Claude Opus 4.7 来了,编程能力又炸了
原创
Claude Opus 4.7 来了,编程能力又炸了
原创
鱼片粥来碗豆腐
修改于 2026-04-17 14:38:44
修改于 2026-04-17 14:38:44
今天继续聊 Claude —— Anthropic 刚刚正式发布了 Claude Opus 4.7,编程能力这次又是一次暴击
Benchmark 一览
下图是 Anthropic 给出的跨领域 benchmark 对比,Opus 4.7 在大多数任务上超过了 Opus 4.6,以及 GPT-5.4 和 Gemini 3.1 Pro:
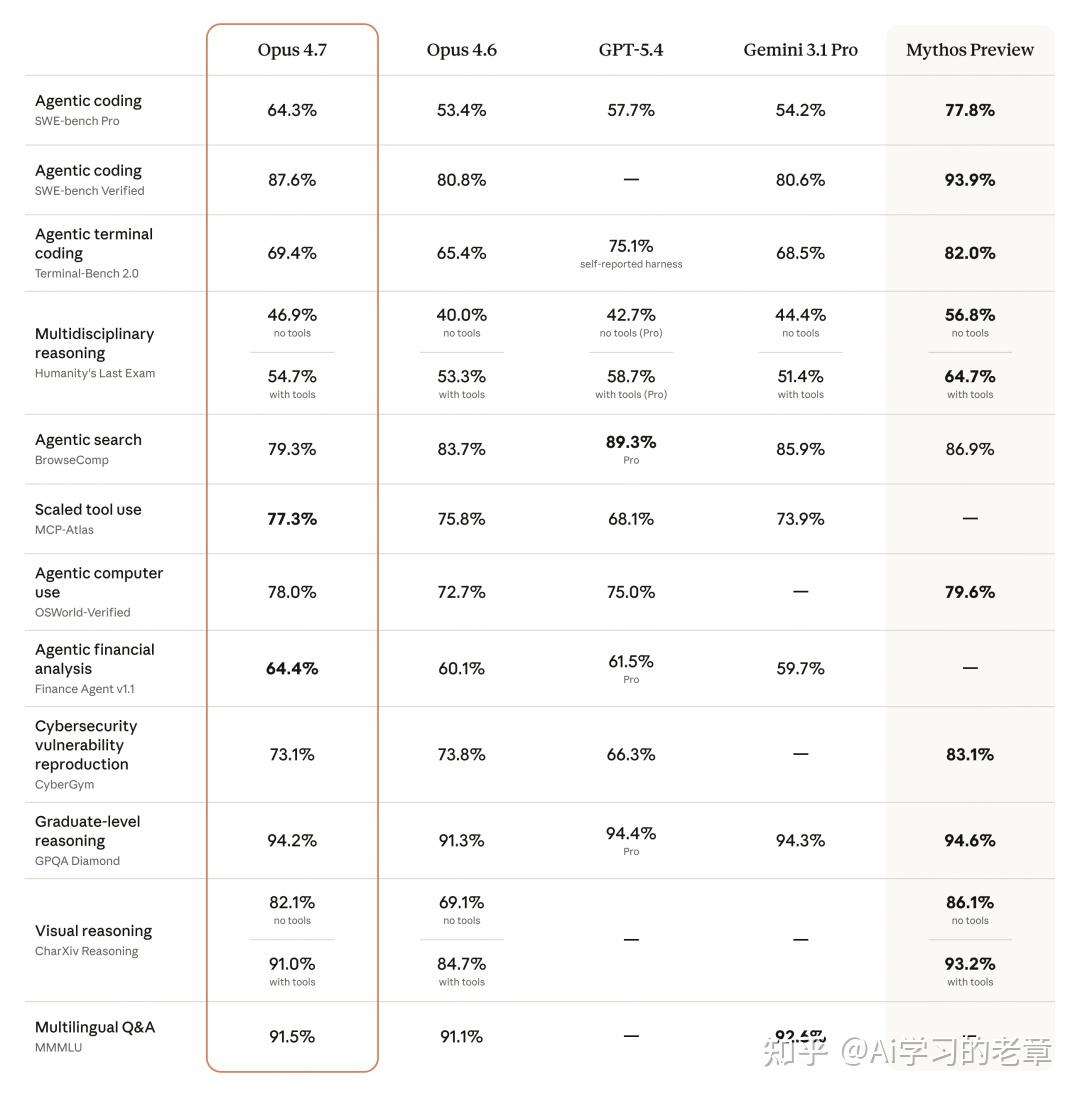
Claude Opus 4.7 跨领域 Benchmark 对比
它比 Opus 4.6 强在哪?
Anthropic 官方说,Opus 4.7 在高级软件工程上是 Opus 4.6 的「显著提升」,尤其是在那些最难的任务上
这话我本来要打个折,但看了一圈测试用户的反馈之后,我信了
几个让我印象深刻的数据:
- Cursor:在 93 个编程任务的 benchmark 上,任务解决率比 Opus 4.6 **提升了 13%**,包括 4 个 Opus 4.6 和 Sonnet 4.6 都搞不定的任务
- Rakuten:在 SWE-bench 上,Opus 4.7 解决的真实生产 bug 是 Opus 4.6 的 3 倍。
- XBOW(自主渗透测试):视觉准确性从 Opus 4.6 的 54.5% 直接干到 **98.5%**,这简直是量变引发质变
- Notion:工具调用准确率和规划能力提升超过 **10%**,更难得的是,它是第一个通过隐式需求测试(implicit-need tests)的模型
视觉能力:分辨率翻了 3 倍多
这次 Opus 4.7 的视觉升级幅度相当大
之前的 Claude 模型能接受的图片分辨率,现在 Opus 4.7 可以接受最长边 2,576 像素(约 3.75 百万像素),是之前版本的 3 倍以上
这意味着什么?
- 读密集截图的 computer-use agent,再也不会因为文字太小看不清而出错
- 从复杂图表里提取数据,精度大幅提升
- 科学、法律文档里那些需要像素级精准的工作,终于能干了
来自 Solve Intelligence(生命科学专利工作流)的反馈印证了这一点:从化学结构式到复杂技术图纸,理解能力大幅跃升
注意这是模型层面的变化,不是 API 参数,图片会自动以更高精度处理。但因为高分辨率图片消耗 token 更多,如果你不需要那么高的精度,可以在发送前先降采样
指令遵循:这次是认真的
Opus 4.7 在指令遵循上大幅提升
听起来是好事,但 Anthropic 自己也提醒了:之前给旧模型写的 prompt,有时候会跑出意外结果——因为旧模型对指令是「松散理解」甚至跳过某些部分,现在 Opus 4.7 是字面意思照单全收
所以如果你是 API 用户,升级前最好重新审视一下你的 prompt,该精确的地方要精确,该删掉的废话要删掉
新功能:xhigh 努力等级
Opus 4.7 引入了全新的 xhigh(extra high)努力等级,介于原来的 high 和 max 之间
这给用户提供了更细粒度的控制:在硬问题上,你可以选择在「思考质量」和「响应延迟」之间找到更合适的平衡点
在 Claude Code 里,现在默认把所有计划的努力等级提升到了 xhigh
官方建议在编程和 Agent 场景下测试时,从 high 或 xhigh 开始
下图是不同努力等级下,token 使用量和任务得分的关系:
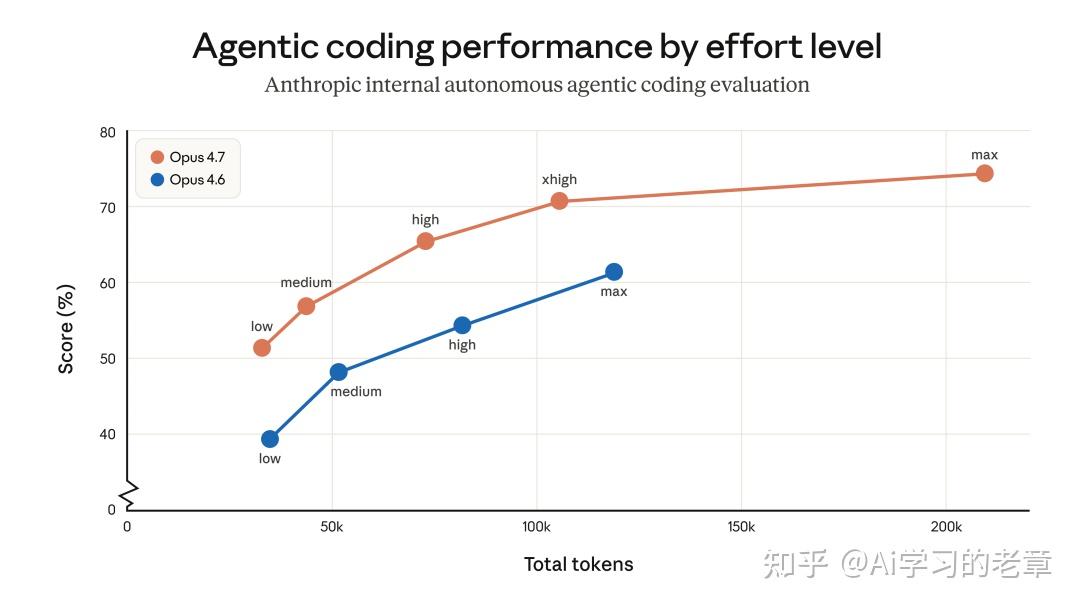
不同努力等级下的 token 使用量与任务得分对比
网络安全:先迈一步,但很谨慎
Anthropic 上周公布了 Project Glasswing,直面 AI 在网络安全领域的两面性——风险与机遇。
Opus 4.7 是 Glasswing 框架下第一个正式落地的模型,它的网络安全能力不如 Claude Mythos Preview(目前最强的 Anthropic 模型),Anthropic 在训练阶段专门做了差异化处理,有意限制了部分网络安全能力
同时,Opus 4.7 配备了自动检测和拦截高危网络安全请求的防护机制
真正有合法需求的安全研究人员、渗透测试工程师,可以通过 Cyber Verification Program加入白名单
这条路子我觉得挺对的:先在能力较弱的模型上验证防护机制是否有效,积累经验后,再逐步向更强的 Mythos 级别模型开放
安全性测评
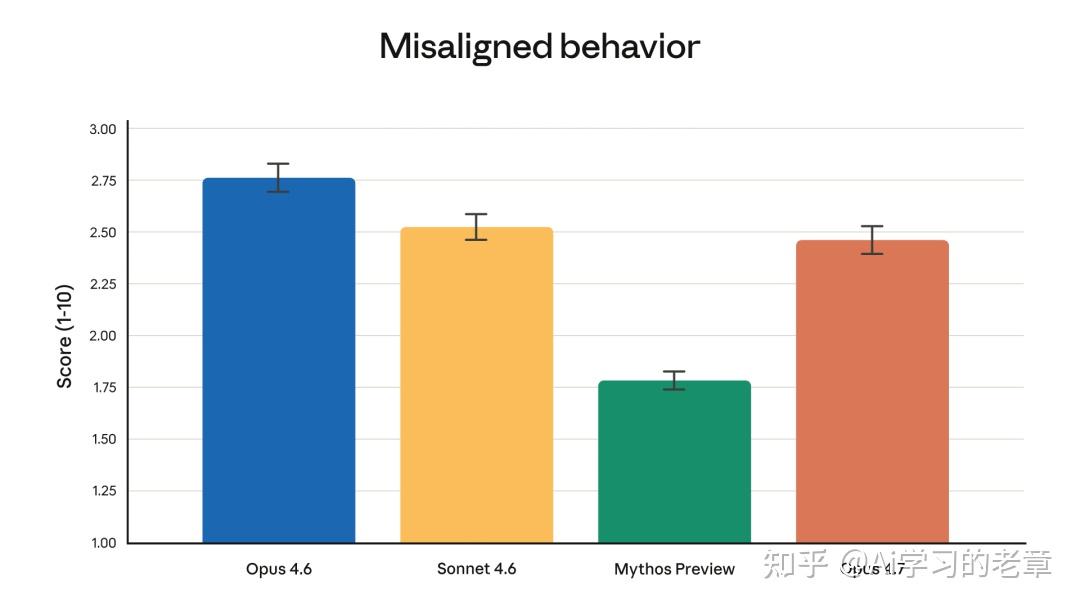
Claude Opus 4.7 行为审计评分
在安全对齐方面,Opus 4.7 和 Opus 4.6 整体差不多——欺骗行为、谄媚、滥用配合率都处于低水平
部分维度(比如诚实性、对抗 prompt 注入攻击)比 4.6 有改进,少数地方(比如有害物质信息的过度详细回复)略微退步
整体结论:「大体对齐、基本可信,但还没达到理想状态」
Mythos Preview 依然是 Anthropic 目前对齐效果最好的模型
价格 & 可用性
好消息:价格不变,和 Opus 4.6 一样:
- 输入:**$5 / 百万 tokens**
- 输出:**$25 / 百万 tokens**
支持平台:
- Claude 全产品线
- Claude API(模型 ID:
claude-opus-4-7) - Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Foundry
⚠️ 但是请注意一个更现实的使用建议
现在大家都在讨论“哪个模型最强”,但实际工作中会遇到一个问题:
👉 不同模型擅长不同任务
例如:
- Claude → 代码 / 推理
- GPT → 通用 / 产品化
- Gemini → 多模态
所以越来越多开发者的做法是:
👉 多模型组合使用,而不是单押一个
但问题也很现实:
- 多账号
- API价格高
- 切换麻烦
因此现在不少人会直接用“统一接入多个模型”的方式(尤其做开发或AI产品的人)。 像一些聚合平台可以:
- 同时调用 Claude / GPT / Gemini
- 做效果对比测试
- 成本压得更低(对频繁调用的人很关键)
还有这些新东西一起上
随 Opus 4.7 一起发布的还有几个配套更新:
/ultrareview命令(Claude Code):一键启动深度代码审查,像一个认真的 reviewer 一样帮你找 bug 和设计问题,Pro 和 Max 用户各有 3 次免费试用额度。- Task Budgets(公测)(API):给开发者一个新机制,引导 Claude 在长任务中合理分配 token 预算,避免前紧后松或前松后紧
- Auto Mode 扩展:Max 用户现在也可以开启 Auto Mode,让 Claude 在长任务里自主决策权限请求,减少中断
升级注意事项
如果你在生产上用 Opus 4.6,升级到 4.7 有两个点要注意:
- 新 tokenizer:同样的输入,token 数大约会增加 1.0–1.35 倍,取决于内容类型
- 更高努力等级下思考更多:尤其是 Agent 场景的后续对话轮次,输出 token 会增加
Anthropic 提供了迁移指南,建议先在真实流量上测一下差异
总结
Opus 4.7 的核心关键词:编程更强、视觉更清、指令更准、安全更严
如果你是:
- Claude Code 用户:直接用,默认已升级到 xhigh 努力等级,新的
/ultrareview也很值得试 - API 开发者:记得重新调 prompt,关注 token 用量变化,迁移指南先读一遍
- 网络安全从业者:有合法需求的走 Cyber Verification Program
最让我感兴趣的其实是这个关于「更好同事」的描述——一个会在技术讨论中反驳你、帮你做出更好决定的 AI
这可能才是 AI 应该有的样子,不是附和你,是真的帮你。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号