【黑马点评日记03】实战:Redis缓存穿透,缓存击穿,缓存雪崩全解析

【黑马点评日记03】实战:Redis缓存穿透,缓存击穿,缓存雪崩全解析

北极的代码
发布于 2026-04-22 13:54:51
发布于 2026-04-22 13:54:51

前言:前面我们学习了添加商户缓存已经主动更新策略,接下来我们将进行一定的实践,看看如何在实战中实现主动更新,之后就是缓存存在的一些问题:
给查询商户的缓存添加超时剔除和主动更新
实现步骤:
修改ShopController中的业务逻辑,满足下面的需求: 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
//不存在,查询数据库
Shop shop = getById(id);
if (shop== null){
return Result.fail("商铺信息不存在");}
//写入缓存
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);根据id修改店铺时,先修改数据库,再删除缓存
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id==null){
return Result.fail("店铺id不能为空");
}
//更新数据库
updateById( shop);
//删除缓存
stringRedisTemplate.delete(RedisConstants.CACHE_SHOP_KEY+id);
return Result.ok();
}
}在这里我们使用了事务,
- 因为店铺数据可能涉及多张表(shop、shop_config、shop_address、shop_audit_log 等)
- 事务回滚保证这些修改要么全成功,要么全失败
- 避免出现“店铺名称改了,但配置没改”的中间状态
时间线:
[开启事务] → [修改 DB 表1] → [修改 DB 表2] → [提交事务] → [删除 Redis 缓存]
↑ ↑ ↑
事务保证原子性 提交成功才删缓存 可重试
如果 DB 修改失败 → 事务回滚 → 不删缓存(缓存数据依然正确)
如果 DB 成功但删缓存失败 → 记录日志 → 异步重试删除缓存穿透:
缓存穿透是指:查询一个根本不存在的数据,缓存层和数据库层都没有这个数据。
每次请求都会直接穿透缓存,打到数据库上。
请求流程:
text
请求 → 查缓存(没有) → 查数据库(也没有) → 返回空
↑ ↑
缓存未命中 每次都查DB危害
- 大量请求直接打到数据库
- 数据库连接被打满,CPU飙升
- 可能引发缓存穿透攻击(恶意请求大量不存在的ID)
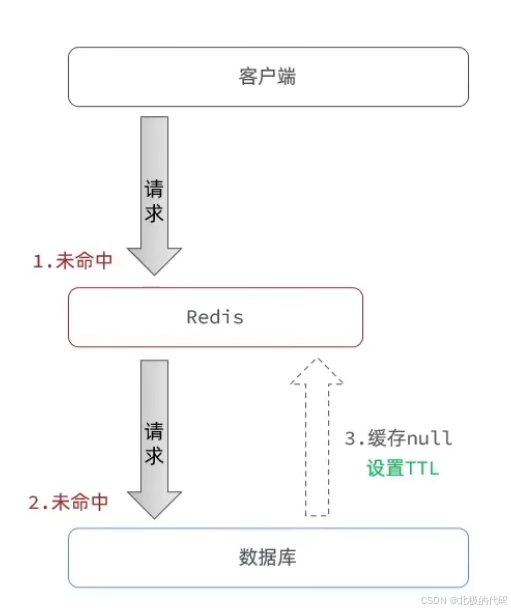
方案1:缓存空对象(最常用)
核心思路:查询不到数据时,缓存一个 null 或特殊标记,设置较短的过期时间。
java
@Service
public class ShopService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private ShopMapper shopMapper;
private static final String CACHE_KEY_PREFIX = "shop:";
private static final Long NORMAL_TTL = 3600L; // 正常数据1小时
private static final Long NULL_TTL = 60L; // 空对象1分钟
public Shop getShopById(Long id) {
String cacheKey = CACHE_KEY_PREFIX + id;
// 1. 查缓存
String cachedJson = redisTemplate.opsForValue().get(cacheKey);
if (cachedJson != null) {
// 判断是否是空对象标记
if ("NULL".equals(cachedJson)) {
return null;
}
// 反序列化返回
return JSON.parseObject(cachedJson, Shop.class);
}
// 2. 查数据库
Shop shop = shopMapper.selectById(id);
// 3. 缓存结果
if (shop != null) {
// 正常数据
redisTemplate.opsForValue().set(
cacheKey,
JSON.toJSONString(shop),
NORMAL_TTL,
TimeUnit.SECONDS
);
} else {
// 空对象缓存
redisTemplate.opsForValue().set(
cacheKey,
"NULL",
NULL_TTL,
TimeUnit.SECONDS
);
}
return shop;
}
}优点:简单、有效 缺点:占用少量内存(短TTL缓解)
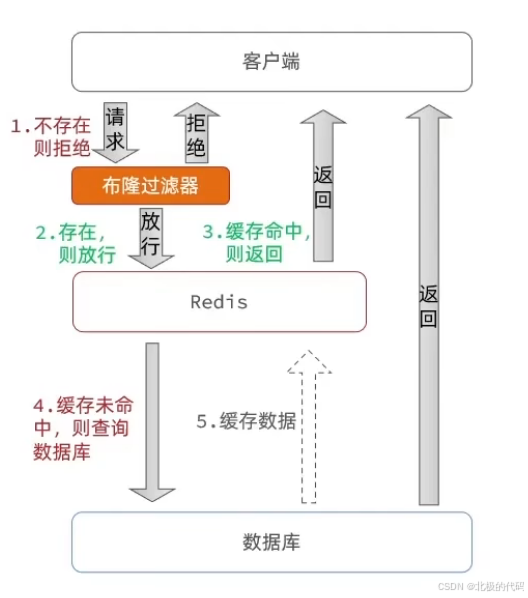
方案2:布隆过滤器(最彻底)
核心思路:将所有存在的 ID 存入布隆过滤器,快速判断一个 ID 是否一定不存在。
Maven 依赖
xml
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.0.0-jre</version>
</dependency>实现代码
java
@Service
public class ShopService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private ShopMapper shopMapper;
// 布隆过滤器:预计100万数据,误判率0.001
private BloomFilter<Long> bloomFilter = BloomFilter.create(
Funnels.longFunnel(),
1_000_000, // 预期插入数量
0.001 // 误判率
);
@PostConstruct
public void initBloomFilter() {
// 启动时加载所有存在的shop_id到布隆过滤器
List<Long> allIds = shopMapper.selectAllIds();
for (Long id : allIds) {
bloomFilter.put(id);
}
log.info("布隆过滤器初始化完成,加载了 {} 个ID", allIds.size());
}
public Shop getShopById(Long id) {
// 1. 布隆过滤器快速判断
if (!bloomFilter.mightContain(id)) {
// 一定不存在,直接返回
return null;
}
// 2. 查缓存
String cacheKey = "shop:" + id;
String cachedJson = redisTemplate.opsForValue().get(cacheKey);
if (cachedJson != null) {
return JSON.parseObject(cachedJson, Shop.class);
}
// 3. 查数据库(可能存在,也可能是误判)
Shop shop = shopMapper.selectById(id);
if (shop != null) {
// 缓存正常数据
redisTemplate.opsForValue().set(
cacheKey,
JSON.toJSONString(shop),
3600,
TimeUnit.SECONDS
);
}
return shop;
}
// 新增店铺时,同步更新布隆过滤器
public void addShop(Shop shop) {
shopMapper.insert(shop);
bloomFilter.put(shop.getId());
}
}优点:内存占用极小(100万ID约1MB),绝对拦截不存在的key 缺点:有误判率(0.1%),需要定期重建
方案3:Redis 布隆过滤器模块(生产级推荐)
Guava 的布隆过滤器是内存级的,多实例部署时每个 JVM 都要加载一遍。推荐使用 RedisBloom 模块。
安装 RedisBloom
bash
# Docker 方式
docker run -p 6379:6379 redislabs/rebloom:latestJava 代码
java
@Service
public class ShopService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private ShopMapper shopMapper;
private static final String BLOOM_KEY = "shop_bloom";
@PostConstruct
public void initBloom() {
// 初始化布隆过滤器(不存在则创建)
redisTemplate.execute((RedisCallback<Boolean>) connection -> {
connection.executeCommand(
"BF.RESERVE".getBytes(),
BLOOM_KEY.getBytes(),
"0.001".getBytes(), // 误判率
"1000000".getBytes() // 容量
);
return true;
});
// 加载所有ID到布隆过滤器
List<Long> allIds = shopMapper.selectAllIds();
for (Long id : allIds) {
redisTemplate.execute((RedisCallback<Boolean>) connection -> {
connection.executeCommand(
"BF.ADD".getBytes(),
BLOOM_KEY.getBytes(),
id.toString().getBytes()
);
return true;
});
}
}
public Shop getShopById(Long id) {
// 1. 布隆过滤器判断
boolean exists = redisTemplate.execute((RedisCallback<Boolean>) connection -> {
return connection.executeCommand(
"BF.EXISTS".getBytes(),
BLOOM_KEY.getBytes(),
id.toString().getBytes()
) == 1;
});
if (!exists) {
return null; // 一定不存在
}
// 2. 查缓存 + 查数据库(同方案1)
// ...
}
}方案4:请求限流(防御恶意攻击)
使用 Sentinel 或 Guava RateLimiter 进行限流。
Guava 限流
java
@Service
public class ShopService {
// 每秒最多10个请求(针对单个ID)
private final LoadingCache<Long, RateLimiter> limiters = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(id -> RateLimiter.create(10.0)); // 每秒10个令牌
public Shop getShopById(Long id) {
// 限流检查
RateLimiter limiter = limiters.get(id);
if (!limiter.tryAcquire()) {
log.warn("ID {} 请求过于频繁,已被限流", id);
return null;
}
// 正常查询逻辑...
}
}Sentinel 限流(阿里开原,更强大)
xml
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.8.6</version>
</dependency>java
@Service
public class ShopService {
@PostConstruct
public void init() {
// 配置限流规则
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("getShopById");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(100); // 每秒100 QPS
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
public Shop getShopById(Long id) {
try {
// 使用 Sentinel 保护
Entry entry = SphU.entry("getShopById");
try {
return doGetShop(id);
} finally {
entry.exit();
}
} catch (BlockException e) {
log.warn("被限流了");
return null;
}
}
private Shop doGetShop(Long id) {
// 正常查询逻辑...
}
}方案5:参数校验(基础防御)
java
public Shop getShopById(Long id) {
// 1. 基础校验
if (id == null || id <= 0) {
return null;
}
// 2. ID范围校验(如果是自增ID)
Long maxId = getMaxShopId(); // 缓存最大ID
if (id > maxId) {
return null;
}
// 3. 格式校验(如果是雪花算法ID)
if (String.valueOf(id).length() != 19) {
return null;
}
// 正常查询...
}商户查询的缓存穿透:
业务逻辑如图:
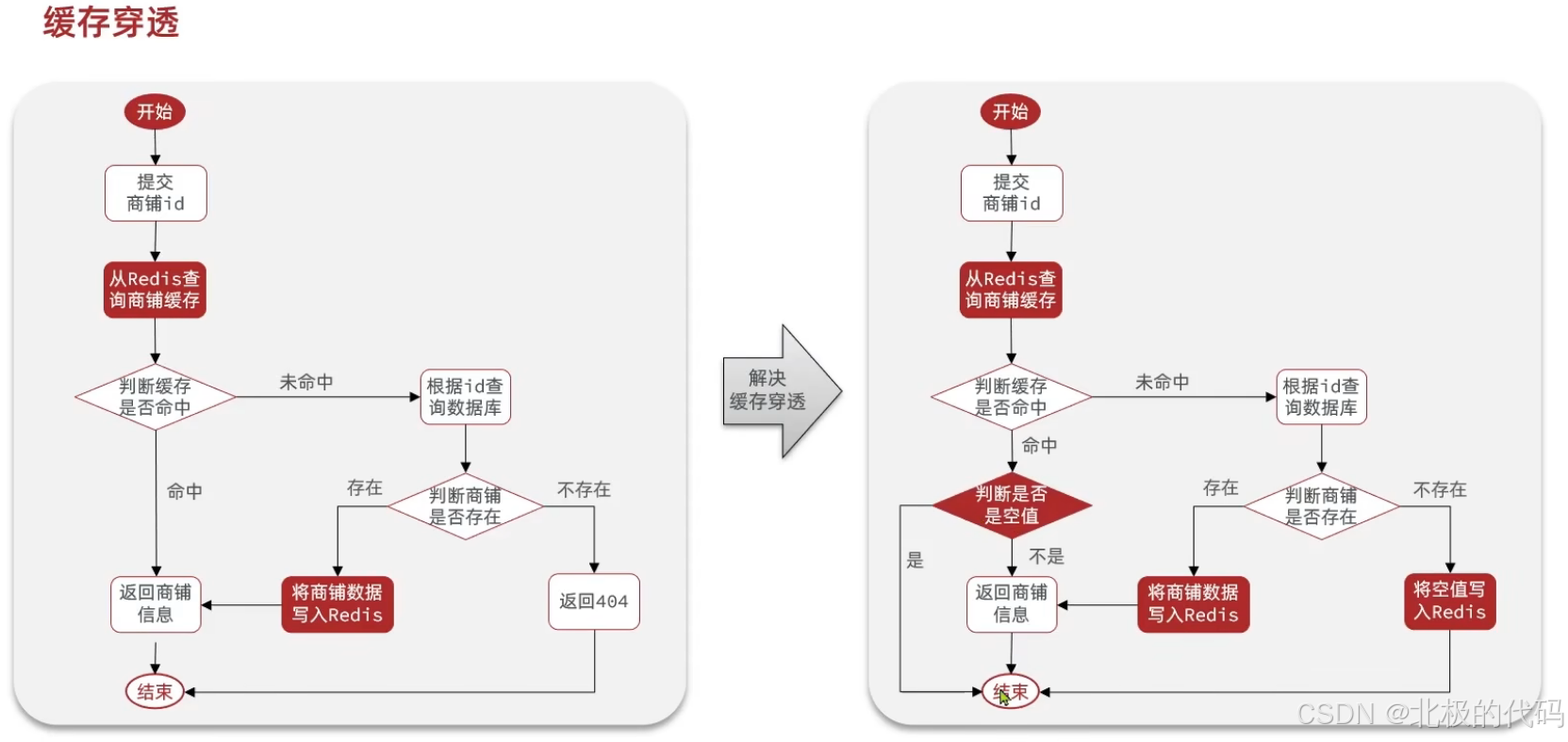
我们主要修改的是将空值写入缓存中,在数据库中查不到商铺的时候直接将空值写入Redis,
然后结束,还有一步逻辑,就是在判断缓存命中的时候,即便缓存是空值,也会命中的,所以我们要添加一个逻辑,也就判断命中的时候是否是空值。也就是:当缓存中存的是空字符串 "" 时,直接返回失败,不再查数据库。
public Result queryById(Long id) {
String key = RedisConstants.CACHE_SHOP_KEY+ id;
//从Redis中查询商品缓存信息
String shopJson = stringRedisTemplate.opsForValue().get(key);
//判断缓存是否存在
if(StrUtil.isNotBlank(shopJson)){
//存在,直接返回
//将json转为对象
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
}
//判断命中的是否为空
if (shopJson != null){
return Result.fail("商铺信息不存在");
}
//不存在,查询数据库
Shop shop = getById(id);
if (shop== null){
//将空值写入缓存
stringRedisTemplate.opsForValue().set(key,"",RedisConstants.CACHE_NULL_TTL,TimeUnit.MINUTES);
return Result.fail("商铺信息不存在");}
//写入缓存
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
}问题本质:空字符串 vs null 的区别
缓存值 | StrUtil.isNotBlank() | shopJson != null | 应该怎么处理 |
|---|---|---|---|
"{\"id\":1}" | true | true | 命中,返回数据 |
"" (空字符串) | false | true | 命中空值,直接返回失败 |
null (不存在) | false | false | 未命中,查数据库 |
代码逻辑:
- 先判断
isNotBlank→ 处理有数据的命中 - 再判断
shopJson != null→ 处理空字符串命中 - 最后才是
null→ 查数据库
这是一个标准的缓存穿透防护模式。
四如果不处理空值,有什么后果?
后果1:数据库被打穿
java
// 恶意攻击:请求10万个不存在的ID
for (int i = 1000000; i < 1100000; i++) {
queryById(i);
}
// 第一次请求:查DB → 缓存空值(2分钟过期)
// 第二次请求(2分钟内):如果不处理空值 → 又查DB → 又缓存空值
// 结果:数据库被反复查询,缓存形同虚设数据库压力:假设QPS=1000,全部穿透到数据库,数据库瞬间崩溃。
后果2:缓存被无效数据占满
虽然写了空值缓存,但因为不判断空值,每次请求都会:
- 从缓存读到
"" - 不认为命中
- 查数据库
- 再次写入
""(覆盖已有的"")
浪费网络IO和CPU。
后果3:日志爆炸
每次穿透都会打印SQL日志、慢查询日志,磁盘很快写满。
缓存雪崩:
缓存雪崩是指:大量的缓存 key 在同一时间集中过期,导致大量请求直接打到数据库,造成数据库压力骤增甚至崩溃。
典型场景
java
// 场景1:批量设置缓存,过期时间都一样
for (int i = 1; i <= 10000; i++) {
stringRedisTemplate.opsForValue().set(
"shop:" + i,
shopJson,
3600, // 都是1小时后过期
TimeUnit.SECONDS
);
}
// 1小时后,这10000个key同时过期
// 下一秒的请求全部穿透到数据库 💥与缓存穿透、缓存击穿的区别
概念 | 原因 | 特点 | 影响范围 |
|---|---|---|---|
缓存穿透 | 查询不存在的数据 | 缓存和DB都没有 | 单个key |
缓存击穿 | 热点key过期 | 缓存没有,DB有 | 单个热点key |
缓存雪崩 | 大量key同时过期 | 缓存没有,DB有 | 大量key |
缓存雪崩的3种原因
1. 大量key同时过期(最常见)
java
// 错误示例:所有key都是同一个过期时间
redis.set("product:1", data, 3600);
redis.set("product:2", data, 3600);
redis.set("product:3", data, 3600);
// ... 10000个2. Redis 实例宕机
- Redis 服务挂了
- 所有请求直接打到数据库
3. 网络故障
- 应用与 Redis 之间的网络断开
- 所有缓存操作超时,请求穿透
三、解决方案(6种)
方案1:设置随机过期时间(最常用,推荐)
核心思路:给过期时间加上一个随机偏移量,避免同时过期。
java
@Service
public class ShopService {
private static final long BASE_TTL = 3600; // 基础1小时
private static final Random RANDOM = new Random();
public void saveShopToCache(Shop shop) {
String key = "shop:" + shop.getId();
// 1小时 + 随机0~300秒,避免同时过期
long randomOffset = RANDOM.nextInt(300); // 0-300秒
long ttl = BASE_TTL + randomOffset;
stringRedisTemplate.opsForValue().set(
key,
JSONUtil.toJsonStr(shop),
ttl,
TimeUnit.SECONDS
);
}
}更精细的随机策略:
java
// 方案A:固定范围随机
long ttl = 3600 + ThreadLocalRandom.current().nextInt(600); // 1小时 ± 5分钟
// 方案B:按业务类型分组随机
long ttl = 3600 + (id % 300); // 根据ID取模,分散过期时间
// 方案C:按时间槽分散
int hour = LocalDateTime.now().getHour();
long ttl = 3600 + (hour * 60); // 不同时段不同TTL方案2:永不过期 + 异步更新(终极方案)
核心思路:缓存不设过期时间,由后台定时任务异步刷新。
java
@Service
public class ShopService {
// 缓存永不过期(或者设置很长的TTL,比如7天)
public void saveShopToCache(Shop shop) {
String key = "shop:" + shop.getId();
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
// 不设置过期时间
}
// 后台定时任务:每小时刷新一次热点数据
@Scheduled(cron = "0 0 * * * ?") // 每小时执行
public void refreshHotShopCache() {
// 获取所有热点店铺ID
List<Long> hotShopIds = getHotShopIds();
for (Long id : hotShopIds) {
Shop shop = getById(id);
if (shop != null) {
stringRedisTemplate.opsForValue().set(
"shop:" + id,
JSONUtil.toJsonStr(shop)
);
}
}
log.info("刷新了 {} 个热点店铺缓存", hotShopIds.size());
}
}优点:彻底避免雪崩 缺点:数据一致性稍差(有延迟)
方案3:使用 Redis 集群(解决实例宕机)
Redis 集群是 Redis 提供的分布式存储方案,用于解决单机 Redis 的三大瓶颈:
- 容量瓶颈:单机内存有限(比如 64GB),存不下所有数据
- 性能瓶颈:单机 QPS 有限(比如 10w/s),扛不住高并发
- 可用性瓶颈:单机挂了,整个服务不可用
核心思想:将数据分片存储到多个 Redis 节点上,每个节点只存一部分数据。
Redis Cluster(官方集群)详解
4.1 架构图
text
┌─────────────┐
│ 客户端 │
└──────┬──────┘
│
┌────────────┼────────────┐
│ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│ Node 1 │ │ Node 2 │ │ Node 3 │
│ 槽0-5460│ │槽5461- │ │槽10923- │
│ Master │ │10922 │ │16383 │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│ Node 4 │ │ Node 5 │ │ Node 6 │
│ Slave │ │ Slave │ │ Slave │
└─────────┘ └─────────┘ └─────────┘4.2 核心概念
1. 槽位(Slot)
- Redis Cluster 有 16384 个槽位(0 ~ 16383)
- 每个 key 通过 CRC16 算法计算属于哪个槽:
slot = CRC16(key) % 16384 - 每个 Master 节点负责一部分槽位
java
// 计算 key 属于哪个槽
int slot = CRC16.getCRC16("user:1001") % 16384;
// 假设 slot = 12345,就去负责 12345 槽位的节点读取2. 分片(Sharding)
text
节点1(Master):负责槽位 0-5460 → 约 1/3 的数据
节点2(Master):负责槽位 5461-10922 → 约 1/3 的数据
节点3(Master):负责槽位 10923-16383 → 约 1/3 的数据3. 主从复制
- 每个 Master 至少有 1 个 Slave(从节点)
- Master 挂了,Slave 自动升级为 Master
- 实现高可用
4.3 数据读写流程
text
客户端:set user:1001 "张三"
步骤1:计算槽位
CRC16("user:1001") % 16384 = 12345
步骤2:查询槽位映射(客户端缓存了)
槽位 12345 在节点2上
步骤3:直接连接节点2执行写入
步骤4:节点2写入成功后,异步同步给 Slave如果连错节点:
text
客户端连了节点1,执行 set user:1001 "张三"
节点1计算槽位 = 12345,发现自己不负责
节点1返回:MOVED 12345 192.168.1.2:6379
客户端收到 MOVED,更新本地映射,重试连节点2形象理解:
写操作 读操作
│ │
▼ ▼
┌─────────┐ ┌─────────┐
│ Master │ ──同步──→ │ Slave 1 │
│ (主节点) │ │ (从节点) │
└─────────┘ └─────────┘
│ │
│ ──同步──→ │
▼ ▼
┌─────────┐ ┌─────────┐
│ Slave 2 │ │ Client │
│ (从节点) │ │ 读请求 │
└─────────┘ └─────────┘作用 | 说明 | 类比 |
|---|---|---|
读写分离 | Master 写,Slave 读,分担压力 | 老板签字,助理复印 |
数据备份 | Slave 实时同步 Master 数据 | 实时云备份 |
高可用 | Master 挂了,Slave 自动升级为 Master | 老板休假,助理顶班 |
流程:
- 所有写操作(set、del、incr)必须走 Master
- Master 将数据异步同步给所有 Slave
- 所有读操作(get、mget)可以走 Slave
说明:我们这里只是简单的理解,后面我们还会更深入的学习
三种主流部署模式对比
模式 | 数据分片 | 高可用 | 水平扩展 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|
主从复制 | ❌ 不分片 | ✅ 读写分离 | ❌ 只能扩读 | ⭐ 简单 | 读多写少 |
哨兵模式 | ❌ 不分片 | ✅ 自动故障转移 | ❌ 只能扩读 | ⭐⭐ 中等 | 需要自动切换 |
Redis Cluster | ✅ 分片 | ✅ 自动故障转移 | ✅ 可扩写 | ⭐⭐⭐ 复杂 | 海量数据、高并发 |
yaml
# 主从复制 + 哨兵模式
spring:
redis:
sentinel:
master: mymaster
nodes:
- 192.168.1.10:26379
- 192.168.1.11:26379
- 192.168.1.12:26379或者使用 Redis Cluster:
java
@Configuration
public class RedisConfig {
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisClusterConfiguration clusterConfig = new RedisClusterConfiguration()
.clusterNode("192.168.1.10", 6379)
.clusterNode("192.168.1.11", 6379)
.clusterNode("192.168.1.12", 6379);
return new LettuceConnectionFactory(clusterConfig);
}
}方案4:多级缓存(本地缓存 + Redis)
核心思路:在应用内存中加一层 Caffeine 缓存,即使 Redis 挂了,本地缓存还能扛一阵。
xml
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>java
@Service
public class ShopService {
@Autowired
private StringRedisTemplate redisTemplate;
// 本地缓存:最大10000条,5分钟后过期
private final Cache<Long, Shop> localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
public Shop getShopById(Long id) {
// 1. 查本地缓存
Shop shop = localCache.getIfPresent(id);
if (shop != null) {
return shop;
}
// 2. 查Redis
String key = "shop:" + id;
String shopJson = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
shop = JSONUtil.toBean(shopJson, Shop.class);
localCache.put(id, shop); // 写入本地缓存
return shop;
}
// 3. 查数据库
shop = getById(id);
if (shop != null) {
// 写入Redis
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 3600, TimeUnit.SECONDS);
localCache.put(id, shop);
}
return shop;
}
}优点:Redis 挂了本地缓存还能用 缺点:占用 JVM 内存,多实例间数据不一致
方案5:请求限流 + 熔断降级
使用 Sentinel 或 Hystrix 保护数据库。
java
@Service
@Slf4j
public class ShopService {
@Autowired
private StringRedisTemplate redisTemplate;
public Shop getShopById(Long id) {
try {
// 限流:每秒最多100个请求
Entry entry = SphU.entry("getShop");
try {
return doGetShop(id);
} finally {
entry.exit();
}
} catch (BlockException e) {
// 被限流,返回降级数据
log.warn("请求被限流,id: {}", id);
return getFallbackShop(id);
}
}
private Shop doGetShop(Long id) {
// 正常查询逻辑...
String key = "shop:" + id;
String shopJson = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
return getById(id);
}
// 降级方案:返回默认数据
private Shop getFallbackShop(Long id) {
Shop fallback = new Shop();
fallback.setId(id);
fallback.setName("系统繁忙,请稍后重试");
return fallback;
}
}方案6:缓存预热(提前加载)
核心思路:系统启动时或高峰期前,提前把热点数据加载到缓存。
java
@Component
public class CachePreheatRunner implements CommandLineRunner {
@Autowired
private ShopService shopService;
@Override
public void run(String... args) throws Exception {
// 系统启动时,加载热门店铺到缓存
log.info("开始缓存预热...");
List<Long> hotShopIds = getHotShopIds(); // 比如销量前1000的店铺
for (Long id : hotShopIds) {
shopService.getShopById(id); // 触发缓存加载
}
log.info("缓存预热完成,共加载 {} 个店铺", hotShopIds.size());
}
private List<Long> getHotShopIds() {
// 可以从数据库查询热销店铺ID
return shopMapper.selectHotShopIds(1000);
}
}定时预热:
java
@Component
public class CacheScheduler {
// 每天凌晨2点预热,早上高峰期缓存都在
@Scheduled(cron = "0 0 2 * * ?")
public void preheatBeforePeak() {
// 预热逻辑...
}
}缓存击穿:
缓存击穿是指:某个热点 Key 在缓存过期的瞬间,有大量并发请求同时发现缓存失效,导致所有请求同时打到数据库,造成数据库压力骤增。 一句话理解:
- 缓存穿透:查不存在的数据(空炮弹)
- 缓存击穿:查存在的热点数据,但缓存刚好过期(炸弹爆炸)
- 缓存雪崩:大量 Key 同时过期(炸弹群)
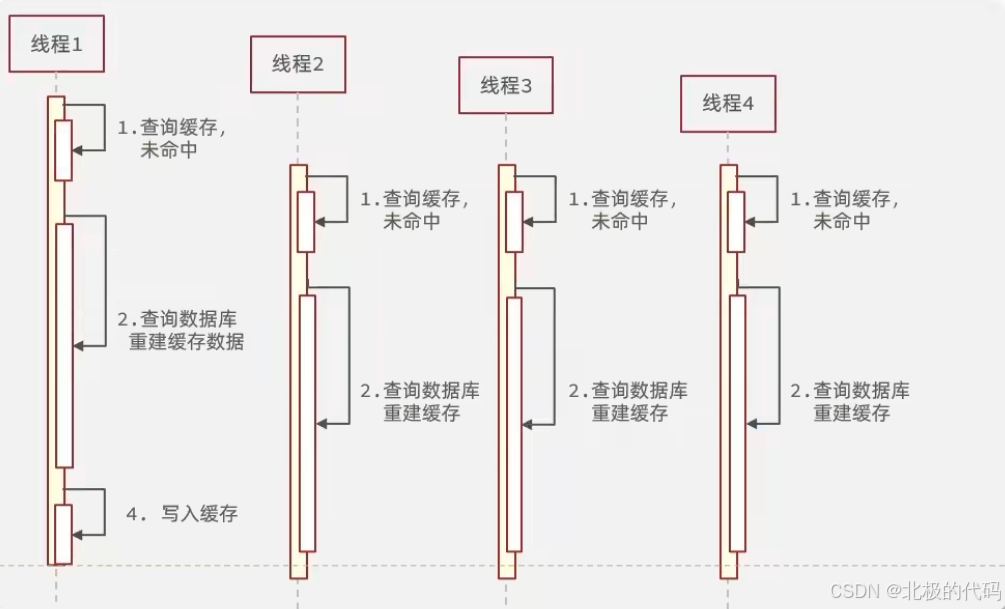
图解缓存击穿
text
时间线:
┌─────────────────────────────────────┐
│ 热点 Key "爆款商品" 缓存过期瞬间 │
└─────────────────────────────────────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 请求1 │ │ 请求2 │ │ 请求3 │
│ 发现空 │ │ 发现空 │ │ 发现空 │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
└─────────────────┼─────────────────┘
▼
┌─────────────────┐
│ 数据库 │
│ CPU 100% ❌ │
│ 连接池满 ❌ │
└─────────────────┘并发场景:假设这个热点 Key 的 QPS = 5000,缓存过期的那一秒,5000 个请求同时打到数据库
解决方案(4 种)
方案1:互斥锁(最常用,推荐)
核心思路:只让一个请求去查数据库,其他请求等待。
java
@Service
@Slf4j
public class ShopService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private ShopMapper shopMapper;
// 本地锁(单机版)
private final ReentrantLock localLock = new ReentrantLock();
public Shop getShopById(Long id) {
String key = "shop:" + id;
// 1. 查缓存
String shopJson = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
// 2. 缓存为空,加锁(只让一个线程查数据库)
Shop shop = null;
localLock.lock();
try {
// Double Check:防止第一个线程查完数据库后,其他等待线程又重复查
shopJson = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
// 3. 查询数据库
shop = shopMapper.selectById(id);
// 4. 写入缓存
if (shop != null) {
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 3600, TimeUnit.SECONDS);
} else {
// 防止穿透
redisTemplate.opsForValue().set(key, "", 60, TimeUnit.SECONDS);
}
} finally {
localLock.unlock();
}
return shop;
}
}分布式锁版本(Redis 实现):
java
@Service
@Slf4j
public class ShopService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private RedissonClient redissonClient; // Redisson 分布式锁
public Shop getShopById(Long id) {
String cacheKey = "shop:" + id;
// 1. 查缓存
String shopJson = redisTemplate.opsForValue().get(cacheKey);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toJsonBean(shopJson, Shop.class);
}
// 2. 分布式锁
String lockKey = "lock:shop:" + id;
RLock lock = redissonClient.getLock(lockKey);
Shop shop = null;
try {
// 尝试加锁,最多等待 3 秒
if (lock.tryLock(3, 10, TimeUnit.SECONDS)) {
try {
// Double Check
shopJson = redisTemplate.opsForValue().get(cacheKey);
if (StrUtil.isNotBlank(shopJson)) {
return JSONUtil.toBean(shopJson, Shop.class);
}
// 查数据库
shop = shopMapper.selectById(id);
// 写缓存
if (shop != null) {
redisTemplate.opsForValue().set(cacheKey, JSONUtil.toJsonStr(shop), 3600, TimeUnit.SECONDS);
}
} finally {
lock.unlock();
}
} else {
// 没拿到锁,休眠重试
Thread.sleep(100);
return getShopById(id); // 递归重试
}
} catch (InterruptedException e) {
log.error("获取锁失败", e);
}
return shop;
}
}优点:简单有效,保证只有一个请求查 DB 缺点:其他请求会等待,有少量延迟
方案2:逻辑过期(永不过期 + 异步更新)
核心思路:缓存不设过期时间,而是存储一个"逻辑过期时间",后台异步刷新。
java
@Data
public class RedisData<T> {
private T data;
private LocalDateTime expireTime; // 逻辑过期时间
}
@Service
@Slf4j
public class ShopService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private ExecutorService executorService; // 线程池
public Shop getShopById(Long id) {
String key = "shop:" + id;
// 1. 查缓存
String json = redisTemplate.opsForValue().get(key);
if (StrUtil.isBlank(json)) {
// 缓存不存在(首次加载),查数据库
return loadShopFromDB(id);
}
// 2. 反序列化
RedisData<Shop> redisData = JSONUtil.toBean(json, RedisData.class);
Shop shop = redisData.getData();
LocalDateTime expireTime = redisData.getExpireTime();
// 3. 判断是否逻辑过期
if (expireTime.isAfter(LocalDateTime.now())) {
// 未过期,直接返回
return shop;
}
// 4. 已过期,尝试获取锁去异步更新
String lockKey = "lock:shop:" + id;
RLock lock = redissonClient.getLock(lockKey);
// 尝试获取锁(非阻塞)
boolean isLock = lock.tryLock();
if (isLock) {
try {
// 异步更新缓存(不阻塞当前请求)
executorService.submit(() -> {
try {
Shop newShop = shopMapper.selectById(id);
RedisData<Shop> newRedisData = new RedisData<>();
newRedisData.setData(newShop);
newRedisData.setExpireTime(LocalDateTime.now().plusMinutes(30));
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(newRedisData));
} finally {
lock.unlock();
}
});
} catch (Exception e) {
log.error("异步更新失败", e);
}
}
// 5. 返回旧数据(即使过期了)
return shop;
}
private Shop loadShopFromDB(Long id) {
Shop shop = shopMapper.selectById(id);
if (shop != null) {
// 写入缓存,逻辑过期时间 30 分钟
RedisData<Shop> redisData = new RedisData<>();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusMinutes(30));
redisTemplate.opsForValue().set("shop:" + id, JSONUtil.toJsonStr(redisData));
}
return shop;
}
}优点:完全无阻塞,用户体验好 缺点:可能返回旧数据(短暂不一致)
方案3:热点 Key 永不过期(手动刷新)
核心思路:真正的热点数据,设置永不过期,通过后台任务定时刷新。
java
@Service
public class ShopService {
// 启动时加载热点数据
@PostConstruct
public void init() {
loadHotShops();
}
// 定时刷新热点数据(每 10 分钟)
@Scheduled(fixedDelay = 600000)
public void refreshHotShops() {
log.info("开始刷新热点店铺缓存");
List<Long> hotShopIds = getHotShopIds(); // 比如销量 Top 1000
for (Long id : hotShopIds) {
Shop shop = shopMapper.selectById(id);
if (shop != null) {
redisTemplate.opsForValue().set("shop:" + id, JSONUtil.toJsonStr(shop));
}
}
log.info("热点店铺缓存刷新完成");
}
public Shop getShopById(Long id) {
// 直接从缓存读,永不过期
String json = redisTemplate.opsForValue().get("shop:" + id);
if (StrUtil.isNotBlank(json)) {
return JSONUtil.toBean(json, Shop.class);
}
// 缓存不存在(非热点),查数据库并设置短 TTL
Shop shop = shopMapper.selectById(id);
if (shop != null) {
redisTemplate.opsForValue().set("shop:" + id, JSONUtil.toJsonStr(shop), 600, TimeUnit.SECONDS);
}
return shop;
}
}优点:彻底解决击穿问题 缺点:需要识别热点数据,内存占用较大
方案4:分级缓存(本地缓存 + Redis)
核心思路:在应用内存中加一层 Caffeine 缓存,即使 Redis 过期了,本地缓存还能扛。
java
@Service
public class ShopService {
// 本地缓存:最大 1000 条,1 分钟过期
private final Cache<Long, Shop> localCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build();
@Autowired
private StringRedisTemplate redisTemplate;
public Shop getShopById(Long id) {
// 1. 查本地缓存
Shop shop = localCache.getIfPresent(id);
if (shop != null) {
return shop;
}
// 2. 查 Redis
String key = "shop:" + id;
String shopJson = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)) {
shop = JSONUtil.toBean(shopJson, Shop.class);
localCache.put(id, shop);
return shop;
}
// 3. 查数据库(加互斥锁)
// ... 互斥锁逻辑
shop = shopMapper.selectById(id);
if (shop != null) {
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 3600, TimeUnit.SECONDS);
localCache.put(id, shop);
}
return shop;
}
}优点:本地缓存扛住瞬间高峰,性能最好 缺点:多实例数据不一致
方案对比与选型
方案 | 实现难度 | 性能 | 数据一致性 | 适用场景 |
|---|---|---|---|---|
互斥锁 | ⭐ 简单 | 中(有等待) | 强一致 | 绝大多数场景 |
逻辑过期 | ⭐⭐ 中等 | 高(无等待) | 最终一致 | 可容忍短暂不一致 |
永不过期 | ⭐⭐ 中等 | 高 | 最终一致 | 真正的热点数据 |
分级缓存 | ⭐⭐⭐ 较复杂 | 极高 | 可能不一致 | 超高并发(秒杀) |
推荐:
- 99% 的场景:互斥锁(简单可靠)
- 对延迟极度敏感:逻辑过期 + 异步刷新
- 超热点数据:永不过期 + 定时刷新
面试回答模板
问:什么是缓存击穿?怎么解决? 答:缓存击穿是指热点 Key 在过期瞬间,大量并发请求同时打到数据库。我们项目采用互斥锁方案:
- 当缓存失效时,不立即查数据库,而是先获取分布式锁
- 只有拿到锁的线程才能查数据库,其他线程等待
- 拿到锁的线程查完数据库并写入缓存后,释放锁
- 其他线程拿到锁后发现缓存已有数据,直接返回
同时使用 Double Check 防止重复查询。对于超热点数据(如首页爆款商品),我们采用永不过期+定时刷新的策略,彻底避免击穿。在高并发场景下,互斥锁会增加少量延迟(约 10-20ms),但能有效保护数据库。
基于查询商铺的业务用互斥锁解决缓存击穿:
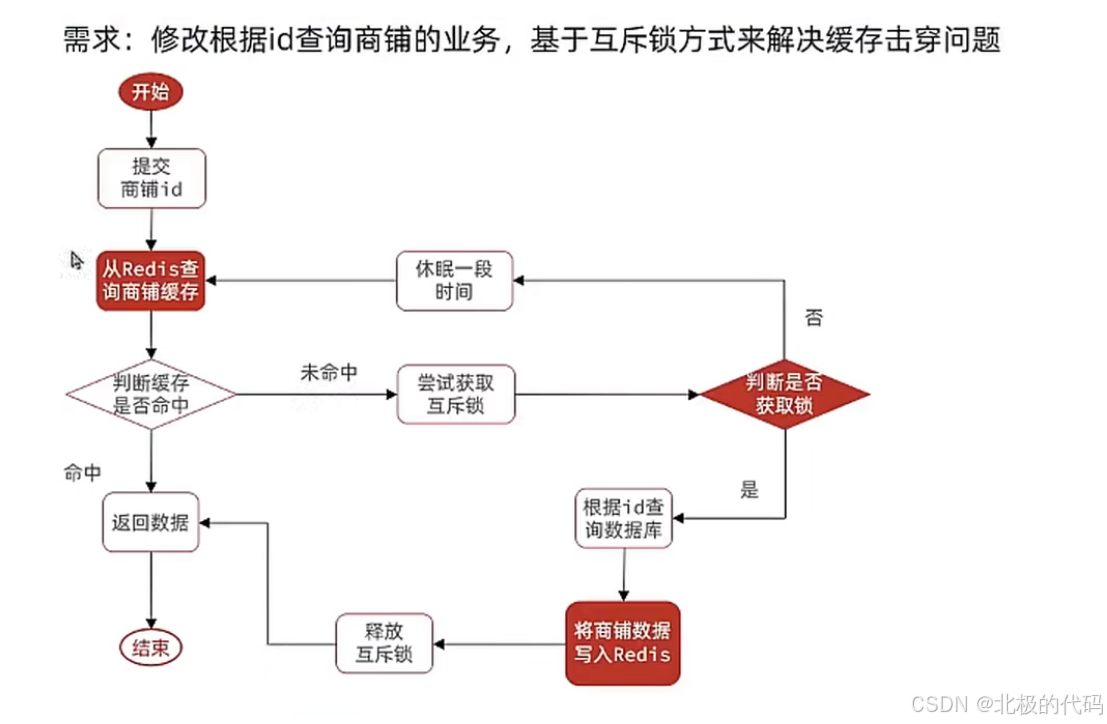
流程图解
text
请求到达
│
▼
┌─────────────────────────────────────┐
│ 1. 查询缓存 │
│ String shopJson = redis.get(key) │
└─────────┬───────────────────────────┘
│
┌─────┴─────┐
│ 是否命中? │
└─────┬─────┘
│
┌─────┴──────────────────────────┐
│ │
命中非空 未命中
│ │
▼ ▼
返回数据 ┌─────────────────┐
│ 2. 尝试获取锁 │
│ tryLock(lockKey)│
└────────┬────────┘
│
┌───────┴───────┐
│ 是否拿到锁? │
└───────┬───────┘
│
┌───────────────┴───────────────┐
│ │
否 是
│ │
▼ ▼
休眠50ms ┌─────────────────┐
递归重试 │ 3. Double Check │
│ │ 再次查询缓存 │
│ └────────┬────────┘
│ │
│ ┌────────┴────────┐
│ │ 缓存是否有数据? │
│ └────────┬────────┘
│ │
│ ┌────────┴────────┐
│ │ 没有 有 │
│ ▼ ▼
│ ┌──────────┐ 直接返回
│ │ 4.查数据库│
│ └─────┬────┘
│ │
│ ▼
│ ┌──────────┐
│ │ 5.写缓存 │
│ └─────┬────┘
│ │
└─────────────────┬───┘
▼
┌──────────┐
│ 6.释放锁 │
└─────┬────┘
│
▼
返回数据代码实现:
public Shop queryWithMutexCache(Long id) {
String key = RedisConstants.CACHE_SHOP_KEY+ id;
//从Redis中查询商品缓存信息
String shopJson = stringRedisTemplate.opsForValue().get(key);
//判断缓存是否存在
if(StrUtil.isNotBlank(shopJson)){
//存在,直接返回
//将json转为对象
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return shop;
}
//判断命中的是否为空
if (shopJson != null){
return null;
}
//缓存击穿利用互斥锁解决
//1.获取互斥锁
String lockKey=RedisConstants.LOCK_SHOP_KEY+id;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
//3.判断锁是否获取成功
if (!isLock){
//获取锁失败,休眠并重试
Thread.sleep(50);
return queryWithMutexCache(id);
}
//4.获取锁成功,DoubleCheck双检测
String resultShopJson= stringRedisTemplate.opsForValue().get( key);
//5.存在,返回数据
if (StrUtil.isNotBlank(resultShopJson)){
return JSONUtil.toBean(resultShopJson, Shop.class);
}
// 4.5 DoubleCheck命中空值
if (resultShopJson != null) {
return null;
}
//不存在,查询数据库
shop = getById(id);
if (shop== null){
//将空值写入缓存(防止缓存穿透)
stringRedisTemplate.opsForValue().set(key,"",RedisConstants.CACHE_NULL_TTL,TimeUnit.MINUTES);
return null;}
//写入缓存
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("获取锁失败", e);
} finally {
//6.释放锁
unlock(lockKey);
}
return shop;
}总体思路和缓存穿透差不多,只是多了个锁的逻辑。
为什么需要 Double Check
text
场景:线程A和线程B同时发现缓存不存在
错误流程(没有Double Check):
t=0ms: 线程A: 获取锁成功 → 查数据库(耗时200ms)
t=1ms: 线程B: 获取锁失败 → 休眠50ms → 重试
t=51ms: 线程B: 重试时,缓存还是空的(线程A还没写完)
线程B: 再次获取锁 → 又查了一次数据库 ❌
正确流程(有Double Check):
t=0ms: 线程A: 获取锁成功 → 查数据库(耗时200ms)
t=1ms: 线程B: 获取锁失败 → 休眠50ms → 重试
t=51ms: 线程B: 重试 → 获取锁成功
线程B: Double Check → 发现缓存已有数据(线程A写入了)
线程B: 直接返回,不查数据库 ✅对比:有双重检查 vs 无双重检查
场景:3个线程,缓存初始为null
时间 | 有双重检查 | 无双重检查 |
|---|---|---|
t=0ms | 3个线程发现缓存null | 3个线程发现缓存null |
t=1ms | 线程A拿到锁 | 线程A拿到锁 |
t=2ms | 线程A第2次检查→null | 线程A直接查DB(无第2次检查) |
t=3ms | 线程A查DB | 线程A查DB |
t=101ms | 线程B拿到锁 | 线程B拿到锁 |
t=102ms | 线程B第2次检查→有数据✅ | 线程B直接查DB❌ |
t=103ms | 线程B返回,不查DB | 线程B又查了一次DB |
t=104ms | 线程C拿到锁 | 线程C拿到锁 |
t=105ms | 线程C第2次检查→有数据✅ | 线程C直接查DB❌ |
结果:
- 有双重检查:1次DB查询 ✅
- 无双重检查:3次DB查询 ❌
总结
问题 | 答案 |
|---|---|
为什么双重检查时缓存还是null? | 因为当前线程是第一个拿到锁的线程,还没有任何线程写入过缓存 |
什么时候会出现这种情况? | 缓存真正为空时(从未查询过 或 缓存已过期) |
这种情况是好是坏? | ✅ 是好的!说明当前线程应该去查数据库 |
如果双重检查时不是null呢? | 说明其他线程已经查过了,当前线程直接返回,不查数据库 |
核心记忆:
双重检查时缓存还是null → 说明我是第一个 → 我去查数据库 双重检查时缓存不是null → 说明别人查过了 → 我直接用
结语:如果对你有帮助,请点赞,关注,收藏,你的支持就是我最大的鼓励!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号