OCR 新纪元,超强文档解析 Skills 来了

OCR 新纪元,超强文档解析 Skills 来了

Ai学习的老章
发布于 2026-04-17 16:30:15
发布于 2026-04-17 16:30:15
知识管理缺了一块拼图
前段时间我在基于大模型、SKills 的知识管理一文中介绍了 Karpathy 的知识管理方法——把各种原始素材统统丢进 raw/ 目录,用 Obsidian Web Clipper 一键裁剪网页,配合 LLM 慢慢「编译」成结构化 wiki
这个思路是对的,先不管三七二十一,把所有原始材料攒在一起。但问题来了:实际工作中,原始材料可不只是网页和 Markdown
合同、财报、研报是 PDF、内部培训材料是 PPT、数据是 Excel,各种文档是 Word……这些东西直接扔给大模型,轻则格式一塌糊涂,重则整个表格都消失了,跨页的更是截成碎片。做过 RAG 的都知道,解析是第一道关,解析不好,后面再聪明也白搭——垃圾进,垃圾出
OCR、文档解析相关我写过 N 多篇:DeepSeek-OCR、HunyuanOCR、PaddleOCR、GLM-OCR、MinerU 等,横向对比了以上开源方案,从落地层面我最推荐的可能还是# RAG 必备,100 页 PDF 文档秒级精准解析!实测,很强!一文中我实测过的TextIn xParse,实力我就不单独摘过来了,总之很强!
现在 xparse-parse 的 Skills 发布了,试用之后感觉:这才是最省心的方式
先说大家最关心的格式支持问题,再细说安装的事儿
格式支持
TextIn xParse 属于商业工具,但这次的skill提供了每日1000页的额度,个人使用完全足够
- 格式支持:PDF+图片(
JPG/PNG/BMP/TIFF/WebP),≤10MB,每日1000页,1次/秒 - 配置凭证后:
https://cc.co/16YSe8(注册后获取APP ID和Secret Code),全格式解锁Word、Excel、PPT、HTML、OFD、RTF等20+格式,单文件≤500MB,无每日页数上限
Skills 地址:github.com/intsig-textin/xparse-skills
核心是两样东西:
- SKILL.md——告诉 Agent 什么时候触发文档解析、怎么路由
- xparse-cli——Go 编写的跨平台二进制工具,底层调用 TextIn xParser API
整个工作流如下图:
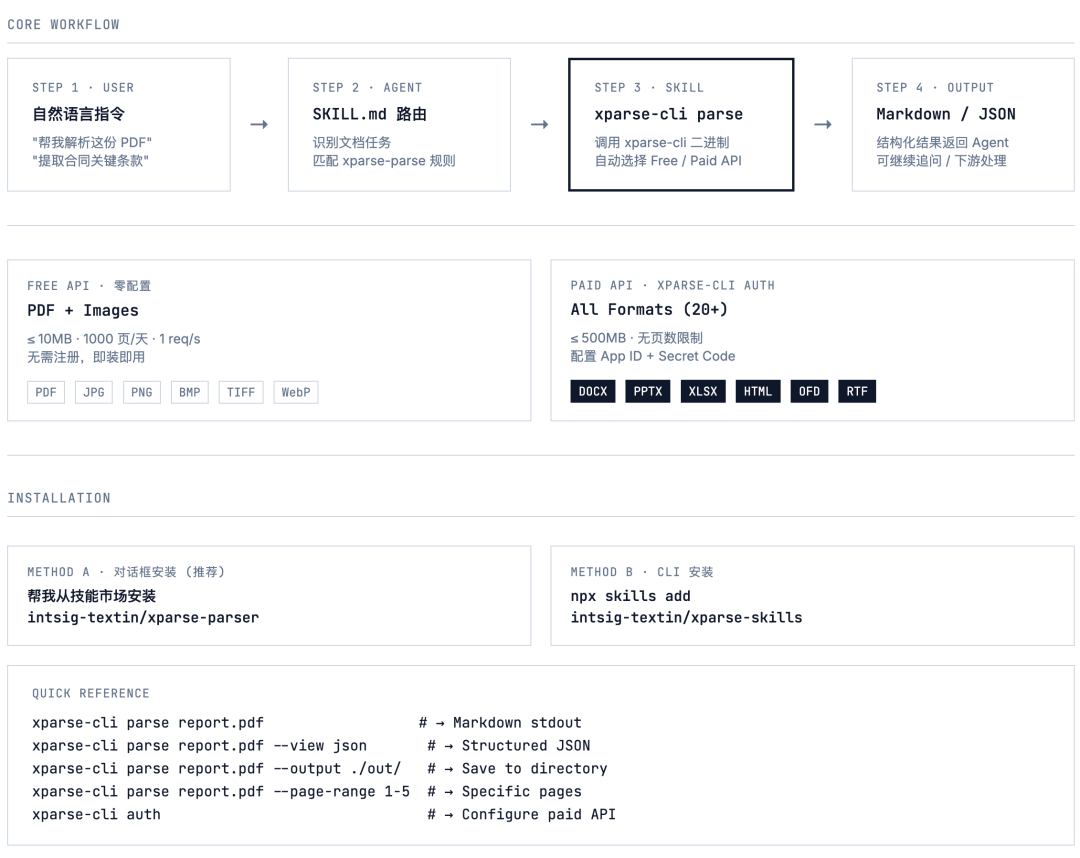
用户说一句话 → Agent 自动识别是文档任务 → 触发 xparse-parse Skill → 调用 xparse-cli → 根据有无凭证自动走免费/付费 API → 返回 Markdown 或 JSON。
全程你不用写一行代码,甚至不用知道 xparse-cli 怎么用
安装方式
方式一:对话框一句话安装
在 Agent 对话框直接说:
帮我从技能市场安装 intsig-textin/xparse-parser
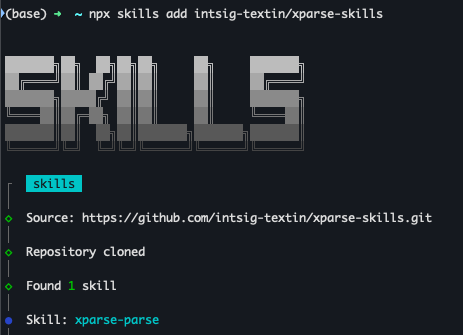
方式二:npx 命令安装(强烈推荐)
npx skills add intsig-textin/xparse-skills
我最推荐这种方式,比较优雅
而且还可以一键安装到所有 Agent 工具中
凭证配置只要一条命令:
xparse-cli auth
按提示输入 App ID 和 Secret Code,保存到 ~/.xparse-cli/config.yaml,后续自动读取
也支持环境变量方式(适合 CI/CD):
export XPARSE_APP_ID=your_app_id
export XPARSE_SECRET_CODE=your_secret_code
用法
在 OpenClaw、Claude Code 等 Agent 平台安装 xparse-parser Skill 后,只需自然语言指令即可完成解析全流程
例如:
- “帮我读一下这份PDF合同,提取关键条款”
- “把这个报告转成Markdown,保存到桌面”
- “这份加密PDF密码是123456,帮我解析前10页”
- “提取这张表格图片里的内容,输出JSON”
核心命令详解
这里大家了解就行了,其实配置好 Skills之后,完全不需要记住这些
# 最基础:解析 PDF,输出 Markdown 到终端
xparse-cli parse report.pdf
# 输出结构化 JSON
xparse-cli parse report.pdf --view json
# 保存到目录(自动命名为 report.md / report.json)
xparse-cli parse report.pdf --output ./result/
# 保存到指定文件
xparse-cli parse report.pdf --output parsed.md
# 只解析指定页码范围(支持多段)
xparse-cli parse report.pdf --page-range 1-5
xparse-cli parse report.pdf --page-range 1-2,5-10
# 解析加密 PDF
xparse-cli parse secret.pdf --password mypassword
# 获取字符级坐标和置信度(做人工核验时用)
xparse-cli parse report.pdf --view json --include-char-details --output ./parsed.json
值得注意的是,CLI 默认已经开启了一套完整的解析能力,不需要额外配置:
能力 | 说明 |
|---|---|
标题层级 | 自动识别文档结构,最多 5 级标题 |
表格结构 | HTML 格式保留单元格层级 |
图片提取 | 内嵌图片识别和提取 |
目录树 | 自动生成文档 TOC |
分页结果 | 页面级元数据 |
唯一需要手动开启的是 --include-char-details(字符坐标),因为这个会大幅增加返回数据量,按需开启
几个实用进阶玩法
① 管道组合,直接喂给 LLM
# 解析后搜索关键词
xparse-cli parse report.pdf | grep "revenue"
# 解析完直接喂给 LLM 总结
xparse-cli parse paper.pdf | llm "summarize this paper"
② 批量处理
# 准备一个文件列表 files.txt,一行一个路径
xparse-cli parse --list files.txt --output ./results/
③ 从解析结果里下载图片
# 先解析为 JSON
xparse-cli parse report.pdf --view json --output result.json
# 再从 JSON 里批量下载所有图片
xparse-cli download --from result.json --output ./images/
④ 私有化部署
如果是私有部署的 TextIn 服务,可以通过 --base-url 指定:
xparse-cli parse report.pdf --base-url https://your-private-server.com
总结
xparse-parse Skill 这个组合,我觉得把文档解析这件事做到了目前最低门槛的状态:
适合你用的场景:
- 用 Agent 做个人知识管理,原料里有大量 PDF/Word/PPT
- 搭建 RAG 知识库,需要高精度的文档结构化
- 日常工作要解析合同、财报、研报这类复杂文档
优缺点直说:
评价 | |
|---|---|
✅ 零代码零门槛 | 说话就能用,适合所有技术水平 |
✅ 复杂表格能力强 | 跨页拼接、合并单元格、无线表格都不虚 |
✅ 免费额度够用 | PDF+ 图片 1000 页/天,轻度使用完全够 |
✅ 管道/批量支持 | 可与 LLM、脚本组合,适合自动化流水线 |
⚠️ Word/PPT/Excel 需付费 | 免费版只有 PDF 和图片 |
⚠️ 免费版 10MB 限制 | 大型 PDF 需要付费账户 |
#文档解析 #Skills #TextIn #Agent #知识管理
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号