OpenClaw成本控制:从月花$1000+到$20,API Token优化指南
原创
OpenClaw成本控制:从月花$1000+到$20,API Token优化指南
原创
小明互联网技术分享社区
发布于 2026-03-18 09:34:10
发布于 2026-03-18 09:34:10

最近逛OpenClaw社区,总能刷到不少“踩坑帖”:有人半夜睡一觉,醒来收到$1100的API账单;有人跟风部署“龙虾”,没用到一周就因成本太高忍痛关停;还有人明明只用来处理简单邮件,月底却被几百美元的开销惊到——其实OpenClaw本身开源免费,真正烧钱的,是我们没摸透它的成本逻辑,尤其是API Token调用这块“隐形吞金兽”。
今天不聊虚的,纯实操干货,帮所有养虾人把成本从三位数压到两位数,甚至零成本运行。全程无AI套话,每一步都能直接照搬,看完就能上手优化,避免大家再交冤枉钱。
先搞懂:OpenClaw的成本,到底花在哪些地方?
很多人以为养虾只需要付API钱,其实不然,完整运行OpenClaw的成本主要分两大块,其中API Token调用占比80%以上,是成本控制的核心;另一块是服务器开销,相对可控,甚至能零成本搞定。
先给大家算笔明白账,避免稀里糊涂花钱:
- 核心成本:API Token调用费(占比80%-95%):这是最容易失控的部分,也是我们今天重点聊的内容。OpenClaw的Token消耗和普通聊天AI完全不是一个量级,稍微配置不当,成本就会翻倍,后面会详细拆解消耗原因和优化方法。
- 次要成本:服务器/本地运行费(占比5%-20%):要么租云服务器,要么用自己的电脑本地运行,前者每月几块到十几块,后者基本零成本(只耗电费),对比API费用,几乎可以忽略不计。
除此之外,还有一些零星开销(比如第三方工具接口费、数据存储费),但对个人用户和小型团队来说,基本可以忽略,重点抓好前两块,就能把养虾成本控住。
重点拆解:API Token调用,为什么这么烧钱?
很多人疑惑,同样是用AI,普通聊天一天花不了几毛钱,OpenClaw却能一天烧几百美元?核心原因是:OpenClaw的Token消耗是“结构性”的,不是按次收费,而是按“多轮推理+上下文+持续运行”叠加消耗,比传统聊天场景多几十甚至上百倍。
结合我自己养虾半年的实操经验,以及社区里的真实踩坑案例,总结出4个最主要的消耗原因,大家可以对照着检查自己的配置,避开这些坑:
1. 多轮推理:一个任务,多次调用
普通聊天是“你问一句,AI答一句”,一次对话只触发一次API调用;但OpenClaw的Agent是“自主思考”,一个简单任务,可能会触发5-10次甚至更多API调用。
比如让Agent处理一封邮件,它会先调用API解析邮件内容,再调用API判断优先级,接着调用API生成回复,最后调用API记录到记忆系统——这一套流程下来,Token消耗是单次聊天的好几倍。如果是复杂任务(比如写代码、做市场分析),多轮推理的次数会更多,消耗直接翻倍。
2. 上下文叠加:每次调用,都要“带行李”
OpenClaw有记忆系统(MEMORY.md + Daily Logs),为了让Agent“记住”之前的操作和任务,每次调用API时,都会附带完整的上下文内容。这就相当于每次出门都要带一堆行李,行李越重,消耗的Token就越多。
我做过测试,一个活跃的Agent会话,上下文会快速膨胀到20万Token以上,哪怕只是简单的问候,每次调用也要携带这些上下文,长期下来,消耗积少成多,不知不觉就花了很多钱。
3. Skills注入:额外增加输入Token
我们给Agent配置的Skills(技能),会自动注入到system prompt里,每次调用API时,这些Skills描述都会作为输入内容,额外消耗Token。尤其是Skills配置得多、描述得详细,每次请求的输入Token都会增加,长期运行下来,也是一笔不小的开销。
4. 24/7持续运行:定时任务不停触发
很多人部署Agent后,会设置cron定时任务,让它24小时不间断运行(比如每小时检查一次邮件、每半小时执行一次监控)。这种情况下,哪怕没有手动触发任务,Agent也会定时调用API,相当于“全天候烧钱”。
社区里最经典的踩坑案例:有用户设置了Agent处理邮件的cron任务,晚上睡觉前一切正常,第二天早上发现API账单暴涨到$1100,原因就是Agent处理邮件时进入了循环推理,一整晚不停调用API,相当于“连夜烧钱”。
实操干货:API Token成本优化,这5招最管用
搞懂了消耗原因,优化就有方向了。结合我自己的优化经验,以及社区里验证过的有效方法,整理出5招实操技巧,从易到难,新手也能快速上手,重点是不用改复杂代码,只需要调整配置,就能降低80%-95%的API成本。
第一招:必做!设置日预算上限
这是最基础、最有效的一步,哪怕你不差钱,也一定要设置,相当于给你的钱包装一个“安全锁”,避免Agent进入循环推理时,无限制消耗Token。
OpenClaw支持在配置中直接设置日预算,可以参考下面的代码,粘贴到你的配置文件里,修改一下数值就能用(新手建议直接用默认值):
{
"agents": {
"defaults": {
"budget": {
"maxTokensPerDay": 500000,
"maxCostPerDay": 5.00
}
}
}
}我自己设置的是每日$5上限,哪怕Agent偶尔出问题,一天也最多花5美元,不会出现一夜几百上千美元的情况,安全感拉满。
第二招:核心优化!用Fallback链,让便宜模型干简单活
Fallback链是OpenClaw核心的省钱策略,原理很简单:主模型不可用时,自动降级到更便宜的模型;但更有效的用法是——主动用它区分任务难度,让贵的模型干复杂任务,便宜的模型干简单任务,从根源上减少贵模型的调用次数。
这里给大家推荐一个经过验证的三级Fallback配置(直接复制使用),能降低80%-95%的API成本:
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6", // 主力模型,处理复杂任务(写代码、复杂推理)
"fallbacks": [
"anthropic/claude-haiku-4-5", // 降级模型1,处理中等难度任务(邮件回复、简单分析)
"deepseek/deepseek-chat" // 降级模型2,处理简单任务(问候、查天气、心跳任务)
]
}
}
}
}通过下图真实的成本对比,一眼就知道有多香:
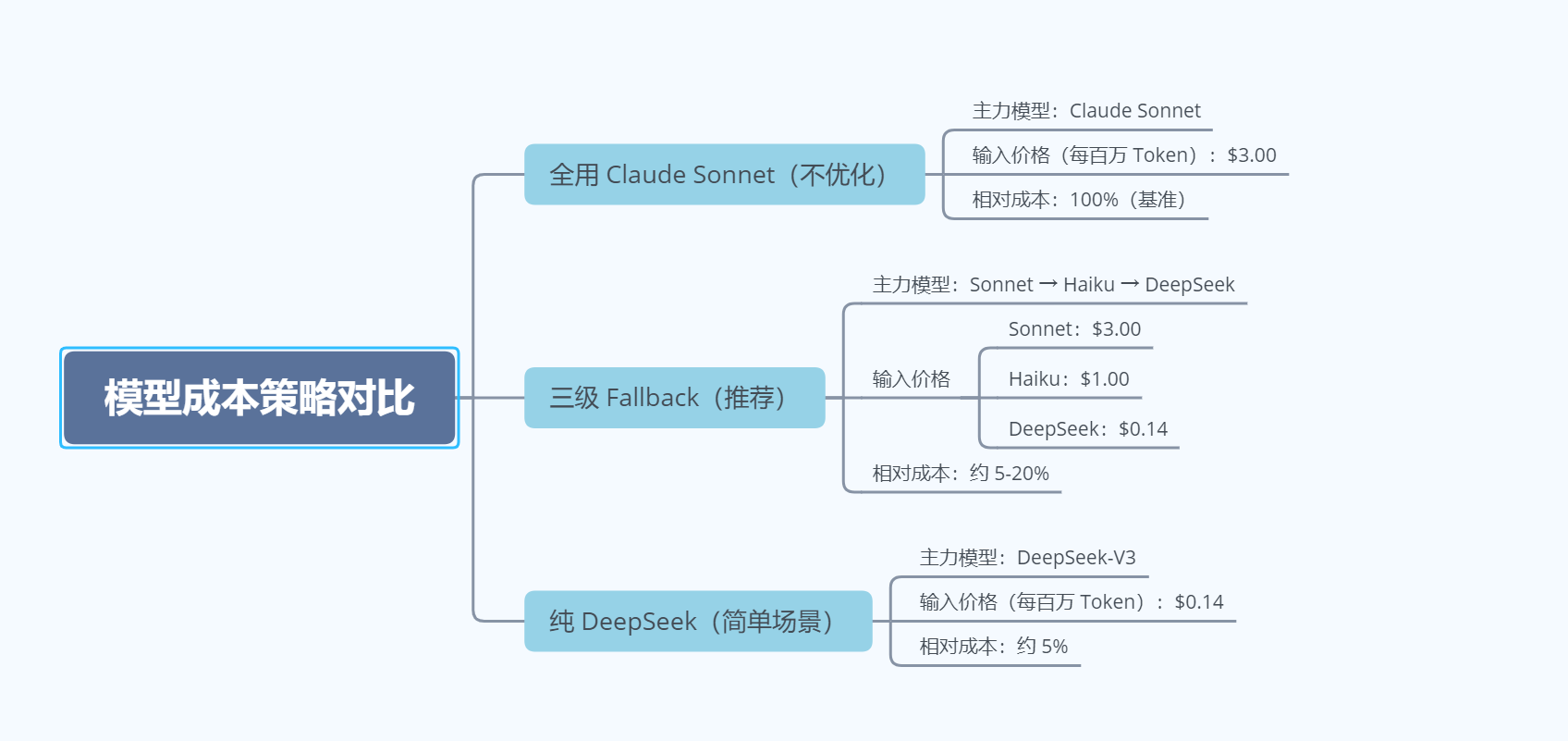
简单说,大部分简单任务(比如查天气、问候、简单查询),都会自动走最便宜的DeepSeek,只有复杂任务才会用到贵的Claude Sonnet,相当于“该省省,该花花”,不浪费一分钱。
第三招:进阶优化!减少上下文冗余
上下文叠加是Token消耗的主要原因之一,我们可以通过两个简单操作,减少冗余上下文,降低消耗:
- 精简记忆系统:只保留必要的记忆内容(比如核心任务记录、常用配置),删除不必要的Daily Logs,避免每次调用都携带大量无关内容。
- 设置上下文过期时间:在配置中设置会话上下文的过期时间(比如12小时),超过时间自动清除,避免上下文无限膨胀,尤其适合长期运行的定时任务。
这一步不用改复杂代码,只需要整理一下记忆文件,新手也能轻松操作,亲测能减少30%左右的Token消耗。
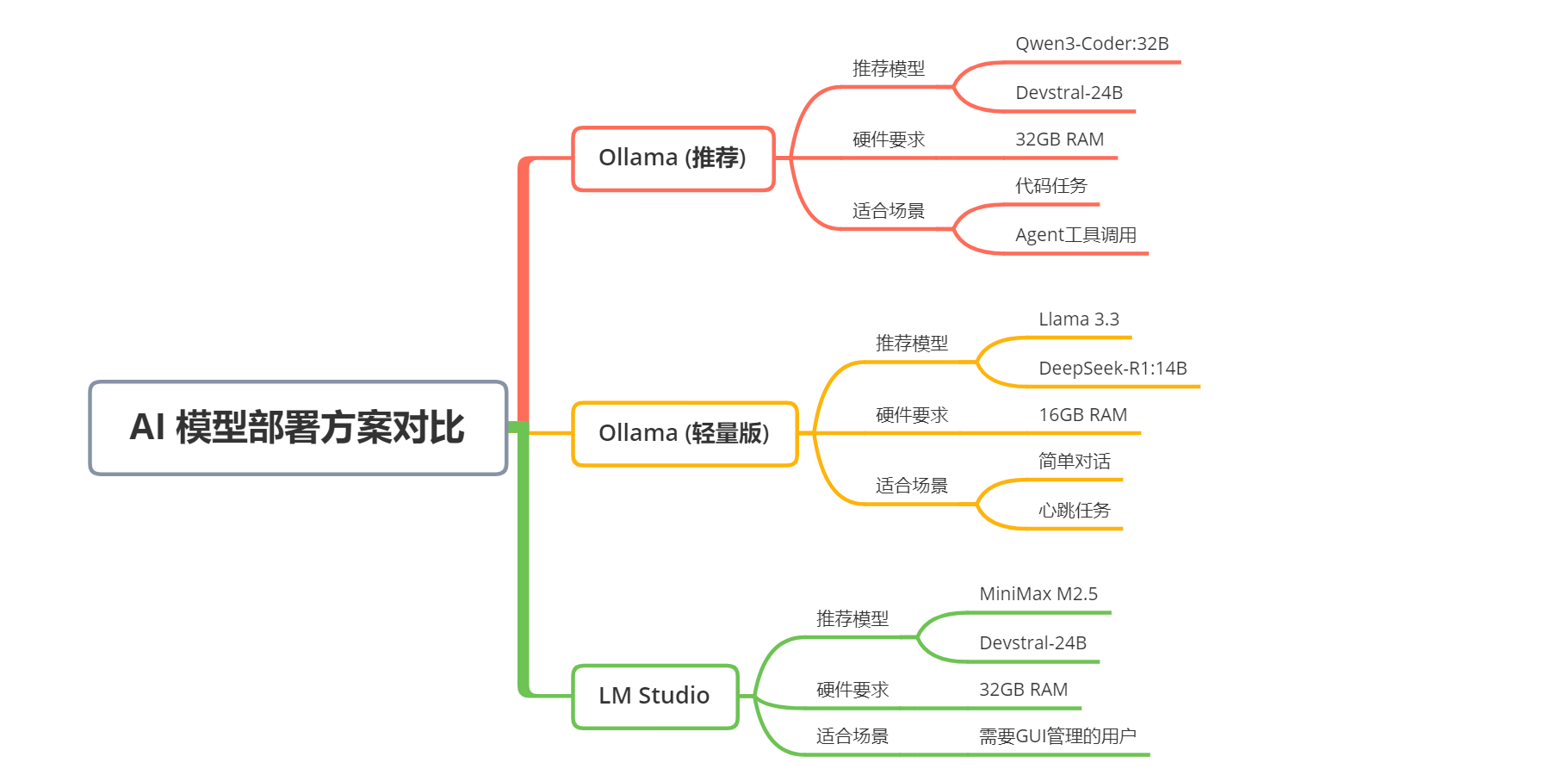
第四招:零成本方案!本地部署模型,彻底告别API费用
如果你的需求只是简单对话、心跳任务、基础工具调用,完全可以不用API,通过Ollama或LM Studio运行本地模型,实现零API成本,只需要支付少量电费。
给大家整理了3个本地部署方案,根据自己的电脑配置选择,直接照搬操作:
这里给大家贴一个Ollama的安装和配置步骤:
# 1. 安装Ollama(官网下载对应系统版本,安装后执行下面的命令)
ollama pull qwen3-coder:32b
# 2. 配置OpenClaw,自动发现本地模型(只需设置环境变量)
# OLLAMA_API_KEY可以是任意值,随便填即可
{
"env": { "OLLAMA_API_KEY": "ollama-local" }
}重点提醒:使用Ollama时,不要用 /v1 OpenAI兼容URL,会导致工具调用异常,让OpenClaw使用原生Ollama API,就能自动发现本地模型,不用额外配置。
第五招:细节优化!避免定时任务“无效消耗”
很多人设置了cron定时任务后,就不管了,导致Agent在没有任务的情况下,依然频繁调用API,浪费Token。这里给大家两个细节优化建议:
- 调整定时任务频率:根据自己的需求设置频率,比如处理邮件,不用每小时检查一次,设置为每天3次(早、中、晚)即可,减少无效调用。
- 添加任务判断条件:在配置中添加判断逻辑,只有当有新任务(比如新邮件、新消息)时,才触发API调用,没有任务时,Agent处于休眠状态,不消耗Token。
服务器成本
聊完了核心的API成本,再简单说一下服务器成本,这部分相对简单,新手可以根据自己的情况选择,每月最低0元就能搞定:
方案 | 月费 | 说明 |
|---|---|---|
腾讯云Lighthouse | 约¥8-12/月 | 社区支持好,新手易上手 |
Fly.io | 免费起步 | 有免费额度,适合轻度使用(每天运行几小时) |
本地电脑运行 | ¥0 | 利用现有电脑,只需保持开机,适合长期在家办公的用户 |
最后总结:养虾不烧钱的核心逻辑
其实OpenClaw成本失控,不是工具本身贵,而是我们没有找对方法。核心逻辑很简单:用对的模型做对的事,用最低的成本满足需求。
给大家推荐一个我自己一直在用的混合模型策略,月均成本只有$5-20,兼顾效率和省钱:
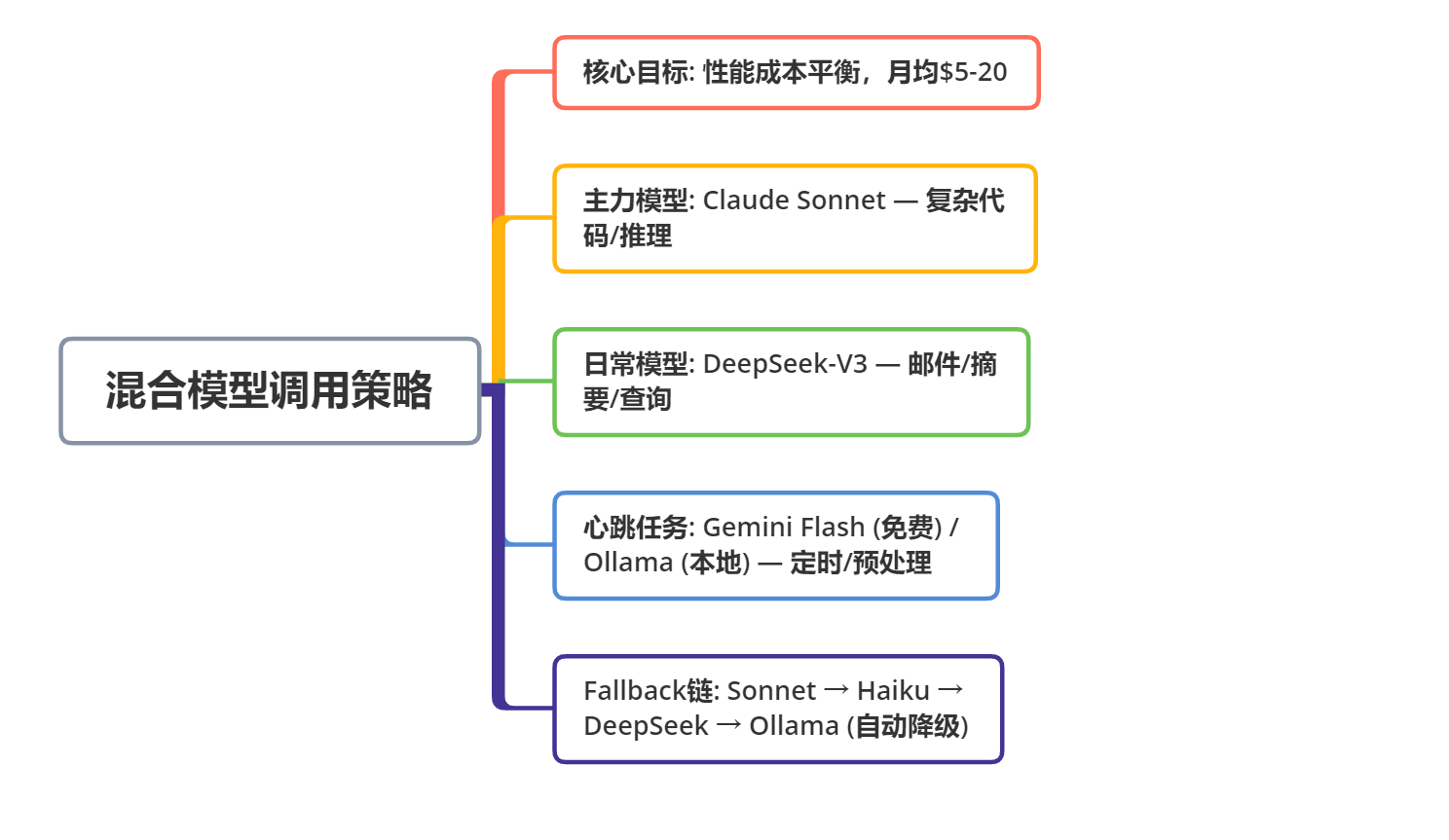
- 主力模型:Claude Sonnet(处理复杂任务,比如写代码、复杂推理)
- 日常模型:DeepSeek-V3(处理简单任务,比如邮件回复、简单查询)
- 心跳任务:Gemini Flash(免费额度)或本地Ollama(零成本)
- Fallback链:Sonnet → Haiku → DeepSeek(自动降级,减少贵模型消耗)
再加上日预算上限,两招就能把月成本从三位数压到两位数甚至个位数。
最后提醒一句:养虾的核心是“实用”,不是“堆配置”。根据自己的需求选择合适的方案,不用追求最顶级的模型,也不用24小时不间断运行,适合自己的,才是最省钱的。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号