CDC是什么?一文带你全面了解CDC
原创
CDC是什么?一文带你全面了解CDC
原创
帆软BI
发布于 2026-03-23 13:33:30
发布于 2026-03-23 13:33:30
电商的实时库存同步、金融的交易审计,还有微服务间的数据协同,这些都离不开对数据库变更的精准、实时捕捉。
而变更数据捕获(CDC),正是解决这一核心需求的关键技术。CDC到底是什么?
今天就带大家全面了解CDC,读懂它如何为企业数据流转赋能。
另外,CDC 本身也是数据仓库建设中核心的实时数据采集环节,我这里整理了一份数据仓库建设解决方案,里面包含了从数仓架构设计、数据集成(含 CDC 场景)到报表体系建设的全流程思路,能帮你把 CDC 技术落地到完整的数据仓库体系里。
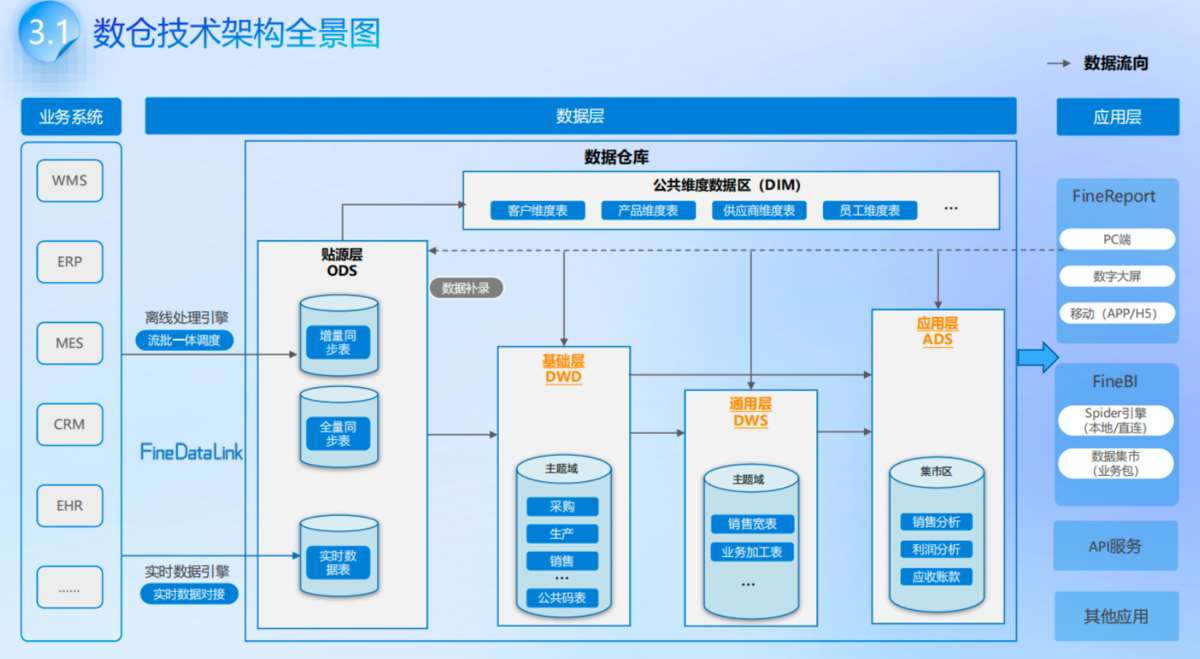
一、CDC是什么
CDC,全称 Change Data Capture,中文叫变更数据捕获。
说白了,它做的事情就一件,实时感知数据库里发生了什么变化,并把这些变化传递出去。
在CDC出现之前,数据同步通常有这几种做法:
1、全量同步
定期把整张表的数据全部导出,覆盖目标端。这种方式简单粗暴,但数据量一大,性能就撑不住,而且同步周期长,数据时效性差。
2、基于时间戳的增量同步
在表里加一个update_time字段,每次只同步时间戳大于上次同步时间的记录。这个方案看起来聪明,但有一个致命缺陷:删除操作根本捕获不到。数据被删了,时间戳字段也跟着消失了,下游完全感知不到。
3、应用层双写
业务代码在写数据库的同时,也往消息队列或者其他存储里写一份。这种方式侵入性强,维护成本高,而且一旦应用代码出问题,两边数据就不一致了。
这些方式有一个共同的问题,它们是被动的、滞后的,而且很难捕获删除操作。
CDC的出现,就是为了解决这个问题。它绕开应用层,直接在数据库层面捕获变更,不依赖业务代码,不依赖表结构里有没有时间戳字段,INSERT、UPDATE、DELETE全部能捕获,而且是实时的。
这是一个思路上的根本性转变,从主动轮询,变成被动监听。
二、CDC是怎么工作的
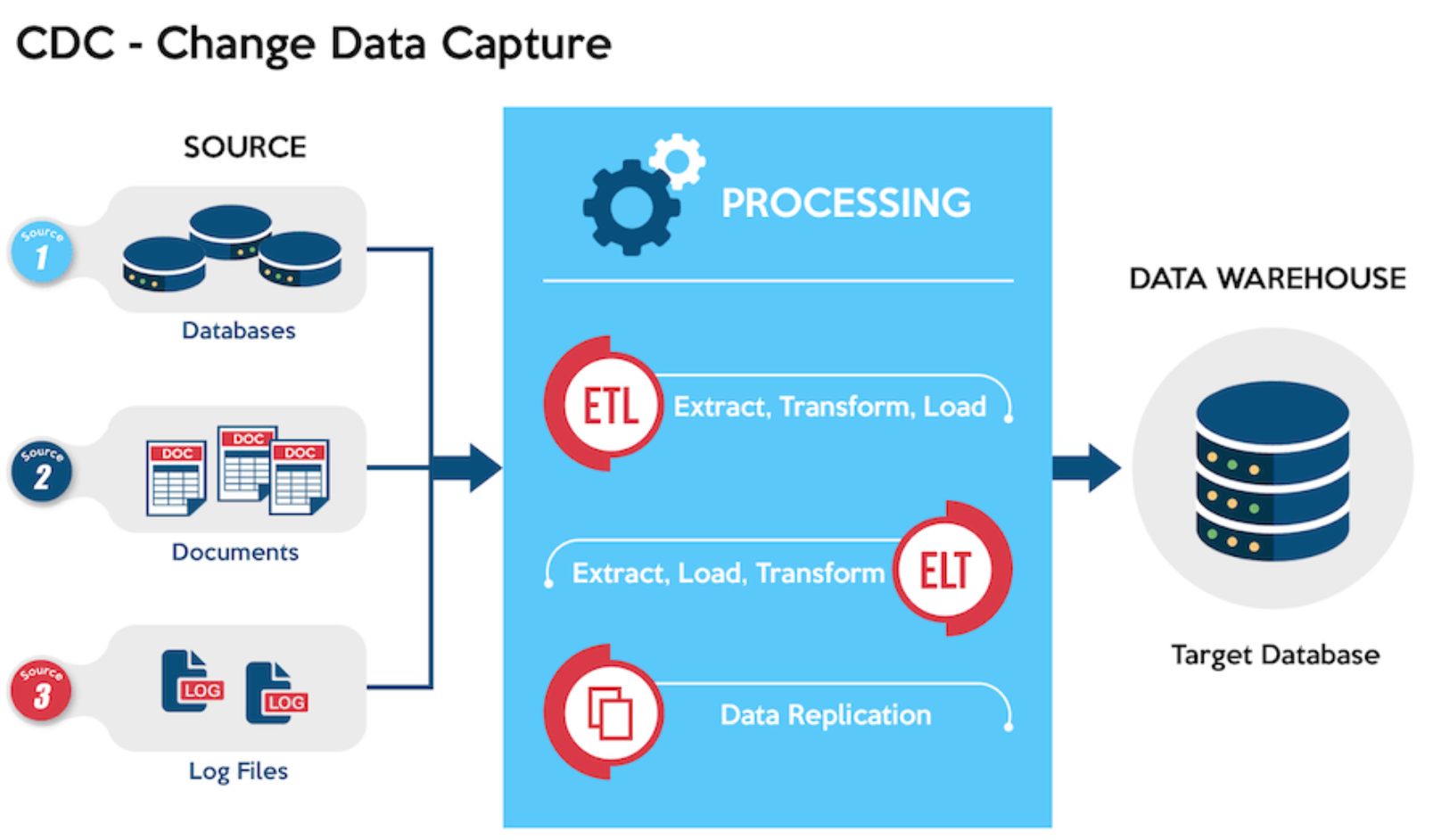
CDC的实现方式有几种,但目前工程实践中最主流、最可靠的,是基于数据库事务日志的方式。
不同数据库的日志机制不同,但核心逻辑完全一致:读取日志 → 解析变更 → 输出标准事件。
1、MySQL:基于Binlog
MySQL有一个叫做Binlog(Binary Log)的机制。每当数据库发生数据变更,MySQL都会把这次操作记录到Binlog里,这个日志本来是为主从复制设计的。
CDC工具做的事情,就是模拟一个MySQL从库的角色,订阅Binlog,实时读取里面的变更事件,然后把这些事件解析、转换、输出。
Binlog有三种格式:STATEMENT、ROW、MIXED。
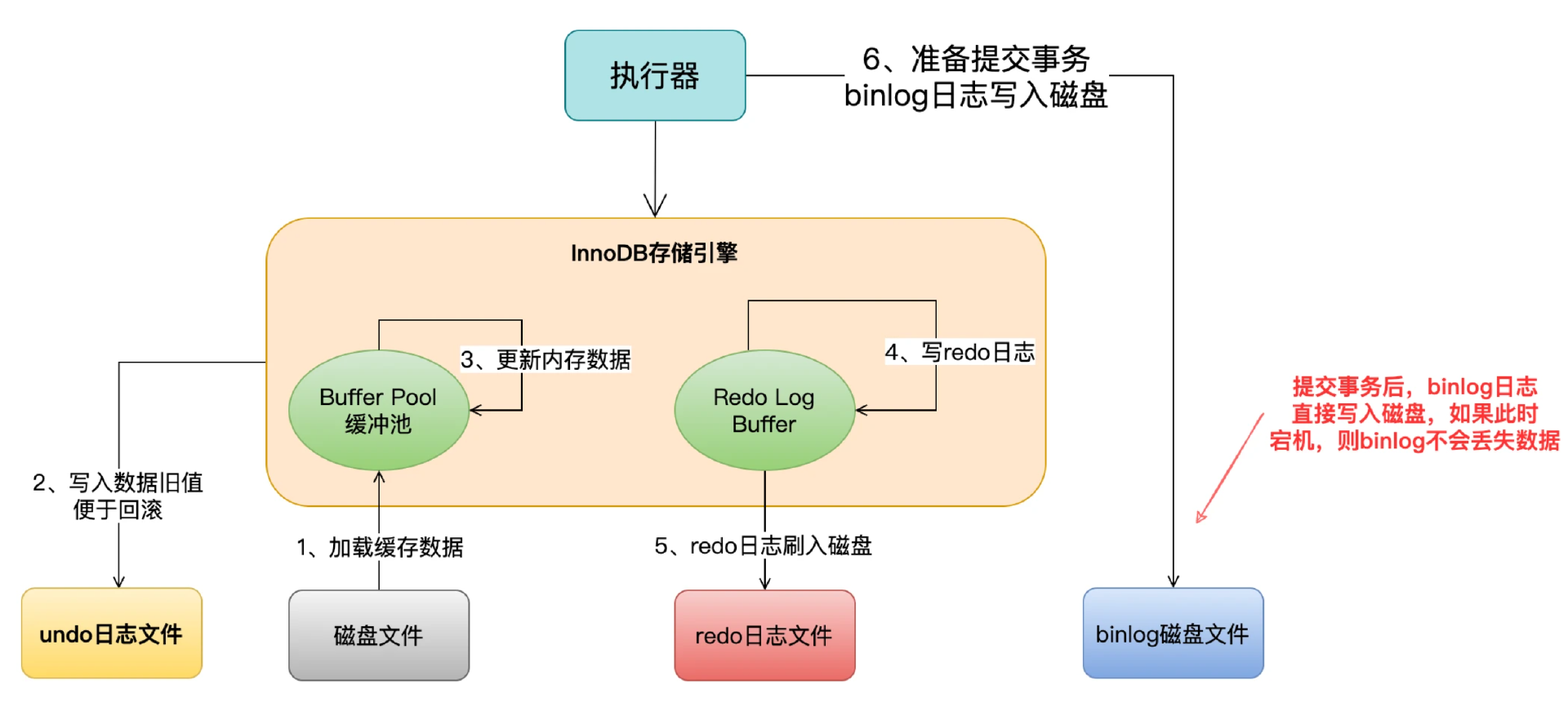
CDC必须使用ROW格式。原因是STATEMENT格式记录的是SQL语句本身,无法准确还原数据行变更。ROW格式记录的是每一行数据变更前后的完整内容,CDC工具能精确提取 before(变更前)和 after(变更后)数据。
2、PostgreSQL:基于逻辑复制与WAL
PostgreSQL有类似的机制,通过 WAL(预写日志)记录所有数据变更,CDC 基于逻辑复制机制实现,需创建复制槽。
复制槽的作用是记录CDC工具的消费位置,确保在CDC工具断开重连期间,WAL文件不会被数据库清理掉,从而保证不丢数据。
这里有一个非常重要的运维细节,复制槽长时间未消费,会导致 WAL 日志持续积压,最终占满磁盘,导致数据库宕机。生产环境必须配置监控告警,并制定手动清理复制槽的应急预案。
3、Oracle:基于LogMiner
Oracle CDC 依赖官方 LogMiner 工具,通过读取在线重做日志和归档日志,解析数据变更事件。
需提前开启数据库归档模式,配置复杂度较高,且受授权成本限制,多用于金融、政务等特定行业场景。
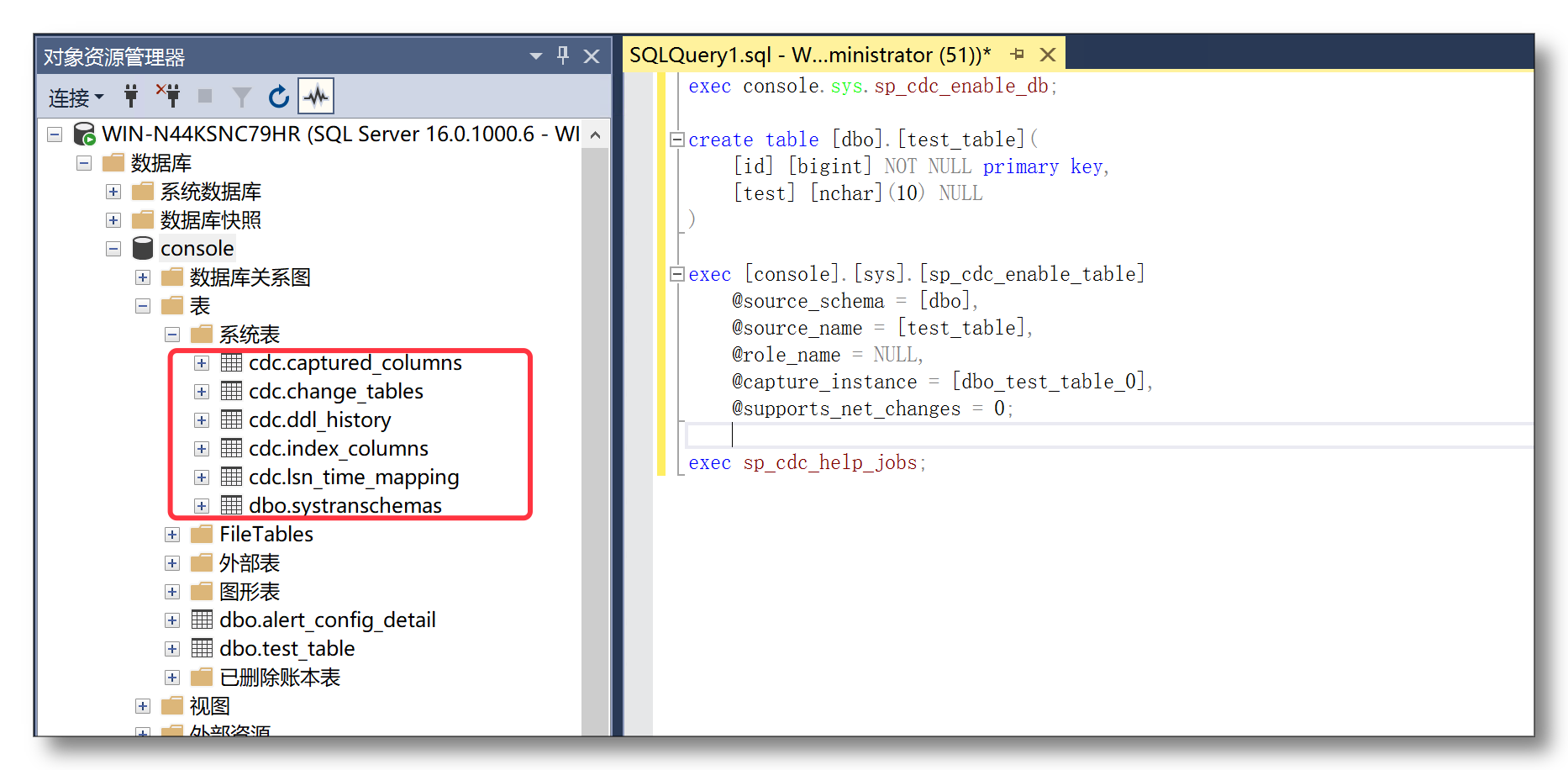
4、SQL Server:内置CDC功能
SQL Server本身内置了一个叫做CDC的功能。开启后自动将数据变更写入专用变更表,CDC 工具通过查询该表获取数据。
该方式不直接读取底层日志,性能和实时性略低,但配置简单、稳定性有保障。
每一条CDC事件,通常包含以下信息:
- 操作类型:INSERT、UPDATE 还是 DELETE
- 操作发生的时间
- 变更前的数据(before image)
- 变更后的数据(after image)
- 所属的数据库和表名
有了这些信息,下游系统就可以精确地知道数据发生了什么,并做出相应的处理。
三、主流的CDC工具
目前业界用得最多的CDC工具,主要是以下几个:
1、FineDataLink
面向企业级的数据集成平台,内置成熟、开箱即用的 CDC 能力,支持 MySQL、Oracle、PostgreSQL、SQL Server 等主流数据库,无需依赖 Kafka、Flink 等额外组件。
核心优势:
- 可视化界面配置,低代码即可完成 CDC 任务,上手快、落地成本低
- 全量快照与增量 CDC 无缝衔接,支持断点续传,不丢数据、不重复同步
- 精准捕获 INSERT、UPDATE、DELETE,兼容数据库日志解析,对业务库侵入小
- 内置监控、告警、数据一致性校验,降低生产运维风险
- 支持从实时捕获、数据清洗到目标入库的全链路一体化,不用组合多个工具
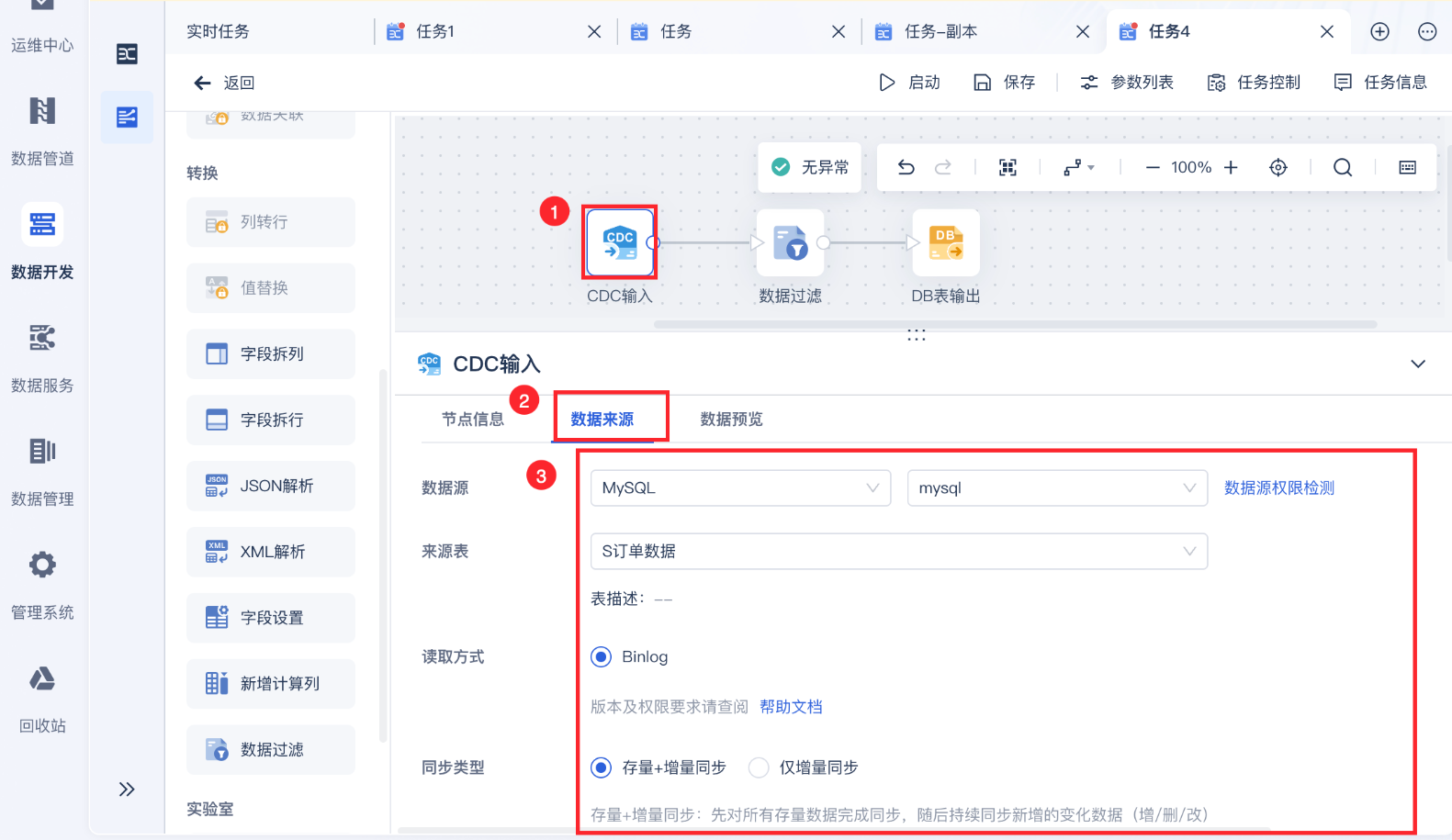
偏企业级商用产品,更适合重视稳定性、运维成本、交付效率的团队。
2、Debezium
目前开源生态里最成熟的CDC框架,支持MySQL、PostgreSQL、MongoDB、Oracle、SQL Server、Db2等。基于Kafka Connect框架运行,输出到Kafka Topic。
核心优势:
- 社区最活跃,文档最完善,遇到问题能找到解决方案
- 对各类数据库的支持深度最好,边界情况处理得最全面
- 内置了初始快照与增量流的无缝衔接机制
- 支持Schema Registry,可以管理事件的Schema演化
强依赖 Kafka Connect,无 Kafka 技术栈的团队引入成本较高;Debezium Server 可独立部署,但支持的输出目标有限。
3、Canal
阿里巴巴开源的MySQL 专用 CDC 工具,国内使用率极高,架构分为 Canal Server(负责读取 Binlog)和 Canal Client(负责消费事件),支持通过 Canal Adapter 直接同步至目标存储。
核心优势:
- 国内社区活跃,中文资料丰富,遇到问题相对容易找到解决方案
- 专注MySQL,对MySQL的Binlog解析支持成熟稳定
- 架构轻量,部署简单,不依赖Kafka Connect这类额外框架
- Canal Adapter支持直接同步到MySQL、Elasticsearch、HBase等常见目标存储,开箱即用
Canal也只支持MySQL,无多数据库兼容能力;Schema 管理能力较弱,边界场景处理不及 Debezium。
4、Flink CDC
Flink CDC是近年来发展最快的方向之一,内嵌于 Apache Flink 的 CDC 方案,可在 Flink 作业中直接定义 CDC 数据源,实现捕获、计算、输出全链路闭环。
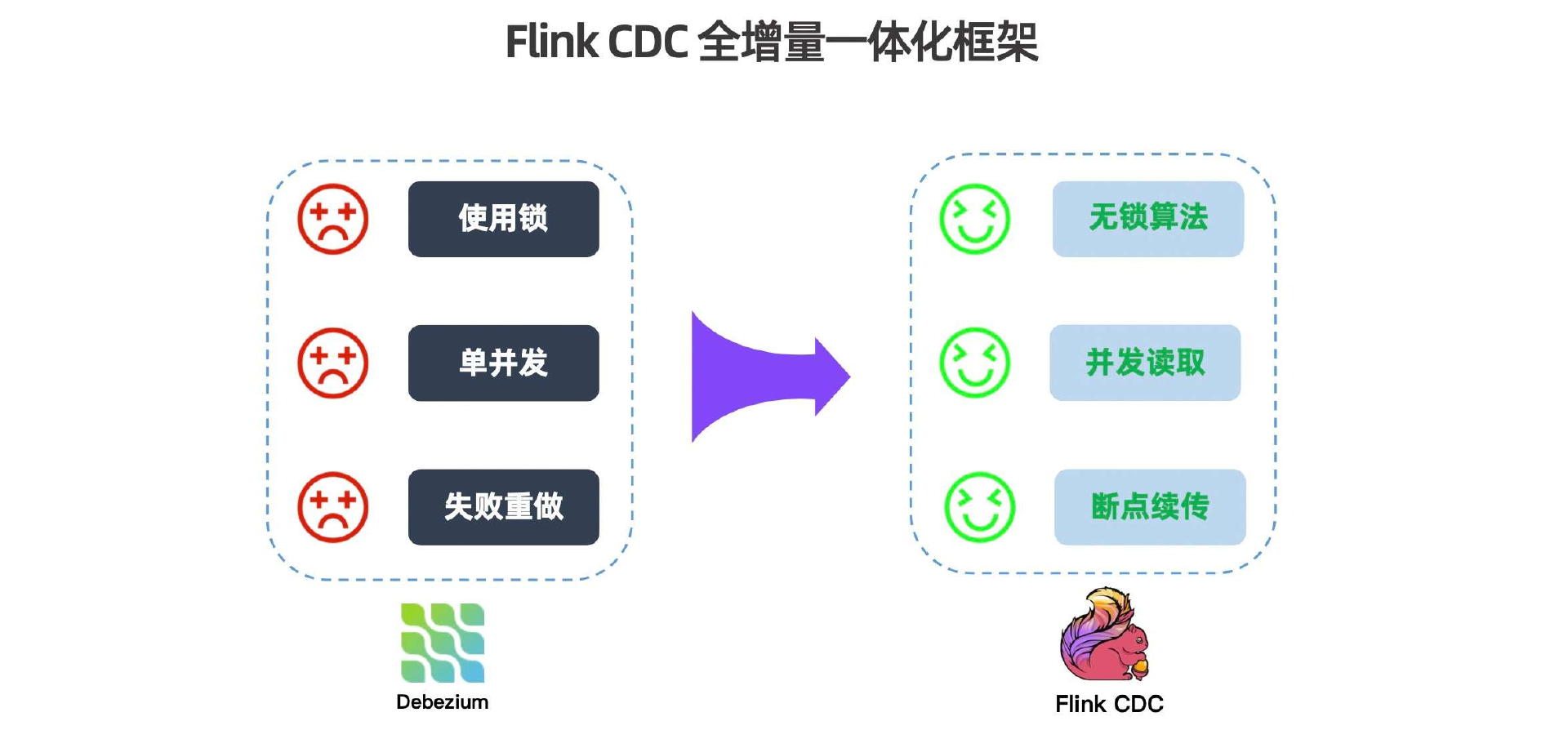
核心优势:
- 省去Kafka中间层,链路更短,端到端延迟更低,运维组件更少
- 与Flink生态深度集成,天然支持实时计算、多表Join、数据入湖
- 2.x之后支持无锁并行快照和全量阶段Checkpoint,生产可用性大幅提升
- 用SQL即可定义数据源和计算逻辑,对已有Flink团队接入成本极低
需要注意的是,Flink CDC对源表有主键要求,无主键表不支持并行快照;Schema 变更无法自动同步,需手动修改作业 DDL 并重启;依赖 Flink 集群,无基础团队学习成本较高。
5、Maxwell
轻量级 MySQL CDC 工具,定位简洁:读取 MySQL Binlog,转换为标准 JSON 格式,输出至 Kafka、RabbitMQ、Redis 或文件。
核心优势:
- 输出的JSON结构干净直观,字段清晰,下游消费程序接入成本极低
- 配置项少,部署简单,几个参数配好就能运行
- 对只需要增量变更事件的轻量场景来说,没有多余的复杂度
Maxwel仅支持 MySQL,无全量快照能力,历史数据需手动初始化;社区活跃度一般,复杂场景参考资料有限。
三、主流的CDC工具
目前业界用得最多的CDC工具,主要是以下几个:
1、FineDataLink
面向企业级的数据集成平台,内置成熟、开箱即用的 CDC 能力,支持 MySQL、Oracle、PostgreSQL、SQL Server 等主流数据库,无需依赖 Kafka、Flink 等额外组件。
核心优势:
- 可视化界面配置,低代码即可完成 CDC 任务,上手快、落地成本低
- 全量快照与增量 CDC 无缝衔接,支持断点续传,不丢数据、不重复同步
- 精准捕获 INSERT、UPDATE、DELETE,兼容数据库日志解析,对业务库侵入小
- 内置监控、告警、数据一致性校验,降低生产运维风险
- 支持从实时捕获、数据清洗到目标入库的全链路一体化,不用组合多个工具
偏企业级商用产品,更适合重视稳定性、运维成本、交付效率的团队。
2、Debezium
目前开源生态里最成熟的CDC框架,支持MySQL、PostgreSQL、MongoDB、Oracle、SQL Server、Db2等。基于Kafka Connect框架运行,输出到Kafka Topic。
核心优势:
- 社区最活跃,文档最完善,遇到问题能找到解决方案
- 对各类数据库的支持深度最好,边界情况处理得最全面
- 内置了初始快照与增量流的无缝衔接机制
- 支持Schema Registry,可以管理事件的Schema演化
强依赖 Kafka Connect,无 Kafka 技术栈的团队引入成本较高;Debezium Server 可独立部署,但支持的输出目标有限。
3、Canal
阿里巴巴开源的MySQL 专用 CDC 工具,国内使用率极高,架构分为 Canal Server(负责读取 Binlog)和 Canal Client(负责消费事件),支持通过 Canal Adapter 直接同步至目标存储。
核心优势:
- 国内社区活跃,中文资料丰富,遇到问题相对容易找到解决方案
- 专注MySQL,对MySQL的Binlog解析支持成熟稳定
- 架构轻量,部署简单,不依赖Kafka Connect这类额外框架
- Canal Adapter支持直接同步到MySQL、Elasticsearch、HBase等常见目标存储,开箱即用
Canal也只支持MySQL,无多数据库兼容能力;Schema 管理能力较弱,边界场景处理不及 Debezium。
4、Flink CDC
Flink CDC是近年来发展最快的方向之一,内嵌于 Apache Flink 的 CDC 方案,可在 Flink 作业中直接定义 CDC 数据源,实现捕获、计算、输出全链路闭环。
核心优势:
- 省去Kafka中间层,链路更短,端到端延迟更低,运维组件更少
- 与Flink生态深度集成,天然支持实时计算、多表Join、数据入湖
- 2.x之后支持无锁并行快照和全量阶段Checkpoint,生产可用性大幅提升
- 用SQL即可定义数据源和计算逻辑,对已有Flink团队接入成本极低
需要注意的是,Flink CDC对源表有主键要求,无主键表不支持并行快照;Schema 变更无法自动同步,需手动修改作业 DDL 并重启;依赖 Flink 集群,无基础团队学习成本较高。
5、Maxwell
轻量级 MySQL CDC 工具,定位简洁:读取 MySQL Binlog,转换为标准 JSON 格式,输出至 Kafka、RabbitMQ、Redis 或文件。
核心优势:
- 输出的JSON结构干净直观,字段清晰,下游消费程序接入成本极低
- 配置项少,部署简单,几个参数配好就能运行
- 对只需要增量变更事件的轻量场景来说,没有多余的复杂度
Maxwel仅支持 MySQL,无全量快照能力,历史数据需手动初始化;社区活跃度一般,复杂场景参考资料有限。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号