[Python技术] 财联社数据获取技术方案


今天看群里有人问财联社的信息怎么获取, 就简单看了下, 花了点时间简单写了一个例子。 要的就是简单、快速。 半个小时就这么过去了
财联社数据获取难点其实是sign的生成,这个搞定了,其他都不是什么问题。
既然提到sign,不得不提JS逆向, 这里就不细讲了。网上很多这方面的例子。之前写了一些相关技术科普文章,感兴趣的同学可以看看。
代码我就不贴了,只要sign搞定了 其他都不是事。 涉及到爬虫,还是谨慎些,不要给自己找事情。况且现在AI编程流行了, 用AI搞定也不是什么事。昨天阿里不是发布了灵码IDE了么,大家写代码又多了一种选择。
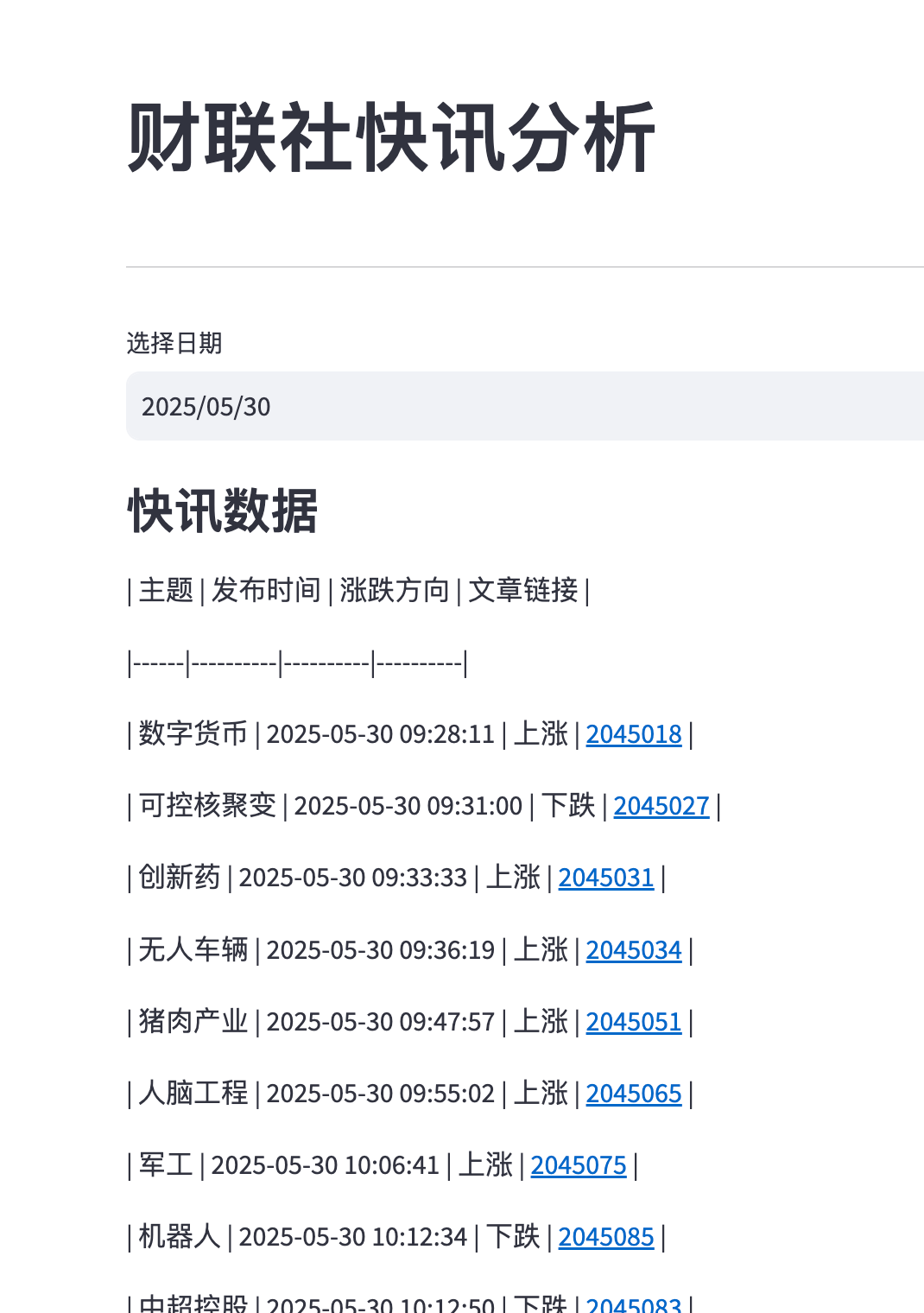
之前有同学对streamlit 怎么添加 超链接, 这个代码可以贴一贴。 我们可以借助st.markdown来实现, 因为DataFrame 的渲染限制较多,我们可以换个思路去实现。
# 创建表格标题
st.markdown("### 快讯数据")
st.markdown("| 主题 | 发布时间 | 涨跌方向 | 文章链接 |")
st.markdown("|------|----------|----------|----------|")
# 逐行渲染带超链接的数据
for _, row in df.iterrows():
# 创建超链接
url = f"https://www.cls.cn/detail/{row['article_id']}"
link_html = f'<a href="{url}" target="_blank" rel="noopener noreferrer">{row["article_id"]}</a>'
# 使用markdown渲染表格行
st.markdown(
f"| {row['symbol_name']} | {row['c_time']} | {row['涨跌方向']} | {link_html} |",
unsafe_allow_html=True
)本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号