苍穹外卖:分页查询与泛型实战详解

苍穹外卖:分页查询与泛型实战详解

北极的代码
发布于 2026-04-22 17:17:10
发布于 2026-04-22 17:17:10
目录
泛型:
实例对比:
为什么不需要强转:
分页查询的流程:
关于Result
具体的实现业务:
1.我们在Cotroller层中定义方法接收前端发送过来的参数。
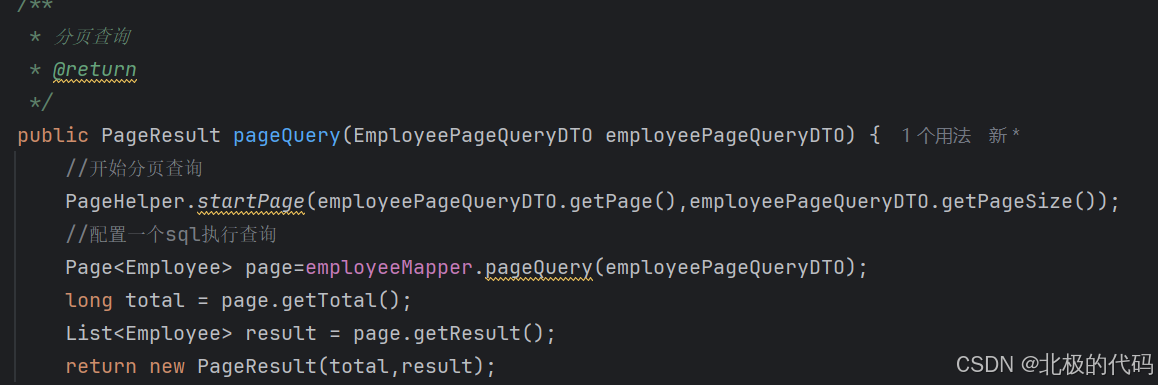
2.Service设置分页参数
3.Mapper接口:
PageHelper详解:
经过前后端联调后,我们发现更新时间的格式并不完善,下面我们进行代码完善:
前言:继我们上一章节讲解完新增员工的具体操作,并分析了具体的流程及实现的难点,这一章节,我们主要探讨分页查询的实现和具体操作及原理。
我们先在这里复习下泛型的知识点:
泛型:
我们下面根据一些例子的对比就能清楚地感知到泛型的作用了
实例对比:
// 没有泛型,List 存的是 Object List list = new ArrayList(); list.add("Hello"); list.add(123); // 取出时必须强转 String str = (String) list.get(0); // 要强转 Integer num = (Integer) list.get(1); // 要强转 // 容易出错 String wrong = (String) list.get(1); // 编译通过,运行报错! // ClassCastException: Integer cannot be cast to String |
|---|
// 泛型指定了类型 List<String> list = new ArrayList<>(); list.add("Hello"); // list.add(123); // 编译错误!只能加String // 取出时不需要强转 String str = list.get(0); // 直接拿,不用强转 |
为什么不需要强转:
原理1:类型参数化 java // 定义泛型类 public class Box<T> { private T item; public T getItem() { return item; public void setItem(T item) { this.item = item; // 使用时指定类型 Box<String> box = new Box<>(); box.setItem("Hello"); // 编译器知道 getItem() 返回的是 String String str = box.getItem(); // 不用强转 |
|---|
原理2:编译期类型检查 java List<String> list = new ArrayList<>(); // 编译期就检查类型 list.add("Hello"); // ✅ 正确 list.add(123); // ❌ 编译错误!类型不匹配 // 编译器知道 list 里全是 String String s = list.get(0); // 所以不用强转 |
原理3:类型擦除 + 自动插入强转 java // 你写的代码(有泛型) List<String> list = new ArrayList<>(); String s = list.get(0); // 编译后实际执行的代码(类型擦除后) List list = new ArrayList(); // 泛型信息被擦除 String s = (String) list.get(0); // 编译器自动插入强转 |
分页查询的流程:
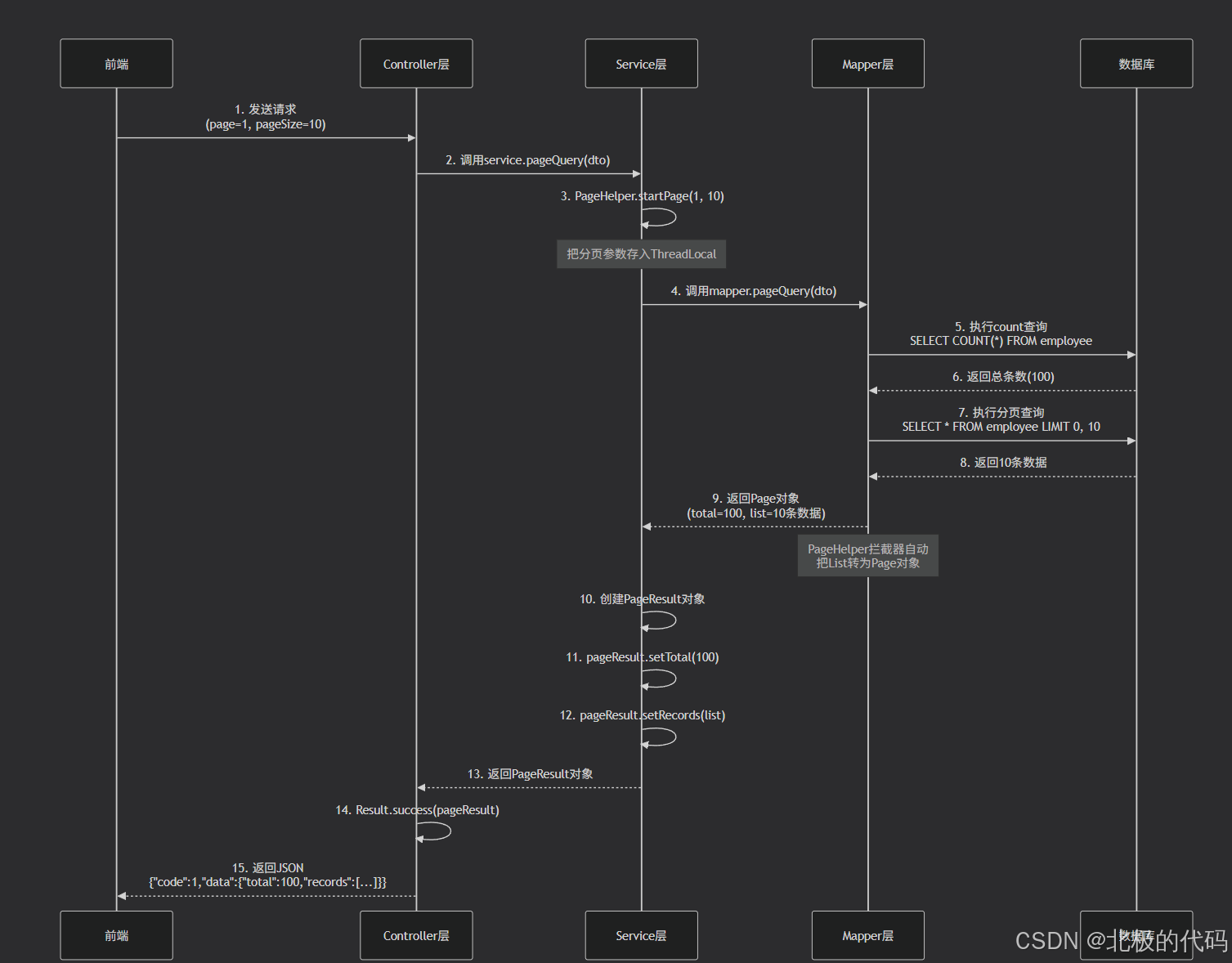
根据分页查询接口设计对应的DTO
这个类中有员工的姓名,页码,以及每页的记录数。
所有的分页查询,统一都封装成PageResult对象。这是分页查询的结果,如果我们要返回给前端,还需要再封装成Result对象,对象的泛型就是PageResult。

关于Result<PageResult>
PageResult 是苍穹外卖中封装分页查询结果的一个通用类,里面的泛型 <T> 是为了让这个类能适用于任何类型的实体。
Result<PageResult> 是苍穹外卖中分页查询接口的返回值类型,它把统一返回格式和分页数据结合在了一起。
- Result:负责统一的响应格式(成功/失败、状态码)
- PageResult:负责分页数据格式(总条数、当前页数据)
result 对象 (Result类型)
├── code: 1
├── msg: "success"
└── data: ──────→ pageResult对象 (PageResult类型)
├── total: 100
└── records: ──────→ List<Employee>对象
├── [0] → Employee对象
├── [1] → Employee对象
└── [2] → Employee对象- 第一层:
Result<...>→ data 字段的类型是PageResult<Employee> - 第二层:
PageResult<Employee>→ records 字段的类型是List<Employee>
具体的实现业务:
1.我们在Cotroller层中定义方法接收前端发送过来的参数。
EmployeePageQueryDTO这个类中封装了前端发送数据的属性,然后调用Service层的方法进行业务查询,并把前端发过来的数据封装起来传入到Service层,这里我们调用的Result.success,并把pageResult传给了他,是为了把pageResult装进data字段,以便给前端返回数据。result对象
├── code: 1
├── msg: "success"
└── data: ──────→ pageResult对象
├── total: 100
└── records: [...]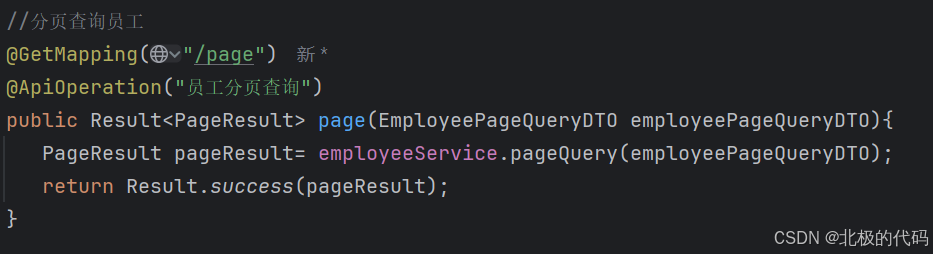
2.Service设置分页参数
我们在service中,利用了一个PageHelper插件来设置分页参数,需要的可以自行添加。由于在controller层中我们封装的dto对象已经接收到前端传来的数据了,并把数据传给了service,我们在service层直接调用就行了employeePageQueryDTO.getPage(),employeePageDTO.getPageSize().
PageHelper.startPage(employeePageQueryDTO.getPage(),employeePageQueryDTO.getPageSize());这是插件的入口,在这里实现了把页码和每页条数存到 ThreadLocal 中。之后调用Mapper中的方法去数据库里根据条件进行查询,从查询到的字段中选择一些进行返回,如total,records,返回封装好的pageResult。
3.Mapper接口:

具体的sql语句在配置文件中写,注意要配置sql方言!
PageHelper.startPage() → 设置分页参数
↓
数据库查询 → 原始数据
↓
Page对象 (total + 数据列表) ← PageHelper自动封装
↓
PageResult (total + records) ← Service手动封装
↓
Result (code + msg + data) ← Controller封装第5-6步:PageHelper拦截器工作 // PageHelper 拦截器自动执行两个查询: // 1. 先执行 count 查询 SELECT COUNT(*) FROM employee -- 结果:100 // 2. 再执行分页查询(自动加上 LIMIT) SELECT * FROM employee LIMIT 0, 10 -- 第1页,每页10条,从第0条开始 |
|---|
第7-8步:数据库返回数据 |
第9步:PageHelper封装Page对象 |
第10-12步:Service封装PageResult |
第13-14步:Controller封装Result |
分页查询流程:前端传页码 → Controller接收 → Service设置分页参数 → Mapper查询 → PageHelper自动增强SQL → 数据库执行两次查询(count+limit) → 返回Page对象 → 封装成PageResult → 封装成Result → 返回JSON给前端PageHelper详解:
1. 拦截器机制(Interceptor) PageHelper 实现了 MyBatis 的 Interceptor 接口: |
|---|
2. ThreadLocal 存储参数,线程分离。 |
3. SQL 改写原理 当执行 Mapper 方法时,PageHelper 拦截器会: 步骤1:获取原 SQL 步骤2:生成count查询 步骤3:生成分页查询,添加limit |
四、Page 对象的封装 |
经过前后端联调后,我们发现更新时间的格式并不完善,下面我们进行代码完善:
/**
* 扩展Spring MVC的消息转化器
* @param converters
*/
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
//创建一个消息转化器的对象
MappingJackson2HttpMessageConverter converter=new MappingJackson2HttpMessageConverter();
//需要为消息转化器设置一个对象转化器,可以将java对象序列化为jason数据
converter.setObjectMapper(new JacksonObjectMapper());
//将自己的消息转化器加入到容器中
converters.add(0,converter);
结语:感谢各位的观看,如果对你有帮助,请点赞,关注,收藏,你的支持就是我最大的鼓励!

本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号