大语言模型优化技术 - KL散度引导的智能量化

大语言模型优化技术 - KL散度引导的智能量化

mixlab
发布于 2026-03-24 20:38:47
发布于 2026-03-24 20:38:47
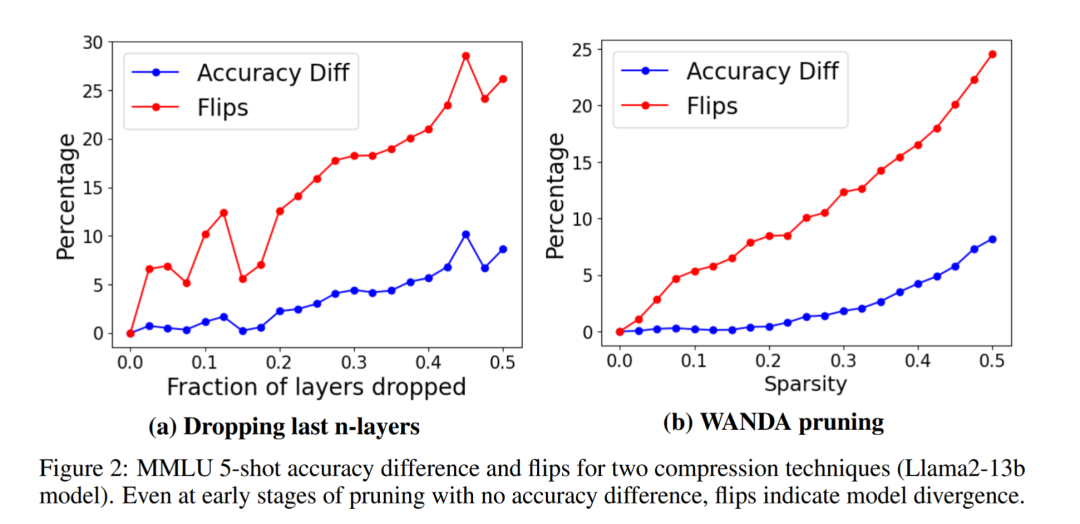
Rishiraj Acharya揭示当前LLM量化评估的盲区——仅关注MMLU分数会掩盖"答案翻转"现象(量化后模型对错答案互换但总分不变)。通过实验证明KL散度(KLD)与翻转率相关性高达0.97,提出分层量化策略:对低敏感层(如MoE专家矩阵)采用2比特激进压缩,对高敏感层(注意力机制)保留8比特精度。这种混合量化在减小模型体积的同时,通过KLD最小化保障模型行为一致性,比传统均匀量化更科学。
- **效率价值**:显著减少模型大小(从90GB压缩到25GB)同时保持性能
- **可访问性价值**:使先进AI模型能在消费级设备上运行
- **技术价值**:提供比传统均匀量化更优的压缩方法
- **创新价值**:建立了新的模型评估标准(KL散度 vs 传统准确率)
### 来源URL
https://huggingface.co/blog/rishiraj/kld-guided-quantization
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号