Nature Reviews Drug Discovery:AI时代的药物靶点识别与评估

Nature Reviews Drug Discovery:AI时代的药物靶点识别与评估

MindDance
发布于 2026-04-21 13:39:38
发布于 2026-04-21 13:39:38
药物研发的高失败率,在相当大程度上并不源于分子设计本身,而是起始阶段的靶点选择存在根本性不确定性。昨日发表于 Nature Reviews Drug Discovery 的综述 Target identification and assessment in the era of AI,系统讨论了人工智能在药物靶点识别与评估中的应用图景。文章的核心判断是,AI正在重塑靶点发现的方法学基础,但其价值并不在于简单替代生物学推理,而在于整合异质数据、生成可检验假说、提高优先级排序效率,并在实验与临床反馈中不断修正模型。
从全文结构看,这篇综述并未将AI视为单一算法工具,而是将其置于一个更完整的研发框架中:从疾病生物学理解、候选靶点提出,到可成药性、安全性、竞争格局与实验验证,再到临床阶段的持续检验。对当前从事AI制药、转化医学和药物发现的研究者而言,这篇文章的价值,不仅在于梳理了主流技术路线,也在于它较为清醒地界定了该领域的现实边界与方法学约束。

一、靶点识别为何仍是药物研发最关键的早期环节
文章指出,靶点识别通常是药物发现流程中的起点,其质量会直接影响后续的先导化合物设计、适应证选择、临床试验路径以及总体资源配置。传统靶点发现长期依赖动物模型、临床观察和分子生物学实验,但随着人类遗传学、组学技术和因果推断方法的发展,研究者越来越强调来自人类本体数据的证据强度。
综述特别提到,具有人类遗传学支持的药物机制,其成功概率通常显著高于缺乏此类支持的项目。这一变化意味着,靶点发现正在从以经验和局部实验为中心,逐步转向以多源证据整合和因果推断为基础的体系化研究。
文章同时给出一个值得反复咀嚼的背景数据:人类大约有 20,000 个蛋白编码基因,其中估计约 4,500 个具有可成药潜力,但目前所有已获批药物所覆盖的不同靶点仅约 716 个。换言之,现有药物开发活动仍只触及了潜在靶点空间的一小部分,未被充分开发的靶点资源依然非常广阔。
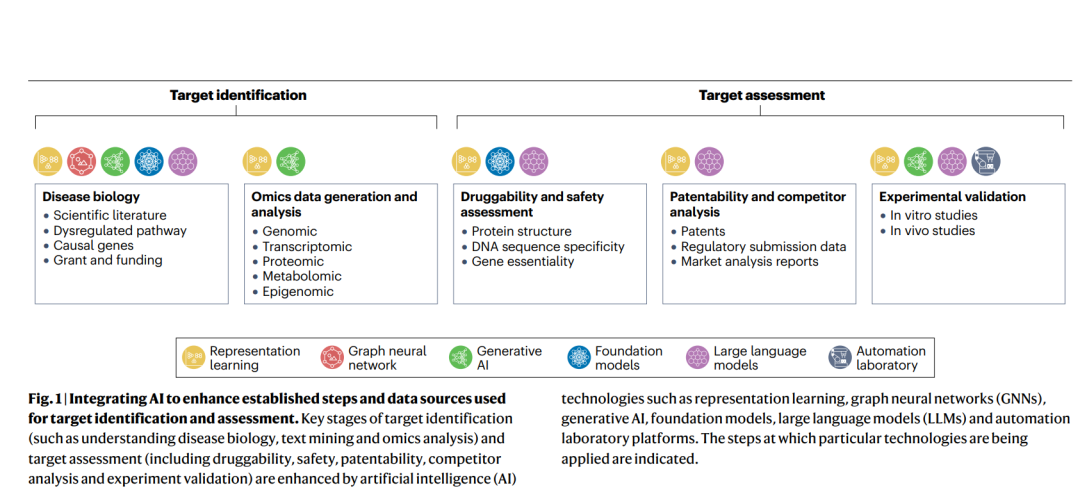
二、靶点识别不是单点预测,而是完整的证据构建过程
这篇综述的一大特点,是它并未将靶点识别简化为模型对基因进行排序的问题。相反,作者强调,靶点发现本质上是一个连续决策过程,通常包括疾病方向选择、疾病机制梳理、候选靶点提出、可成药性与安全性评估、知识产权与竞争格局分析,以及后续的体内外实验验证。
因此,AI的作用并不是凭空给出正确答案,而是在不同阶段协助研究者处理复杂信息。例如,它可以整合文献、组学、影像、临床试验、电子病历、专利和市场数据,构建跨层级的疾病表征;也可以利用机器学习模型识别潜在机制节点、预测靶点风险,甚至辅助实验设计和结果回流。文章所描述的,并不是单一模型的升级,而是靶点发现范式的系统性演化。
三、靶点选择的核心标准:机制、可成药性、安全性与转化价值
在作者看来,靶点识别首先是一个生物学问题,其次才是一个计算问题。一个候选靶点之所以值得进入药物开发流程,至少需要满足以下几类要求。
1. 治疗假说必须成立
所谓治疗假说,并不是指某个分子与疾病显著相关,而是指研究者能够提出可信的机制链条,说明该靶点的调控如何影响疾病进程,并最终转化为患者可感知的临床获益。换言之,AI所支持的并不应只是相关性排序,而应服务于更严格的机制性推断。
2. 可成药性必须具体到治疗模态
对于小分子药物,可成药性通常与靶标表面的结合口袋、配体可及性和结构可塑性密切相关;对于抗体、寡核苷酸、基因治疗和细胞治疗,则需要采用不同的评价标准。文章特别强调,随着治疗模态多样化,可成药性的定义已不再局限于传统小分子范式。AlphaFold3 等结构预测工具之所以重要,恰恰在于它们可以为蛋白-配体、抗体-抗原以及寡核苷酸-蛋白复合体提供更高质量的结构信息,从而扩展早期评估能力。
3. 安全性应尽早纳入靶点评估
综述明确区分了靶点层面的 on-target 风险与后续药物层面的 off-target 风险。某些不良反应本身就来自靶点生理功能的干预,因此安全性不应被视为临床后期才需要考虑的问题。作者认为,预测毒理学、通路级分析和结构相似性评估,可以在靶点阶段预先识别部分风险。与此同时,真正全面的 off-target 评估仍需依赖后续候选药物筛选和实验体系验证。
4. 新颖性、把握度与商业可行性之间存在张力
文章用了较大篇幅讨论首创新靶点与成熟靶点优化之间的平衡。高把握度靶点通常证据更充分,转化路径更清晰,但往往竞争激烈;高新颖性靶点则可能带来 first-in-class 机会,但科学与商业不确定性也更高。作者并不主张片面追求新颖性,而是强调靶点选择必须同时考虑科学可信度与商业可实施性。
5. 联合治疗价值越来越重要
对于肿瘤、感染和多因素慢病等复杂疾病,单靶点干预往往不足以获得理想疗效。文章因此提出,候选靶点是否具备联合治疗潜力,已成为越来越重要的评价维度。这一判断使靶点价值不再局限于其单药属性,而延伸到更广泛的治疗策略布局之中。
四、AI用于靶点识别的主要数据基础
综述系统总结了AI驱动靶点识别所依赖的多类数据资源。作者反复强调,模型性能的上限在很大程度上取决于数据质量、覆盖面与整合方式。
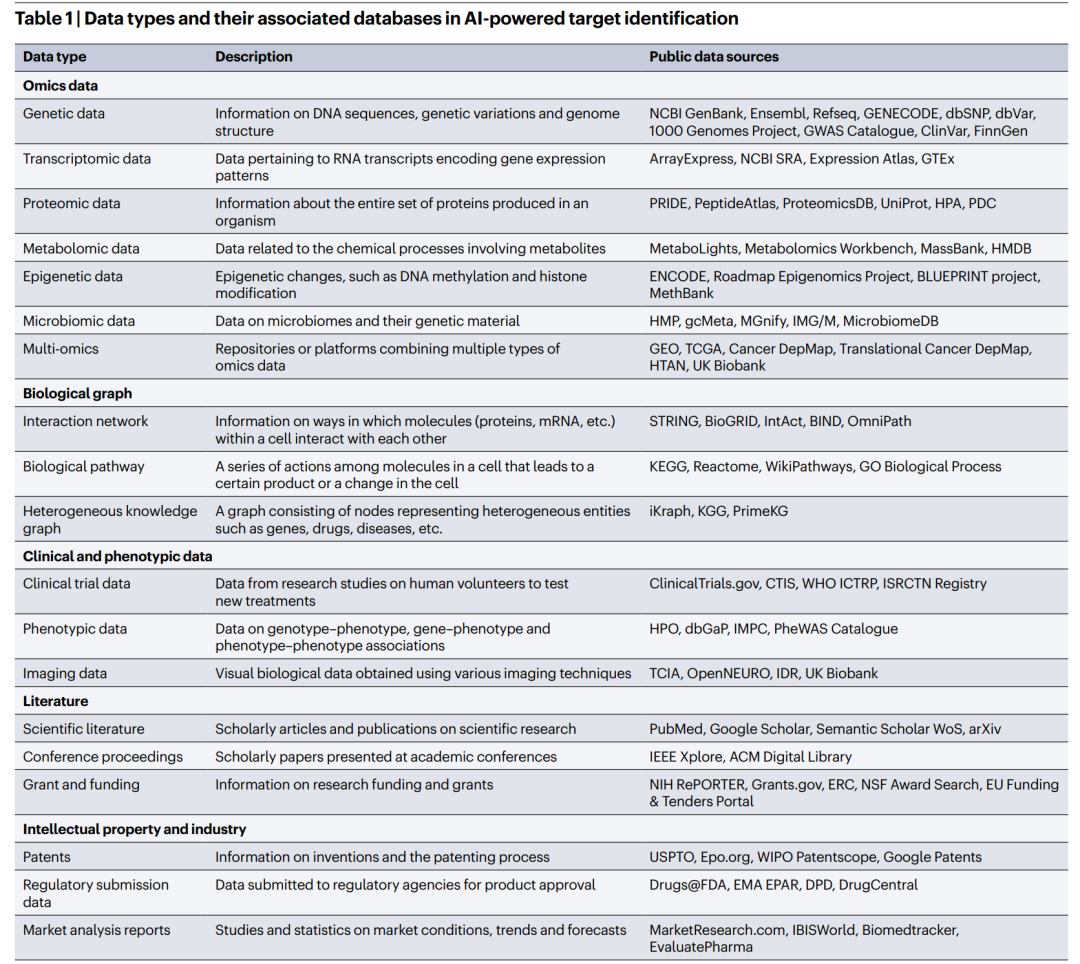
1. 多组学数据
基因组、转录组、蛋白组、代谢组、表观组以及微生物组数据,共同构成了疾病分子机制的多层视图。对于靶点识别而言,单一维度的异常往往不足以支撑因果判断,而跨组学整合则有助于定位真正位于疾病驱动网络中的关键节点。
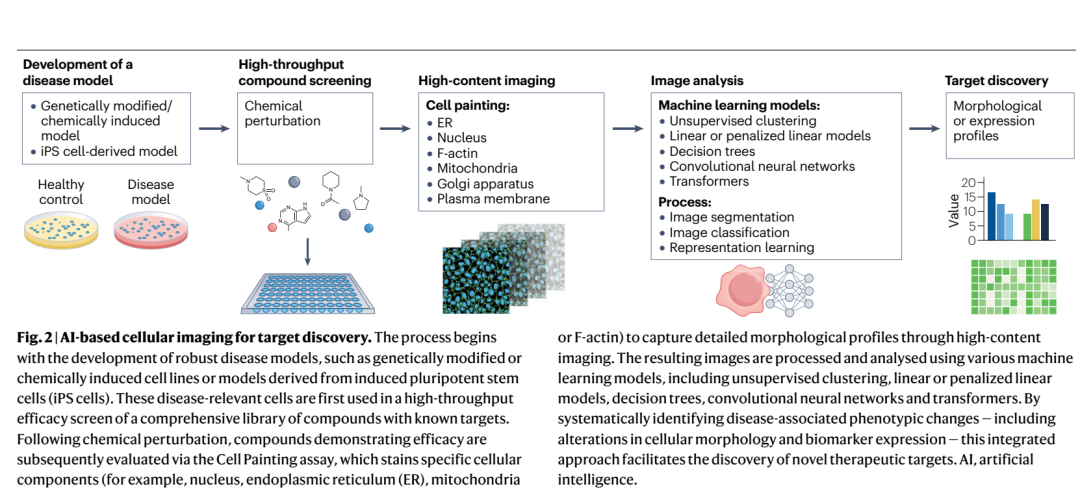
2. 细胞影像与高内涵表型数据
文章将高内涵成像与 Cell Painting 视为重要的数据来源,因为许多疾病状态首先表现为细胞形态、细胞器状态或应激模式的系统性改变,而非单个分子读数的异常。综述引用了肠道纤维化和 ALS 的案例,说明图像表征学习和 transformer 等模型可以从复杂表型中提取疾病相关信号,并反向支持靶点发现。
3. 生物知识图谱与网络数据
蛋白互作网络、通路数据库和异质知识图谱之所以适合AI应用,是因为靶点本质上并非孤立节点,而是嵌入在多层生物网络之中。图神经网络、矩阵分解和路径推理等方法,可以在这些网络中发现隐含关系、候选因果链和潜在可干预位点。
4. 临床与表型数据
临床试验数据库、电子病历、患者分层信息及影像资料,使得靶点识别不再停留在分子层面,而有机会与真实患者结局建立联系。文章认为,临床数据尤其有助于判断某一靶点是否真正具有患者获益意义,而不仅是实验体系中的统计显著性。
5. 文献、专利、监管与市场信息
这是全文非常务实的一部分。作者明确指出,靶点识别并非纯粹的学术问题。科学文献、基金流向、专利、监管申报和市场报告,都能够为靶点的新颖性、竞争格局和商业化前景提供额外证据。成熟的AI靶点平台,往往不是围绕单一组学矩阵构建,而是面向一个跨科学与产业的信息生态系统。
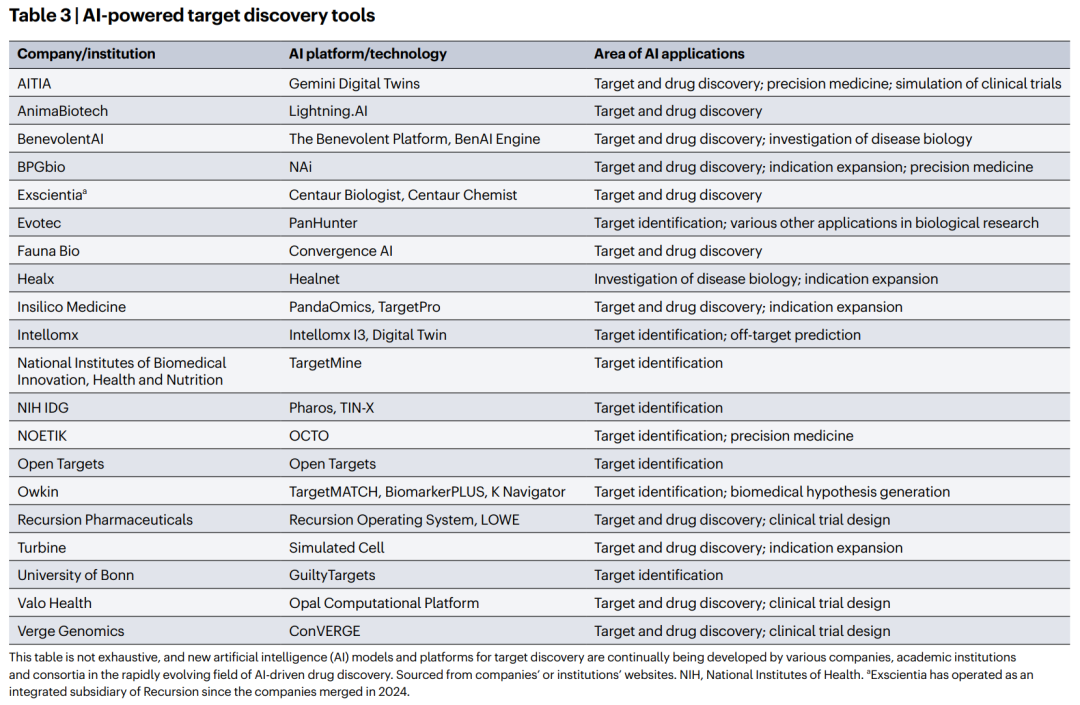
五、AI方法谱系:从监督学习到基础模型与多智能体系统
文章并未将注意力局限于某一类热门模型,而是从方法论上梳理了当前靶点识别中的主要AI技术路线。
1. 监督学习
监督学习适用于已有标签的问题,例如药物-靶点相互作用预测、疾病基因优先级排序等。文中列举的 BANDIT、L2G、MPxgb 与 TargetPro 都属于这一范畴。这类模型的优势在于可以利用既往已知药理与遗传学知识,学习与临床相关的可迁移规律。
2. 无监督与自监督学习
生物医学领域大量数据缺乏明确标签,因此无监督和自监督学习具有天然优势。它们可以从海量未标注数据中学习潜在结构,例如网络模块、图像表示和分子表征。文章将这种能力视为发现新颖靶点的重要基础,因为它有助于突破对既有标签体系的过度依赖。
3. 半监督学习
在已知正样本极少、未知样本极多的情况下,半监督学习尤其适合靶点发现任务。DrugnomeAI 与 GuiltyTargets 的例子说明,在标签稀缺场景下,结合少量已知靶点与大量未标注基因,可以更有效地完成可成药性评估和优先级排序。
4. 表征学习与图神经网络
表征学习能够将蛋白序列、显微图像、网络结构和多组学数据编码为高维嵌入,用于下游推理与预测。图神经网络则特别适合处理蛋白互作网络、知识图谱和通路图等结构化数据。文章中的 KG4SL、EMOGI 与 PDGrapher 等模型,展示了图方法在癌症靶点、合成致死关系以及疾病逆转性扰动组合发现中的应用潜力。
5. 生成式AI与基础模型
在作者看来,生成式AI和基础模型的意义不只是生成文本或图像,而是通过大规模预训练获得更通用的生物学表示。Geneformer、scGPT 和 Phenom-Beta 分别代表了单细胞转录组与表型影像方向的基础模型,它们通过在超大规模数据上学习表达模式、细胞状态与扰动规律,使模型具备迁移到多种下游任务的能力。
6. 大语言模型与多智能体系统
BioGPT 与 TxGemma 代表了面向生物医学与药物开发任务的大语言模型。更进一步,文章提到 AI co-scientist 和 OriGene 这类多智能体框架,前者可在代理间的生成、争论与修正中迭代优化科学假说,后者则试图模拟虚拟疾病生物学家的推理流程,在多组学、临床与文献数据库之间完成面向问题的协同检索与综合判断。综述在这一部分的表述相对克制,但可以看出,作者已将自然语言驱动的推理系统视为未来靶点发现的重要组成部分。
六、模型提出靶点之后,如何证明其具有真实价值
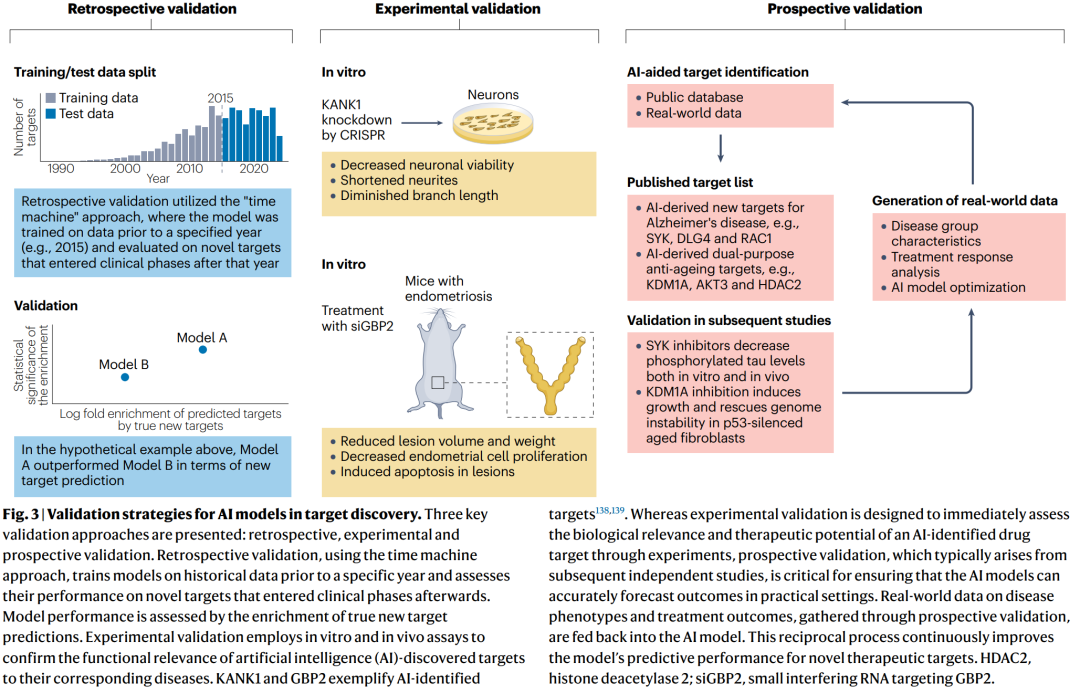
文章将AI模型验证划分为三个层次,这一部分对于理解靶点发现研究的证据等级非常关键。
1. 回顾性验证
回顾性验证通常采用时间切分策略,也即所谓的时间机器方法:用某一时间点之前的数据训练模型,再评估其是否能够预测后续进入临床阶段的新靶点。该方法主要用于回答一个核心问题,即模型是否真正具有前瞻性,而不是仅仅复述历史知识。
2. 实验验证
实验验证包括体外细胞实验、分子实验和动物模型研究。文章以 KANK1、GBP2 和 HCK 等例子说明,AI预测的候选靶点只有在功能扰动后产生与疾病一致的表型变化,才具备进一步推进的合理性。作者同时指出,实验验证昂贵且耗时,因此AI不仅用于提出靶点,也需要帮助确定最值得验证的对象。
3. 前瞻性验证
前瞻性验证要求AI提出的靶点在后续独立研究乃至临床开发中得到支持。综述举例称,某些AI提出的阿尔茨海默病和衰老相关靶点,后来在独立研究中得到进一步印证。文章还引用了关于临床试验结果预测的研究,说明AI在更接近真实研发结局的场景下,已有一定验证基础。作者最终强调,靶点的终极验证标准仍然是成功的人体临床试验。
七、AI不仅用于识别靶点,也在重塑靶点评估
1. 结构预测与可成药性分析
在靶点评估层面,AlphaFold 系列模型的影响尤为显著。文章认为,结构预测AI极大扩展了可用于早期分析的蛋白结构资源,使研究者即便在缺乏实验结构的情况下,也能够开展初步的口袋分析、配体结合推断和结构辅助设计。
但作者并未因此夸大结构AI的实际能力。综述明确指出,在部分回顾性分子对接研究中,AlphaFold 结构在重现配体结合模式和区分活性分子方面仍存在局限;不过在部分前瞻性配体发现案例中,其表现已接近实验结构。这意味着结构预测AI对于靶点评估非常重要,但仍需与实验结构和后续药化验证相结合。
2. 隐性口袋与潜在可成药蛋白空间的扩展
文章还特别讨论了 cryptic pockets,也即在无配体结构中不明显、但可能在构象变化中暴露的隐性结合口袋。PocketMiner 等模型可以以远高于传统模拟方法的速度预测这类口袋,从而显著扩展潜在可成药蛋白的范围。对于长期被视为难成药或不可成药的靶标而言,这类方法具有明显的方法学意义。
3. 新颖性与商业可实施性评估
综述提出,靶点评估不应停留在生物学层面。基于AI和大语言模型的综合分析,可以同时衡量靶点的新颖性、竞争程度、因果证据强弱、实验模型可得性以及监管和市场环境。这个视角表明,靶点价值的判断正在从单维度科学评价,走向科学、技术与产业约束的联合分析。
八、文章重点讨论的几个临床阶段案例
作者强调,到目前为止,尚无源自AI驱动靶点识别的新药最终通过成功临床试验并获得监管批准。不过,已经有少数由AI识别或显著支持其靶点假说的候选药物进入临床阶段。综述重点讨论了以下几类案例。
1. TNIK:特发性肺纤维化
在 IPF 场景中,Insilico Medicine 利用整合二十余种AI和生物信息模型的平台,从 IPF 与健康肺组织的多组学数据中优先识别出 TNIK。随后设计得到 TNIK 抑制剂 INS018_055,并在约 18 个月内完成前临床推进。文章指出,该化合物在肺、皮肤和肝纤维化小鼠模型中表现出抗纤维化和抗炎活性;在两项 I 期和一项 IIa 期研究中显示出可接受的安全性与耐受性。中国 IIa 研究纳入 71 例 IPF 患者,并在次要终点用力肺活量上观察到剂量依赖性改善。
2. APLNR:代谢性衰老与肥胖相关方向
BioAge 基于纵向人类衰老队列、多组学数据与贝叶斯网络分析,识别出 apelin 信号相关网络,并支持 APLNR 作为干预代谢衰老的潜在靶点。文中提到,APLNR 激动剂 azelaprag 在 I b 期研究中能够减缓老年卧床人群肌肉大小、功能与蛋白合成能力的下降,血浆蛋白组结果也显示其可重现部分耐力运动相关效应。不过,后续 azelaprag 与 tirzepatide 联合用于肥胖的 II 期试验因部分受试者出现肝酶升高而终止。这一案例提示,AI能够提高靶点提出的质量,但并不能消除后续开发中的安全性风险。
3. PIKfyve:ALS
在 ALS 领域,PIKfyve 抑制的概念已有前期实验支持,而 Verge Genomics 的 ConVERGE 平台则进一步从人源多模态数据出发强化了这一靶点方向,并推动候选药物 VRG50635 进入 I 期和概念验证研究。文章指出,该项目最终因疗效不足而终止。这一结果较为清楚地表明,计算预测、人源数据支持与临床有效性之间仍然存在显著鸿沟。
4. DRD2:表型筛选后的AI靶点去卷积
DRD2 案例具有较强的方法学代表性。ONC201 最初来源于表型筛选,而非先验靶点假说;其后通过 BANDIT 对药物结构、转录响应、已知靶点和不良反应等多类特征的整合分析,预测 DRD2 是其关键靶点之一。该预测得到实验支持,并推动了在高 DRD2 表达肿瘤中的临床探索。值得注意的是,文章同时指出,dordaviprone 在 2025 年获批用于 H3 K27M 突变弥漫性中线胶质瘤时,其关键抗肿瘤活性可能更多与后续发现的线粒体 caseinolytic protease P 别构激活有关。这一案例提示,AI支持的靶点去卷积十分重要,但真实药理机制往往比单一靶点叙事更复杂。
九、作者如何看待当前AI靶点发现的主要限制
与一些过度乐观的综述不同,这篇文章对现实问题的讨论相当充分。
1. 数据质量与数据可得性仍是基础瓶颈
文章指出,AI模型高度依赖大规模高质量数据,但现实中的组学数据库常存在元数据缺失、标签错误、命名不一致等问题。对于罕见病、少数族群和社会弱势人群,数据匮乏会进一步削弱模型泛化能力。文献数据同样存在可重复性不足的问题,而由文献与数据库构建的知识图谱还会继承热门基因偏置和度偏置。
2. 类别不平衡会影响模型偏好
已知药物靶点在全基因组中本就占极少数,这使得模型很容易学习到接近既有热门靶点的模式,而不擅长识别真正新颖但证据稀疏的候选。对靶点发现而言,这不是简单的数据科学问题,而是会直接影响创新能力边界的问题。
3. 多模态整合远未成熟
尽管多组学和多模态整合已成为共识,但不同数据类型之间在量纲、噪声结构、缺失机制和生物学语义上存在根本差异。文章因此认为,未来真正重要的进展,不只是更大的模型,而是更可靠的异质数据整合框架。
4. 可解释性与透明度仍需显著增强
作者明确指出,黑箱模型在药物研发决策中面临天然阻力。研究者不仅关心模型给出什么结论,更关心其证据来源、关键特征与错误模式。可解释AI的重要性,正在于让模型输出能够被领域专家审阅、质疑与修正。
5. 评测体系尚不统一
文章认为,传统分类指标不足以全面衡量靶点识别系统的价值,因为真正重要的问题还包括可成药性、结构信息可得性、实验验证可行性、再利用潜力和临床相关性。TargetBench 等新型评测系统的意义,正在于尝试将这些更贴近真实研发需求的维度纳入统一比较框架。
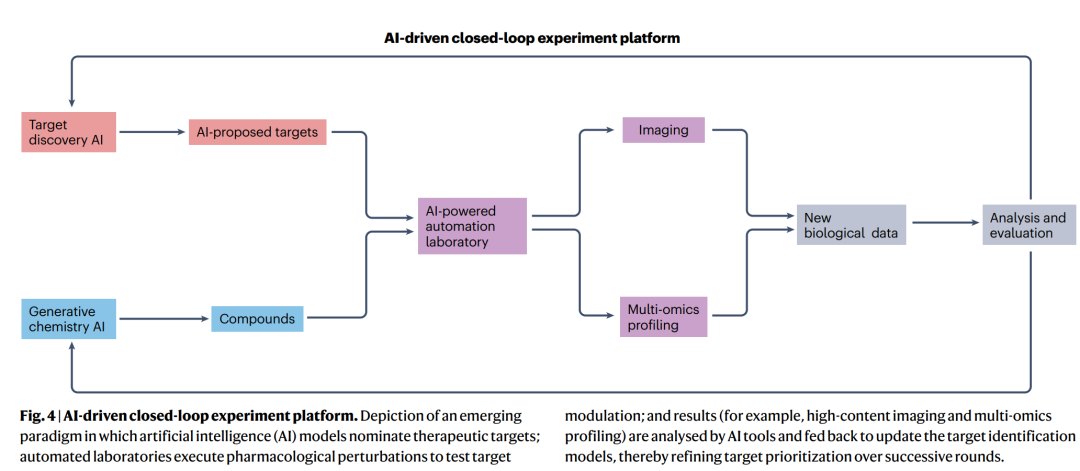
十、未来方向:闭环式AI实验平台
在文章的结尾部分,作者提出了一个非常清晰的未来图景:靶点发现的关键,不再只是提升单个模型的预测性能,而是构建闭环式AI实验平台。在这一框架中,AI模型提出候选靶点,自动化实验平台执行扰动与检测,高内涵影像和多组学数据实时回流,再由AI系统进行分析、更新与再排序。
这种模式将计算与实验联结为可迭代循环,使靶点发现从线性流程转变为持续优化过程。综述提到,AstraZeneca、Tempus 和 Insilico Medicine 等已在推进类似平台。作者显然认为,这类系统才更可能真正提高靶点发现的转化效率。
END
总体而言,这篇综述传达出的并不是一种技术乐观主义,而是一种更接近现实研发场景的方法论更新。AI在药物靶点识别与评估中的真正价值,不是替代实验,也不是绕开生物学,而是提高证据整合能力、增强假说生成效率、优化验证优先级,并在实验与临床反馈中持续改进决策。
对于药物研发领域而言,AI正在改变的,或许不是发现靶点这一目标本身,而是发现靶点的方式:从零散证据驱动,转向多模态整合;从静态判断,转向动态迭代;从局部最优,转向更面向临床转化的系统优化。就这一点而言,这篇文章提供的不是某种终局答案,而更像是一份关于未来研发基础设施如何演化的清晰路线图。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号