MetaClaw: 野外元学习与进化的智能体新范式

MetaClaw: 野外元学习与进化的智能体新范式

安全风信子
发布于 2026-03-22 08:15:40
发布于 2026-03-22 08:15:40
作者: HOS(安全风信子) 日期: 2026-03-21 主要来源平台: HuggingFace 摘要: MetaClaw 提出了一种持续元学习框架,通过技能驱动的快速适应和机会主义策略优化,实现了 LLM 智能体在野外环境中的持续进化。本文深入分析其核心机制、技术实现和实验结果,探讨其在生产环境中的应用价值和未来发展方向。
PS:翻译错误“野外”实际为开放场景
目录:
- 1. 背景动机与当前热点
- 2. 核心更新亮点与全新要素
- 3. 技术深度拆解与实现分析
- 4. 与主流方案深度对比
- 5. 工程实践意义、风险、局限性与缓解策略
- 6. 未来趋势与前瞻预测
1. 背景动机与当前热点
本节核心价值:理解 MetaClaw 诞生的背景和解决的核心问题,把握当前 LLM 智能体发展的关键挑战。
在当今 AI 时代,大型语言模型(LLM)智能体已成为处理复杂多步骤任务的强大助手。然而,部署在实际环境中的智能体往往保持静态,无论用户需求如何演变,它们一旦训练完成就不再改变。这造成了一个根本性的矛盾:智能体必须持续为用户提供服务而不中断,但其能力却随着任务分布的变化而逐渐过时。
在 OpenClaw 等平台上,单个智能体连接到 20 多个消息渠道,处理多样化、不断演变的工作负载。现有的方法要么存储原始轨迹而不提取可迁移的行为知识,要么维护与权重优化脱节的静态技能库,要么在重新训练期间导致服务中断。
MetaClaw 的出现正是为了解决这一核心矛盾,它提出了一种持续元学习框架,通过技能驱动的快速适应和机会主义策略优化,实现了智能体在野外环境中的持续进化,同时确保服务不中断。
2. 核心更新亮点与全新要素
本节核心价值:深入了解 MetaClaw 的三大核心创新点,及其如何实现智能体的持续进化。
MetaClaw 引入了三个关键的全新要素,使其在 LLM 智能体领域脱颖而出:
- 技能驱动的快速适应:通过 LLM 进化器分析失败轨迹并合成新技能,实现零服务中断的即时改进。这一机制允许智能体从错误中快速学习,无需等待批量训练即可应用新技能。
- 机会主义策略优化:利用云 LoRA 微调通过 RL 与过程奖励模型(PRM)进行基于梯度的权重更新,仅在用户不活跃窗口由机会主义元学习调度器(OMLS)触发。OMLS 监控可配置的睡眠时间、系统键盘不活动和 Google 日历占用情况,确保更新不会影响用户体验。
- 代理式架构:MetaClaw 建立在代理式架构之上,无需本地 GPU 即可扩展到生产规模的 LLM。这一设计使得即使是资源有限的环境也能部署和运行 MetaClaw。
此外,MetaClaw 还引入了技能生成版本控制机制,严格分离支持数据(技能进化消耗的失败轨迹)和查询数据(用于 RL 更新的适应后轨迹),防止过时奖励污染。
3. 技术深度拆解与实现分析
本节核心价值:深入剖析 MetaClaw 的技术实现细节,包括其架构设计、核心组件和工作流程。
3.1 架构设计
MetaClaw 采用了分层架构设计,主要包括以下组件:
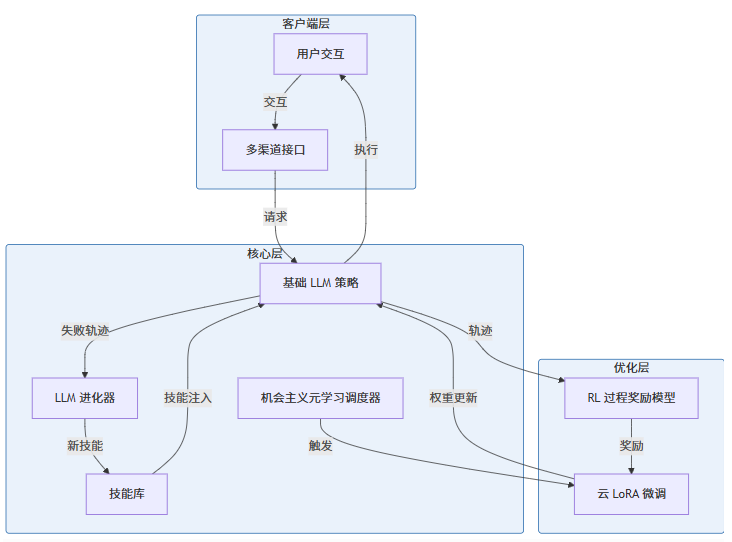
3.2 核心组件详解
3.2.1 技能驱动的快速适应
技能驱动的快速适应机制通过以下步骤工作:
- 收集智能体执行过程中的失败轨迹
- LLM 进化器分析这些轨迹,识别失败模式
- 合成新的技能指令,添加到技能库中
- 立即将新技能注入到基础策略中,无需等待批量更新
3.2.2 机会主义策略优化
机会主义策略优化由 OMLS 控制,具体流程如下:
- OMLS 监控系统状态,包括用户活动、键盘输入和日历安排
- 在检测到用户不活跃窗口时,触发云 LoRA 微调
- 使用 RL 与过程奖励模型对基础策略进行权重更新
- 更新完成后,新策略自动上线
3.2.3 技能生成版本控制
为防止数据污染,MetaClaw 实现了严格的版本控制机制:
- 支持数据(失败轨迹)用于技能进化
- 查询数据(适应后轨迹)用于 RL 更新
- 两者严格分离,确保 RL 更新基于最新的技能效果
3.3 代码示例
以下是 MetaClaw 核心组件的实现示例:
# 技能驱动的快速适应实现
class LLMEvolver:
def __init__(self, base_model):
self.base_model = base_model
def analyze_failure(self, trajectory):
"""分析失败轨迹,识别失败模式"""
# 提取失败原因和上下文
failure_reason = self.extract_failure_reason(trajectory)
context = self.extract_context(trajectory)
return failure_reason, context
def synthesize_skill(self, failure_reason, context):
"""基于失败分析合成新技能"""
# 生成技能指令
skill_instruction = self.generate_skill_instruction(failure_reason, context)
return skill_instruction
# 机会主义元学习调度器
class OMLS:
def __init__(self, user_activity_monitor, calendar_integration):
self.user_activity_monitor = user_activity_monitor
self.calendar_integration = calendar_integration
def is_user_inactive(self):
"""检测用户是否不活跃"""
# 检查键盘活动
keyboard_inactive = self.user_activity_monitor.is_keyboard_inactive()
# 检查日历占用
calendar_free = self.calendar_integration.is_calendar_free()
return keyboard_inactive and calendar_free
def trigger_optimization(self):
"""当用户不活跃时触发优化"""
if self.is_user_inactive():
self.start_cloud_lora_finetuning()
# 代理式架构实现
class MetaClawAgent:
def __init__(self, base_policy, skill_library, llm_evolver, omls):
self.base_policy = base_policy
self.skill_library = skill_library
self.llm_evolver = llm_evolver
self.omls = omls
def process_request(self, request):
"""处理用户请求"""
# 注入相关技能
relevant_skills = self.skill_library.get_relevant_skills(request)
enhanced_request = self.inject_skills(request, relevant_skills)
# 执行基础策略
response = self.base_policy.execute(enhanced_request)
# 分析执行结果
if self.is_failure(response):
# 处理失败轨迹
trajectory = self.extract_trajectory(request, response)
self.process_failure(trajectory)
# 检查是否需要触发优化
self.omls.trigger_optimization()
return response3.4 实验结果分析
MetaClaw 在两个基准测试上展示了显著的性能提升:
- MetaClaw-Bench:934 个问题,44 个模拟工作日
- 技能驱动适应提高了高达 32% 的相对准确率
- 完整 pipeline 将 Kimi-K2.5 的准确率从 21.4% 提升到 40.6%(对比 GPT-5.2 基线 41.1%)
- 端到端任务完成率提高了 8.25 倍
- AutoResearchClaw:23 阶段自主研究 pipeline
- 仅技能注入就提高了 18.3% 的综合鲁棒性
4. 与主流方案深度对比
本节核心价值:通过多维度对比,清晰展示 MetaClaw 与其他智能体方案的优势和差异。
方案 | 持续学习能力 | 服务中断 | 技能库管理 | 适应速度 | 可扩展性 | 性能提升 |
|---|---|---|---|---|---|---|
MetaClaw | 持续元学习 | 无中断 | 动态进化 | 即时 | 代理式架构,支持生产规模 | 准确率提升 32% |
传统静态智能体 | 无 | 无 | 静态 | 无 | 有限 | 无 |
定期重训练 | 批次学习 | 有中断 | 静态 | 慢 | 有限 | 中等 |
基于 RAG 的智能体 | 有限(依赖检索) | 无 | 无 | 中等 | 中等 | 有限 |
在线学习智能体 | 持续 | 无 | 有限 | 中等 | 有限 | 中等 |
4.1 对比分析
- 持续学习能力:MetaClaw 通过元学习框架实现了真正的持续学习,而传统方案要么完全静态,要么只能进行批次学习。
- 服务中断:MetaClaw 通过机会主义更新和技能驱动适应,实现了零服务中断,这是其最大的优势之一。
- 技能库管理:MetaClaw 维护动态进化的技能库,而其他方案要么没有技能库,要么技能库是静态的。
- 适应速度:技能驱动适应允许 MetaClaw 即时应用新技能,而其他方案通常需要等待批量更新。
- 可扩展性:代理式架构使得 MetaClaw 能够扩展到生产规模的 LLM,无需本地 GPU。
- 性能提升:实验结果表明,MetaClaw 在准确率和任务完成率方面都有显著提升。
5. 工程实践意义、风险、局限性与缓解策略
本节核心价值:探讨 MetaClaw 在工程实践中的应用价值、潜在风险和局限性,以及相应的缓解策略。
5.1 工程实践意义
MetaClaw 为 LLM 智能体的工程实践带来了多方面的价值:
- 持续服务保障:通过零中断的技能更新和机会主义策略优化,确保智能体能够持续为用户提供服务,这对于生产环境中的智能体至关重要。
- 自适应能力:MetaClaw 能够根据用户需求和任务分布的变化自动调整,减少了手动干预的需要,降低了维护成本。
- 性能提升:实验结果表明,MetaClaw 能够显著提高智能体的性能,特别是在复杂的多步骤任务中。
- 资源效率:代理式架构和机会主义更新机制使得 MetaClaw 能够更有效地利用计算资源,降低了运行成本。
5.2 风险与局限性
尽管 MetaClaw 展现了显著的优势,但也存在一些风险和局限性:
- 技能质量控制:自动合成的技能可能质量参差不齐,需要有效的质量控制机制。
- 计算资源需求:虽然采用了代理式架构,但云 LoRA 微调仍然需要一定的计算资源。
- 数据依赖性:MetaClaw 的性能依赖于高质量的失败轨迹数据,数据质量差可能导致技能退化。
- 适应边界:对于完全新颖的任务类型,MetaClaw 的适应能力可能有限。
5.3 缓解策略
针对上述风险和局限性,可以采取以下缓解策略:
- 技能质量评估:引入技能评估机制,对合成的技能进行质量评估,确保只有高质量的技能被添加到技能库中。
- 资源优化:优化云 LoRA 微调的资源使用,例如使用更高效的微调方法和资源调度策略。
- 数据质量控制:建立数据过滤和预处理机制,确保只有高质量的失败轨迹被用于技能进化。
- 混合适应策略:结合预训练和元学习,增强对新颖任务的适应能力。
6. 未来趋势与前瞻预测
本节核心价值:展望 MetaClaw 技术的未来发展方向,以及其对 LLM 智能体领域的潜在影响。
6.1 技术演进趋势
MetaClaw 代表了 LLM 智能体发展的一个重要方向,未来可能的演进趋势包括:
- 多模态技能融合:将 MetaClaw 的技能学习机制扩展到多模态领域,使智能体能够处理文本、图像、音频等多种输入。
- 跨智能体技能共享:建立智能体间的技能共享机制,使不同智能体能够相互学习和借鉴技能。
- 自监督技能发现:通过自监督学习自动发现和提取技能,减少对失败轨迹的依赖。
- 实时适应优化:进一步优化适应速度,实现近乎实时的技能更新和策略优化。
6.2 应用前景
MetaClaw 的技术理念和实现方法具有广泛的应用前景:
- 客服智能体:能够持续学习用户需求和问题模式,提供更准确、个性化的服务。
- 科研助手:如 AutoResearchClaw 所示,能够自主完成复杂的研究任务,并不断改进其能力。
- 软件开发助手:能够学习新的编程范式和工具,提高代码生成和问题解决能力。
- 个人助手:能够适应个人用户的习惯和偏好,提供更加个性化的服务。
6.3 开放问题
MetaClaw 的发展也带来了一些值得深入研究的开放问题:
- 技能泛化性:如何确保合成的技能能够泛化到不同的上下文和任务中?
- 长期记忆管理:如何有效管理和检索长期积累的技能,避免技能库过度膨胀?
- 安全与伦理:如何确保自动进化的技能符合安全和伦理标准?
- 可解释性:如何提高 MetaClaw 决策和技能合成的可解释性,使用户能够理解和信任智能体的行为?
参考链接:
- 主要来源:MetaClaw: Just Talk – An Agent That Meta-Learns and Evolves in the Wild - 北卡罗来纳大学教堂山分校的持续元学习框架
- 辅助:GitHub 仓库 - MetaClaw 的代码实现
附录(Appendix):
- 实验环境:MetaClaw-Bench(934 个问题,44 个模拟工作日),AutoResearchClaw(23 阶段自主研究 pipeline)
- 模型配置:基于 Kimi-K2.5,对比 GPT-5.2 基线
- 关键超参数:技能合成阈值、机会主义更新窗口、LoRA 微调参数
关键词: MetaClaw, 持续元学习, LLM 智能体, 技能驱动适应, 机会主义优化, 代理式架构, 野外进化

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号