RAG+任务规划如何落地?2026企业智能体记忆与执行全栈解析
原创
RAG+任务规划如何落地?2026企业智能体记忆与执行全栈解析
原创
用户11837377
发布于 2026-03-20 18:06:21
发布于 2026-03-20 18:06:21
过去一年,AI智能体成为技术社区讨论最热的方向之一。许多开发者在体验各种Agent框架时都会产生一个疑问:为什么看起来很聪明的大模型,一旦进入企业场景就容易“失忆”、答错问题,甚至无法完成复杂任务?
原因其实很简单,大模型擅长推理和生成,但企业系统需要的不只是推理能力,还包括稳定的知识来源、长期记忆以及跨系统执行能力。真正可落地的智能体系统,往往是由多个技术层共同构成的,模型负责理解与决策,知识系统负责提供记忆,工作流或自动化系统负责执行任务。
也正因为如此,当前主流的智能体架构,几乎都会围绕三个关键能力展开:记忆(Memory)、知识检索(RAG)、任务规划(Planning)。理解这三者之间的关系,基本就能看清今天智能体技术的核心逻辑。

01 (2)
智能体为什么需要“记忆”
很多人第一次接触大模型时,都会误以为模型本身就等同于一个巨大的知识库,但实际上,大模型在训练完成后就不再实时更新知识,也无法记住具体用户的历史信息。因此,一旦进入企业应用环境,模型很快就会遇到两个典型限制。
首先是不知道企业内部知识。企业的大量业务规则、产品资料、历史文档都不会出现在公开训练数据中,如果没有额外机制,大模型很难给出准确回答。其次是无法长期记忆交互过程。模型的上下文窗口有限,一旦任务涉及多轮操作或跨系统流程,模型很容易“忘记”之前发生的事情。
因此,智能体系统通常会设计两种不同类型的记忆。
一种是短期记忆。它主要用于维护当前任务的上下文,比如最近的对话历史、已经执行过的操作结果以及当前任务状态。大多数Agent框架都会通过上下文管理或缓存机制实现这一能力。
另一种则是长期记忆。它通常通过外部知识系统实现,例如文档知识库、数据库或向量数据库。当用户提出问题时,系统会从这些知识源中检索相关信息,再交给模型进行推理,这种技术路径正是近年来非常流行的 RAG(Retrieval-Augmented Generation)。
RAG如何让模型拥有企业知识
RAG的核心思想其实很直观:在模型生成回答之前,先去企业知识库里找到最相关的信息,再把这些信息提供给模型参考。
在工程实现中,这一过程通常包含几个关键步骤。首先需要对企业知识进行整理,包括产品文档、技术手册、业务流程说明以及历史数据等。为了方便检索,这些内容通常会被切分为较小的文本片段。
接下来,这些文本会被转换为向量表示,并存储到向量数据库中。常见的向量数据库包括 Milvus、Pinecone、Weaviate 等。向量化之后,系统就可以通过语义搜索找到与问题最相关的内容,而不是仅仅依赖关键词匹配。
当用户提出问题时,系统会先将问题转化为向量,然后在向量库中检索最相似的文本片段。最后,这些检索到的内容会被加入到提示词中,再交给大模型生成回答。
这种方式的优势在于,它能够把企业私有知识动态注入到模型推理过程中,从而显著降低模型“幻觉”的概率。因此,在当前的AI应用中,无论是智能客服、企业知识助手还是技术支持系统,RAG几乎已经成为标准架构。

国内外许多平台都在推动这一技术路线。例如,OpenAI 在其 Assistants 和 Agent 架构中强调知识工具的调用;Amazon 在 Bedrock 中提供知识库与Agent能力结合的服务;而在中国,百度智能云、阿里云百炼、腾讯云TI平台等,也都推出了类似的企业知识库与RAG解决方案。
但企业智能体仅靠RAG还不够
随着应用深入,很多企业逐渐发现一个问题:RAG可以解决“模型不知道答案”的问题,却无法解决“系统不知道如何完成任务”的问题。
举一个常见的业务场景。假设用户提出这样的需求: “分析客户投诉记录,生成总结报告,并发送给负责人。”
这其实是一个多步骤任务,其中可能包括数据查询、内容分析、报告生成以及邮件发送等多个环节。如果只是依靠RAG,系统只能回答问题,却无法自动执行这些步骤。
于是近年来出现了一种新的架构趋势:Agentic RAG,简单来说,就是在RAG基础上加入智能体的任务规划能力。智能体不仅可以检索知识,还能够根据目标拆解任务、调用工具并逐步完成流程。
在这一模式下,AI系统的角色从问答工具升级为“任务执行系统”。
智能体如何实现任务规划
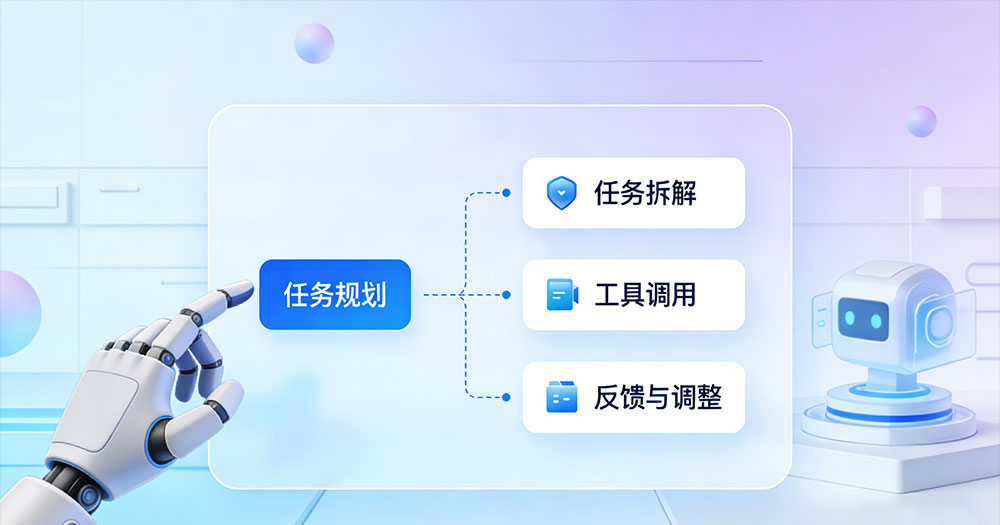
在多数智能体框架中,任务规划通常包含三个关键机制。
首先是任务拆解能力。当用户给出一个复杂目标时,智能体会把它拆分成多个可执行的子任务。例如完成一份财务分析报告,系统可能会先获取数据,再进行统计分析,最后生成报告并提交审批。
其次是工具调用能力。为了完成这些子任务,智能体需要调用各种外部工具,例如数据库查询接口、API服务、数据分析程序甚至自动化机器人。
最后是反馈与调整机制。在任务执行过程中,智能体会根据结果不断修正计划,例如当某一步失败时重新执行或调整流程。这样就形成了一个持续循环的任务执行体系。
正因为有了这些机制,智能体才能处理复杂的企业业务流程,而不仅仅是进行简单的问答。
03
企业智能体的关键难点:知识与流程的结合
在真实企业环境中,知识系统往往分散在多个系统里,比如ERP、CRM、OA以及各类文档平台。如果这些数据无法被统一调度,再先进的模型也难以真正参与业务流程。
因此,越来越多企业开始尝试把智能体能力与自动化系统结合,让AI不仅能理解任务,还能直接执行操作。
在国外,这种趋势可以在多个平台上看到。例如 LangChain 和 LangGraph 提供了智能体工作流框架,Microsoft 在 Copilot Studio 中强化了自动化能力。国内厂商也在类似方向上持续探索,例如百度智能云的AI Agent平台、阿里云百炼智能体开发框架以及智谱的Agent能力等。
而在企业级自动化领域,一些厂商则通过“智能体+流程自动化”的架构推动落地。例如在金智维的K-APA智能流程自动化平台中,智能体可以负责理解任务和调用知识库,而自动化机器人则负责具体执行系统操作。这种模式可以把AI能力与企业既有系统深度结合,使智能体真正参与业务流程。
在金融行业,这种模式已经开始被应用于多个场景。
例如在银行业务中,员工每天需要在多个系统之间频繁操作,大量工作都属于规则明确、重复性较高的数据处理任务。通过引入AI数字员工,可以实现跨系统数据采集、报表生成以及风险监测等流程自动化。在一些银行的实践中,数字员工已经能够完成账户风险监测、数据报送以及报表统计等任务,并显著减少人工操作。据金智维的相关案例显示,AI数字员工上线后不仅提高了业务处理效率,也降低了人为操作错误的风险。
类似的实践也出现在证券行业,例如在金智维X国信证券的数字化项目中,AI数字员工通过RPA与OCR、NLP技术结合,实现了基金指令解析、报表数据采集以及日终数据报送等场景自动化,数据导出效率提升约300%,整体运营效率显著提高。
在企业财务场景中,自动化同样能够发挥作用。以苏州某国有资产控股集团为例,通过部署AI数字员工,企业在29家银行账户、12个网银场景中实现了自动化流程管理,数字员工能够自动下载账户流水、完成银企对账并生成余额调节表,大幅提升财务处理效率并减少差错。
在公共服务领域,类似技术也被应用于政务和司法系统。例如在智慧法院建设中,数字助理可以协助处理文书制作、案件执行以及档案归档等事务性工作,累计执行任务超过10万次,显著减轻法官团队的事务负担。
这些实践都充分说明,当智能体能力与流程自动化系统结合时,AI不仅能回答问题,还能真正参与业务执行。

04
从当前行业发展来看,企业级智能体系统正在逐渐形成一个较为清晰的技术架构。最底层是大模型,负责语言理解和推理能力;在其之上是知识系统,通过RAG或知识图谱提供长期记忆;再往上是智能体层,用于任务规划和工具调用;最上层则是执行系统,例如自动化平台或业务系统接口。
当这四层能力被整合之后,AI系统就不仅仅是一个聊天工具,而是一个能够持续执行任务的数字劳动力。
因此,在今天的企业AI实践中,人们逐渐意识到一个事实:大模型只是起点。真正决定智能体是否能够落地的,是记忆系统、知识架构以及流程执行能力之间的协同设计。
而围绕这些能力构建的智能体架构,也正在成为下一代企业AI系统的基础。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号