全球第一Kaggle选手开源:最新量化赛事方案!


Datawhale干货 作者:周远哲,Kaggle全球排名第一
作者是 Kaggle 目前全球排名第一选手,获得多个大规模量化竞赛的 top3,专注于时序预测、量化建模领域。
Kaggle量化赛事:三井商品预测挑战赛
Kaggle是全球最大的数据科学竞赛平台。本次由日本三井物产主办的商品预测挑战赛,聚焦大宗商品贸易领域的核心需求——多市场价差序列预测。
参赛者需基于LME(伦敦金属交易所)、JPX(日本交易所)等全球市场的金属、能源及外汇数据,构建能够应对时区差异、政策突变等复杂场景的时序预测模型。竞赛采用改进的夏普比率作为评估指标,直接对标实际交易中的风险调整后收益要求。
为什么选择开源这个方案? 由于三井竞赛数据复杂、评估指标特殊,目前论坛中尚未出现一个leak-free、可复现、结构清晰的baseline。本文提供一套由 Kaggle 全球排名第一选手开源的完整解决方案,旨在为参赛者提供一个可靠的起点。
赛事地址:https://www.kaggle.com/competitions/mitsui-commodity-prediction-challenge
完整代码地址:https://www.kaggle.com/code/yuanzhezhou/mitsui-co-baseline-train-infer
完整的量化解决方案
📊 数据分析
1. 输入数据
提供的数据覆盖了全球4市场多品种的标准化原始指标,分别来自于 “金属、期货、美股 / ETF、外汇”
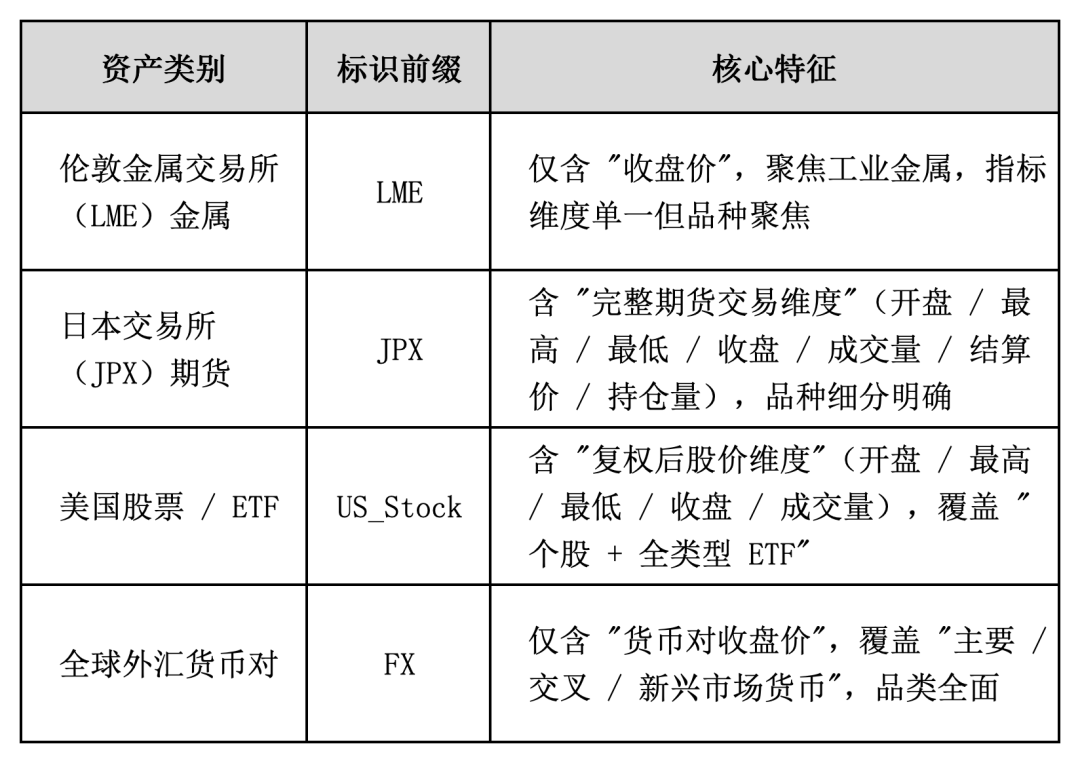
1)LME(伦敦金属交易所)
包含四个核心的工业金属品种,分别为
- AH(铝)
- CA(铜,LME 核心工业金属)
- PB(铅)
- ZS(锌)
提供的数据指标仅包含收盘价. 这是因为金属市场的核心需求就是 “权威定价基准”,收盘价是唯一能满足全产业链(贸易、套期保值、分析)的核心指标.
2)JPX(日本交易所集团)
数据指标上提供了
- Open(开盘价)、High(最高价)、Low(最低价)、Close(收盘价):经典 “OHLC” 价格维度
- Volume(成交量):当日交易总量,反映市场活跃度
- settlement_price(结算价):期货特有维度,用于当日盈亏计算和持仓估值
- open_interest(持仓量):未平仓合约数,反映市场多空情绪和资金规模
交易的品种分别为
- 贵金属期货:黄金(Mini 迷你 / Rolling-Spot 连续现货 / Standard 标准)、铂金(Mini/ Standard)
- 工业商品期货:RSS3 橡胶期货(天然橡胶主流品种)
其中的 mini 可以视为 standard 的缩小版本,可以以更小的单位与门槛进行交易.
3)US_Stock
提供的数据为复权后的数据,数据指标上提供了
- adj_open(复权开盘价)、adj_high(复权最高价)、adj_low(复权最低价)、adj_close(复权收盘价)
- adj_volume(成交量,无需复权,反映交易活跃度)
资产覆盖的范围非常广,涵盖 “宽基指数 ETF、行业 ETF、商品 ETF、债券 ETF、个股、杠杆 ETF”
- 宽基 / 区域 ETF:ACWI(全球股票)、VT(全球股票)、VEA(发达市场除美)、VWO(新兴市场)
- 商品 ETF:GLD(黄金)、SLV(白银)、GDX(黄金矿业)、NUGT(3 倍做多黄金矿业,杠杆 ETF)
- 债券 ETF:AGG(美国总债)、BND(美国国债)、BNDX(国际国债)、TIP(通胀保值债券)
- 行业个股:能源(CVX 雪佛龙、EOG)、矿业(RIO 力拓、VALE 淡水河谷)、金融(TD 道明银行、MS 摩根士丹利)、工业(CAT 卡特彼勒)
- 杠杆 / 主题 ETF:YINN(3 倍做多中国指数)、URA(铀矿主题)
4)FX 外汇
仅包含收盘价
2. 标签
共有424个标签,分为4组. 每组106个标签分别预测1,2,3,4天的不同交易品的收益率的差值. 这里的收益率通过以下公式计算得到
这里的差值包含了
- 跨类别差值:LME_PB_Close(金属铅) - US_Stock_VT_adj_close(美股ETF)(金属 vs 股票)、JPX_Gold_Standard_Futures_Close(黄金期货) - FX_USDJPY(外汇)(期货 vs 外汇);
- 同类别差值:LME_CA_Close(铜) - LME_ZS_Close(锌)(金属内部价差)
3. 总结
主办方提供了不同品种的交易品,试图预测不同周期以及不同品种间的相对收益来构建一个更稳定的资产组合. 在全球化的背景下,通过对冲来自于不同交易品的风险,我们可以构建单位风险下收益率更高的投资组合。
🔧 数据预处理
由于不同的数据的覆盖度不同,我们这里把所有的数据整理到相同的格式(OHLCV...)然后统一进行特征工程. 这里的预处理代码主要由大模型生成
import pandas as pd
import warnings
import os
warnings.filterwarnings("ignore", message="DeprecationWarning")
warnings.filterwarnings("ignore", message="See the caveats")
# 屏蔽特定的 FutureWarning
warnings.filterwarnings(
'ignore',
category=FutureWarning,
message="The behavior of DataFrame concatenation with empty or all-NA entries is deprecated."
)
def preprocess(df):
df = df.copy()
df = df.rename(columns={'date_id': 'date'})
# 创建空的结果 DataFrame
result = pd.DataFrame(columns=['date', 'id', 'close', 'open', 'high', 'low', 'volume', 'sprice', 'interest'])
# 处理 LME 数据
lme_metals = ['AH', 'CA', 'PB', 'ZS']
for metal in lme_metals:
temp_df = pd.DataFrame()
temp_df['date'] = df['date']
temp_df['id'] = f'LME_{metal}'
temp_df['close'] = df[f'LME_{metal}_Close']
# LME 数据没有其他字段,设置为 NaN
temp_df['open'] = None
temp_df['high'] = None
temp_df['low'] = None
temp_df['volume'] = None
temp_df['sprice'] = None
temp_df['interest'] = None
result = pd.concat([result, temp_df], ignore_index=True)
# 处理 JPX 期货数据
jpx_products = {
'Gold_Mini': ['Open', 'High', 'Low', 'Close', 'Volume', 'settlement_price', 'open_interest'],
'Gold_Rolling-Spot': ['Open', 'High', 'Low', 'Close', 'Volume', 'settlement_price', 'open_interest'],
'Gold_Standard': ['Open', 'High', 'Low', 'Close', 'Volume', 'open_interest'],
'Platinum_Mini': ['Open', 'High', 'Low', 'Close', 'Volume', 'settlement_price', 'open_interest'],
'Platinum_Standard': ['Open', 'High', 'Low', 'Close', 'Volume', 'open_interest'],
'RSS3_Rubber': ['Open', 'High', 'Low', 'Close', 'Volume', 'settlement_price', 'open_interest']
}
for product, columns in jpx_products.items():
temp_df = pd.DataFrame()
temp_df['date'] = df['date']
temp_df['id'] = f'JPX_{product}'
if'Close'in columns:
temp_df['close'] = df[f'JPX_{product}_Futures_Close']
if'Open'in columns:
temp_df['open'] = df[f'JPX_{product}_Futures_Open']
if'High'in columns:
temp_df['high'] = df[f'JPX_{product}_Futures_High']
if'Low'in columns:
temp_df['low'] = df[f'JPX_{product}_Futures_Low']
if'Volume'in columns:
temp_df['volume'] = df[f'JPX_{product}_Futures_Volume']
if'settlement_price'in columns:
temp_df['sprice'] = df[f'JPX_{product}_Futures_settlement_price']
if'open_interest'in columns:
temp_df['interest'] = df[f'JPX_{product}_Futures_open_interest']
result = pd.concat([result, temp_df], ignore_index=True)
# 处理 US Stock 数据
us_stocks = [
'ACWI', 'AEM', 'AG', 'AGG', 'ALB', 'AMP', 'BCS', 'BKR', 'BND', 'BNDX',
'BP', 'BSV', 'CAT', 'CCJ', 'CLF', 'COP', 'CVE', 'CVX', 'DE', 'DVN',
'EEM', 'EFA', 'EMB', 'ENB', 'EOG', 'EWJ', 'EWT', 'EWY', 'EWZ', 'FCX',
'FNV', 'FXI', 'GDX', 'GDXJ', 'GLD', 'GOLD', 'HAL', 'HES', 'HL', 'IAU',
'IEF', 'IEMG', 'IGSB', 'JNK', 'KGC', 'KMI', 'LQD', 'LYB', 'MBB', 'MPC',
'MS', 'NEM', 'NUE', 'NUGT', 'OIH', 'OKE', 'OXY', 'PAAS', 'RIO', 'RSP',
'RY', 'SCCO', 'SHEL', 'SHY', 'SLB', 'SLV', 'SPIB', 'SPTL', 'SPYV', 'STLD',
'TD', 'TECK', 'TIP', 'TRGP', 'URA', 'VALE', 'VCIT', 'VCSH', 'VEA', 'VGIT',
'VGK', 'VGLT', 'VGSH', 'VT', 'VTV', 'VWO', 'VXUS', 'VYM', 'WMB', 'WPM',
'X', 'XLB', 'XLE', 'XOM', 'YINN'
]
for stock in us_stocks:
temp_df = pd.DataFrame()
temp_df['date'] = df['date']
temp_df['id'] = f'US_Stock_{stock}'
temp_df['close'] = df[f'US_Stock_{stock}_adj_close']
temp_df['open'] = df[f'US_Stock_{stock}_adj_open']
temp_df['high'] = df[f'US_Stock_{stock}_adj_high']
temp_df['low'] = df[f'US_Stock_{stock}_adj_low']
temp_df['volume'] = df[f'US_Stock_{stock}_adj_volume']
# US Stock 数据没有 sprice 和 interest,设置为 NaN
temp_df['sprice'] = None
temp_df['interest'] = None
result = pd.concat([result, temp_df], ignore_index=True)
# 处理 FX 数据
fx_pairs = [
'AUDJPY', 'AUDUSD', 'CADJPY', 'CHFJPY', 'EURAUD', 'EURGBP', 'EURJPY',
'EURUSD', 'GBPAUD', 'GBPJPY', 'GBPUSD', 'NZDJPY', 'NZDUSD', 'USDCHF',
'USDJPY', 'ZARJPY', 'ZARUSD', 'NOKUSD', 'NOKEUR', 'CADUSD', 'AUDNZD',
'EURCHF', 'EURCAD', 'AUDCAD', 'GBPCHF', 'EURNZD', 'AUDCHF', 'GBPNZD',
'GBPCAD', 'CADCHF', 'NZDCAD', 'NZDCHF', 'ZAREUR', 'NOKGBP', 'NOKCHF',
'ZARCHF', 'NOKJPY', 'ZARGBP'
]
for pair in fx_pairs:
temp_df = pd.DataFrame()
temp_df['date'] = df['date']
temp_df['id'] = f'FX_{pair}'
temp_df['close'] = df[f'FX_{pair}']
# FX 数据只有收盘价,其他字段设置为 NaN
temp_df['open'] = None
temp_df['high'] = None
temp_df['low'] = None
temp_df['volume'] = None
temp_df['sprice'] = None
temp_df['interest'] = None
result = pd.concat([result, temp_df], ignore_index=True)
# 重置索引
result = result.reset_index(drop=True)
return result
class CFG:
if os.path.exists('./mitsui-commodity-prediction-challenge'):
input_path = './mitsui-commodity-prediction-challenge/'
else:
input_path = '/kaggle/input/mitsui-commodity-prediction-challenge/'
config = CFG()
df = pd.read_csv(f'{config.input_path}/train.csv')
df_processed = preprocess(df)
⚙️ 建模
这里我们用三种不同的简单思路的进行建模,并且提供最终的模型以及模型融合的提交代码. 这里用到的三种不同建模方式分别为:
- 利用树模型同时对所有标签进行多目标预测
- 利用树模型预测单个品种收益率,然后求差值
- 利用树模型预测不同品种对收益率的差值
1. 评价指标
metric函数首先计算了每一日的 秩相关(斯皮尔曼),接着再计算了这个相关系数的夏普比率(假设无风险利率为0)用来衡量模型的稳定盈利能力.
2. 特征工程
我们构建了一些基础的特征,包含了一些价格之间的比值, 技术指标以及历史统计量
import pandas as pd
import numpy as np
def create_features(df, windows=[5, 10, 20], ):
# 确保数据按日期排序
df = df.sort_values(['id', 'date']).reset_index(drop=True)
# 按资产分组处理
grouped = df.groupby('id')
features_list = []
for asset_id, group in grouped:
group = group.copy()
for col1 in ['close', 'open', 'high', 'low']:
for col2 in ['close', 'open', 'high', 'low']:
if col1>col2:
group[f'{col1}/{col2}'] = (group[col1]-group[col2]) / (group[col1]+group[col2])
group['open/close_shift1'] = group['open']/group['close'].shift(1)
for window in windows:
group[f'ret_{window}'] = group['close']/group['close'].shift(window) - 1
group[f'vol_{window}'] = (group['close']/group['close'].shift(1) - 1).rolling(window).std()
group[f'volume_{window}'] = group['volume'].rolling(window).mean()/group['volume'].rolling(window*2).mean()
group[f'technical1_{window}'] = (group['close'] > group['high'].ffill().shift(1)).astype('float') - (group['close'] < group['low'].ffill().shift(1)).astype('float')
group[f'technical2_{window}'] = (group['low'] > group['high'].ffill().shift(1)).astype('float') - (group['high'] < group['low'].ffill().shift(1)).astype('float')
# sprice和interest相关特征
if'sprice'in group.columns:
group['sprice_change'] = group['sprice']/group['sprice'].ffill().shift(1) - 1
group['premium_discount'] = (group['close'] - group['sprice']) / group['sprice']
if'interest'in group.columns:
group['volume_interest_ratio'] = group['volume'] / (group['interest'] + 1)
features_list.append(group)
# 合并所有资产的特征
features_df = pd.concat(features_list, ignore_index=True)
return features_df
df_features = create_features(df_processed)
df_features
3. 单个树模型
这里尝试一次对所有424个标签同时进行预测,我们利用catboost的MultiRMSE损失函数和gpu模式进行训练,训练速度还是很快的。完整代码参考baseline。
model = CatBoostRegressor(
loss_function='MultiRMSE', # 多输出回归
task_type='GPU', # GPU加速
reg_lambda=2000, # 强正则化
)
4. 单目标预测模型
我们预测的标签是收益率的价差,这里我们可以尝试先单独预测每一个品种的收益率,再取差值作为最终的预测值。
5. 价差预测模型
由于预测收益率后再求差的模型效果不是很理想,我们也可以尝试直接对收益率的差值进行预测。这里我们将不同样本对的特征进行拼接,然后预测每一个样本对对应的label。
🧩模型融合与提交
为了方便融合不同的模型,我们把不同的模型的方法抽象为
class BaseModel:
def preprocess(self, df): ...
def train(self, df): ...
def predict(self, df): ...
三个函数,用统一的格式来进行处理。这样具体的逻辑分别在不同的predict函数中实现,预测的时候只需要调用predict函数即可,这样可以让代码更整洁,鲁棒性更强。
总结与提升思路
这里我们通过统一的特征工程与建模,试图学习不同交易品种之间的共同特征,并且使用树模型进行不同思路上的建模。但是与此同时,也存在一些没有解决的问题。例如FX与LME的数据都只有close price,这个时候需要想办法尽可能充分利用close price所包含的信息;close price是经过一整天市场博弈后得到的结论,内部所包含的信息量是最多的。而USA数据中则包含了最广的市场覆盖度和最充分的信息,可以考虑如何充分利用这些信息来提升整体预测的效果。
下面给出一些进一步提升效果的思路:
- ⭐️⭐️⭐️特征工程增强: 尝试进行更多有效的特征工程
- ⭐️⭐️标签重构: 尝试改变训练标签,这里作为baseline简单进行了排序处理,应该存在更好的方案
- ⭐️⭐️模型多样性: 尝试使用神经网络等深度学习模型进行建模
- ⭐️预处理: 尝试进行更精细的数据预处理
- ⭐️⭐️⭐️验证策略优化: 进行更鲁棒性的交叉验证,这里我们只用了最后的N天作为验证集,这样会导致对于验证集时期的数据过拟合。比赛数据作为天级别的预测,样本点很少,模型很容易过拟合。
从竞赛到实战经验
在实际业务环境中,我们可以获得远比竞赛数据更丰富的信息源,以下是一些我们可以参考的信息:
- 基本面信息:
- 利率政策:美联储利率, ECB利率, BOJ利率
- 经济指标: GDP增长率, CPI通胀, 失业率, PMI
- 贸易数据: 进出口额, 贸易顺差/逆差
- 情绪指标: VIX恐慌指数, 消费者信心指数
- 产业链上下游数据
- 供给端:矿山产量、库存水平、运输数据
- 需求端:工业产出、制造业指数、季节性需求
- 物流数据:航运指数、港口吞吐量、仓储数据
- 另类数据源
- 卫星图像:监控原油库存、农田作物生长
- 网络舆情:社交媒体情绪、新闻事件影响
- 供应链数据:供应商信息、物流跟踪数据
- 高频数据的深度挖掘
- tick级交易数据:订单簿深度、交易冲击成本
- 市场微观结构:买卖价差、成交量分布、流动性指标
- 事件驱动特征:大宗交易、机构调仓、指数重构
延伸阅读
更多量化预测思路和竞赛技巧,欢迎访问我的博客: https://shorturl.at/LKhAD
END
声明:欢迎转载、转发。气象学家公众号转载信息旨在传播交流,其内容由作者负责,不代表本号观点。文中部分图片来源于网络,如涉及内容、版权和其他问题,请联系小编处理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号