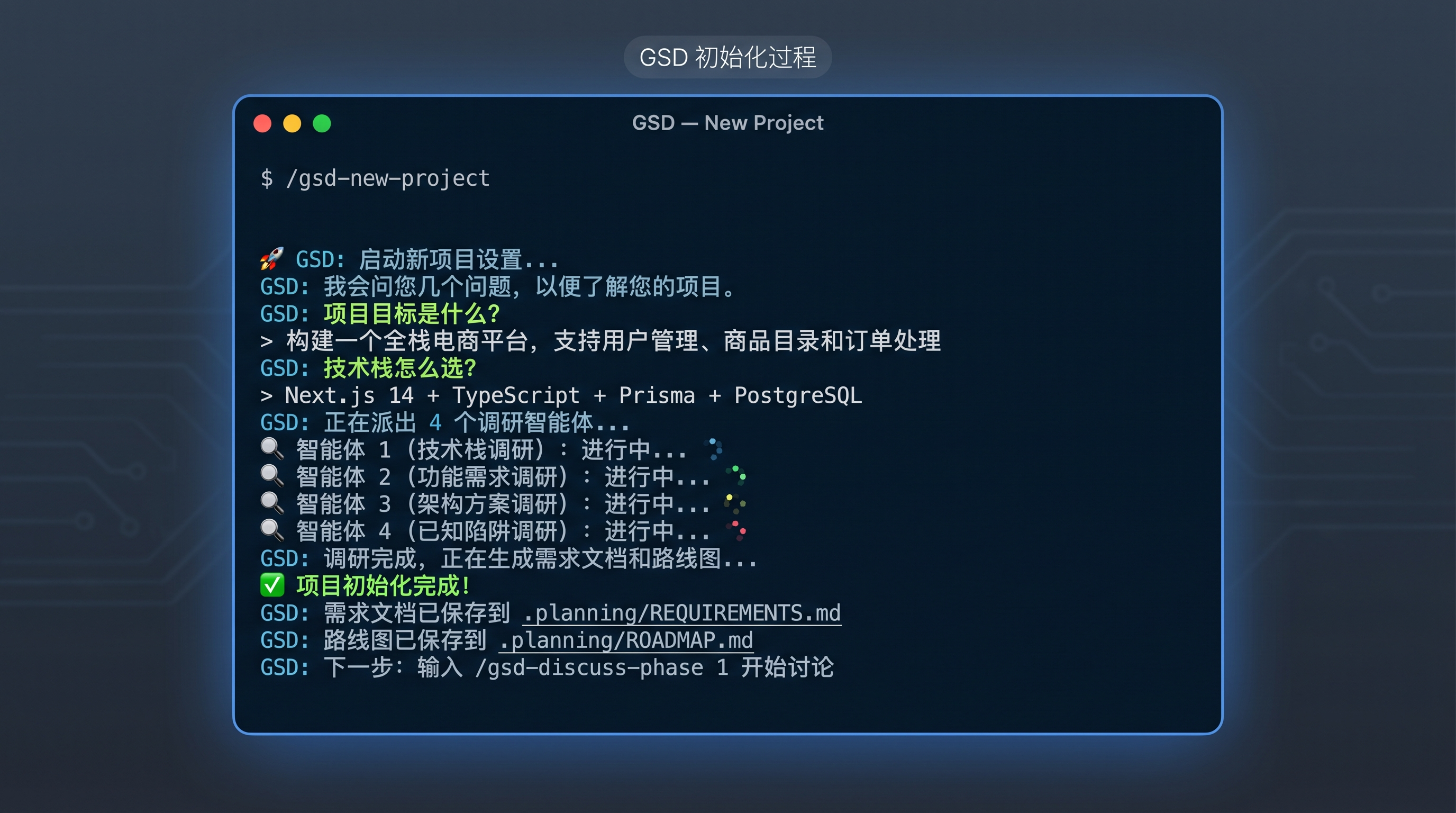
GSD 终端初始化交互界面
5.3 模型适配与选型测试
GSD 默认使用当前平台的模型配置。它的设计是 Absent = Enabled——只要你的 Claude Code 已经配好了模型(不管是 Claude、GLM5 还是其他),GSD 会自动继承平台的模型设置,不需要额外配置。通过 /gsd-set-profile inherit 可以让 GSD 直接使用当前运行时的模型选择,不强制指定 Opus/Sonnet/Haiku。
实际使用中,不同模型在 GSD 各环节的表现差异明显。Planning 阶段涉及复杂的依赖分析和任务拆解,对模型的推理深度要求高;Execution 阶段则需要准确理解 XML 格式指令并生成代码,对指令遵循能力敏感。
建议在正式项目启动前,先用 /gsd-quick 跑一个小任务做适配测试。我分别用 智谱 GLM Coding Planhttps://www.bigmodel.cn/glm-coding?ic=YCG7BTU5QC和 MiniMax Token Plan(https://platform.minimaxi.com/subscribe/token-plan?code=8nzRbxE4m1&source=link做了对比:感兴趣可以通过我的链接试试(比官网直购便宜 10%),GLM 在 Planning 环节的中文指令理解比较准确,MiniMax 在 Execution 环节的代码生成速度快。两个方案的入门套餐价格都不贵,拿来试错成本不高。不过 GLM 基本抢不到,Minimax 整体效果确实不如 GLM,也请谨慎考虑。
如果不确定选哪个,可以先用 inherit 模式跑一轮 /gsd-quick,观察 GSD 输出的 Research 和 Plan 质量,再决定后续 Phase 用哪个模型。
5.4 执行一个完整的 Phase
假设项目路线图有 3 个 Phase,我们从 Phase 1 开始。
讨论阶段
/gsd-discuss-phase 1目标:捕获你的实现偏好。GSD 会问一些关键问题——用什么 ORM?要不要写测试?API 风格是 REST 还是 GraphQL?你的回答被记录到 .planning/ 目录中,后续所有 Agent 都能看到。
规划阶段
/gsd-plan-phase 1Planner Agent 基于讨论结果生成执行计划,Checker Agent 审核计划。Checker 发现问题就打回修改,循环直到通过。
生成的 PLAN.md 大致结构(简化版):
<plan phase="1" milestone="User Management">
<task type="auto" wave="1">
<name>Create User Model</name>
<files>src/models/User.ts</files>
<action>Define User schema with Prisma</action>
<verify>npx prisma validate succeeds</verify>
<done>User model compiles without errors</done>
</task>
<task type="auto" wave="1">
<name>Create Auth utilities</name>
<files>src/utils/auth.ts</files>
<action>Implement JWT helpers using jose</action>
<verify>Unit tests pass</verify>
<done>Sign and verify tokens working</done>
</task>
<task type="auto" wave="2">
<name>Create Login Endpoint</name>
<files>src/app/api/auth/login/route.ts</files>
<action>Use User Model and Auth utilities</action>
<verify>curl returns 200 for valid credentials</verify>
<done>Login returns cookie, invalid returns 401</done>
</task>
</plan>Wave 1 的两个任务并行执行,Wave 2 依赖 Wave 1 的结果,串行等待。
执行阶段
/gsd-execute-phase 1编排器按 Wave 分组,把任务分配给执行 Agent。每个 Agent 拿到干净的 200K 上下文窗口,只看到自己任务相关的文件和指令。任务完成后,每个产生独立的 Git 提交。
验证阶段
/gsd-verify-work 1验证 Agent 回溯 PLAN.md 中每个任务的 <verify> 条件,检查代码库是否满足。不通过的任务会生成报告,路由到下一轮修复。
5.5 关键文件一览
执行完一个 Phase 后,.planning/ 目录结构大致如下:
.planning/
├── PROJECT.md # 项目愿景、约束、决策
├── REQUIREMENTS.md # 需求文档(v1/v2/超出范围)
├── ROADMAP.md # 阶段分解与状态追踪
├── STATE.md # 全局状态(当前阶段、进度)
├── config.json # 工作流配置
├── research/ # 初始化时的域调研结果
│ ├── SUMMARY.md # 调研摘要
│ ├── STACK.md # 技术栈调研
│ ├── FEATURES.md # 功能模式调研
│ ├── ARCHITECTURE.md # 架构模式调研
│ └── PITFALLS.md # 已知陷阱
└── phases/ # 各阶段的执行产物
└── 01-phase-name/
├── 01-CONTEXT.md # 用户偏好(discuss 阶段产出)
├── 01-RESEARCH.md # 阶段调研(plan 阶段产出)
├── 01-01-PLAN.md # XML 执行计划
├── 01-01-SUMMARY.md # 执行摘要
└── 01-VERIFICATION.md # 验证报告全部是人类可读的 Markdown 和 JSON。你可以直接打开编辑,也可以用 Git 追踪变更历史。
6. GSD 模式下的提效建议
6.1 Quick Mode vs 完整流程
不是每个任务都需要走完整的 6 步循环。
如果是一个明确的、小范围的改动(修一个 bug、加一个字段),可以直接跳到 execute 阶段。只有涉及架构决策、多模块协作的复杂任务,才需要走完整的 discuss → plan → execute → verify 流程。
判断标准很简单:这个改动涉及几个文件? 超过 5 个文件,走完整流程。1-2 个文件的小改动,快速模式就够了。
6.2 上下文窗口管理
GSD 的 Fresh Context Per Agent 设计已经解决了大部分上下文管理问题。但实际使用中有几个技巧:
- 不要在一个 Phase 里塞太多任务,单 Phase 5-8 个任务是合理范围
- 利用
.planning/目录的手动编辑能力——发现 Agent 理解有偏差时,直接改 PLAN.md 比在对话中纠正更可靠 - 关注 Hook 系统的上下文监控警告,当 35% 剩余时就要考虑收尾当前任务
6.3 原子提交的实践
GSD 自动做原子提交,但你可以主动利用这个机制:
- 每次 verify 通过后,给当前状态打一个 Git tag
- 某个 Wave 执行失败时,用
git revert精确回退到失败前的状态 - 在 CI/CD 中按 Wave 粒度运行测试,不用等所有任务完成后才跑
6.4 多里程碑管理
大型项目拆成多个里程碑(Milestone),每个里程碑包含若干 Phase。
STATE.md 追踪当前里程碑和 Phase 进度。建议每个里程碑结束时做一次完整的 verify,确认所有 Phase 目标达成后再进入下一个里程碑。
总结
GSD 解决的核心问题是上下文腐烂。它通过多 Agent 编排、文件化状态、Wave 并行执行三层机制,把 AI 编程从单线程对话升级为结构化的工程流程。
三个关键取舍需要了解:
- 文件化状态换取上下文清洁 — Agent 之间通过文件通信而不是上下文累积,代价是磁盘上多了一些
.planning/文件 - 编排开销换取质量保障 — Planning 阶段的 Planner/Checker 对抗机制会增加规划时间,但减少了执行阶段的返工
- Wave 粒度换取并行效率 — 任务拆分越细,并行度越高,但编排复杂度也越高
如果你的项目足够复杂(多模块、多文件、多步骤),这些取舍是值得的。如果只是修个 bug、加个按钮,直接用原始的 AI 对话就够了。
相关资源
GSD GitHub 仓库:https://github.com/gsd-build/get-shit-done
GSD 安装命令:npx get-shit-done-cc@latest
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号