南大MOTIP:多目标跟踪不再需要复杂匹配规则,简洁方法效果更优
原创
南大MOTIP:多目标跟踪不再需要复杂匹配规则,简洁方法效果更优
原创
CoovallyAIHub
发布于 2026-03-18 11:40:48
发布于 2026-03-18 11:40:48
导读
多目标跟踪(MOT)的主流做法是"检测+关联":先检测出每一帧的目标,再用匈牙利算法、IoU 匹配等手工设计的启发式方法把前后帧的目标对应起来。这些方法能用,但每遇到一个新场景(遮挡严重、目标外观相似、运动轨迹不规律),就需要一轮新的调参和规则修改。
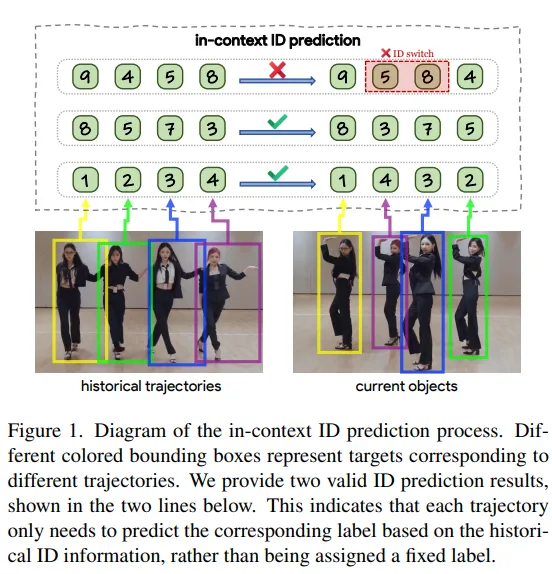
南京大学王利民团队提出了一个新视角:把目标关联问题转化为 ID 预测问题。给定一组历史轨迹(每条轨迹带有一个 ID 标签),直接预测当前帧检测到的目标应该分配哪个 ID。这个过程形式上类似分类,但本质不同:传统分类的标签有固定语义(猫=1、狗=2),而 MOT 中的 ID 标签是随机分配的,只表示"一致性"而不携带语义信息——同一条轨迹的 ID 保持一致即可,具体是哪个数字无所谓。这种"上下文相关"的标签设计使模型可以泛化到推理时未见过的新轨迹。
基于这个思路,MOTIP 用一个 DETR 检测器 + 可学习 ID 字典 + ID Decoder 的简洁架构,在 DanceTrack 上 HOTA 达到 69.6(不使用额外数据),超越此前最优 CO-MOT(65.3)+4.3 个百分点。在 SportsMOT 和 BFT(鸟类追踪)上同样达到 SOTA。
论文信息
- 标题:Multiple Object Tracking as ID Prediction
- 作者:Ruopeng Gao, Ji Qi, Limin Wang†(通讯作者)
- 机构:南京大学(新型软件技术国家重点实验室)、中国移动(苏州)、上海 AI Lab
- 代码:https://github.com/MCG-NJU/MOTIP
一、启发式匹配的困境:为什么需要换个思路?
主流 MOT 方法的关联步骤依赖手工设计的启发式规则:
方法类型 | 做法 | 局限 |
|---|---|---|
IoU 匹配 | 用前后帧检测框的 IoU 计算相似度,匈牙利算法做最优匹配 | 目标快速移动或遮挡时 IoU 接近零,匹配失败 |
运动模型 | 用卡尔曼滤波预测目标下一帧位置,再做匹配 | 假设线性运动,非线性轨迹(如舞蹈、球类运动)效果差 |
外观特征 | 提取 ReID 特征计算余弦相似度 | 目标外观相似时(如穿同色队服的运动员)容易混淆 |
这些方法的共同问题是:每一种假设(线性运动、外观可区分、IoU 重叠充分)都有适用边界,一旦超出边界就需要针对性修补。比如 OC-SORT 为了处理突然停止和启动的运动专门设计了"虚拟轨迹",Hybrid-SORT 组合了多种相似度度量。每次改进都需要大量人工分析和参数调优。
论文提出的核心问题是:能否在保持"检测+关联"解耦的同时,把关联部分从启发式规则变成端到端可学习的?
MOTIP 的回答是:把关联转化为 ID 预测——给定上下文(历史轨迹 + 它们的 ID 标签),直接预测当前检测目标的 ID。
图片来源于原论文
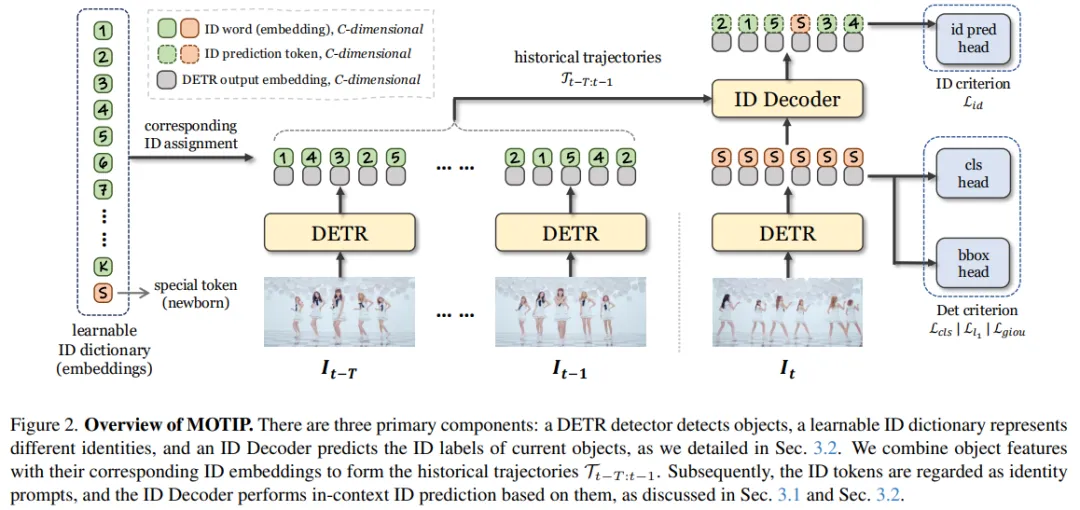
二、MOTIP 的三个组件:检测器 + ID 字典 + ID Decoder
组件 1:DETR 检测器
使用 Deformable DETR(ResNet-50 骨干)对每一帧做目标检测,输出每个目标的 C 维特征向量和检测框。
MOTIP 的一个关键设计是检测和关联解耦:检测器只负责检测,关联由后续的 ID Decoder 独立完成。这避免了 MOTR 等方法中检测 query 和跟踪 query 在同一个解码过程中产生冲突的问题。
组件 2:可学习 ID 字典
定义一个 ID 字典 I = {i₁, i₂, ..., iK, i_spec},其中:
- K 个常规 ID token:每个是 C 维可学习向量,代表不同的身份
- 1 个特殊 token(i_spec):代表"新出现的目标"
关键理解:ID 标签不携带语义信息,它们只表示"一致性"。轨迹 1 和轨迹 2 的 ID 可以互换,只要同一条轨迹内的 ID 保持一致。这使得模型可以泛化到推理时未见过的新轨迹——不需要为每条新轨迹学习新的表示,只需复用已有的 ID token。
组件 3:ID Decoder
标准 Transformer Decoder,包含交替堆叠的 self-attention 和 cross-attention 层。注意力结构如下:
- Query:当前帧的检测目标(特征与 i_spec 拼接,2C 维)
- Key / Value:过去 T 帧(固定窗口)中所有历史轨迹的 token(特征与对应 ID embedding 拼接,2C 维)
其中 self-attention 层让当前帧的多个检测目标之间互相交换信息,避免多个相似目标被分配到同一个 ID。消融实验(Table 4)显示,在最终配置中去掉 self-attention 后 HOTA 从 62.2 降至 60.2;论文还指出,引入轨迹增强后,有无 self-attention 的性能差距进一步拉大,验证了这一设计的重要性。
ID Decoder 输出每个检测目标在 K+1 个 ID 上的概率分布,经线性分类头得到最终预测。推理时的 ID 分配并非简单取最高概率,而是包含一套完整的决策流程:
- 检测置信度低于 λ_det 的目标直接过滤
- 同一帧中如果多个目标预测了同一个 ID,只保留置信度最高的,其余标记为新目标
- ID 预测概率需超过 λ_id 阈值才被接受,否则标记为新目标
- 新目标的检测置信度需超过 λ_new 才正式建立新轨迹
整个过程等价于:在历史轨迹提供的"上下文"中,为当前检测目标做 ID 预测——这就是"in-context ID prediction"的含义。
图片来源于原论文
三、轨迹增强:训练时模拟推理时的错误
MOTIP 的一个巧妙设计是轨迹增强(Trajectory Augmentation),解决训练和推理之间的分布差异。
训练时使用 Ground Truth 构建历史轨迹,轨迹是"干净"的。但推理时,模型的 ID 分配可能出错(比如把目标 A 的 ID 分给了目标 B),导致历史轨迹中夹杂错误。如果训练时从未遇到过这种"脏数据",模型的鲁棒性就不够。
论文设计了两种增强策略:
策略 | 做法 | 模拟的场景 |
|---|---|---|
轨迹随机遮挡 | 以概率 λ_occ 随机丢弃轨迹中的 token | 目标被遮挡导致轨迹不完整 |
轨迹随机交换 | 以概率 λ_sw 随机交换同一帧中两条轨迹的 ID token | 模型给外观相似的目标分配了错误 ID |
两种增强的超参数都设为 0.5,在消融实验中证明对性能有显著贡献。
四、消融实验:ID 预测 vs ReID 匹配,差距有多大?
DanceTrack 主实验
DanceTrack 是当前最具挑战性的 MOT 基准之一,包含群舞场景中频繁交互、外观相似、非线性运动的目标。
方法 | HOTA | AssA | IDF1 | 额外数据 |
|---|---|---|---|---|
ByteTrack | 47.7 | 32.1 | 53.9 | 无 |
OC-SORT | 55.1 | 38.3 | 54.6 | 无 |
MeMOTR | 63.4 | 52.3 | 65.5 | 无 |
CO-MOT | 65.3 | 53.5 | 66.5 | 无 |
MOTIP | 69.6 | 60.4 | 74.7 | 无 |
MOTRv2 | 69.9 | 59.0 | 71.7 | 有 |
MOTIP | 72.0 | 63.5 | 76.8 | 有 |
不使用额外数据时,MOTIP 在 HOTA(+4.3)、AssA(+6.9)、IDF1(+8.2)上全面领先。AssA(关联准确率)的提升最大,直接验证了 ID 预测在目标关联上的优势。
使用额外数据后,MOTIP 达到 72.0 HOTA,超越 MOTRv2(69.9)和 CO-MOT(69.4)。
SportsMOT
体育赛事场景包含频繁的镜头切换、运动员的高速移动和反复交互。OC-SORT 通过显式建模非线性运动在该数据集上表现突出。
方法 | HOTA | AssA | IDF1 |
|---|---|---|---|
ByteTrack | 62.1 | 50.5 | 69.1 |
TrackFormer | 63.3 | 61.1 | 72.4 |
OC-SORT | 68.1 | 54.8 | 68.0 |
MeMOTR | 68.8 | 57.8 | 69.9 |
MOTIP | 72.6 | 63.2 | 77.1 |
MOTIP 在不使用额外数据的情况下 HOTA 达到 72.6,比 MeMOTR(68.8)高 3.8,且在 AssA(+5.4)和 IDF1(+7.2)上优势更为明显。值得注意的是,MOTIP 不使用额外数据的成绩甚至超过了多数使用额外数据的方法(如 OC-SORT 71.9、DiffMOT 72.1)。
BFT(鸟类追踪)
鸟类追踪与行人追踪有显著不同:鸟类在三维空间中运动更动态,且外观高度相似(没有衣服等人工特征可用于区分),对关联算法提出了不同维度的挑战。
方法 | HOTA | AssA | IDF1 |
|---|---|---|---|
JDE | 30.7 | 23.4 | 37.4 |
FairMOT | 40.2 | 28.2 | 41.8 |
ByteTrack | 62.5 | 64.1 | 82.3 |
CenterTrack | 65.0 | 54.0 | 61.0 |
OC-SORT | 66.8 | 68.7 | 79.3 |
MOTIP | 70.5 | 71.8 | 82.1 |
MOTIP 在这个全新的跟踪场景中同样达到 SOTA,验证了方法的跨场景泛化能力。
ID 预测 vs ReID 管线的直接对比
论文在完全相同的目标特征上做了直接对比实验,分别用 ReID 方法(FairMOT 的分类损失、对比学习损失)和 MOTIP 的 ID 预测做关联:
关联方式 | HOTA | AssA | IDF1 |
|---|---|---|---|
两阶段 ReID(FairMOT 式) | 29.4 | 11.5 | 22.1 |
两阶段对比学习 | 41.0 | 22.6 | 36.4 |
两阶段 ID 预测(MOTIP) | 55.4 | 41.1 | 55.7 |
一阶段 ReID + 匈牙利 | 50.6 | 34.7 | 50.9 |
一阶段 ID 预测(MOTIP) | 59.5 | 47.2 | 61.1 |
在相同特征下,ID 预测方式的 HOTA 比 ReID 高 8.9-26 个百分点(两阶段设置下差距更大)。这说明性能差距主要来自关联范式的不同,而非特征提取的差异。
五、总结与思考
论文贡献总结:
- 新范式:将多目标跟踪的关联问题重新定义为 in-context ID 预测,端到端可学习,不依赖启发式匹配
- 简洁架构:DETR + ID 字典 + Transformer Decoder,没有复杂的额外模块
- 跨场景验证:DanceTrack(HOTA 69.6/72.0)、SportsMOT(HOTA 72.6)和 BFT(鸟类追踪,HOTA 70.5)三个基准上均达到 SOTA
- 轨迹增强:随机遮挡 + 随机交换,有效弥合训练和推理之间的分布差异
MOTIP 最值得关注的不是具体的数字提升,而是它对 MOT 关联问题的重新定义。传统方法把关联看作"匹配问题"(在两组对象之间找最优对应),MOTIP 把它看作"预测问题"(给定上下文,预测 ID 标签)。这种视角转换带来了两个结构性优势:
- 端到端可学习:匹配规则不再需要手工设计,模型直接从数据中学习最优的关联策略
- 上下文感知:ID Decoder 通过 Transformer 的注意力机制看到所有历史轨迹和当前所有检测目标,可以利用全局信息做决策,而传统方法只做两两比较
训练效率也值得一提:8 张 4090,DanceTrack 训练不到一天。对于学术实验室来说门槛不高。
局限方面:
- K 的上限:ID 字典大小 K 限制了同时可追踪的轨迹数量。论文通过回收已结束轨迹的 ID 来缓解(实验显示 token 利用率通常低于 40%),但在极端密集场景下仍可能成为瓶颈
- 架构刻意从简:论文作者明确指出,当前设计遵循"less is more"原则,优先验证 ID 预测范式的可行性。未来可以探索定制化的 ID Decoder 结构、引入运动/深度等额外跟踪线索、以及更精细的轨迹建模技术
总体来说,MOTIP 用一个简洁且符合直觉的思路重新定义了 MOT 的关联问题,在多个高难度基准上取得了一致的 SOTA 结果。作者自己也指出,"MOTIP 的简洁性和显著结果为后续研究留下了大量发展空间"——这正是好 baseline 的特征。
Coovally AI Hub 解读AI前沿——顶会论文解读、开源项目精选、企业落地案例,帮你技术进阶与商业破圈。如果您有技术交流或合作意向,欢迎联系我们和评论区留言讨论~
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号