不改权重、不用训练!BEM用背景记忆抑制固定摄像头误检,YOLO/RT-DETR全系有效
原创
不改权重、不用训练!BEM用背景记忆抑制固定摄像头误检,YOLO/RT-DETR全系有效
原创
CoovallyAIHub
发布于 2026-04-17 16:32:33
发布于 2026-04-17 16:32:33
导读
预训练检测器在COCO上精度亮眼,但一旦部署到固定摄像头监控场景,误检率往往大幅上升——阴影、栏杆、重复纹理都可能被当成目标。问题出在哪?本文指出根源在于类内稀疏性(per-class sparsity):COCO每张图每个类别只有少量实例,而监控场景往往是密集、单类别的。
针对这个问题,仁川国立大学与美国德克萨斯理工大学的研究团队提出了BEM(Background Embedding Memory),一个完全免训练、不修改模型权重的推理时模块。BEM利用固定摄像头场景中"背景几乎不变"这一先验,通过背景嵌入记忆与余弦相似度驱动的logit重评分,自适应抑制误检。在LLVIP数据集上,BEM在全部8种检测器配置下均提升了P-AUC和mAP@0.5,其中RT-DETR-L(COCO→VOC)的P-AUC提升达+5.75个点,且无需任何额外训练。
论文信息
- 标题:BEM: Training-Free Background Embedding Memory for False-Positive Suppression in Real-Time Fixed-Background Camera
- 作者:Junwoo Park, Jangho Lee, Sunho Lim
- 机构:Department of Computer Science and Engineering, Incheon National University; Army Artificial Intelligence Center, Republic of Korea Army; Department of Computer Science, Texas Tech University
- 代码:https://github.com/Leo-Park1214/Background-Embedding-Memory.git
一、固定摄像头场景下,预训练检测器为什么"不准"?
YOLO系列和RT-DETR等主流检测器在COCO基准上经过充分训练,通用检测能力已经相当成熟。然而,当这些模型被直接部署到固定摄像头的实际监控场景(如交通路口、安防通道)时,精度往往出现明显下降,大量假阳性检测(false positives)成为主要瓶颈。
论文将这一现象归因于类内稀疏性(per-class sparsity)问题。以COCO数据集为例,其设计强调类别多样性(category diversity),每张图像中每个类别通常只有少量实例。但在固定摄像头监控场景中,情况截然不同——以LLVIP行人监控数据集为例,单张图像中可能出现十几个行人,属于典型的密集、单类别或少类别分布。这种分布差异使得检测器容易将场景中反复出现的背景结构(如阴影、栏杆、路面标线)误判为前景目标。
与此同时,论文提出了一个关键观察:固定摄像头场景有一个尚未被充分利用的先验——准静态背景(quasi-static background)。摄像头固定不动,意味着背景在时间维度上几乎不变。实验表明,当前帧与背景越相似(即场景中前景目标越少),检测器的精度越稳定;反之,当场景变化较大时,误检风险也随之升高。
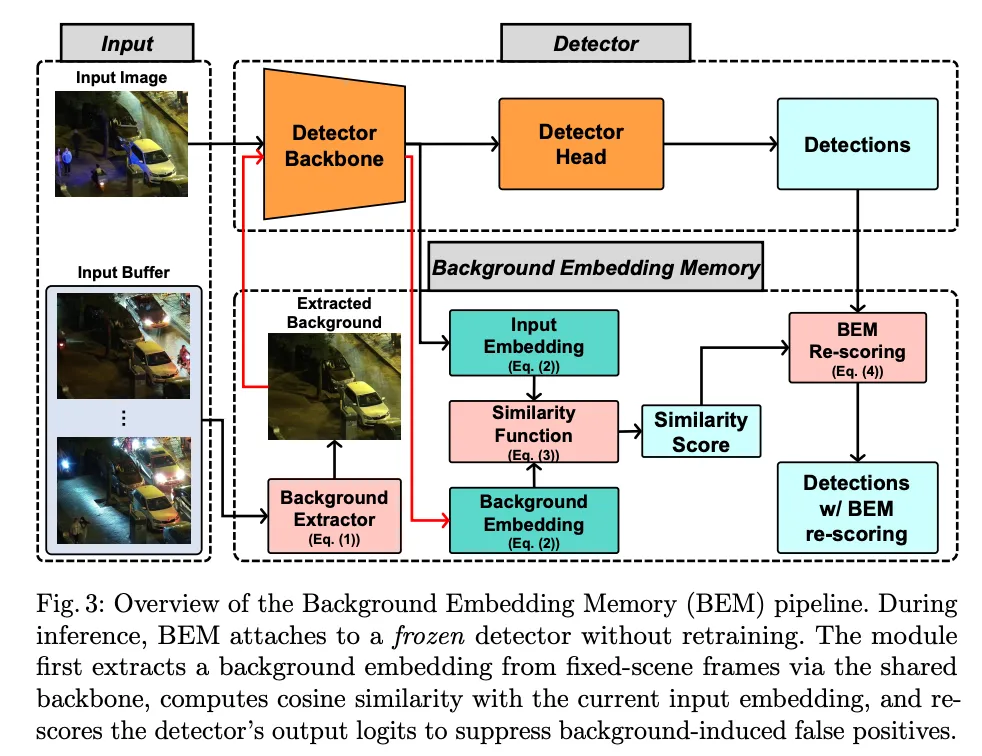
二、BEM:用背景记忆驱动误检抑制
基于上述观察,论文提出了BEM(Background Embedding Memory)。BEM是一个免训练(training-free)、不修改模型权重的推理时模块,可以直接挂载在任意预训练检测器之上。其核心思路是:利用背景的时序稳定性,建立一个背景嵌入记忆,再通过背景-当前帧的相似度来自适应调整检测器的输出置信度,从而抑制误检。
整个流程分为三步:
Step 1:背景估计(Background Estimation)
BEM从最近L帧(论文中L=25,经经验搜索确定)中提取背景。具体方法是:利用检测器自身的检测框标记前景区域,对非前景区域的像素进行掩码时序平均(masked temporal averaging)。公式为:
B = Σ(I_t ⊙ M_t) / Σ M_t
其中M_t=0的区域表示被检测器标记的前景区域。这样得到的背景估计B,排除了前景目标的干扰,保留了场景的静态结构信息。
Step 2:背景嵌入记忆(Background Embedding Memory)
BEM复用检测器自身的backbone(不修改权重),分别提取背景B和当前帧I的特征,经过全局池化和归一化后得到:
- E_B = norm(pool(f(B))):背景嵌入
- E_I = norm(pool(f(I))):当前帧嵌入
然后计算两者的余弦相似度:
c = E_I^T · E_B
论文通过实验验证了一个关键发现:相似度c与场景中目标数量呈负相关,与P-AUC呈正相关。换言之,c越高表明当前帧越接近纯背景,检测器的精度越高;c越低则说明场景中前景目标较多或场景发生了较大变化。
Step 3:相似度驱动的Logit重评分(Similarity-Driven Logit Re-scoring)
在获得相似度c之后,BEM对检测器输出的N个proposal进行重评分。具体做法是:
- 将N个proposal按置信度降序排列,得到排名r_i
- 在logit空间中施加反向相似度、排名加权的惩罚:
z'_i = logit(s̄_i) - (α/γ) · w_i / max(c, δ)
s'_i = σ(z'_i)
其中:
- w_i = (N - r_i) / (N + 1):排名权重,高置信度的proposal排名靠前,w_i较小,受到的惩罚更轻
- α:惩罚尺度(per-detector调优)
- γ:温度参数
- δ:数值稳定常数(10⁻⁶)
这个设计的核心逻辑是:当背景相似度c较低时(场景变化大或目标较多),惩罚项增大,更积极地抑制低置信度检测;而高置信度的检测受到的影响较小,从而保护真正的正确检测不被误伤。
图片来源于原论文
三、实验结果:8种检测器配置全面提升
数据集与实验设置
论文选用LLVIP数据集进行评估。LLVIP包含16,836对可见光+红外图像,覆盖26个街道位置,目标类别为单一的行人检测,可见光分辨率为1920×1080,红外分辨率为1280×720,是典型的固定摄像头监控场景。
实验覆盖了8种检测器变体:
- COCO预训练:YOLOv11m、YOLOv8s、RT-DETR-L
- COCO→VOC微调:YOLOv11m、YOLOv8s、RT-DETR-L
- 开放词汇模型:YOLOv8s-Worldv2、YOLOv8l-Worldv2
所有检测器在评估时权重完全冻结,BEM作为外部模块附加,不修改任何模型参数。评估指标包括mAP@0.50、P-AUC(Precision-Confidence AUC)和Latency。
检测精度对比
模型(变体) | P-AUC Base | P-AUC BEM | mAP@0.5 Base | mAP@0.5 BEM |
|---|---|---|---|---|
YOLOv11m (COCO) | 89.82 | 92.87(±0.034) | 80.49 | 80.99(±0.001) |
YOLOv8s (COCO) | 88.44 | 91.63(±0.017) | 75.34 | 75.90(±0.028) |
RT-DETR-L (COCO) | 77.60 | 82.85(±0.030) | 79.26 | 79.59(±0.022) |
YOLOv11m (COCO→VOC) | 93.39 | 94.24(±0.004) | 68.71 | 69.51(±0.012) |
YOLOv8s (COCO→VOC) | 92.67 | 93.51(±0.013) | 66.17 | 66.88(±0.021) |
RT-DETR-L (COCO→VOC) | 78.44 | 84.19(±0.027) | 66.19 | 66.58(±0.027) |
YOLOv8s-Worldv2 | 81.78 | 81.88(±0.011) | 90.23 | 91.36(±0.001) |
YOLOv8l-Worldv2 | 86.22 | 86.27(±0.005) | 91.20 | 92.36(±0.003) |
从结果来看:
- BEM在全部8种设置下均同时提升了P-AUC和mAP@0.5,没有出现任何性能退化
- P-AUC提升幅度最大的是RT-DETR-L(COCO→VOC),从78.44提升到84.19,增幅达+5.75
- COCO预训练模型整体获益最大,P-AUC平均提升约+2至+5个点
- mAP@0.5的提升幅度较小但方向一致为正,范围在+0.33到+1.16之间
- 提升主要集中在高背景相似度的帧上——即背景主导、前景目标较少的帧受益最大
延迟开销
模型 | Base延迟 (ms) | BEM延迟 (ms) | 相对增幅 |
|---|---|---|---|
YOLOv11m | 370.15 (±1.22) | 415.02 (±3.81) | +12.1% |
YOLOv8s | 318.49 (±1.97) | 368.26 (±5.93) | +15.6% |
RT-DETR-L | 30.87 (±0.14) | 54.44 (±0.34) | +76.3% |
YOLOv8s-Worldv2 | 23.52 (±0.10) | 41.67 (±0.12) | +77.2% |
YOLOv8l-Worldv2 | 25.51 (±0.08) | 44.44 (±0.08) | +74.2% |
BEM增加的延迟主要来自背景嵌入的特征提取计算。对于本身推理较慢的模型(如YOLOv11m,基线370.15ms),BEM的相对开销较小(+12.1%);对于本身较快的模型(如RT-DETR-L,基线30.87ms),相对开销较大(+76.3%),但绝对延迟仍为54.44ms,在实时监控场景中仍属可接受范围。
四、消融实验:超参数α和γ的影响
论文对BEM的两个核心超参数——惩罚尺度α和温度参数γ进行了消融分析。
实验发现,当γ较大时,模型对α的选择不敏感,P-AUC在较宽的α范围内保持稳定。这意味着在实际部署中,用户不需要对α进行精细调优,只需选择一个较大的γ值即可获得稳健的表现。
此外,背景估计中的时间窗口长度L=25也是经验搜索确定的。这个参数决定了用多少帧来估计背景,过短可能导致背景估计不稳定,过长则可能无法适应缓慢的光照变化。
五、总结与思考
BEM的核心思路是利用固定摄像头"背景不变"的先验,在推理时通过背景嵌入相似度自适应校正检测器输出,无需训练或修改权重。实验在8种检测器配置上P-AUC均有提升(最高+5.75),且无性能退化。
值得关注的是,BEM目前仅在LLVIP(单类别行人监控)上验证,在多类别场景和背景存在周期性变化(树木摇摆、光照剧变)的条件下是否仍然可靠,还需更多验证。此外,对RT-DETR-L等快速模型的延迟增幅达76%,边缘部署场景中可考虑缓存背景嵌入来降低开销。BEM的即插即用特性和已开源代码,使其对已部署YOLO/RT-DETR的监控系统具有较高的工程实用价值。

图片来源于原论文
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号