最近一周约了30多场面试,感觉有点飘了~


先来唠唠
不知道大家有没有发现,最近分享的面经其实都来自同一位学员。今天就来聊一下他的求职经历,说不定能给正在找工作的你一些启发。
他是本科软件工程毕业,有四年工作经验,后面有长达一年的职业空窗期。今年 9 月中旬,他加入我们,开启了集中冲刺找工作的节奏。
第一次和他做完模拟面试,我就确定他一定能找到一个满意的岗位。哪怕他之前做的是运维相关的工作技术难度不高,哪怕空窗期不算短,但他身上的特质太加分了:性格开朗,思维活跃,执行力特别强。每天他都会在群里带着各种各样的问题和我们大家一起讨论。
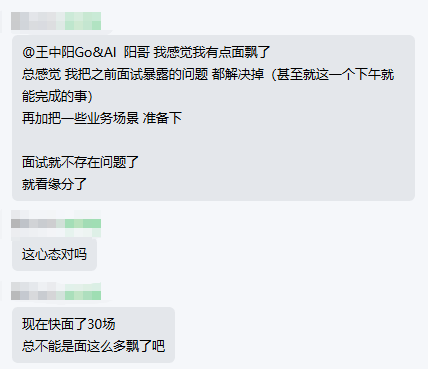
现在看来我的判断很正确,最近一周,他足足约到了 30 多场面试,连他自己都调侃说有点 “飘” 了~
他还有个做得特别好的地方,也是我们一直反复跟学员强调的,那就是面试后的复盘。不管每场面试结果如何、有没有通过,他都会认真总结,提炼经验、弥补不足,可以说这是他快速进步的关键。
话说回来,你们找工作时,一周最多约过多少场面试?欢迎大家在评论区晒一晒,看看有没有比他更厉害的面霸!
下面分享一篇他最近在百度AI架构师的面试,学习起来!
面经分享
北京 百度AI架构师 正式岗
给百度文心一言 大模型 做文心助手 类似豆包 元宝 千问,入口会放在百度贴吧以及其他应用
- 自我介绍
- 聊聊项目,总结为 对于一些比较老的项目,技术债务怎么处理,包括业务逻辑、老的数据库
- 对于老数据库 你们有考虑过迁移导出吗?不进行迁移导出的话 你们最后的业务逻辑是怎么去处理的?
- 讲一讲 你们用Binlog去监听 实现消息推送的一个业务设计
- 你们使用消息队列的话 如何去保证消息的一个幂等性(消息重复问题)
- 经典问题 redis 穿透 击穿 雪崩问题处理
缓存穿透是指查询的数据在缓存和数据库里都没有,导致请求直接冲击数据库。可以通过缓存空值(设短过期时间)、用布隆过滤器提前过滤不存在的键,或者在接口层校验拦截非法请求来处理。
缓存击穿是热点 key 突然过期,大量并发请求同时绕过缓存访问数据库。解决方式包括让热点 key 永不过期(主动更新)、用互斥锁控制只有一个线程去查数据库(其他线程等待重试),或者提前把热点数据加载到缓存。
缓存雪崩是大量 key 同时过期,或者 Redis 服务故障,导致所有请求一下子全打到数据库。可以给过期时间加随机值避免同时失效,给 Redis 做高可用(主从、集群),加多级缓存(本地缓存 + Redis),用服务熔断降级保护数据库,还可以做好持久化让 Redis 故障后快速恢复数据。
- golang的协程底层调用(GMP机制)
Golang 的 GMP 机制是协程调度的核心,G 指协程(用户态轻量线程,占内存少、切换快),M 是操作系统内核线程(实际执行的载体),P 是处理器(相当于 “中间调度器”,保存着 G 的运行所需资源,比如本地队列)。
P 的数量默认和 CPU 核心数一致,它是 G 和 M 的桥梁 —— 只有 M 绑定了 P,才能从 P 的本地队列里取 G 来执行。当一个 G 运行时,如果遇到阻塞(比如 IO 操作),P 会和当前 M 解绑,再找另一个空闲的 M 来运行队列里的其他 G,避免线程空转。
另外,P 的本地队列装不下的 G 会放到全局队列,当某个 P 的本地队列空了,还会去全局队列或其他 P 的队列 “偷” G 来执行(工作窃取),这样能充分利用多核资源,让大量协程高效调度。
- golang map是并发安全吗?为什么?想并发使用怎么处理?
Golang的原生map不是并发安全的。因为map内部数据结构(比如哈希表、链表)在并发读写时,可能会出现数据竞争(比如同时扩容、修改键值对),导致内部状态被破坏,Go运行时会检测到这种情况并直接触发panic,防止数据损坏。
想并发使用map,主要有两种处理方式:
- 用锁保护:通过
sync.Mutex或sync.RWMutex加锁。RWMutex更适合读多写少的场景,读操作加读锁(多个读可并发),写操作加写锁(独占),能提高效率。 - 使用
sync.Map:Go 1.9引入的并发安全map,内部做了特殊优化,适合键值对频繁增删或存在大量临时键的场景,直接调用其Load、Store等方法即可安全并发操作。 - go语言 New和make有什么区别?
Go 语言中 new 和 make 都是用于分配内存的内置函数,但用法和适用场景不同:
new 可以用于任何类型,它会为该类型分配一块零值内存,返回的是指向该类型的指针(即 *T)。比如 new(int) 会返回 *int,指向 0;new(struct{}) 返回指向空结构体的指针。
make 只能用于切片(slice)、映射(map)、通道(channel) 这三种引用类型,它不仅分配内存,还会初始化它们的内部数据结构(比如 slice 的长度和容量、map 的哈希表、channel 的缓冲区),返回的是类型本身(即 T),而不是指针。比如 make([]int, 2) 返回一个长度为 2 的 []int 切片。
简单说:new 偏重于“分配零值内存并返回指针”,适用于所有类型;make 偏重于“初始化引用类型的内部结构”,只用于 slice、map、channel。
- 在你的业务中 你的消息一致性是怎么做的
- (我多余提这个问题)你们redis分布式锁 不用luna脚本的话 怎么去实现多服务器扣减?
- 你们的智能旅行助手 是怎么实现上下文存储 保证记忆的
- 你们这个AI项目 为什么要有mysql
- 开放性问题 如果以后景区人气暴涨,用户和AI助手的交互多起来,对话很大,你会从哪些方面提供更个性化的服务
- 算法题:给定一个 升序 不重复数组,随机以一个元素为准 进行左旋。然后给一个target 在旋转后的数组 找这个target数。要求 时间复杂度在o(logN)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号