5.5K Star,中文首发!仿人类四层记忆网络,让 Agent 不再遗忘
原创
5.5K Star,中文首发!仿人类四层记忆网络,让 Agent 不再遗忘
原创
CoovallyAIHub
发布于 2026-03-24 16:26:57
发布于 2026-03-24 16:26:57
导读
为什么你的 Agent 总是"失忆"?你给它讲过一遍用户偏好,下次对话它又问一遍;你纠正了它的错误,过几轮它还是犯同样的问题。
这背后是当前 Agent 记忆方案的结构性缺陷。大多数方案要么把对话历史塞进上下文窗口,要么用 RAG 做语义检索——但这两种方式本质上都只是"存储+搜索",Agent 并没有从过去的交互中学到任何东西。
2026 年 1 月,Vectorize.io 开源了 Hindsight,一个专门为 Agent 设计的记忆系统。它的设计思路不是"更好的检索",而是模仿人类记忆的组织方式:把原始事实、亲身经历、归纳观察、策划摘要分层管理,让 Agent 能像人一样从经验中形成理解,而不只是背诵对话记录。在 LongMemEval 基准测试中,Hindsight 以 91.4% 的准确率达到了截至 2026 年 1 月公开报告的最高水平。
本文将从 Agent 记忆的现有问题出发,逐层拆解 Hindsight 的记忆架构和核心操作,并给出上手方式。

图片来源于 GitHub 社区
项目信息
- 项目: Hindsight — Agent Memory System
- 团队: Vectorize.io
- GitHub: https://github.com/vectorize-io/hindsight(5.5K+ Stars,MIT 协议)
- 官方文档: https://docs.hindsight.work
一、Agent 为什么会"遗忘"?RAG 和知识图谱不够用
当前主流的 Agent 记忆方案大致分三类:把对话历史塞进上下文窗口、用 RAG 做语义检索、或者构建知识图谱。这些方案各自有效,但在"让 Agent 持续学习"这个目标上,都存在明显的短板。
上下文窗口:贵且会丢信息
把所有对话历史塞进 prompt 是最简单的方案,但代价高昂——token 消耗随对话增长线性膨胀,而且模型对长上下文的注意力分配并不均匀,早期的重要信息容易被"淹没"。Hindsight 的博客引用了 LongMemEval 基准测试数据:使用 GPT-4o 做全上下文输入,准确率只有 60.2%;使用 20B 参数的开源模型,更是降到了 39.0%。
RAG:只有语义相似性这一条路
传统 RAG 通过向量相似度检索相关文档片段,但 Agent 记忆场景有几个 RAG 难以处理的需求:
维度 | RAG 的表现 | Agent 记忆的实际需求 |
|---|---|---|
检索策略 | 仅语义相似度 | 语义 + 关键词 + 实体关系 + 时间范围 |
时间推理 | 无法理解"上个月""去年春天" | 需要解析日期并做范围过滤 |
多跳推理 | 受限于检索到的片段 | 需要跨实体的关系链推理 |
状态管理 | 查询间无状态 | 需要跨 session 的持久化记忆 |
实体理解 | 无 | 需要实体识别、消歧和追踪 |
简单来说,RAG 是为"找文档"设计的,不是为"记住和学习"设计的。
知识图谱:静态且缺少推理层
知识图谱擅长存储结构化的实体-关系数据,但它的局限在于静态——图谱中的知识不会自己演化。Agent 与用户交互产生的偏好变化、行为模式,需要一个能自动归纳和更新理解的机制,而不只是往图谱里加节点。
Hindsight 的思路是:不替代 RAG 或知识图谱,而是在更高层面上重新组织 Agent 的记忆,让不同类型的知识进入不同的通道,用不同的方式管理和检索。
二、四层记忆网络:从原始事实到归纳理解
Hindsight 最核心的设计是它的记忆分层架构。项目 README 将其称为"仿生数据结构"(biomimetic data structures),意思是它模仿了人类记忆的组织方式——人不会把所有信息平铺存放,而是分层管理:底层是原始感知,上层是归纳理解。
Hindsight 将 Agent 的记忆组织为四种类型,按从底层到高层排列:
第一层:世界事实(World Facts)
定义:关于外部世界的客观信息。
示例:"Alice 在 Google 担任软件工程师""炉子会烫手"
世界事实是 Agent 接收到的关于人、地点、事物的基础信息。每条事实会经过实体识别和消歧处理——比如"Alice""Alice Chen""Alice C." 会被合并为同一个实体。
第二层:经验事实(Experience Facts)
定义:Agent 自身参与的对话和事件。
示例:"我向 Bob 推荐了 Python""我碰了炉子,很烫"
与世界事实不同,经验事实记录的是 Agent 亲身经历的交互,包含情感上下文和动机推理。例如,当输入"Alice 去年春天加入 Google,她对研究机会感到兴奋"时,系统不仅提取核心事实(谁、什么、何时),还会捕捉情感(兴奋)和动机(为了研究机会)。
第三层:观察(Observations)
定义:系统从多条原始事实中自动归纳出的模式和理解。
观察是 Hindsight 区别于其他记忆系统的关键层。它不是手动创建的,而是通过后台的自动整合引擎生成:在 retain() 操作完成后,系统自动将新事实与已有观察进行比对和综合。
示例:当系统积累了"Alice 偏好 Python""Alice 不喜欢冗余代码"等多条事实后,会自动归纳出一条观察——"Alice 是一个注重可读性和简洁性的 Python 开发者"。
观察具备演化能力:当 Alice 从 Google 跳槽到 Meta,观察会更新为"Alice 在 Meta 工作(此前在 Google)",保留历史轨迹的同时反映最新状态。
第四层:心智模型(Mental Models)
定义:用户策划的、针对常见查询的高层摘要。
示例:"团队沟通最佳实践""项目风险评估框架"
心智模型是四层中优先级最高的。与自动生成的观察不同,心智模型由用户主动创建和维护,用于为 Agent 提供稳定的认知框架。
检索优先级
当 recall() 或 reflect() 操作被触发时,系统按优先级顺序查找:
心智模型 → 观察 → 原始事实
高层知识优先返回,只在高层没有覆盖时才回退到底层事实。这模仿了人类的认知模式——你日常做决策时依赖的是归纳出的经验和判断框架,而不是逐条回忆原始细节。
图片来源于 GitHub 社区
三、三种核心操作:保留、回忆、反思
Hindsight 通过三个操作与记忆系统交互:Retain(保留)、Recall(回忆)、Reflect(反思)。
Retain:不只是存储,是结构化理解
retain() 负责将新信息写入记忆库。它不是简单地存进去——据官方文档描述,背后有一个 LLM 驱动的结构化提取流程,包括从输入文本中识别核心事实和实体关系、将同一实体的不同称呼合并(实体消歧)、通过实体/时间/因果等维度将新事实与已有记忆建立关联、记录事件发生时间和系统接收时间(双时间戳),以及自动触发观察层的后台整合更新。
from hindsight_client import Hindsightclient = Hindsight(base_url="http://localhost:8888")# 基础存储client.retain( bank_id="my-bank", content="Alice works at Google as a software engineer")# 更多参数和用法详见官方文档Recall:四路并行检索 + 融合排序
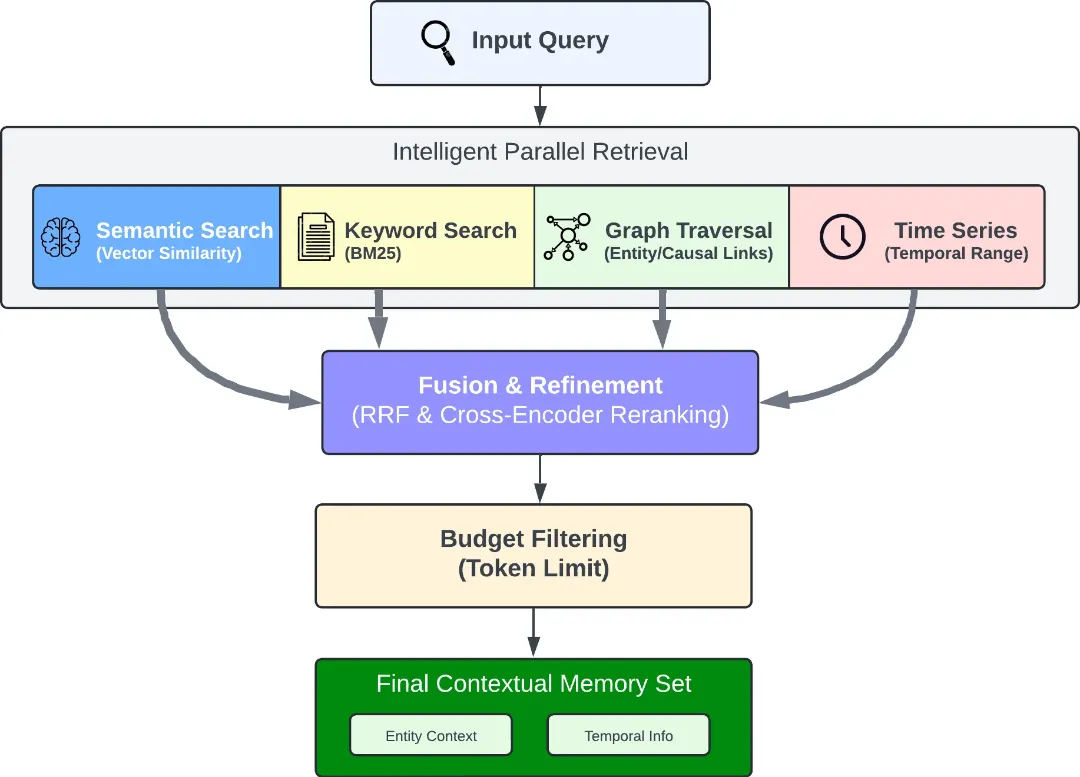
recall() 负责从记忆库中检索信息。它不是单一策略检索,而是四种检索策略并行执行,然后融合结果:
策略 | 机制 | 擅长的查询类型 |
|---|---|---|
语义检索 | 向量相似度 | "Alice 做什么工作?" |
关键词检索 | BM25 精确匹配 | 包含专有名词或技术术语的查询 |
图检索 | 实体/时间/因果关系遍历 | "为什么 Alice 加入 Google?"(多跳推理) |
时间检索 | 日期解析 + 范围过滤 | "六月发生了什么?""上个月的变化" |
四路结果通过倒数排名融合(Reciprocal Rank Fusion)合并,再经过交叉编码器(Cross-Encoder)重排序,最终按 token 预算裁剪输出。
# 语义查询client.recall(bank_id="my-bank", query="What does Alice do?")# 时间查询client.recall(bank_id="my-bank", query="What happened in June?")Reflect:从记忆中生成新认知
reflect() 是 Hindsight 中最像"思考"的操作。它不是检索已有信息,而是对已有记忆进行深度分析,形成新的连接和洞察。
适用场景:
- AI 项目经理反思项目中需要关注的风险
- 销售 Agent反思哪些外展消息得到了回复、哪些没有,以及可能的原因
- 客服 Agent反思用户频繁提出但产品文档尚未覆盖的问题
reflect() 的行为受记忆库的三个配置参数影响:
参数 | 作用 |
|---|---|
Mission | 记忆库的自然语言身份定义 |
Directives | Agent 必须遵守的硬性规则 |
Disposition | 影响推理风格的软性特质(如怀疑程度、字面理解倾向、共情程度),按 1-5 分制设定 |
client.reflect(bank_id="my-bank", query="What should I know about Alice?")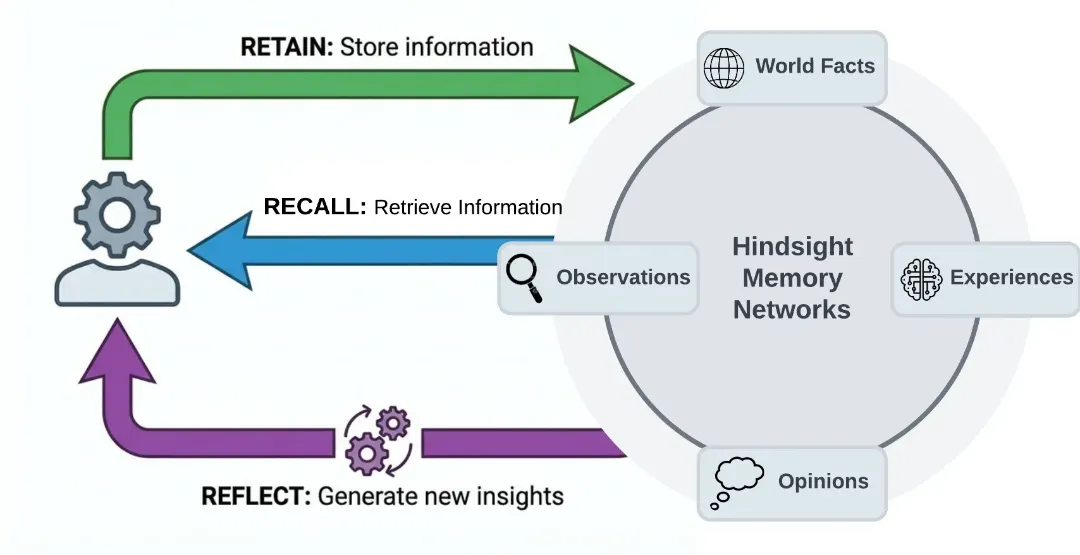
图片来源于 GitHub 社区
四、性能数据:LongMemEval 基准测试
Hindsight 团队使用 LongMemEval 基准测试来评估系统性能。这是一个用于评估对话式 AI 记忆系统在多种场景下表现的标准测试集。
基准测试结果
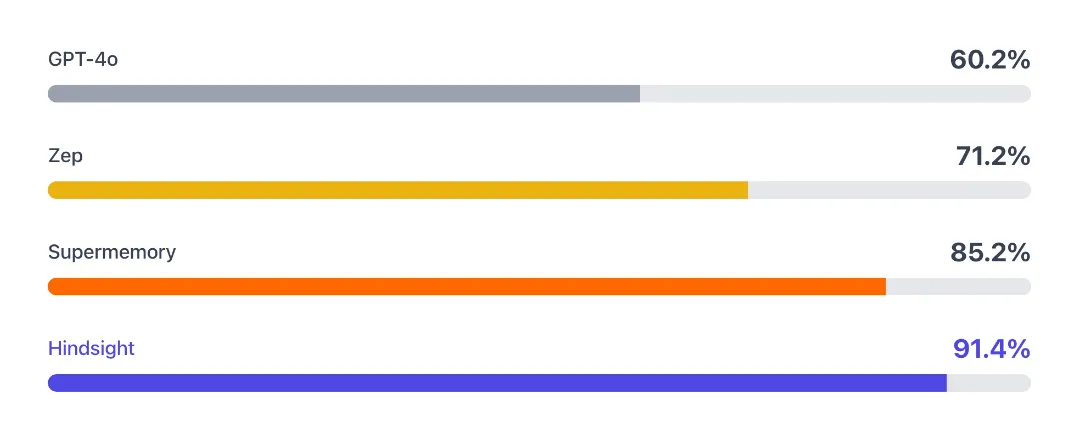
方案 | 模型 | 准确率 |
|---|---|---|
Full-context(全上下文) | OSS-20B | 39.0% |
Full-context(全上下文) | GPT-4o | 60.2% |
Zep | GPT-4o | 71.2% |
Supermemory | GPT-4o | 81.6% |
Supermemory | GPT-5 | 84.6% |
Supermemory | Gemini-3 | 85.2% |
Hindsight | OSS-20B | 83.6% |
Hindsight | OSS-120B | 89.0% |
Hindsight | Gemini-3 | 91.4% |
几个值得关注的数据点:
- 相同模型下的对比:使用 OSS-20B 模型时,Hindsight(83.6%)比全上下文方案(39.0%)高出 44.6 个百分点。这说明性能提升主要来自记忆系统的架构设计,而非模型能力。
- 小模型+好记忆 > 大模型+无记忆:Hindsight + OSS-20B(83.6%)已经超过了 GPT-4o 全上下文(60.2%),以及 Zep + GPT-4o(71.2%)。
- 当前最高准确率:Hindsight + Gemini-3 达到 **91.4%**,是公开报告中的最高水平(截至 2026 年 1 月)。
关于数据来源:Hindsight 的基准测试结果已由 Virginia Tech Sanghani 人工智能与数据分析中心以及 The Washington Post 独立复现。其他方案的数据为各自官方报告。
图片来源于 GitHub 社区
五、上手使用与集成方式
部署方式
Hindsight 提供三种部署方式:
方式一:Docker 单命令启动(推荐)
export OPENAI_API_KEY=sk-xxxdocker run --rm -it --pull always -p 8888:8888 -p 9999:9999 \ -e HINDSIGHT_API_LLM_API_KEY=$OPENAI_API_KEY \ -v $HOME/.hindsight-docker:/home/hindsight/.pg0 \ ghcr.io/vectorize-io/hindsight:latest启动后,API 在 http://localhost:8888,管理界面在 http://localhost:9999。
方式二:Docker Compose(外部 PostgreSQL)
适合需要独立数据库管理的生产环境。
方式三:Python 嵌入式(无需服务器)
pip install hindsight-all -Uimport osfrom hindsight import HindsightServer, HindsightClientwith HindsightServer( llm_provider="openai", llm_model="gpt-5-mini", llm_api_key=os.environ["OPENAI_API_KEY"]) as server: client = HindsightClient(base_url=server.url) client.retain(bank_id="my-bank", content="Alice works at Google") results = client.recall(bank_id="my-bank", query="Where does Alice work?")客户端SDK
语言 | 安装方式 |
|---|---|
Python | pip install hindsight-client -U |
Node.js / TypeScript | npm install @vectorize-io/hindsight-client |
去 | 官方文档提供 |
REST API | 直接 HTTP 调用 |
命令行界面 | 命令行工具 |
法学硕士支持
Hindsight 的 LLM 处理层(用于保留提取的事实和反映的推理)支持多种成功:
OpenAI / Anthropic / Gemini / Groq / Ollama / LM Studio / MiniMax
通过HINDSIGHT_API_LLM_PROVIDER环境变量切换。支持 Ollama 意味着可以完全在本地运行,不依赖外部 API。
框架集成
官方文档推出了与主流Agent框架的集成支持,包括MCP Server、Pydantic AI、LangGraph/LangChain、CrewAI、Vercel AI SDK、LiteLLM、OpenClaw、Agno、Hermes Agent、NemoClaw等。
另外,Hindsight还提供了LLM Wrapper模式——只需替换现有的LLM客户端为Hindsight封装版本(2行代码),可以自动在LLM调用过程中访问内存,从而无需代理的其他逻辑。
五、总结与思考
事后看来,试图解决 Agent 记忆领域的一个根本性问题:Agent 需要的不是更大的上下文或更好的搜索,而是一套能够使其“学习”的记忆架构。
其核心设计选择值得关注:
- 分层管理不同类型的知识,而不是把所有信息扔进同一个管理库
- 自动从原始事实中归纳观察,让Agent的理解随着信息积累而完成
- 四路搜索+融合排序,不依赖单一搜索策略
- 支持时间推理和因果推理,能够处理“去年”“为什么”此类查询
从基准测试数据来看,记忆系统的架构设计对最终效果的贡献可能比底层模型更大——Hindsight + 20B 模型(83.6%)已经超过了 GPT-4o 上下文全方案(60.2%)。这对于意在推理成本的生产环境来说,有实际价值。
当然,LongMemEval是一个标准化的对话记忆测试集,实际业务场景的复杂度可能与基准测试存在差异。Hindsight目前已在财富500强企业和多家AI创业公司的环境生产中使用,具体的落地效果还需要更多案例验证。
相关链接
- GitHub 仓库:vectorize-io/hindsight
- 官方文档:docs.hindsight.work(也可以通过hindsight.vectorize.io访问)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号