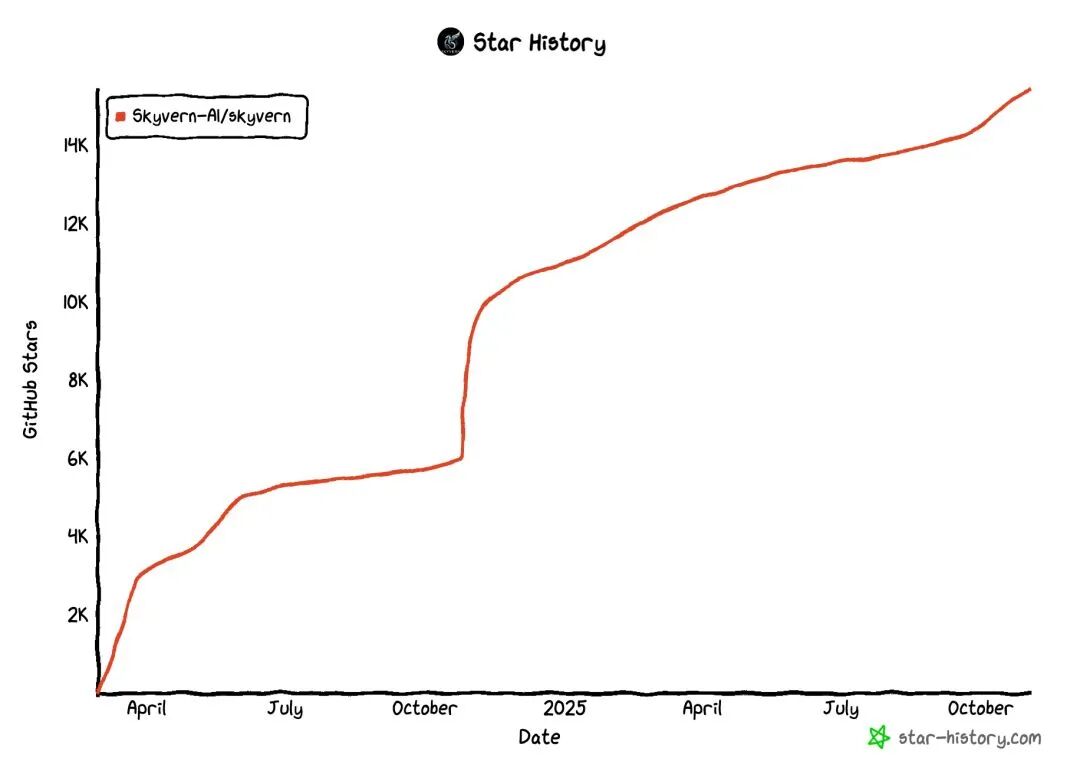
GitHub 狂揽 15000+ Star!这个 AI 浏览器自动化项目火了

GitHub 狂揽 15000+ Star!这个 AI 浏览器自动化项目火了

搜罗万相
发布于 2026-03-26 19:02:09
发布于 2026-03-26 19:02:09
浏览器自动化的新纪元
在 Web 自动化领域,开发者们长期面临着一个令人头疼的问题:精心编写的自动化脚本往往因为网页改版而突然失效。每当目标网站调整页面结构,我们就不得不重新定位元素、修改代码、反复测试,这种维护工作既耗时又令人沮丧。
而现在,一个名为 Skyvern 的开源项目正在改变这一现状。这个在 GitHub 上获得超过 15000 Star 的自动化浏览器工具,通过引入 AI 技术,为浏览器自动化带来了全新的解决方案。
传统方案的困境
传统的浏览器自动化工具(如 Selenium)依赖于精确的元素定位器——XPath、CSS 选择器等。开发者需要仔细分析页面结构,为每个需要操作的元素编写定位规则。这种方式虽然成熟稳定,但存在明显的脆弱性:
- 网站改版后,元素位置和属性发生变化,脚本立即失效
- 不同网站的结构差异大,难以编写通用脚本
- 动态加载和复杂交互增加了定位难度
- 维护成本随着目标网站数量线性增长
这些痛点促使开发者寻找更智能、更具适应性的解决方案。
Skyvern 的创新之处
基于视觉的智能理解
Skyvern 最大的创新在于,它不再依赖固定的元素选择器,而是利用多模态大语言模型(如 Gemini)来理解页面内容。
具体来说,Skyvern 会"看到"整个页面的截图,然后通过 AI 模型识别和理解页面上的各种元素——哪里是按钮、哪里是输入框、需要点击哪里、应该填写什么内容。这种视觉理解能力让它能够像人一样与网页交互,而不是机械地执行预设指令。
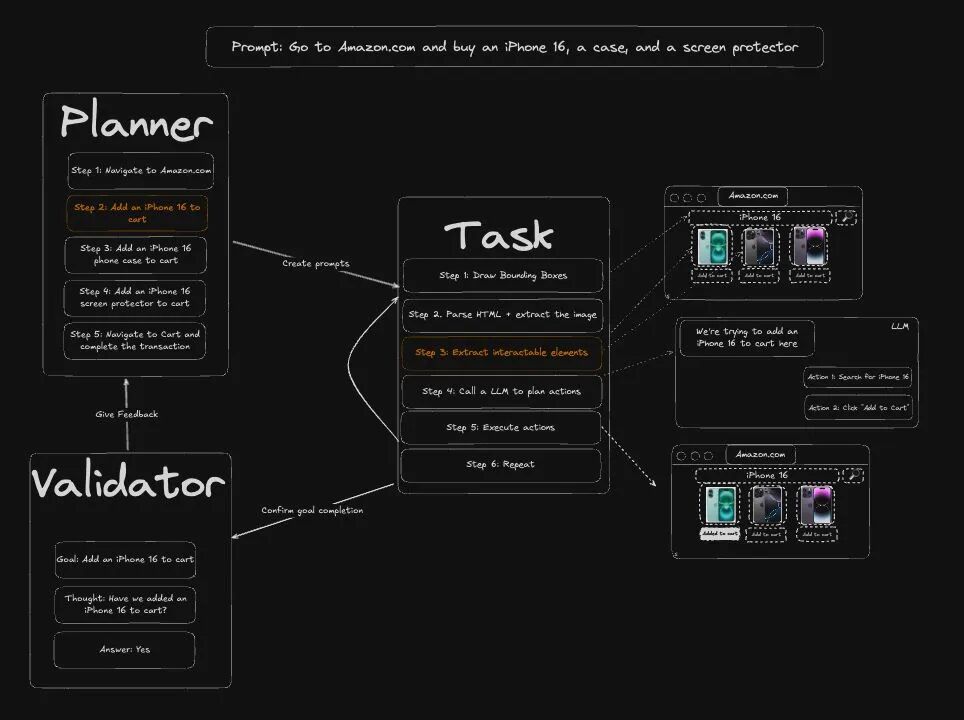
这种方式的优势显而易见:即使网站进行改版,只要页面的视觉布局和交互逻辑大致相同,Skyvern 就能继续正常工作,无需修改代码。
智能逻辑推理能力
除了视觉识别,Skyvern 还具备强大的逻辑推理能力。它能够理解表单问题的含义,并根据已有信息做出合理判断。
举个实际例子:在填写汽车保险报价表单时,遇到"你 18 岁时就有驾照了吗?“这样的问题。如果提供的信息显示用户 16 岁就获得了驾照,Skyvern 能够推理出答案应该是"是”,并自动完成填写。
这种上下文理解和推理能力使得 Skyvern 能够处理复杂的业务场景,大大减少了人工干预的需要。

核心功能特性
自动代码生成与维护
Skyvern 在首次执行任务时会自动生成 Playwright 代码。后续运行时直接使用这些代码,显著提升执行速度并降低 API 调用成本。更令人印象深刻的是,如果检测到网页发生变化,它能够自动重新识别内容并修复代码,实现真正的自适应维护。
完善的认证支持
安全性方面,Skyvern 支持多种主流的身份验证方式:
- 基于二维码的双因素认证
- 短信验证码
- 邮箱验证码
- 主流密码管理器集成
这使得它能够处理需要登录的复杂场景,满足企业级应用的安全要求。
实时监控与调试
Skyvern 提供了实时查看功能,让开发者可以观察浏览器的每个操作步骤。每个操作都有对应的截图记录,这对于调试和问题排查非常有帮助。
灵活的数据提取
它能够严格按照指定格式提取网页数据,支持 JSON、CSV 等多种输出格式,满足不同的数据处理需求。

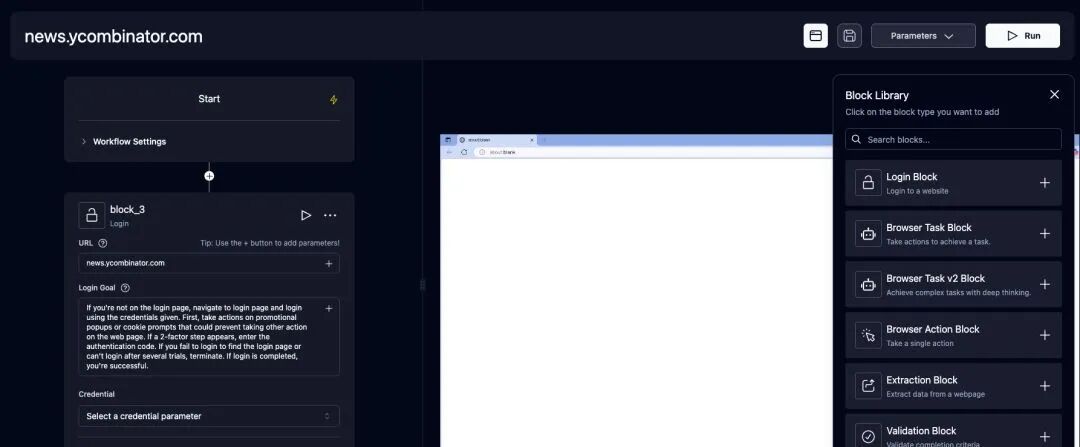
快速上手指南
Skyvern 提供了云服务和自部署两种使用方式。对于初学者,可以直接使用官方云服务快速体验(提供 5 美元免费额度)。而对于开发者,推荐自行部署开源版本,以便更好地控制成本和接入自己的大模型。
安装步骤
自部署的安装过程非常简单:
- 环境准备:确保系统已安装 Python 3.11 以上版本和 Docker
- 安装 Skyvern:
pip install skyvern - 初始化配置:
skyvern quickstart - 启动服务:
skyvern run all 启动成功后,通过浏览器访问 http://localhost:8080 即可开始使用。
API 调用
除了 Web 界面,Skyvern 还提供了 Python API,只需几行代码就能完成自动化任务的调用,非常适合集成到现有系统中。
应用场景
Skyvern 特别适合以下场景:
- 重复性数据采集:定期从多个网站收集价格、库存等信息
- 批量表单填写:自动化处理大量在线表单提交
- 文档下载:定期下载发票、报告等文件
- 跨平台操作:在多个不同结构的网站上执行类似操作
- 监控与测试:持续监控网站功能和性能
注意事项
在使用 Skyvern 时需要注意:
成本考虑:由于依赖大语言模型,每次任务执行都会产生 API 调用费用。对于高频任务,建议评估成本效益,或考虑使用代码缓存功能降低调用频率。
准确性:虽然 AI 理解能力强大,但在特别复杂或不规范的页面上可能出现误判。建议在正式使用前充分测试,并设置适当的错误处理机制。
合规性:自动化操作时要遵守目标网站的使用条款和相关法律法规,避免对服务器造成过大负担。
最后说一下
Skyvern 代表了浏览器自动化技术的新方向,它用 AI 的智能理解替代了传统的硬编码方式,极大地提高了自动化脚本的适应性和维护性。对于那些长期被脚本维护问题困扰的开发者和企业来说,这无疑是一个值得尝试的解决方案。
随着多模态大语言模型技术的不断成熟和成本的逐步下降,这种 AI 驱动的自动化方式很可能成为未来的主流。如果你的工作涉及大量重复性的网页操作,不妨给 Skyvern 一个机会,或许它能为你节省大量时间和精力。
项目地址:https://github.com/Skyvern-AI/skyvern
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号