OpenClaw-RL: 通过对话训练任意智能体的全新框架

OpenClaw-RL: 通过对话训练任意智能体的全新框架

安全风信子
发布于 2026-03-22 08:22:26
发布于 2026-03-22 08:22:26
作者: HOS(安全风信子) 日期: 2026-03-21 主要来源平台: HuggingFace 摘要: OpenClaw-RL 提出了一种创新框架,通过利用各种交互模态的下一状态信号进行策略学习,实现了智能体的持续改进。本文深入分析其核心机制、技术实现和实验结果,探讨其在多领域的应用价值和未来发展方向。
目录:
- 1. 背景动机与当前热点
- 2. 核心更新亮点与全新要素
- 3. 技术深度拆解与实现分析
- 4. 与主流方案深度对比
- 5. 工程实践意义、风险、局限性与缓解策略
- 6. 未来趋势与前瞻预测
1. 背景动机与当前热点
本节核心价值:理解 OpenClaw-RL 诞生的背景和解决的核心问题,把握当前智能体强化学习的关键挑战。
在智能体交互的过程中,每次操作都会产生一个下一状态信号,即用户回复、工具输出、终端或 GUI 状态变化。然而,现有的智能体强化学习系统并未将这些信号作为实时、在线的学习来源。这导致了一个重要的机会被忽视:不同交互模态(如个人对话、终端执行、GUI 交互、SWE 任务和工具调用轨迹)之间的学习无法共享和协同。
OpenClaw-RL 的出现正是为了解决这一问题,它基于一个简单但深刻的观察:下一状态信号是通用的,策略可以同时从所有这些信号中学习。不同的交互形式并不是 separate 的训练问题,而是可以在同一个循环中用于训练同一个策略的交互。
这一理念为智能体的持续学习和改进开辟了新的可能性,特别是在多模态、多任务场景下,OpenClaw-RL 能够更有效地利用交互数据,实现智能体能力的快速提升。
2. 核心更新亮点与全新要素
本节核心价值:深入了解 OpenClaw-RL 的三大核心创新点,及其如何实现智能体的通用学习。
OpenClaw-RL 引入了三个关键的全新要素,使其在智能体强化学习领域脱颖而出:
- 通用下一状态信号利用:识别到不同交互模态(个人对话、终端执行、GUI 交互、SWE 任务、工具调用)产生的下一状态信号都是通用的学习来源,打破了传统方法中不同交互类型的隔离。
- 双重信号提取:从下一状态信号中提取两种信息:评估信号(通过 PRM 评判器提取为标量奖励)和指令信号(通过后见之明引导的在线策略蒸馏提取)。这种双重提取机制比传统的单一奖励信号提供了更丰富的学习信息。
- 异步设计:模型服务实时请求、PRM 评判器评判正在进行的交互、训练器同时更新策略,三者之间零协调开销。这种异步设计使得 OpenClaw-RL 能够在服务用户的同时持续学习和改进。
此外,OpenClaw-RL 还引入了后见之明引导的在线策略蒸馏(OPD),从下一状态中提取文本提示,构建增强的教师上下文,并提供比任何标量奖励更丰富的 token 级定向优势监督。
3. 技术深度拆解与实现分析
本节核心价值:深入剖析 OpenClaw-RL 的技术实现细节,包括其架构设计、核心组件和工作流程。
3.1 架构设计
OpenClaw-RL 采用了异步多组件架构设计,主要包括以下组件:
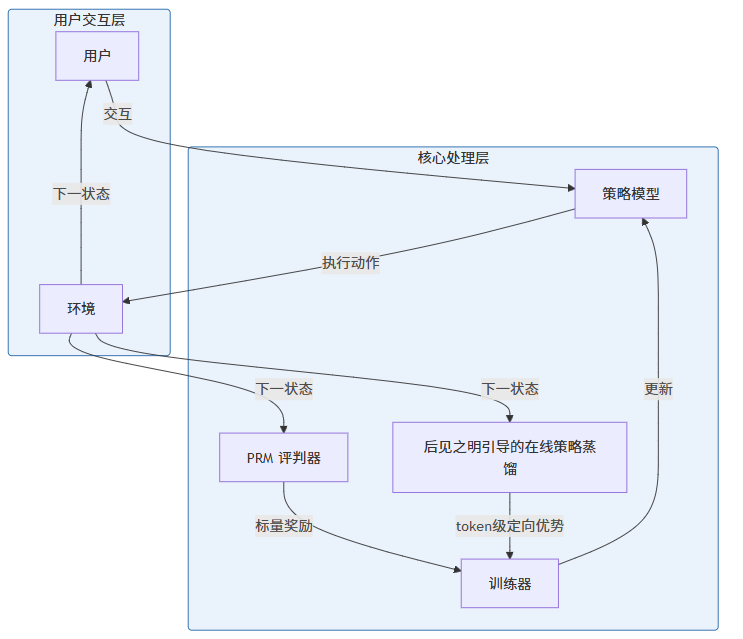
3.2 核心组件详解
3.2.1 下一状态信号处理
OpenClaw-RL 对下一状态信号的处理包括两个关键步骤:
- 评估信号提取:通过 PRM 评判器将下一状态信号转换为标量奖励,指示动作执行的好坏。
- 指令信号提取:通过 OPD 从下一状态中提取文本提示,构建增强的教师上下文,提供 token 级定向优势监督。
3.2.2 异步训练机制
异步设计是 OpenClaw-RL 的核心优势之一,具体工作流程如下:
- 模型服务:策略模型实时处理用户请求,执行动作并返回结果。
- PRM 评判:PRM 评判器并行分析正在进行的交互,生成标量奖励。
- OPD 处理:OPD 组件并行从下一状态中提取指令信号,生成 token 级定向优势。
- 策略更新:训练器基于收集到的奖励和优势信号,异步更新策略模型。
这种异步设计确保了系统在服务用户的同时持续学习,无需中断服务。
3.2.3 多模态支持
OpenClaw-RL 的一个重要特点是支持多种交互模态,包括:
- 个人对话:从用户的重新查询、纠正和明确反馈中学习
- 终端执行:从命令执行结果中学习
- GUI 交互:从界面状态变化中学习
- SWE 任务:从代码执行和调试结果中学习
- 工具调用:从工具执行结果中学习
3.3 代码示例
以下是 OpenClaw-RL 核心组件的实现示例:
# 下一状态信号处理
class NextStateProcessor:
def __init__(self, prm_judge, opd):
self.prm_judge = prm_judge
self.opd = opd
def process(self, state, action, next_state):
"""处理下一状态信号"""
# 提取评估信号(标量奖励)
reward = self.prm_judge.evaluate(state, action, next_state)
# 提取指令信号(token级定向优势)
advantages = self.opd.extract_advantages(state, action, next_state)
return reward, advantages
# PRM 评判器
class PRMJudge:
def __init__(self, model):
self.model = model
def evaluate(self, state, action, next_state):
"""评估动作执行质量,生成标量奖励"""
# 构建评估提示
prompt = self.build_evaluation_prompt(state, action, next_state)
# 使用模型评估
evaluation = self.model.generate(prompt)
# 提取标量奖励
reward = self.extract_reward(evaluation)
return reward
# 后见之明引导的在线策略蒸馏
class OPD:
def __init__(self, model):
self.model = model
def extract_advantages(self, state, action, next_state):
"""从下一状态中提取指令信号,生成token级定向优势"""
# 从下一状态中提取文本提示
hints = self.extract_hints(next_state)
# 构建增强的教师上下文
teacher_context = self.build_teacher_context(state, action, hints)
# 生成token级定向优势
advantages = self.generate_advantages(teacher_context, action)
return advantages
# 异步训练器
class AsyncTrainer:
def __init__(self, policy, buffer_size=10000):
self.policy = policy
self.buffer = []
self.buffer_size = buffer_size
def add_experience(self, state, action, reward, advantages, next_state):
"""添加经验到缓冲区"""
experience = (state, action, reward, advantages, next_state)
self.buffer.append(experience)
# 限制缓冲区大小
if len(self.buffer) > self.buffer_size:
self.buffer = self.buffer[-self.buffer_size:]
def train(self, batch_size=32, epochs=1):
"""异步训练策略模型"""
if len(self.buffer) < batch_size:
return
# 随机采样批次
batch = random.sample(self.buffer, batch_size)
# 训练模型
for epoch in range(epochs):
loss = self.policy.update(batch)
return loss
# OpenClaw-RL 主类
class OpenClawRL:
def __init__(self, policy, prm_judge, opd, trainer):
self.policy = policy
self.prm_judge = prm_judge
self.opd = opd
self.trainer = trainer
self.processor = NextStateProcessor(prm_judge, opd)
def process_interaction(self, state):
"""处理用户交互"""
# 策略生成动作
action = self.policy.generate_action(state)
# 执行动作,获取下一状态
next_state = self.execute_action(action)
# 处理下一状态信号
reward, advantages = self.processor.process(state, action, next_state)
# 添加经验到训练缓冲区
self.trainer.add_experience(state, action, reward, advantages, next_state)
# 异步训练
self.trainer.train()
return action, next_state3.4 实验结果分析
OpenClaw-RL 在多个场景下展示了显著的性能提升:
- 个人智能体:通过日常使用持续改进,从用户的重新查询、纠正和明确反馈中学习,提高对话质量和准确性。
- 通用智能体:在终端、GUI、SWE 和工具调用设置中支持可扩展的强化学习,展示了过程奖励的效用。
- 跨模态学习:能够在不同交互模态之间共享学习成果,提高整体性能。
4. 与主流方案深度对比
本节核心价值:通过多维度对比,清晰展示 OpenClaw-RL 与其他智能体强化学习方案的优势和差异。
方案 | 信号利用 | 训练模式 | 多模态支持 | 实时学习 | 协调开销 | 性能提升 |
|---|---|---|---|---|---|---|
OpenClaw-RL | 双重信号(评估+指令) | 异步 | 支持多种模态 | 实时 | 零 | 显著 |
传统 RL | 单一奖励信号 | 同步 | 有限 | 批次 | 高 | 中等 |
基于人类反馈的 RL | 人类反馈 | 同步 | 有限 | 批次 | 高 | 显著 |
在线学习 | 单一信号 | 同步 | 有限 | 实时 | 中 | 中等 |
模仿学习 | 专家示范 | 离线 | 有限 | 无 | 低 | 有限 |
4.1 对比分析
- 信号利用:OpenClaw-RL 从下一状态中提取双重信号(评估信号和指令信号),比传统方案仅使用单一奖励信号提供了更丰富的学习信息。
- 训练模式:异步设计使得 OpenClaw-RL 能够在服务用户的同时持续学习,而传统方案通常需要同步训练,会中断服务。
- 多模态支持:OpenClaw-RL 支持多种交互模态,能够在不同模态之间共享学习成果,而传统方案通常针对特定模态设计。
- 实时学习:OpenClaw-RL 能够实时从交互中学习,而传统方案通常需要批次处理。
- 协调开销:OpenClaw-RL 的组件之间零协调开销,而传统方案通常需要复杂的协调机制。
- 性能提升:实验结果表明,OpenClaw-RL 在多种场景下都能实现显著的性能提升。
5. 工程实践意义、风险、局限性与缓解策略
本节核心价值:探讨 OpenClaw-RL 在工程实践中的应用价值、潜在风险和局限性,以及相应的缓解策略。
5.1 工程实践意义
OpenClaw-RL 为智能体强化学习的工程实践带来了多方面的价值:
- 简化训练流程:通过利用自然产生的下一状态信号,避免了人工标注奖励信号的需要,简化了训练流程。
- 持续学习能力:智能体能够在日常使用中持续学习和改进,无需定期离线重训练。
- 多模态统一:将不同交互模态的学习统一到同一个框架中,提高了系统的通用性和可扩展性。
- 实时服务保障:异步设计确保了在学习的同时不中断服务,提高了用户体验。
- 资源效率:通过复用现有交互数据,减少了对额外训练数据的需求,提高了资源利用效率。
5.2 风险与局限性
尽管 OpenClaw-RL 展现了显著的优势,但也存在一些风险和局限性:
- 信号质量依赖:OpenClaw-RL 的性能依赖于下一状态信号的质量,信号质量差可能导致学习效果不佳。
- 计算资源需求:异步训练和多组件架构需要一定的计算资源支持。
- 稳定性挑战:实时学习可能导致策略波动,影响系统稳定性。
- 领域适应性:在全新领域或任务中,可能需要一定的适应期才能达到理想性能。
- OPD 提示质量:后见之明引导的在线策略蒸馏的效果依赖于从下一状态中提取的提示质量。
5.3 缓解策略
针对上述风险和局限性,可以采取以下缓解策略:
- 信号质量控制:建立信号质量评估机制,过滤低质量信号,确保只有有价值的信号被用于学习。
- 资源优化:优化组件设计和实现,减少计算资源需求,提高系统效率。
- 稳定性保障:引入策略平滑机制,避免训练过程中的策略剧烈波动。
- 领域适应:为新领域或任务提供初始引导,加速系统适应过程。
- OPD 优化:改进提示提取算法,提高 OPD 生成的提示质量和有效性。
6. 未来趋势与前瞻预测
本节核心价值:展望 OpenClaw-RL 技术的未来发展方向,以及其对智能体强化学习领域的潜在影响。
6.1 技术演进趋势
OpenClaw-RL 代表了智能体强化学习发展的一个重要方向,未来可能的演进趋势包括:
- 多模态深度融合:进一步深化多模态交互的融合,实现更复杂的跨模态学习和推理。
- 自适应信号处理:开发更智能的信号处理机制,能够自动适应不同场景和任务的需求。
- 分布式训练:扩展到分布式环境,支持更大规模的智能体训练和部署。
- 元学习集成:与元学习技术结合,提高智能体在新任务上的快速适应能力。
- 可解释性增强:提高学习过程和决策的可解释性,使用户能够理解和信任智能体的行为。
6.2 应用前景
OpenClaw-RL 的技术理念和实现方法具有广泛的应用前景:
- 个人助手:能够通过日常交互持续学习用户偏好和习惯,提供更加个性化的服务。
- 客服智能体:能够从与用户的对话中持续学习,提高服务质量和问题解决能力。
- 开发者工具:能够从开发过程中学习,提供更智能的代码建议和问题解决方案。
- 教育助手:能够根据学生的反馈和学习进度持续调整教学策略,提供个性化的学习体验。
- 智能家居控制:能够从用户的交互中学习,提供更智能、更符合用户习惯的家居控制。
6.3 开放问题
OpenClaw-RL 的发展也带来了一些值得深入研究的开放问题:
- 信号噪声处理:如何有效处理下一状态信号中的噪声,提高学习效率?
- 长期记忆整合:如何将短期学习与长期记忆整合,实现更持久的能力提升?
- 安全与伦理:如何确保学习过程符合安全和伦理标准,避免不良行为的学习?
- 多智能体协作:如何在多智能体环境中应用 OpenClaw-RL,实现智能体之间的协作学习?
- 泛化能力:如何提高智能体从特定交互中学习到的能力的泛化性,使其能够应用到新的场景中?
参考链接:
- 主要来源:OpenClaw-RL: Train Any Agent Simply by Talking - 普林斯顿 AI 实验室的智能体强化学习框架
- 辅助:GitHub 仓库 - OpenClaw-RL 的代码实现
附录(Appendix):
- 实验环境:个人智能体场景、通用智能体场景(终端、GUI、SWE、工具调用)
- 模型配置:支持各种 LLM 作为基础模型
- 关键超参数:PRM 评判器参数、OPD 提示提取参数、训练批次大小和学习率
关键词: OpenClaw-RL, 智能体强化学习, 下一状态信号, 后见之明引导, 在线策略蒸馏, 异步设计, 多模态学习

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号