代码实战:手把手教你用Python构建蛋白质互作预测模型

代码实战:手把手教你用Python构建蛋白质互作预测模型

Tom2Code
发布于 2026-04-17 17:26:15
发布于 2026-04-17 17:26:15
一.Background
想象一下,在我们身体内部,数以万计的蛋白质分子正在进行着一场永不停歇的"社交派对"。它们相互识别、结合、分离,形成了维持生命活动的复杂网络。这些蛋白质之间的相互作用(Protein-Protein Interactions, PPI)不仅决定了细胞的基本功能,更是药物发现和疾病治疗的关键靶点。
然而,传统的实验方法识别蛋白质相互作用既昂贵又耗时。以酵母双杂交系统为例,验证一对蛋白质是否相互作用可能需要数周时间,而人体内约有20,000个蛋白质,理论上可能的相互作用对数高达2亿!这意味着仅靠实验手段,我们可能需要数千年才能绘制完整的人类蛋白质相互作用图谱。
这就是为什么AI驱动的药物发现(AIDD)如此重要的原因。
近年来,随着AlphaFold解决蛋白质结构预测问题,以及ChatGPT展现的语言模型威力,生物信息学正经历着一场前所未有的革命。特别是蛋白质语言模型(如ESM、ProtT5)的出现,让我们能够像理解自然语言一样理解蛋白质序列,从而以前所未有的精度预测蛋白质间的相互作用。
一些数据:
- 📊 传统实验方法的PPI检测准确率约为70-80%
- 🚀 最新深度学习模型在标准数据集上可达到95%+的准确率
- ⏱️ 计算预测时间从数周缩短至数秒
- 💰 单次预测成本从数千美元降至几乎为零
为什么选择蛋白质相互作用预测?
在药物发现的漫长旅程中,准确识别蛋白质相互作用是至关重要的第一步。90%的疾病都与蛋白质功能异常相关,而蛋白质很少单独发挥作用——它们通过复杂的相互作用网络协同工作。癌症、阿尔茨海默病、新冠病毒感染等疾病的治疗,本质上都是在干预特定的蛋白质相互作用。
今天,我将带你从零开始,用Python代码构建一个现代化的蛋白质相互作用预测模型。我们将使用最前沿的ESM蛋白质语言模型、对偶网络(Siamese Network)架构。
首先介绍一下我们的数据集来源:
来自论文:
这是一篇来自兰州大学的论文:
《SCMPPI: Supervised Contrastive Multimodal
Framework for Predicting Protein-Protein Interactions》

这篇论文提出了一种名为 SCMPPI(Supervised Contrastive Multimodal Framework for Predicting Protein-Protein Interactions) 的新型监督对比多模态框架,旨在解决蛋白质-蛋白质相互作用(PPI)预测中传统实验方法耗时且昂贵、现有计算模型在跨模态特征融合、鲁棒性和假阴性抑制方面面临挑战的问题。
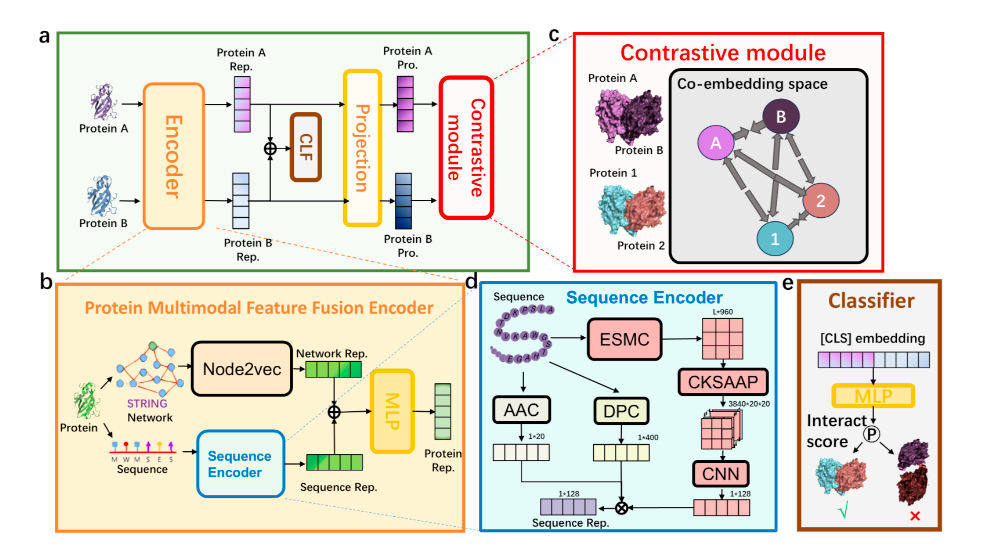
SCMPPI的论文结构图
这篇论文很有意思,其中提出了多种蛋白质序列的特征提取方式,其中包括不限于:
1.AAC, amino acid composition,氨基酸位置频次向量。
2.DPC,dipeptide composition,二肽组成性向量。
3.cksaap,k-gap amino acid pairs,k-间隔氨基酸对。
4.cksaap-esmC,k-gap amino acid pairs with ESMC,用esmc提取特征向量后的k-间隔氨基酸对。
这些编码技巧,如果有时间,我们会在下一次文章中进行讲解,这次我们
将使用这篇文章中的部分数据集进行一个简单的ppi分类任务的实现。这篇文章主包
已经复现成功了。
二.数据集说明
本次我们使用论文中的Human ppi数据集,来自于:

来看一下数据集的格式,一共有三个文件:
其中pairs_neg.csv 和pairs_pos.csv 格式一样,分别存放了阳性数据和阴性数据,其中的序列来自于uniprotein.csv,
pairs_neg.csv 长这个样子,共4263对阴性数据:
阳性数据共3900条。
uniprotein.csv长这个样子:
共2835条序列。
其中pairs_neg.csv村发生过的是没有相互作用的两个蛋白质序列的编号a和编号b;
pairs_pos.csv分别存放的是存在相互作用的两个蛋白质序列的编号a和编号b。
这些编号对应着uniprotein.csv中的序列。
三.模型设计
总体思路:
蛋白质序列A → ESMC编码 → 特征提取 ↘
交互特征融合 → 分类决策
蛋白质序列B → ESMC编码 → 特征提取 ↗
为什么使用ESMC编码,是因为:
- ESMC模型经过数百万蛋白质序列训练,已经"学会"了氨基酸的上下文关系ESM3蛋白质语言模型cookbook(3)
- 我们使用全局平均池化而非简单的CLS token,保留了整个序列的语义信息
- 这相当于让AI"阅读理解"蛋白质的"语言",而不是死记硬背序列
其次,我们使用了对偶网络(Siamese)的参数共享策略,因为蛋白质A和B在相互作用中地位平等,不应该用不同的"标准"衡量。所以我们选择了共享权重。对称性保证:predict(A,B) = predict(B,A),符合物理直觉。
最后,在我们的模型设计中,我们还使用了focalloss,因为主包最近在研究这个损失函数,大家也可以换成其他的进行测试。
因为主包现在的服务器还没空闲,所以就租了一个服务器进行测试,大家可以多跑几个epoch,进行测试。
先给大家看一眼结果:
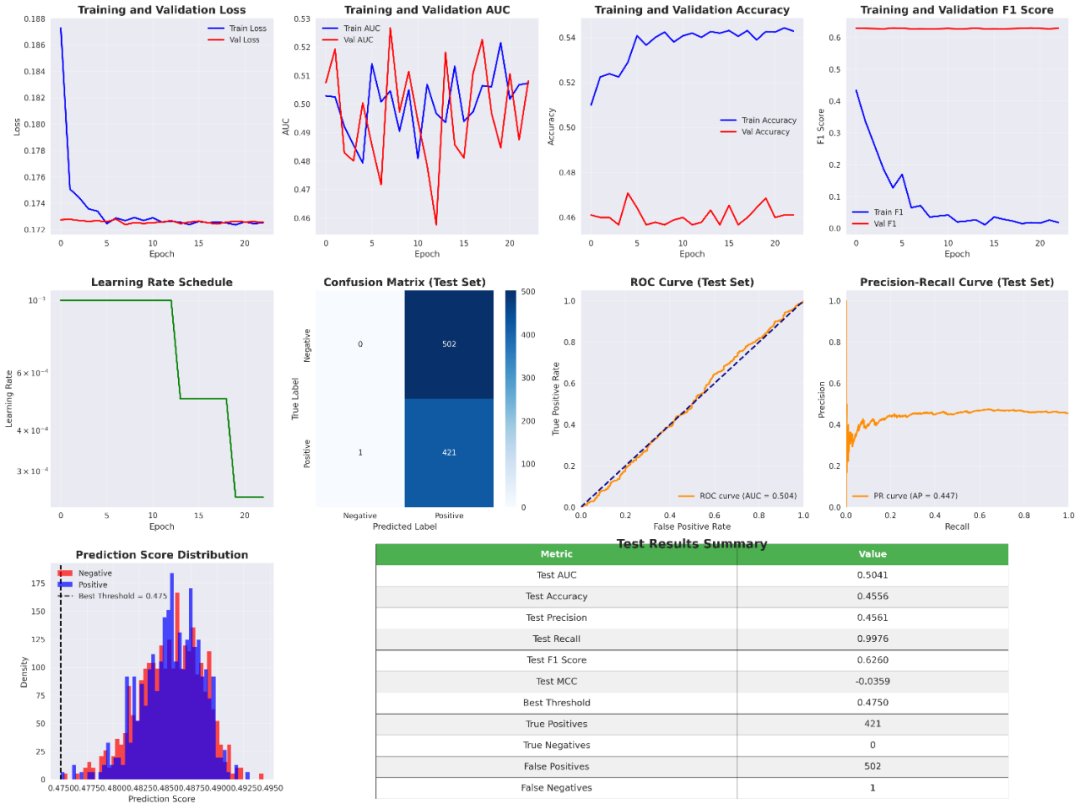
以及训练过程:

四.模型代码
上干货,主要是模型代码,项目代码太多,为了读者体验,就截取了部分代码进行展示:
class SiameseNetwork(nn.Module):
"""增强的对偶网络架构"""
def __init__(self, input_dim=640, hidden_dims=[512, 256, 128],
dropout_rate=0.3, use_batch_norm=True):
super(SiameseNetwork, self).__init__()
self.input_dim = input_dim
self.hidden_dims = hidden_dims
# 共享的特征提取网络
layers = []
prev_dim = input_dim
for i, hidden_dim in enumerate(hidden_dims):
layers.append(nn.Linear(prev_dim, hidden_dim))
if use_batch_norm:
layers.append(nn.BatchNorm1d(hidden_dim))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Dropout(dropout_rate))
prev_dim = hidden_dim
self.feature_extractor = nn.Sequential(*layers)
# 注意力机制
self.attention = nn.MultiheadAttention(
embed_dim=hidden_dims[-1],
num_heads=8,
dropout=dropout_rate,
batch_first=True
)
# 交互特征计算层
interaction_dim = hidden_dims[-1] * 4 + 1 # concat + element-wise + diff + cosine
self.interaction_layers = nn.Sequential(
nn.Linear(interaction_dim, hidden_dims[-1]),
nn.BatchNorm1d(hidden_dims[-1]) if use_batch_norm else nn.Identity(),
nn.ReLU(inplace=True),
nn.Dropout(dropout_rate),
nn.Linear(hidden_dims[-1], hidden_dims[-1] // 2),
nn.ReLU(inplace=True),
nn.Dropout(dropout_rate // 2)
)
# 最终分类层
self.classifier = nn.Sequential(
nn.Linear(hidden_dims[-1] // 2, 32),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Linear(32, 1)
)
self._initialize_weights()
def _initialize_weights(self):
"""权重初始化"""
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm1d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, emb_a, emb_b):
# 特征提取
feat_a = self.feature_extractor(emb_a)
feat_b = self.feature_extractor(emb_b)
# 自注意力
feat_a_att, _ = self.attention(feat_a.unsqueeze(1), feat_a.unsqueeze(1), feat_a.unsqueeze(1))
feat_b_att, _ = self.attention(feat_b.unsqueeze(1), feat_b.unsqueeze(1), feat_b.unsqueeze(1))
feat_a_att = feat_a_att.squeeze(1)
feat_b_att = feat_b_att.squeeze(1)
# 多种交互特征
concat_feat = torch.cat([feat_a_att, feat_b_att], dim=1)
element_wise = feat_a_att * feat_b_att
abs_diff = torch.abs(feat_a_att - feat_b_att)
cosine_sim = F.cosine_similarity(feat_a_att, feat_b_att, dim=1, eps=1e-8).unsqueeze(1)
# 综合交互特征
interaction_feat = torch.cat([concat_feat, element_wise, abs_diff, cosine_sim], dim=1)
# 处理和预测
processed_feat = self.interaction_layers(interaction_feat)
output = self.classifier(processed_feat)
return output.squeeze(), cosine_sim.squeeze然后是训练的类:
class PPITrainer:
"""PPI模型训练器"""
def __init__(self, model, device='cuda', use_focal_loss=True):
self.model = model.to(device)
self.device = device
if use_focal_loss:
self.criterion = FocalLoss(alpha=1, gamma=2)
else:
self.criterion = nn.BCEWithLogitsLoss()
self.optimizer = torch.optim.AdamW(
model.parameters(),
lr=1e-3,
weight_decay=1e-4,
betas=(0.9, 0.999)
)
self.scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
self.optimizer, mode='max', factor=0.5, patience=5, verbose=True
)
self.best_val_score = 0
self.patience_counter = 0
self.early_stop_patience = 15
# 记录训练历史
self.history = {
'train_losses': [], 'val_losses': [],
'train_aucs': [], 'val_aucs': [],
'train_accs': [], 'val_accs': [],
'train_f1s': [], 'val_f1s': [],
'learning_rates': []
}
def train_epoch(self, train_loader):
"""单个epoch的训练"""
self.model.train()
total_loss = 0
predictions, labels = [], []
for batch in tqdm(train_loader, desc="Training"):
emb_a = batch['emb_a'].to(self.device)
emb_b = batch['emb_b'].to(self.device)
label = batch['label'].to(self.device)
self.optimizer.zero_grad()
output, cosine_sim = self.model(emb_a, emb_b)
loss = self.criterion(output, label)
# 余弦相似度正则化
cosine_reg = 0.01 * torch.mean(torch.abs(cosine_sim))
total_loss_batch = loss + cosine_reg
total_loss_batch.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)
self.optimizer.step()
total_loss += loss.item()
predictions.extend(torch.sigmoid(output).detach().cpu().numpy())
labels.extend(label.detach().cpu().numpy())
avg_loss = total_loss / len(train_loader)
auc = roc_auc_score(labels, predictions)
# 计算其他指标
binary_preds = (np.array(predictions) > 0.5).astype(int)
accuracy = accuracy_score(labels, binary_preds)
f1 = f1_score(labels, binary_preds)
return avg_loss, auc, accuracy, f1
def validate(self, val_loader):
"""验证"""
self.model.eval()
total_loss = 0
predictions, labels = [], []
all_outputs = []
with torch.no_grad():
for batch in tqdm(val_loader, desc="Validation"):
emb_a = batch['emb_a'].to(self.device)
emb_b = batch['emb_b'].to(self.device)
label = batch['label'].to(self.device)
output, _ = self.model(emb_a, emb_b)
loss = self.criterion(output, label)
total_loss += loss.item()
predictions.extend(torch.sigmoid(output).cpu().numpy())
labels.extend(label.cpu().numpy())
all_outputs.extend(output.cpu().numpy())
avg_loss = total_loss / len(val_loader)
auc = roc_auc_score(labels, predictions)
# 计算最佳阈值
precision, recall, thresholds = precision_recall_curve(labels, predictions)
f1_scores = 2 * (precision * recall) / (precision + recall + 1e-8)
best_threshold = thresholds[np.argmax(f1_scores)]
binary_preds = (np.array(predictions) > best_threshold).astype(int)
accuracy = accuracy_score(labels, binary_preds)
f1 = f1_score(labels, binary_preds)
precision_val = precision_score(labels, binary_preds)
recall_val = recall_score(labels, binary_preds)
mcc = matthews_corrcoef(labels, binary_preds)
return {
'loss': avg_loss, 'auc': auc, 'accuracy': accuracy, 'f1': f1,
'precision': precision_val, 'recall': recall_val, 'mcc': mcc,
'best_threshold': best_threshold, 'predictions': predictions,
'labels': labels, 'binary_preds': binary_preds
}
def train(self, train_loader, val_loader, epochs=100):
"""完整训练流程"""
for epoch in range(epochs):
print(f"\nEpoch {epoch+1}/{epochs}")
# 训练
train_loss, train_auc, train_acc, train_f1 = self.train_epoch(train_loader)
# 验证
val_results = self.validate(val_loader)
# 学习率调度
self.scheduler.step(val_results['auc'])
current_lr = self.optimizer.param_groups[0]['lr']
# 记录历史
self.history['train_losses'].append(train_loss)
self.history['val_losses'].append(val_results['loss'])
self.history['train_aucs'].append(train_auc)
self.history['val_aucs'].append(val_results['auc'])
self.history['train_accs'].append(train_acc)
self.history['val_accs'].append(val_results['accuracy'])
self.history['train_f1s'].append(train_f1)
self.history['val_f1s'].append(val_results['f1'])
self.history['learning_rates'].append(current_lr)
print(f"Train - Loss: {train_loss:.4f}, AUC: {train_auc:.4f}, Acc: {train_acc:.4f}, F1: {train_f1:.4f}")
print(f"Val - Loss: {val_results['loss']:.4f}, AUC: {val_results['auc']:.4f}, Acc: {val_results['accuracy']:.4f}, F1: {val_results['f1']:.4f}")
print(f"Val - Precision: {val_results['precision']:.4f}, Recall: {val_results['recall']:.4f}, MCC: {val_results['mcc']:.4f}")
print(f"Best Threshold: {val_results['best_threshold']:.4f}, LR: {current_lr:.6f}")
# 早停检查
if val_results['auc'] > self.best_val_score:
self.best_val_score = val_results['auc']
self.patience_counter = 0
torch.save({
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'epoch': epoch,
'val_auc': val_results['auc'],
'best_threshold': val_results['best_threshold']
}, 'best_ppi_model.pth')
print("🎉 保存最佳模型!")
else:
self.patience_counter += 1
if self.patience_counter >= self.early_stop_patience:
print(f"⏹️ 早停触发! 最佳验证AUC: {self.best_val_score:.4f}")
break
return self.history如果大家还有其他疑问,可以找Tom一起讨论~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号