人脸识别到底靠什么技术实现?从刷脸支付到地铁闸机,拆解工业级应用的核心逻辑

人脸识别到底靠什么技术实现?从刷脸支付到地铁闸机,拆解工业级应用的核心逻辑

搜罗万相
发布于 2026-03-26 20:33:51
发布于 2026-03-26 20:33:51
现在出门基本离不开人脸识别了——买咖啡刷脸付账,进地铁刷脸过闸,去政务大厅办事甚至不用带身份证,对着镜头扫一下就能确认身份。但很多人可能会好奇:这些设备是怎么准确认出“我是我”的?还是像以前那样简单对比照片,或者找几个五官特征点吗?
其实早不是了。现在工业场景里的人脸识别,底层技术已经全面转向深度学习,尤其是基于卷积神经网络(CNN)的模型。比起传统方法,它应对光线变化、戴口罩、侧脸等复杂情况的能力强了不止一个档次。今天就从技术原理到实际应用,把这事说清楚。
一、为什么传统技术被淘汰了?
早期的人脸识别,靠的是“手工定义特征”——简单说就是工程师先告诉机器“该看什么”,再让机器按这个标准去比对。最典型的有三种:
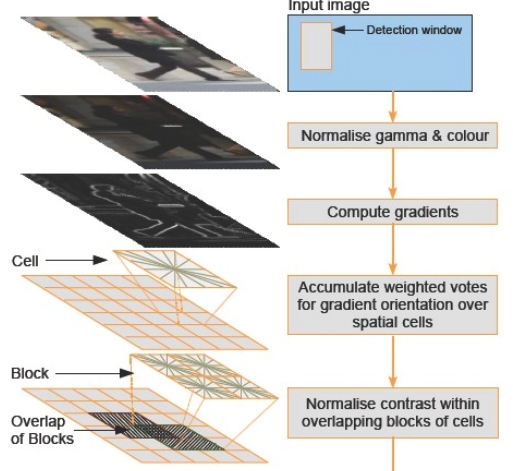
- SIFT(尺度不变特征变换):主打“不管照片放大缩小,都能找到同样的特征点”,比如眼角、鼻尖这些固定位置;
- HOG(方向梯度直方图):会把人脸分成小块,统计每个小块里线条的朝向,比如眉毛是斜的还是平的,再拼成整体特征;
- LBP(局部二值模式):对比每个像素和周围像素的明暗差异,生成一串二进制代码,相当于给人脸做个“像素指纹”。

alt text
alt text

alt text
这些方法在实验室里看着还行,但到了真实场景就容易“掉链子”。比如你戴个墨镜,SIFT找的特征点就少了一半;商场里灯光忽明忽暗,HOG统计的线条方向就乱了;甚至你笑的时候苹果肌鼓起来,LBP的“像素指纹”都可能变样。简单说,传统技术太“死板”,稍微有点变化就认不出人了。
alt text
而深度学习的优势正好能补上这个短板:它不用人提前设定“该看什么”,而是自己从海量数据里学规律。比如给模型喂10万张不同光线、不同姿态、不同表情的人脸照片,它会自己总结出“不管这人戴不戴口罩,颧骨到下巴的轮廓比例是不变的”“哪怕侧脸,眉骨到鼻梁的弧度有独特性”——这些人类没注意到的“隐藏特征”,恰恰是识别的关键。
二、工业级人脸识别

alt text
1. 第一步:人脸检测——先把“脸”从画面里揪出来
机器要先知道“哪里有人脸”,才能后续识别。这一步的关键是“快”和“准”——既要在复杂画面里(比如人群、逆光场景)快速定位,又不能把路灯、圆桌子误判成脸。
早期用的是Haar特征+Adaboost分类器,原理类似“找不同”:先预设好“眼睛是两个暗块,鼻子是中间亮块”这种特征,再让机器在画面里逐块比对。但这种方法对模糊画面、侧脸的识别率很低,现在已经基本被淘汰。
alt text
现在工业界主流用的是两种深度学习模型:
- MTCNN(多任务级联卷积神经网络):最常用的“人脸定位神器”,核心是“分三次筛选”。第一次快速扫一遍画面,把所有可能是脸的区域圈出来(哪怕是模糊的小色块);第二次用更精细的网络过滤掉明显不是脸的区域(比如方形的瓷砖);第三次不仅确定脸的位置,能准确标出眼睛、鼻子、嘴巴的坐标——相当于既找到脸,又给脸做了“关键点定位”,为后续提取特征打基础。
- RetinaFace:比MTCNN更进阶,能处理更极端的情况——比如人脸只露出1/3,或者在强光、逆光环境下,它都能准确检测到。现在高端的刷脸设备,比如银行的自助终端,基本用的是这个模型。
举个实际案例:支付宝刷脸支付时,镜头会先调用MTCNN,在1秒内完成“找脸+关键点定位”,甚至能判断你是不是“活人脸”(比如让你眨眨眼),防止有人用照片作弊。

alt text
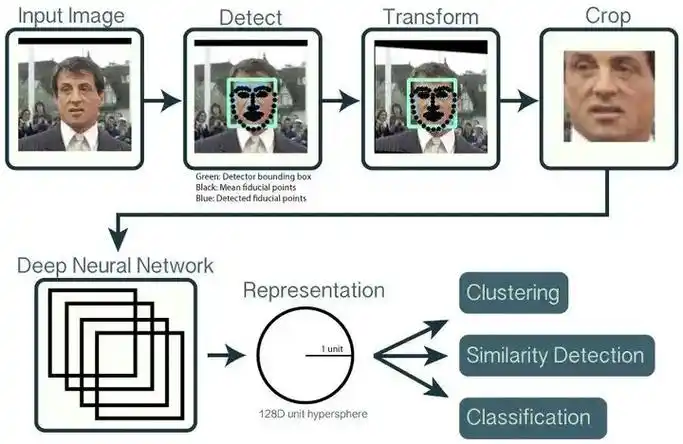
2. 第二步:特征提取——给人脸做个“数字身份证”
找到脸之后,下一步要做的是“提取独特特征”——简单说就是把人脸转换成一串数字,这串数字要满足两个要求:同一个人的不同照片,数字尽量相似;不同人的照片,数字尽量不同。
这一步是人脸识别的核心,目前工业界主流用两种模型:
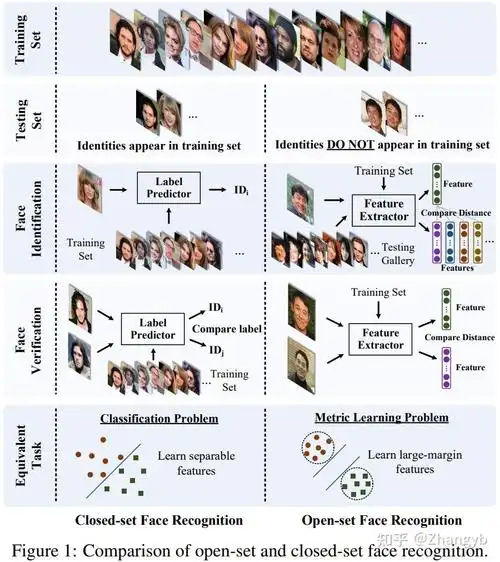
- FaceNet:谷歌提出的经典模型,核心是用“三元组损失(triplet loss)”训练。比如同时给模型看三张图:你的正面照(锚点图)、你的侧脸照(正样本)、别人的照片(负样本),模型会调整参数,让“锚点图和正样本的数字距离”尽可能近,“锚点图和负样本的数字距离”尽可能远。训练好后,它能把人脸转换成128维或512维的向量(就是128个或512个数字),这串向量就是你的“数字身份证”。
alt text
- ArcFace:比FaceNet更精准的升级款,加入了“角度损失(Angular Margin Loss)”。简单说就是进一步拉大“不同人数字向量的差距”——比如你和长得像的人,FaceNet可能会把你们的向量算得比较近,但ArcFace会刻意扩大这个差距,减少认错人的概率。现在金融、政务这些对精度要求高的场景,基本都用ArcFace。
alt text
举个例子:你今天没化妆、明天戴了眼镜,FaceNet提取的128维向量,核心数字不会变;而ArcFace还能区分出“你戴的是黑框眼镜”和“别人戴的是无框眼镜”,进一步降低误判率。
3. 第三步:特征匹配——比对“数字身份证”是否一致
最后一步就是“比对特征”:把实时提取的“数字向量”,和数据库里存的你的向量做对比,判断是不是同一个人。
常用的比对方法是计算“欧氏距离”——简单说就是算两个向量之间的“直线距离”:距离越小,相似度越高;距离越大,相似度越低。
实际应用中会设定一个“阈值”(比如0.8):
- 如果两个向量的距离<0.8,就判定“匹配成功”,闸机开门、支付完成;
- 如果距离>0.8,就判定“匹配失败”,会提示你重新刷脸,或者用密码、验证码辅助验证。
这里有个细节:不同场景的阈值会调整。比如地铁闸机更看重“速度”,阈值可能设得宽松一点(比如0.85),避免频繁卡顿;而刷脸支付更看重“安全”,阈值会设得严格(比如0.75),哪怕多让用户刷一次,也要减少盗刷风险。

alt text
三、从实际场景看:不同设备的技术适配逻辑
同样是人脸识别,刷脸支付和地铁闸机的技术选择其实不一样——核心是“场景需求决定技术方案”。
1. 刷脸支付:安全优先,多模型协同
以支付宝、微信支付为例,它们的核心需求是“不能认错人,更不能被照片、视频欺骗”,所以技术上有三个关键点:
- 用RetinaFace+ArcFace组合:RetinaFace确保在各种光线、遮挡(比如戴口罩)下都能准确检测人脸;ArcFace提取的特征向量区分度更高,减少和他人的“混淆概率”;
- 加入“活体检测”:比如让用户眨眨眼、张张嘴,或者用红外镜头捕捉人脸的温度分布(照片没有温度),防止假体攻击;
- 多模型投票:不是靠一个模型判断,而是同时调用3-5个不同结构的模型,只有多数模型都判定“匹配”,才会通过验证。
2. 地铁闸机:速度优先,模型轻量化
地铁闸机的核心需求是“快”——早高峰时每秒可能要处理2-3个人,而且闸机里的硬件算力有限,不能用太复杂的模型。所以技术上会做“轻量化优化”:
- 用YOLO(实时目标检测模型)做人脸检测:YOLO的特点是“一次性扫完画面,直接定位人脸”,比MTCNN快30%以上,适合高并发场景;
- 模型“剪枝+量化”:把ArcFace这类复杂模型“精简”——比如删掉不重要的神经网络连接(剪枝),把32位的数字换成8位(量化),这样模型体积变小,计算速度变快,在闸机的嵌入式设备上也能流畅运行;
- 降低特征维度:把512维的特征向量压缩到64维,虽然精度略有下降,但比对速度能提升8倍,完全满足地铁“快过闸”的需求。
四、工业界的技术优化:让模型更“能打”
真实场景比实验室复杂得多——比如工地的人脸识别要应对粉尘、强光,小区门禁要处理老人的皱纹、小孩的成长变化。为了让模型更“能打”,工程师会做这些优化:
1. 模型轻量化:在小设备上跑起来
很多场景的硬件算力有限(比如智能门锁、老旧闸机),这时候会用两种方法:
- 剪枝:像修剪树枝一样,删掉模型里“作用小”的神经元和连接,比如把原本1000个神经元的网络,精简到500个,计算量直接减半;
- 量化:把模型里的“高精度数字”换成“低精度”,比如从32位浮点数(能表示小数)换成8位整数,存储体积缩小4倍,计算速度提升3倍以上。
2. 数据增强:让模型“见多识广”
模型的识别能力,取决于它“见过多少场景”。工程师会用GAN(生成对抗网络) 生成大量“模拟数据”:比如把正常人脸照片改成逆光、侧光、模糊的版本,或者生成戴口罩、戴帽子的合成人脸,让模型在训练时“见多识广”,遇到真实场景的复杂情况也能应对。
3. 多模型融合:降低误判率
对精度要求极高的场景(比如金融开户),会用“多模型融合”:比如同时用FaceNet、ArcFace、EfficientNet三种模型提取特征,再用“加权投票”的方式判断——如果两种模型说“匹配”,一种说“不匹配”,就按多数结果来,这样误判率能降低到百万分之一以下。
现在的人脸识别,已不是“对比照片”的初级阶段,而是以CNN为核心,MTCNN/RetinaFace做检测,FaceNet/ArcFace做特征提取的完整技术体系。它之所以能在支付、交通、政务等场景普及,核心是深度学习解决了传统技术的“死板”问题——既能应对复杂环境,又能平衡精度和速度。
未来随着模型进一步轻量化、隐私保护技术(比如联邦学习,不用收集原始人脸数据就能训练模型)的发展,人脸识别可能会渗透到更多场景:比如医院的病历调取、校园的宿舍门禁,甚至景区的票务核验。技术的核心始终是“为人服务”,而搞懂这些背后的逻辑,也能让我们更理性地看待这项技术。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号