140:产品反馈闭环与迭代:持续优化Agentic产品

140:产品反馈闭环与迭代:持续优化Agentic产品

安全风信子
发布于 2026-04-20 08:11:46
发布于 2026-04-20 08:11:46
作者: HOS(安全风信子) 日期: 2026-03-26 主要来源平台: GitHub 摘要: 本文深入探讨产品反馈闭环与迭代,通过详细案例展示如何持续优化Agentic产品。我们将分析反馈收集方法、迭代优化流程、数据驱动决策以及最佳实践,为AI产品经理和运营专家提供一套完整的产品迭代指南。
目录- 1. 核心技术价值
- 2. 反馈闭环概述
- 2.1 反馈闭环的定义与价值
- 2.2 反馈闭环的核心环节
- 2.3 反馈闭环流程图
- 3. 反馈收集方法
- 3.1 主动反馈收集
- 3.1.1 用户调研
- 3.1.2 用户访谈
- 3.2 被动反馈收集
- 3.2.1 行为数据分析
- 3.2.2 客服反馈分析
- 3.3 自动反馈收集
- 3.3.1 埋点数据收集
- 4. 反馈分析方法
- 4.1 定量分析
- 4.1.1 统计分析
- 4.1.2 情感分析
- 4.2 定性分析
- 4.2.1 主题分析
- 5. 迭代优化流程
- 5.1 迭代规划
- 5.1.1 优先级排序
- 5.1.2 迭代计划制定
- 5.2 迭代执行
- 5.2.1 敏捷开发
- 5.3 效果验证
- 5.3.1 A/B测试验证
- 6. 实战案例
- 6.1 案例一:AI写作工具反馈闭环
- 6.2 案例二:AI客服系统反馈闭环
- 7. 最佳实践
- 7.1 反馈收集最佳实践
- 7.2 迭代优化最佳实践
- 7.3 团队协作最佳实践
- 8. 未来发展趋势
- 8.1 技术趋势
- 8.2 流程趋势
- 8.3 组织趋势
- 反馈闭环检查清单
- 反馈闭环指标仪表盘
- 2.1 反馈闭环的定义与价值
- 2.2 反馈闭环的核心环节
- 2.3 反馈闭环流程图
- 3.1 主动反馈收集
- 3.1.1 用户调研
- 3.1.2 用户访谈
- 3.2 被动反馈收集
- 3.2.1 行为数据分析
- 3.2.2 客服反馈分析
- 3.3 自动反馈收集
- 3.3.1 埋点数据收集
- 4.1 定量分析
- 4.1.1 统计分析
- 4.1.2 情感分析
- 4.2 定性分析
- 4.2.1 主题分析
- 5.1 迭代规划
- 5.1.1 优先级排序
- 5.1.2 迭代计划制定
- 5.2 迭代执行
- 5.2.1 敏捷开发
- 5.3 效果验证
- 5.3.1 A/B测试验证
- 6.1 案例一:AI写作工具反馈闭环
- 6.2 案例二:AI客服系统反馈闭环
- 7.1 反馈收集最佳实践
- 7.2 迭代优化最佳实践
- 7.3 团队协作最佳实践
- 8.1 技术趋势
- 8.2 流程趋势
- 8.3 组织趋势
- 反馈闭环检查清单
- 反馈闭环指标仪表盘
1. 核心技术价值
本节为你提供的核心技术价值:掌握产品反馈闭环与迭代的核心方法,建立持续优化机制,实现产品的长期成功和用户满意度的持续提升。
2. 反馈闭环概述
2.1 反馈闭环的定义与价值
反馈闭环是指收集用户反馈、分析反馈、采取行动、验证效果的循环过程。反馈闭环的价值包括:
- 产品改进:基于真实用户反馈改进产品
- 用户满意:提高用户满意度
- 问题发现:及时发现和解决问题
- 创新驱动:驱动产品创新
- 竞争优势:建立竞争优势
2.2 反馈闭环的核心环节
环节 | 描述 | 关键活动 |
|---|---|---|
收集 | 收集用户反馈 | 多渠道收集 |
分析 | 分析反馈数据 | 数据分析 |
决策 | 制定改进决策 | 优先级排序 |
执行 | 执行改进措施 | 快速迭代 |
验证 | 验证改进效果 | 效果评估 |
2.3 反馈闭环流程图
反馈闭环流程:
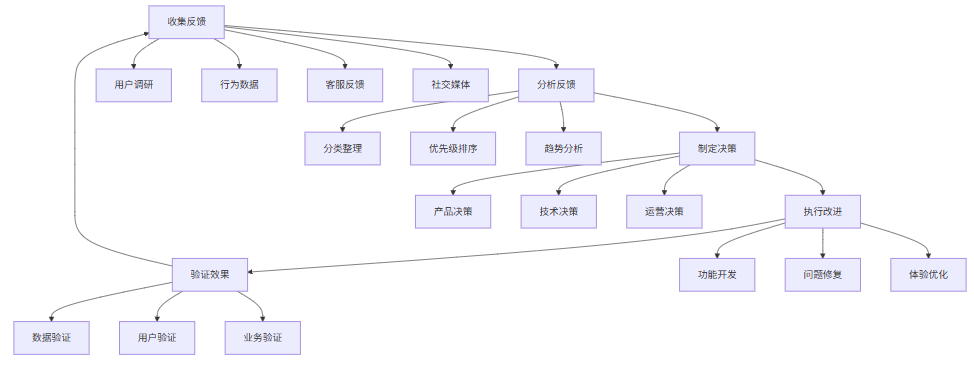
3. 反馈收集方法
3.1 主动反馈收集
3.1.1 用户调研
主动进行用户调研收集反馈。
用户调研框架:
class UserSurveyManager:
def __init__(self):
self.survey_types = {
"nps": self.create_nps_survey,
"csat": self.create_csat_survey,
"feature_feedback": self.create_feature_survey,
"general_feedback": self.create_general_survey
}
def create_survey(self, survey_type, target_users):
"""
创建调研
"""
if survey_type in self.survey_types:
return self.survey_types[survey_type](target_users)
else:
return self.create_general_survey(target_users)
def create_nps_survey(self, target_users):
"""
创建NPS调研
"""
return {
"type": "nps",
"question": "您有多大可能向朋友推荐我们的产品?",
"scale": "0-10",
"follow_up": "请告诉我们您给出这个分数的原因",
"target_users": target_users,
"created_at": datetime.now()
}
def create_csat_survey(self, target_users):
"""
创建CSAT调研
"""
return {
"type": "csat",
"question": "您对产品的整体满意度如何?",
"scale": "1-5",
"follow_up": "请告诉我们您的具体感受",
"target_users": target_users,
"created_at": datetime.now()
}
def create_feature_survey(self, target_users):
"""
创建功能调研
"""
return {
"type": "feature_feedback",
"questions": [
"您最常使用哪些功能?",
"哪些功能对您最有价值?",
"您希望我们添加哪些新功能?",
"哪些功能使用起来有困难?"
],
"target_users": target_users,
"created_at": datetime.now()
}
def distribute_survey(self, survey, distribution_channels):
"""
分发调研
"""
distribution_results = {}
for channel in distribution_channels:
if channel == "email":
distribution_results[channel] = self.send_email_survey(survey)
elif channel == "in_app":
distribution_results[channel] = self.show_in_app_survey(survey)
elif channel == "push":
distribution_results[channel] = self.send_push_survey(survey)
return distribution_results
def collect_responses(self, survey_id):
"""
收集响应
"""
responses = self.get_survey_responses(survey_id)
return {
"total_responses": len(responses),
"completion_rate": self.calculate_completion_rate(responses),
"responses": responses
}3.1.2 用户访谈
进行深度用户访谈收集反馈。
用户访谈框架:
class UserInterviewManager:
def __init__(self):
self.interview_types = {
"exploratory": self.conduct_exploratory_interview,
"validation": self.conduct_validation_interview,
"feedback": self.conduct_feedback_interview
}
def schedule_interview(self, user_id, interview_type):
"""
安排访谈
"""
return {
"user_id": user_id,
"type": interview_type,
"scheduled_time": self.find_available_slot(user_id),
"interviewer": self.assign_interviewer(),
"questions": self.prepare_questions(interview_type)
}
def conduct_interview(self, interview):
"""
进行访谈
"""
# 记录访谈内容
transcript = self.record_interview(interview)
# 分析访谈内容
analysis = self.analyze_interview(transcript)
return {
"transcript": transcript,
"analysis": analysis,
"key_insights": self.extract_key_insights(analysis),
"action_items": self.generate_action_items(analysis)
}
def prepare_questions(self, interview_type):
"""
准备访谈问题
"""
question_sets = {
"exploratory": [
"请描述您使用产品的典型场景",
"您在使用产品时遇到的最大挑战是什么?",
"您希望通过产品实现什么目标?",
"您目前如何解决这个问题?"
],
"validation": [
"这个功能对您有帮助吗?",
"您会如何使用这个功能?",
"这个功能还缺少什么?",
"您愿意为这个功能付费吗?"
],
"feedback": [
"您对产品的整体感受如何?",
"哪些方面做得好?",
"哪些方面需要改进?",
"您有什么建议?"
]
}
return question_sets.get(interview_type, [])3.2 被动反馈收集
3.2.1 行为数据分析
分析用户行为数据获取反馈。
行为数据分析框架:
class BehaviorDataAnalyzer:
def __init__(self):
self.analysis_types = {
"usage_pattern": self.analyze_usage_pattern,
"feature_adoption": self.analyze_feature_adoption,
"user_flow": self.analyze_user_flow,
"churn_prediction": self.predict_churn
}
def analyze_behavior(self, user_data, analysis_type):
"""
分析用户行为
"""
if analysis_type in self.analysis_types:
return self.analysis_types[analysis_type](user_data)
else:
return self.analyze_usage_pattern(user_data)
def analyze_usage_pattern(self, user_data):
"""
分析使用模式
"""
return {
"frequency": self.calculate_usage_frequency(user_data),
"duration": self.calculate_session_duration(user_data),
"features_used": self.identify_used_features(user_data),
"time_of_day": self.analyze_usage_time(user_data),
"device_type": self.analyze_device_usage(user_data)
}
def analyze_feature_adoption(self, user_data):
"""
分析功能采用
"""
features = self.get_all_features()
adoption_data = {}
for feature in features:
adoption_data[feature] = {
"users_used": self.count_feature_users(user_data, feature),
"usage_frequency": self.calculate_feature_frequency(user_data, feature),
"satisfaction": self.measure_feature_satisfaction(user_data, feature)
}
return adoption_data
def analyze_user_flow(self, user_data):
"""
分析用户流程
"""
return {
"common_paths": self.identify_common_paths(user_data),
"drop_off_points": self.identify_drop_off_points(user_data),
"conversion_funnel": self.build_conversion_funnel(user_data),
"optimization_opportunities": self.identify_optimization_opportunities(user_data)
}
def predict_churn(self, user_data):
"""
预测流失
"""
churn_indicators = {
"usage_decline": self.detect_usage_decline(user_data),
"engagement_drop": self.detect_engagement_drop(user_data),
"support_tickets": self.analyze_support_tickets(user_data),
"feature_abandonment": self.detect_feature_abandonment(user_data)
}
churn_score = self.calculate_churn_score(churn_indicators)
return {
"churn_score": churn_score,
"risk_level": self.categorize_risk_level(churn_score),
"indicators": churn_indicators,
"recommended_actions": self.recommend_retention_actions(churn_indicators)
}3.2.2 客服反馈分析
分析客服数据获取反馈。
客服反馈分析框架:
class SupportFeedbackAnalyzer:
def __init__(self):
self.feedback_categories = {
"bug_report": self.categorize_bug_report,
"feature_request": self.categorize_feature_request,
"usability_issue": self.categorize_usability_issue,
"general_feedback": self.categorize_general_feedback
}
def analyze_support_tickets(self, tickets):
"""
分析客服工单
"""
analysis = {
"total_tickets": len(tickets),
"categories": {},
"trends": {},
"priority_issues": []
}
# 分类工单
for ticket in tickets:
category = self.categorize_ticket(ticket)
if category not in analysis["categories"]:
analysis["categories"][category] = []
analysis["categories"][category].append(ticket)
# 分析趋势
analysis["trends"] = self.analyze_trends(analysis["categories"])
# 识别优先问题
analysis["priority_issues"] = self.identify_priority_issues(analysis["categories"])
return analysis
def categorize_ticket(self, ticket):
"""
分类工单
"""
# 使用NLP分类
ticket_text = ticket["subject"] + " " + ticket["description"]
for category, categorizer in self.feedback_categories.items():
if categorizer(ticket_text):
return category
return "general_feedback"
def categorize_bug_report(self, text):
"""
分类Bug报告
"""
bug_keywords = ["bug", "error", "crash", "not working", "broken", "issue"]
return any(keyword in text.lower() for keyword in bug_keywords)
def categorize_feature_request(self, text):
"""
分类功能请求
"""
feature_keywords = ["wish", "want", "need", "would be great", "feature", "add"]
return any(keyword in text.lower() for keyword in feature_keywords)
def categorize_usability_issue(self, text):
"""
分类可用性问题
"""
usability_keywords = ["confusing", "difficult", "hard to use", "unclear", "complicated"]
return any(keyword in text.lower() for keyword in usability_keywords)
def identify_priority_issues(self, categories):
"""
识别优先问题
"""
priority_issues = []
# 基于频率和影响排序
for category, tickets in categories.items():
if len(tickets) > 10: # 频繁出现的问题
priority_issues.append({
"category": category,
"count": len(tickets),
"priority": "high",
"sample_tickets": tickets[:5]
})
return sorted(priority_issues, key=lambda x: x["count"], reverse=True)3.3 自动反馈收集
3.3.1 埋点数据收集
通过埋点自动收集用户行为数据。
埋点数据收集框架:
class TrackingDataManager:
def __init__(self):
self.tracking_events = {}
self.event_properties = {}
def track_event(self, event_name, properties=None):
"""
追踪事件
"""
event_data = {
"event_name": event_name,
"timestamp": datetime.now(),
"properties": properties or {},
"user_id": self.get_current_user_id(),
"session_id": self.get_session_id()
}
# 发送到分析平台
self.send_to_analytics(event_data)
# 存储到本地
if event_name not in self.tracking_events:
self.tracking_events[event_name] = []
self.tracking_events[event_name].append(event_data)
def track_page_view(self, page_name):
"""
追踪页面浏览
"""
self.track_event("page_view", {"page": page_name})
def track_feature_usage(self, feature_name, action):
"""
追踪功能使用
"""
self.track_event("feature_usage", {
"feature": feature_name,
"action": action
})
def track_user_action(self, action_name, details=None):
"""
追踪用户行为
"""
self.track_event("user_action", {
"action": action_name,
"details": details or {}
})
def track_error(self, error_type, error_message, context=None):
"""
追踪错误
"""
self.track_event("error", {
"error_type": error_type,
"error_message": error_message,
"context": context or {}
})4. 反馈分析方法
4.1 定量分析
4.1.1 统计分析
对反馈数据进行统计分析。
统计分析框架:
class FeedbackStatisticsAnalyzer:
def __init__(self):
self.statistical_methods = {
"descriptive": self.descriptive_statistics,
"comparative": self.comparative_statistics,
"trend": self.trend_analysis,
"correlation": self.correlation_analysis
}
def analyze_statistics(self, feedback_data, method="descriptive"):
"""
分析统计数据
"""
if method in self.statistical_methods:
return self.statistical_methods[method](feedback_data)
else:
return self.descriptive_statistics(feedback_data)
def descriptive_statistics(self, data):
"""
描述性统计
"""
import numpy as np
return {
"count": len(data),
"mean": np.mean(data),
"median": np.median(data),
"std": np.std(data),
"min": np.min(data),
"max": np.max(data),
"quartiles": np.percentile(data, [25, 50, 75])
}
def comparative_statistics(self, data):
"""
比较统计
"""
# 比较不同群体的反馈
segments = self.segment_data(data)
comparison = {}
for segment_name, segment_data in segments.items():
comparison[segment_name] = self.descriptive_statistics(segment_data)
return comparison
def trend_analysis(self, data):
"""
趋势分析
"""
# 分析反馈趋势
time_series = self.group_by_time(data)
trends = {
"overall_trend": self.calculate_overall_trend(time_series),
"seasonality": self.detect_seasonality(time_series),
"change_points": self.detect_change_points(time_series)
}
return trends
def correlation_analysis(self, data):
"""
相关性分析
"""
# 分析反馈之间的相关性
correlation_matrix = self.calculate_correlation_matrix(data)
return {
"correlation_matrix": correlation_matrix,
"strong_correlations": self.identify_strong_correlations(correlation_matrix),
"insights": self.generate_correlation_insights(correlation_matrix)
}4.1.2 情感分析
分析用户反馈的情感倾向。
情感分析框架:
class SentimentAnalyzer:
def __init__(self):
self.sentiment_model = self.load_sentiment_model()
def analyze_sentiment(self, text):
"""
分析情感
"""
# 使用NLP模型分析情感
sentiment_score = self.sentiment_model.predict(text)
return {
"score": sentiment_score,
"label": self.categorize_sentiment(sentiment_score),
"confidence": self.calculate_confidence(sentiment_score)
}
def categorize_sentiment(self, score):
"""
分类情感
"""
if score > 0.6:
return "positive"
elif score < 0.4:
return "negative"
else:
return "neutral"
def batch_analyze(self, texts):
"""
批量分析
"""
results = []
for text in texts:
results.append(self.analyze_sentiment(text))
return {
"results": results,
"summary": self.summarize_sentiments(results)
}
def summarize_sentiments(self, results):
"""
汇总情感分析结果
"""
total = len(results)
positive = sum(1 for r in results if r["label"] == "positive")
negative = sum(1 for r in results if r["label"] == "negative")
neutral = sum(1 for r in results if r["label"] == "neutral")
return {
"total": total,
"positive": positive,
"negative": negative,
"neutral": neutral,
"positive_ratio": positive / total if total > 0 else 0,
"negative_ratio": negative / total if total > 0 else 0
}4.2 定性分析
4.2.1 主题分析
分析反馈的主题和关键词。
主题分析框架:
class TopicAnalyzer:
def __init__(self):
self.topic_model = self.load_topic_model()
def extract_topics(self, texts):
"""
提取主题
"""
# 使用主题模型提取主题
topics = self.topic_model.fit_transform(texts)
return {
"topics": self.format_topics(topics),
"keywords": self.extract_keywords(texts),
"topic_distribution": self.calculate_topic_distribution(topics)
}
def extract_keywords(self, texts):
"""
提取关键词
"""
# 使用TF-IDF或类似方法提取关键词
keywords = []
for text in texts:
text_keywords = self.extract_text_keywords(text)
keywords.extend(text_keywords)
return self.aggregate_keywords(keywords)
def categorize_feedback(self, texts):
"""
分类反馈
"""
categories = {
"product_quality": [],
"user_experience": [],
"feature_request": [],
"bug_report": [],
"pricing": [],
"support": []
}
for text in texts:
category = self.classify_feedback(text)
categories[category].append(text)
return categories5. 迭代优化流程
5.1 迭代规划
5.1.1 优先级排序
对反馈进行优先级排序。
优先级排序框架:
class PriorityRanker:
def __init__(self):
self.priority_factors = {
"impact": 0.4,
"frequency": 0.3,
"effort": 0.2,
"strategic": 0.1
}
def rank_feedback(self, feedback_items):
"""
排序反馈
"""
ranked_items = []
for item in feedback_items:
score = self.calculate_priority_score(item)
ranked_items.append({
"item": item,
"score": score,
"priority": self.categorize_priority(score)
})
return sorted(ranked_items, key=lambda x: x["score"], reverse=True)
def calculate_priority_score(self, item):
"""
计算优先级得分
"""
impact_score = self.assess_impact(item)
frequency_score = self.assess_frequency(item)
effort_score = self.assess_effort(item)
strategic_score = self.assess_strategic_value(item)
total_score = (
impact_score * self.priority_factors["impact"] +
frequency_score * self.priority_factors["frequency"] +
(1 - effort_score) * self.priority_factors["effort"] +
strategic_score * self.priority_factors["strategic"]
)
return total_score
def assess_impact(self, item):
"""
评估影响
"""
# 基于用户数量、业务影响等评估
return min(item.get("affected_users", 0) / 1000, 1.0)
def assess_frequency(self, item):
"""
评估频率
"""
# 基于反馈出现频率评估
return min(item.get("frequency", 0) / 100, 1.0)
def assess_effort(self, item):
"""
评估工作量
"""
# 基于实现难度评估
effort_levels = {"low": 0.2, "medium": 0.5, "high": 0.8}
return effort_levels.get(item.get("effort", "medium"), 0.5)
def assess_strategic_value(self, item):
"""
评估战略价值
"""
# 基于产品战略评估
return item.get("strategic_value", 0.5)
def categorize_priority(self, score):
"""
分类优先级
"""
if score >= 0.7:
return "P0"
elif score >= 0.5:
return "P1"
elif score >= 0.3:
return "P2"
else:
return "P3"5.1.2 迭代计划制定
制定迭代计划。
迭代计划框架:
class IterationPlanner:
def __init__(self):
self.iteration_length = 14 # 2周
self.capacity = 40 # 每迭代40个故事点
def plan_iteration(self, ranked_feedback, team_capacity):
"""
规划迭代
"""
iteration_plan = {
"items": [],
"total_points": 0,
"capacity": team_capacity,
"remaining_capacity": team_capacity
}
for item in ranked_feedback:
item_points = self.estimate_story_points(item)
if iteration_plan["remaining_capacity"] >= item_points:
iteration_plan["items"].append(item)
iteration_plan["total_points"] += item_points
iteration_plan["remaining_capacity"] -= item_points
return iteration_plan
def estimate_story_points(self, item):
"""
估算故事点
"""
# 基于复杂度估算
complexity = item.get("complexity", "medium")
points_map = {"low": 1, "medium": 3, "high": 5, "very_high": 8}
return points_map.get(complexity, 3)5.2 迭代执行
5.2.1 敏捷开发
采用敏捷开发方法执行迭代。
敏捷开发框架:
class AgileDevelopmentManager:
def __init__(self):
self.sprint_length = 14
self.current_sprint = None
def start_sprint(self, sprint_plan):
"""
开始冲刺
"""
self.current_sprint = {
"id": self.generate_sprint_id(),
"start_date": datetime.now(),
"end_date": datetime.now() + timedelta(days=self.sprint_length),
"plan": sprint_plan,
"status": "in_progress",
"daily_standups": []
}
def conduct_daily_standup(self, updates):
"""
进行每日站会
"""
standup = {
"date": datetime.now(),
"updates": updates,
"blockers": self.identify_blockers(updates)
}
self.current_sprint["daily_standups"].append(standup)
return standup
def complete_sprint(self):
"""
完成冲刺
"""
self.current_sprint["status"] = "completed"
self.current_sprint["completion_date"] = datetime.now()
# 计算完成率
completed_items = [item for item in self.current_sprint["plan"]["items"] if item.get("completed")]
self.current_sprint["completion_rate"] = len(completed_items) / len(self.current_sprint["plan"]["items"])
return self.current_sprint5.3 效果验证
5.3.1 A/B测试验证
通过A/B测试验证改进效果。
效果验证框架:
class ImprovementValidator:
def __init__(self):
self.test_framework = ABTestFramework()
def validate_improvement(self, improvement, metrics):
"""
验证改进效果
"""
# 设计A/B测试
test_design = self.design_validation_test(improvement, metrics)
# 执行测试
test_results = self.test_framework.run_test(test_design)
# 分析结果
analysis = self.analyze_test_results(test_results)
return {
"improvement": improvement,
"test_design": test_design,
"results": test_results,
"analysis": analysis,
"recommendation": self.generate_recommendation(analysis)
}
def design_validation_test(self, improvement, metrics):
"""
设计验证测试
"""
return {
"name": f"validation_{improvement['id']}",
"hypothesis": improvement["expected_impact"],
"metrics": metrics,
"sample_size": self.calculate_sample_size(metrics),
"duration": 14
}
def analyze_test_results(self, results):
"""
分析测试结果
"""
return {
"statistical_significance": self.check_significance(results),
"effect_size": self.calculate_effect_size(results),
"confidence_interval": self.calculate_confidence_interval(results),
"practical_significance": self.check_practical_significance(results)
}6. 实战案例
6.1 案例一:AI写作工具反馈闭环
背景: 某AI写作工具建立反馈闭环机制。
实施方案:
- 反馈收集:多渠道收集用户反馈
- 分析处理:自动分类和优先级排序
- 迭代优化:2周迭代周期
- 效果验证:A/B测试验证
效果:
- 用户满意度:从70%提升到90%
- 问题解决率:从60%提升到85%
- 功能采用率:提升40%
- 用户留存率:提升25%
6.2 案例二:AI客服系统反馈闭环
背景: 某AI客服系统建立持续优化机制。
实施方案:
- 实时监控:监控客服质量指标
- 用户反馈:收集用户满意度评价
- 问题分析:分析常见问题模式
- 模型优化:持续优化AI模型
效果:
- 问题解决率:从75%提升到92%
- 用户满意度:从65%提升到88%
- 平均响应时间:从30秒降低到10秒
- 人工转接率:从40%降低到15%
7. 最佳实践
7.1 反馈收集最佳实践
- 多渠道收集:使用多种渠道收集反馈
- 持续收集:持续收集用户反馈
- 分类整理:及时分类整理反馈
- 用户激励:激励用户提供反馈
- 隐私保护:保护用户隐私
7.2 迭代优化最佳实践
- 快速迭代:快速迭代验证想法
- 数据驱动:基于数据做决策
- 用户中心:以用户需求为中心
- 持续改进:持续改进产品
- 效果验证:验证改进效果
7.3 团队协作最佳实践
- 跨职能协作:产品、技术、运营协作
- 透明沟通:透明的沟通机制
- 知识共享:共享反馈和经验
- 持续学习:持续学习和改进
- 用户导向:以用户为导向
8. 未来发展趋势
8.1 技术趋势
- AI驱动分析:AI驱动的反馈分析
- 实时反馈:实时反馈收集和处理
- 预测性分析:预测用户需求和问题
- 自动化优化:自动化产品优化
- 个性化反馈:个性化反馈收集
8.2 流程趋势
- 持续反馈:持续反馈机制
- 快速迭代:更快的迭代速度
- 自动化验证:自动化效果验证
- 智能优先级:智能优先级排序
- 协同优化:协同优化流程
8.3 组织趋势
- 用户中心文化:用户中心的企业文化
- 数据驱动决策:数据驱动的决策机制
- 敏捷组织:敏捷的组织结构
- 持续学习:持续学习的组织
- 开放创新:开放的创新机制
参考链接:
- 主要来源:Product Feedback Loop - 产品反馈闭环
- 辅助:Continuous Improvement - 持续改进
- 辅助:Agile Product Development - 敏捷产品开发
附录(Appendix):
反馈闭环检查清单
- 反馈渠道建立完成
- 反馈收集机制建立
- 分析流程设计完成
- 优先级排序规则制定
- 迭代计划流程建立
- 效果验证机制建立
- 团队协作流程建立
- 持续改进机制建立
反馈闭环指标仪表盘
指标 | 当前值 | 目标值 | 趋势 |
|---|---|---|---|
反馈收集量 | 1000/月 | 2000/月 | ↑ |
反馈处理率 | 80% | 95% | ↑ |
问题解决率 | 70% | 90% | ↑ |
用户满意度 | 75% | 90% | ↑ |
迭代周期 | 3周 | 2周 | ↓ |
关键词: 反馈闭环, 产品迭代, 持续优化, 用户反馈, 数据驱动, 敏捷开发, 效果验证

在这里插入图片描述

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号