智谱GLM太强了,coding plan还需要限时抢购,咱们自己vllm也咧一个呗!

智谱GLM太强了,coding plan还需要限时抢购,咱们自己vllm也咧一个呗!

有态度的马甲
发布于 2026-04-21 09:54:05
发布于 2026-04-21 09:54:05

图片
上文《higress这个中登才是AI时代的心头好》提到用vll production-stack 部署LLM, 今天我们补交作业, 记录使用vllm production-stack 部署llm。
1. k8s调度gpu
集群管理员,需要在worker节点上安装设备驱动,并运行对应的设备插件。
为了让 K8s 识别并使用 GPU,这两个条件必须同时满足:
- NVIDIA驱动(NVIDIA Drivers):操作系统与GPU 硬件通信的底层基础,它让操作系统能够识别并控制 GPU 。
- NVIDIA Device Plugin:K8s的插件(节点上以daemonset形式部署),负责将GPU资源上报给K8s集群(nvidia.com/gpu),并让Pod可以请求和使用这些资源 。

具体表现在:
kubectl describe node node10上能显示扩展资源:
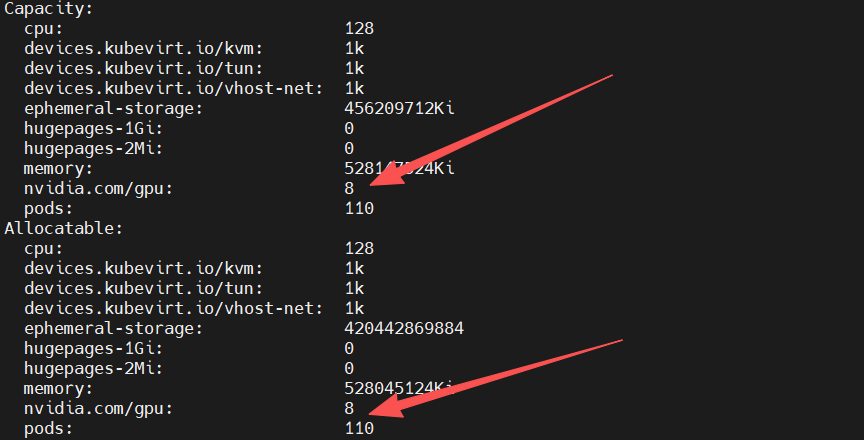
对于扩展资源gpu,请求和限制必须一样。
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
为帮助我们在k8s中便捷配置、管理GPU,英伟达推出了gpu operator[1] ,具备以下能力
- NVIDIA 驱动程序(以启用 CUDA)
驱动会在每个节点上以pod形式安装,
kubectl exec -it -n gpu-operator nvidia-driver-daemonset-xxxxx -- nvidia-smi, 或者sudo chroot /run/nvidia/driver nvidia-smi(因为驱动文件被挂载到主机这个目录下); 另外如果主机上安装了nvidia-smi驱动,gpu operator将不会在该节点上部署driver pod。
- k8s device plugin
- NVIDIA Container Toolkit、
- 使用 GFD 的自动节点标记
- 基于 DCGM 的监控
以下使用默认helm charts配置安装 gpu operator:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v24.9.2
以上为worker节点配置了最常见的容器gpu加速, gpu operator还支持配置虚拟机gpu加速、管理vgpu设备[2], 如果你的k8s集群要管控云原生虚拟机(kubevirt)[https://github.com/kubevirt/kubevirt],需要先按照文档步骤设置节点标签
kubectl label node <node-name> --overwrite nvidia.com/gpu.workload.config=vm-passthrough.
2. vllm production-stack
2.1 vllm的原理
为了理解请求,LLM 需要了解字词之间的关系以及如何在字词之间建立关联,与人类使用语义和推理来理解字词不同,LLM 是通过数学运算来“推理”的, 面对大量用户请求时, 需要消耗大量显存。
vllm[3]是伯克利大学开源的吞吐量最强、最容易使用的推理引擎。
从本质上讲,vLLM[4]作为一组指令工作,通过持续“批处理”用户请求,鼓励KV Cache创建快捷方式。
① KV Cache: 是一种短期内存存储, 它是将每个token(词元)所对应的值保存到缓存中, 以空间换时间的方式支持快速推理。
② 连续批处理:是一种可同时处理多个查询的技术(将先前计算的查询词元创建快捷方式),。
借助vLLM,LLM可以将批处理请求中重复部分的词元字符串(“what is the capital of”)保存在短期记忆(KV 缓存)中,并发送一个“翻译请求”,而不是两个单独的请求。
2.2 vllm production-stack
LMCache[5]大语言模型推理引擎的扩展,目标是减小首字延迟TTFT,提高吞吐量。
LMCache与vllm结合产生了 vllm production-stack, 通过这个项目可以得到:
- 无需更改任何应用代码, 就能从单个vLLM实例扩展到分布式vLLM部署
- 通过网页仪表盘监控指标
- 基于请求路由和KVCache卸载带来的性能提升
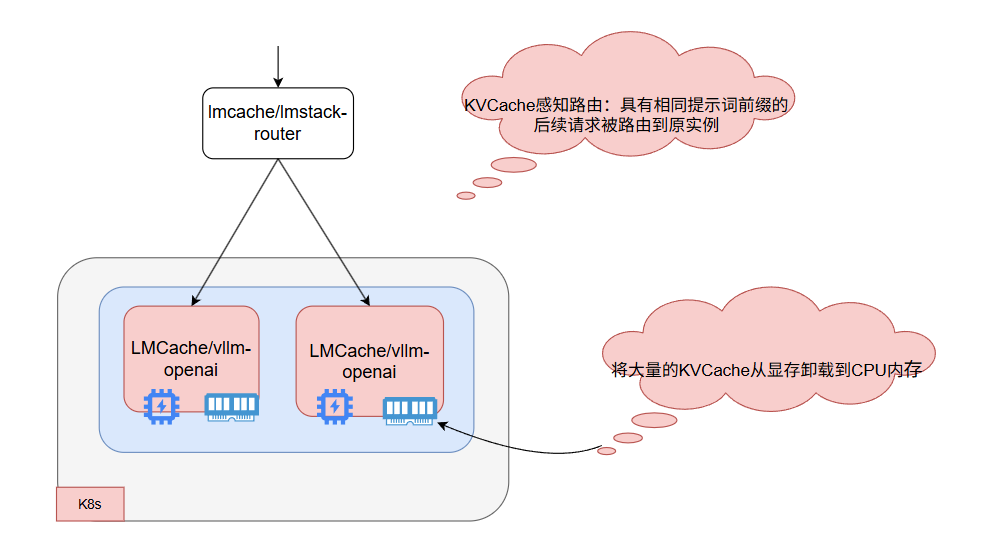
① KV Cache感知路由[6]: 确保具有相同prompt前缀的后续请求被路由到同一实例,从而最大化 KV 缓存的利用率并提高性能。
② KVCache卸载[7]将大量KV Cache从GPU显存卸载到CPU或磁盘,从而实现更多潜在的KV Cache命中, 在helm charts中要应用lmcache-vllm[8]镜像。
3. glm4.7-flash
glm4.7-flash[9]是一个 30B-A3B MoE 模型, 号称30B级别中最强的模型。
按照上文显存估算: 权重值大概60GB, 可部署在4卡24G 4090上。
官方提示glm这货需要使用transformers框架, 最新的vllm-openai:latest镜像无 transformers框架,使用vllm-openai:latest会报错。
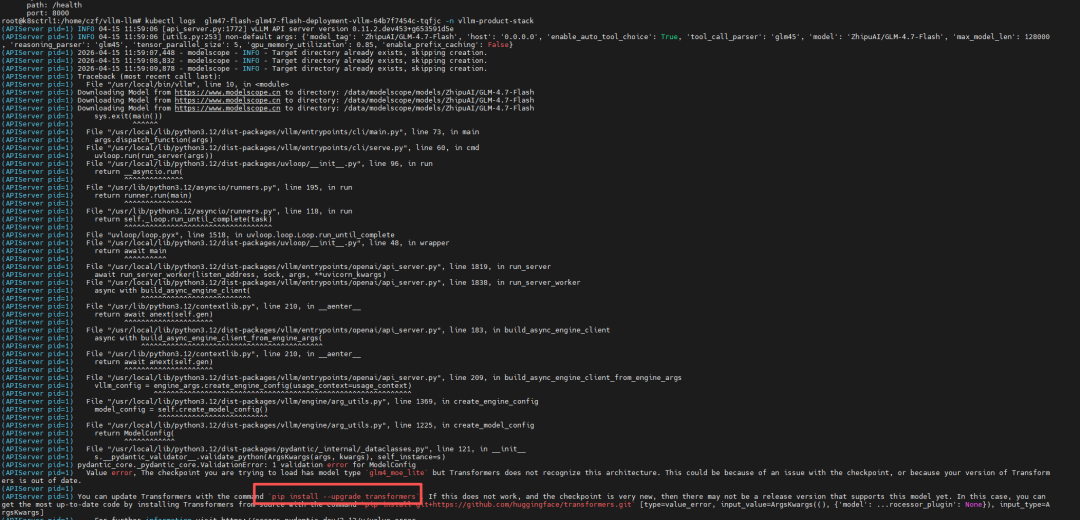
故需要我们自己建立一个镜像,dockerfile也很简单(基础镜像不是lmcache-vllm, 不带显存卸载能力):
FROM vllm/vllm-openai:latest
RUN apt-get update && \
apt-get install -y git && \
rm -rf /var/lib/apt/lists/*
# 安装支持 GLM-4.7-Flash 的最新版 transformers
RUN pip install --no-cache-dir git+https://github.com/huggingface/transformers.git \
-i https://mirrors.aliyun.com/pypi/simple/
# docker build -t12205599/vllm-glm47:fixed -f Dockerfile
# docker push 12205599/vllm-glm47:fixed
使用vllm production-stack时,要注关注 helm charts value文件:
下面使用4卡4090部署1个glm4.7-flash模型实例。
# glm4.7-flash.yaml
root@k8sctrl1:/home/czf/vllm-llm# cat glm47-flash.yaml
routerSpec:
imagePullPolicy: "IfNotPresent"
nodeSelectorTerms:
- matchExpressions:
- key: nvidia.com/gpu.workload.config
operator: In
values:
- "vm-passthrough"
env:
- name: TZ
value: "Asia/Shanghai"
servingEngineSpec:
runtimeClassName: "nvidia"
imagePullPolicy: "IfNotPresent"
extraVolumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: "30Gi"
extraVolumeMounts:
- name: dshm
mountPath: /dev/shm
modelSpec:
- name: "glm47-flash"
repository: "12205599/vllm-glm47"
tag: "fixed"
modelURL: "ZhipuAI/GLM-4.7-Flash"
replicaCount: 1
requestCPU: 16
requestMemory: "150Gi"
requestGPU: 4
shmSize: "30Gi"
pvcStorage: "120Gi"
pvcAccessMode: ["ReadWriteMany"]
storageClass: "csi-cephfs-models-sc" # 自动创建pvc
pvcAnnotations:
helm.sh/resource-policy: "keep" # helm uninstall 之后不要删除pvc
vllmConfig:
tensorParallelSize: 4 # 不要使用6卡
maxModelLen: 120000
extraArgs:
- "--gpu-memory-utilization"
- "0.90"
- "--tool-call-parser"
- "glm45"
- "--reasoning-parser"
- "glm45"
- "--enable-auto-tool-choice"
env:
- name: VLLM_USE_MODELSCOPE
value: "true"
- name: HF_ENDPOINT
value: "https://hf-mirror.com"# 当必须联网时 使用hf国内镜像站点
- name: NCCL_DEBUG
value: "INFO"
- name: NCCL_P2P_DISABLE
value: "1"
- name: NCCL_IB_DISABLE
value: "1"
- name: NCCL_SHM_DISABLE
value: "0"
- name: PYTORCH_ALLOC_CONF
value: "expandable_segments:True"
- name: NCCL_CUDA_MEM_MANAGE
value: "0"
- name: NCCL_CUMEM_HOST_ENABLE
value: "0"
- name: TZ
value: "Asia/Shanghai"
- name: MODELSCOPE_CACHE # 告诉vLLM 把模型下载到pod内的value路径
value: "/data/modelscope"
startupProbe:
initialDelaySeconds: 1800 # 第一次等待30min再探测
periodSeconds: 15
failureThreshold: 60
timeoutSeconds: 10
httpGet:
path: /health
port: 8000
- 镜像尽量使用
IfNotPresent拉取策略,因为这些镜像实在太大了。 - 为拉取模型权重文件,启动探针可以先设置为较大的时间 30 * 60=1800,后面可使用
upgrade更改为合适的探针时间。 - 设置环境变量:VLLM_USE_MODELSCOPE: true, HF_ENDPOINT:"https://hf-mirror.com" 从国内的模搭社区下载文件,验证时使用
huggingface.com镜像站hf-mirror.com。
多个pod可共享加载同一个模型文件, 模型使用共享文件存储。
pvcStorage: "120Gi"
pvcAccessMode: ["ReadWriteMany"]
storageClass: "csi-cephfs-models-sc" # 自动创建pvc
这个配置会自动产生pvc,产生的pvc会默认挂载pod内/data目录,这个信息要与环境变量MODELSCOPE_CACHE匹配(这个变量指示vllm将模型文件下载到pod内目录)。
helm install glm4.7-flash vllm/vllm-satck -f glm4.7-flash.yaml -n vllm-product-stack

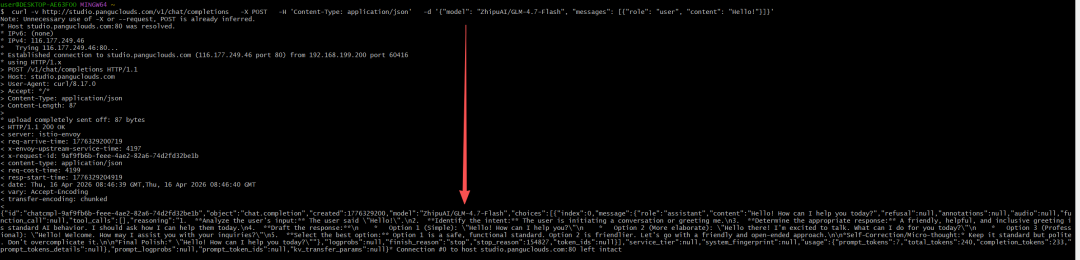
添加到higress网关之后,兼容openai的api如下:
curl -v http://studio.panguclouds.com/v1/chat/completions -X POST -H 'Content-Type: application/json' -d '{"model": "ZhipuAI/GLM-4.7-Flash", "messages": [{"role": "user", "content": "Hello!"}]}'
4. 总结
gpu在整个AI生态占据了黄金生态位, 目前算力市场一卡难求, token coding plan价格也是水涨船高。
作为AI基础设施团队的目标是不断压榨gpu, 高质量高效地产出token。
本文概述了vllm 这一流行推理框架的原理, 核心是批处理用户请求(对有相同词元字符串部分建立KV Cache快捷方式);
社区引入的LMCache进一步将昂贵的KVCache显存卸载到内存或其他存储, 目的是提高显存使用率,优化吞吐量和首字延迟。
二者结合就是 vllm production-stack的实践。
参考资料
[1]
gpu operator: https://docs.nvda.net.cn/datacenter/cloud-native/gpu-operator/latest/overview.html
[2]
gpu operator还支持配置虚拟机gpu加速、管理vgpu设备: https://docs.nvda.net.cn/datacenter/cloud-native/gpu-operator/latest/gpu-operator-kubevirt.html
[3]
vllm: https://docs.vllm.ai/en/stable/
[4]
vLLM: https://www.redhat.com/zh-cn/topics/ai/what-is-vllm
[5]
LMCache: https://github.com/LMCache/LMCache
[6]
KV Cache感知路由: https://github.com/vllm-project/production-stack/blob/main/tutorials/17-kv-aware-routing.md
[7]
KVCache卸载: https://github.com/vllm-project/production-stack/blob/main/tutorials/05-offload-kv-cache.md
[8]
lmcache-vllm: https://hub.docker.com/r/lmcache/vllm-openai/tags
[9]
glm4.7-flash: https://modelscope.cn/models/ZhipuAI/GLM-4.7-Flash
本文文字原创,搁笔常恐意味尽,愿闻读者金玉声, ”永久更新“地址见原文。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号