基于概率匹配思想修复AI降水预报短板



谁没被天气预报坑过?说要下暴雨,结果只飘了几滴毛毛雨;说只是小雨,出门没带伞直接淋成落汤鸡 —— 这锅,统计学习模型得背一半!
目前,基于深度学习的人工智能方法正在降水预报领域扮演着越来越关键的角色,尤其是针对数小时内的临近预报和未来一天的短时预报。这类模型能够基于海量的雷达、卫星等观测数据学习降水模式,预报降水的落区、强度和演变。然而,这类模型均存在一个难以突破的瓶颈,即对极端强降水事件的预报能力往往不尽如人意,其预报结果常常出现降水强度系统性偏弱、空间结构随预报时长增加快速平滑的特征。
究其根源,问题很大程度上出现在模型训练的“指挥棒”,即损失函数的设计。目前,绝大多数深度学习降水预报模型都采用均方误差 (MSE) 作为损失函数。它的计算方法是:将预报降水场和观测降水场中每一个处于相同位置的降水值进行对比,计算所有区域降水值差异的平均平方和。模型的训练目标则是最小化这个整体误差。
然而,正是这种“逐点严格对比”的评判原则,导致了著名的 “双重惩罚” 问题。可以这样理解:假设模型已经正确地预报到某个区域将发生一场暴雨,但它预报的暴雨中心位置,与实际发生的中心点偏移了几公里。在 MSE 的评判体系下,它会遭受两次惩罚:一次是因为在真实的暴雨中心位置上没有报出足够的雨量 (漏报),另一次是因为在它自己预报的位置上报出了实际并不存在的暴雨 (空报)。这种“答对了内容,但答错了位置也要扣分”的苛刻标准,迫使模型在学习过程中变得极其“保守”。于是,模型会倾向于给出一个平滑化、接近气候平均状态的预报图:刻意压低强降水的峰值,同时可能夸大弱降水的范围 (如图1a)。因此,降水预报中最关键、最具致灾风险的强降水信号被显著弱化,预报价值下降。
为了克服这个问题,我们能否换一种完全不同的思路来“指导”深度学习的预报呢?本研究的核心创新,正是从 “位置依赖”这一根本点出发,探索了一种与位置无关的解决方案。我们提出了一个简洁且高效的深度学习损失函数缓解这个问题——概率匹配损失函数 (PM loss)。PM loss弱化了传统方法中强迫预报场与观测场在空间位置上严格对齐的范式。它不仅要考虑相同坐标点的降水值差异,还要考虑两者在整体强度“排名”上的一致性。 在训练模型时,它的具体实现分为三步 (图1b):
第一步:全局排序。对于任意预报时长的预报场和对应的观测场,分别将图中所有坐标点的降水值取出,按照从大到小的顺序进行独立排序,得到两条与坐标点位置无关的“降水值序列”。
第二步:顺序匹配。让预报场排序后的降水值序列,尽可能地接近观测场排序后的降水值序列。即只关注预报场中的“最大值”是否接近观测场的“最大值”,“次大值”是否接近“次大值”,依此类推。
第三步:与传统方法组合。将顺序匹配后计算的差异值和传统均方误差损失函数进行加权平均,得到PM loss。
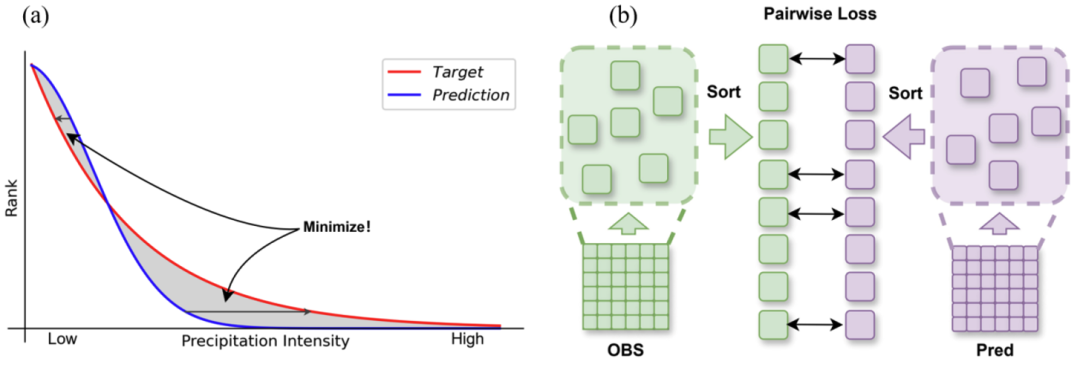
图1 (a) 概率匹配损失函数的优化目标;(b)概率匹配损失函数的计算示意图。
这种方法能够使模型不再因为把暴雨中心预报偏了几公里而遭受重罚,它可以将一部分“注意力”集中在如何准确地把握降水场的强度分布特征上。即预报结果中的强、中、弱各级别降水的出现比例和强度档次与实际情况吻合,也能获得良好的评价。
为了验证 PM loss 的有效性,我们在两个预报场景上进行了验证:一是利用覆盖我国华东地区的多源数据 (以雷达反射率为降水指示量,辅以卫星和 ERA5 再分析数据) 进行未来12小时、逐小时的短时降水预报;二是利用公开的风暴数据集 (SEVIR) 在更精细的时间尺度上进行未来1小时、逐5分钟的临近降水预报。
试验结果充分展示了 PM loss 的优越性,具体包括以下几点:
(1) 强降水预报能力显著改善 (图2):使用 PM loss 训练的模型,对于强降水阈值的预报技巧得到了实质性提升。该模型的CSI评分相比于使用传统MSE损失函数训练的模型有一定增加,表明模型“捕捉”致灾性强降水的能力更强了。此外,BIAS评分也更加接近于1,表明PM loss显著降低了模型的降水负偏差。
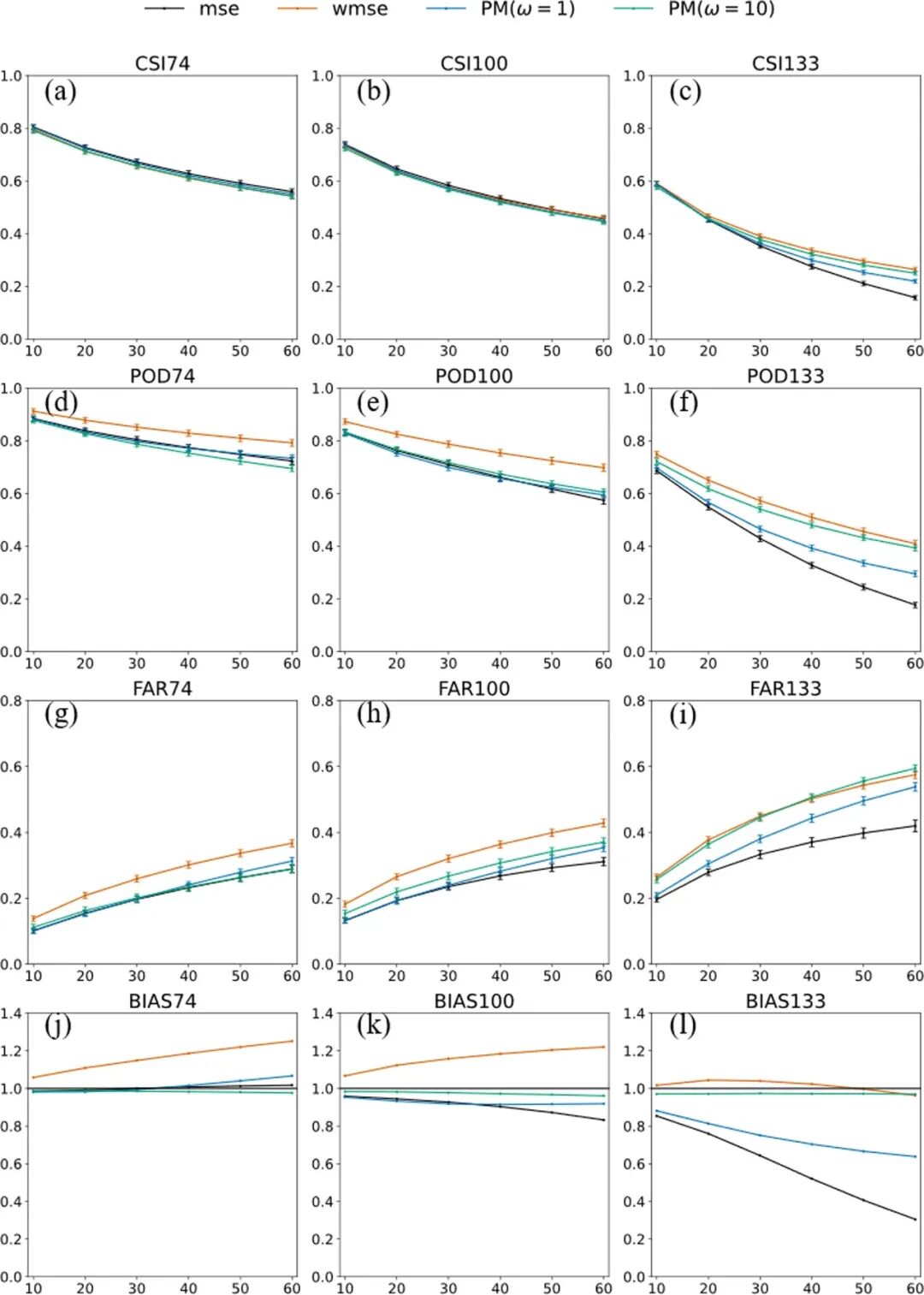
图2 采用均方误差(mse)、加权均方误差 (wmse) 与概率匹配 (PM) 损失函数所训练的ConvLSTM模型在不同降水强度对应像素值 (74、100、133) 下的一小时降水临近预报定量评估。(a-c)、(d-f)、(g-i)、(j-l) 分别对应CSI、POD、FAR及BIAS评分,误差棒表示置信区间。像素值74、100、133分别对应0.78、1.51和3.53 kg/m²的降水强度。
(2) 降水强度分布匹配更完美 (图3):使用PM loss训练的模型所预报出的不同强度降水的发生频率分布与真实观测的分布曲线吻合更好。它成功纠正了传统模型 “弱降水报得多、强降水报得少” 的系统性偏差,使得预报的降水概率分布更加真实可信。
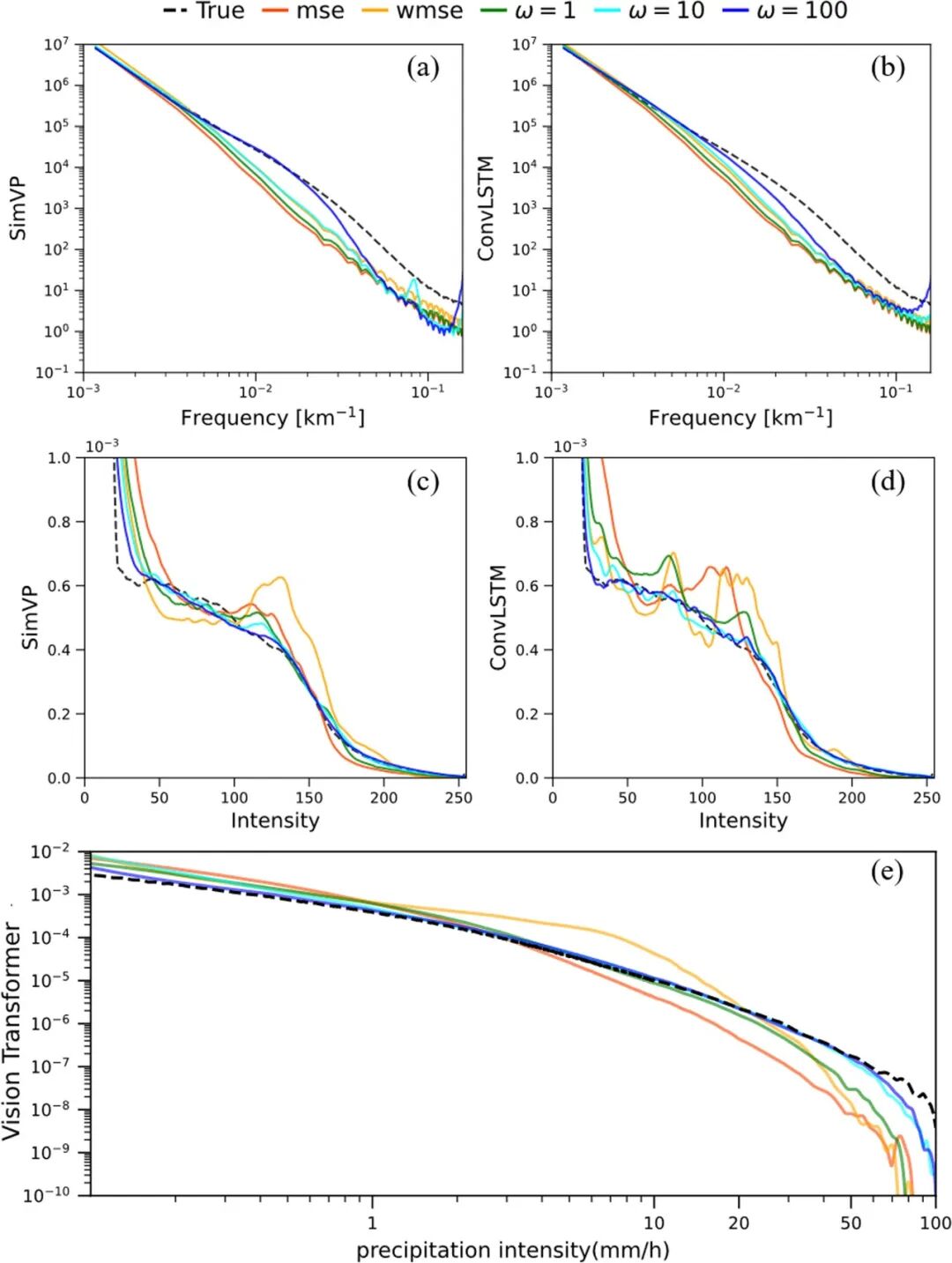
图3 基于均方误差 (mse)、加权均方误差 (wmse) 与概率匹配 (PM) 损失函数训练的机器学习模型针对降水临近预报 (提前1h) 的 (a, b) 功率谱密度与 (c, d) 频率分布。(e) 降水短期预报(提前12h)的频率分布。黑色虚线表示观测数据,红色与橙色实线分别代表基于mse与wmse的模型;绿色、青色与蓝色实线依次对应权重因子为1、10、100的基于PM的模型。
(3) 不同强度降水的预报改善更均衡:尤为重要的是,PM loss 在提升强降水预报性能的同时,并未降低模型对小雨、中雨等常见天气情形的预报能力,体现了其良好的平衡性。
(4) 降水空间结构更合理:以图4中的一次强降水预报评估为例,使用PM loss训练的模型表现出一种“纠偏”特性:它会增强那些原本预报偏弱的降水信号,同时抑制那些预报偏强的信号,从而使得整体的预报场在强度分布上更逼近观测。

图4 基于均方误差 (mse)、加权均方误差 (wmse) 与概率匹配 (PM) 损失函数所训练的ConvLSTM模型一次个例1h降水临近预报中的对比。第1行是观测 (truth);第2行是基于mse的预报;第3行是基于wmse的预报;第4–6行表示权重因子分别为1、10、100的基于PM的预报。色卡的黑色与蓝色标注分别对应像素单位与降水强度 (kg/m²)。
综上所述,本研究提出的“位置无关”的 PM loss 函数,通过绕过 “双重惩罚” 这一根本性障碍,有效缓解了深度学习模型在极端强降水预报中系统性偏弱的问题。此外,该损失函数的提出不仅为优化降水预报模型提供了全新的技术思路,其 “概率分布匹配”而非“位置匹配” 的核心思想,也可以为深度学习模型在其他具有间歇性、空间不均匀性特征的天气要素 (如冰雹、大雾、雷暴大风) 预报中的应用提供启发。
上述研究工作已在12月16日发表在地学权威期刊《Geophysical Research Letters》上,第一作者为上海市气象局中心气象台/上海市人工智能气象应用创新中心曹原工程师与复旦大学李帅毅硕士研究生,通讯作者为复旦大学冯杰研究员,文章合作者还包括上海市气象局中心气象台陈磊高级工程师、复旦大学张义军教授、复旦大学人工智能创新与产业研究院李昊研究员等。
论文信息 >
作者简介 >

第一作者:曹原,上海中心气象台, 上海市人工智能气象应用创新中心, 工程师。AI天气预报团队负责人,负责 “雨师”、“扶摇” 等AI气象预报模型研发,上海市气象局“青年气象英才”。2023年获复旦大学计算机博士学位,研究方向聚焦AI天气预报方法、极端天气小样本问题、ML-NWP耦合优化问题。在气象领域国际期刊、AI领域国际学术会议发表论文十余篇,发明专利一项。我们具有一线气象+AI数据、算力和业务应用与探索场景,现招聘实习生 (可远程) ,简历投递:caoy16@fudan.edu.cn。

共一作者:李帅毅,复旦大学大气与海洋科学系,硕士研究生;研究方向:强对流天气短临预报。

通讯作者:冯杰,复旦大学大气与海洋科学系,研究员;研究方向:数值天气预报,集合预报,资料同化。
END
声明:欢迎转载、转发。气象学家公众号转载信息旨在传播交流,其内容由作者负责,不代表本号观点。文中部分图片来源于网络,如涉及内容、版权和其他问题,请联系小编处理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号