R语言实战结构方程模型(代码+解读+画图)


在正式介绍R语言实战结构方程模型之前,我们已经铺垫了3篇内容:
- 结构方程模型的基础知识
- lavaan包的使用方法
- R语言实战验证性因子分析
有了前面的铺垫,R语言结构方程模型所需要的理论知识就差不多了,下面给大家介绍R语言做结构方程模型。这部分将通过两个具体的示例进行介绍,先介绍一个简单的,再介绍一个复杂的。
示例1
首先是孙振球医学统计学第5版例23-3。
为了研究Stroke-PRO量表生理领域与心理领域中不同维度之间的内在联系以及各维度之间的因果关联,采用该量表收集295例脑卒中患者生理领域及心理领域的数据。以生理领域的躯体症状(SOS)和心理领域的焦虑(ANX)构建一个最简单的结构方程模型,模型只包含一个外生潜变量和内生潜变量。
library(lavaan) # 做SEM
library(haven) # 读取spss格式的数据
df23_3 <- haven::read_sav("datasets/例23-03.sav")
dim(df23_3)
## [1] 295 12
注意根据模型的假设(也就是变量之间的关系)写公式,不要乱写(和使用aov做各种各样的方差分析非常类似),这里的假设有3个:
- 躯体症状(SOS)和所属的各条目之间的关系
- 焦虑(ANX)和所属的各条目之间的关系
- 躯体症状会导致焦虑(这条其实题干中没有明确说明,是根据书中的结果反推的)
所以模型也有3个,前两个是测量模型,第3个是结构模型:
# 前两个公式是测量模型,第3个公式是结构模型
sem_models <- ' sos =~ PHD1+PHD2+PHD3+PHD4+PHD5+PHD6+PHD7
anx =~ PSD1+PSD2+PSD3+PSD4+PSD5
anx ~ sos'
使用sem函数拟合结构方程模型:
fit <- sem(sem_models, data = df23_3)
查看结果,这里输出的结果中包含了标准化的结果:
summary(fit,standardized=T,rsquare = T)
## lavaan 0.6-19 ended normally after 33 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 25
##
## Number of observations 295
##
## Model Test User Model:
##
## Test statistic 161.889
## Degrees of freedom 53
## P-value (Chi-square) 0.000
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## sos =~
## PHD1 1.000 0.695 0.472
## PHD2 0.946 0.148 6.378 0.000 0.658 0.508
## PHD3 1.060 0.176 6.041 0.000 0.737 0.466
## PHD4 1.382 0.175 7.894 0.000 0.961 0.785
## PHD5 1.377 0.172 8.029 0.000 0.958 0.824
## PHD6 1.322 0.165 8.023 0.000 0.919 0.822
## PHD7 1.078 0.158 6.839 0.000 0.750 0.575
## anx =~
## PSD1 1.000 0.931 0.721
## PSD2 0.923 0.079 11.747 0.000 0.860 0.720
## PSD3 0.996 0.074 13.379 0.000 0.927 0.824
## PSD4 0.988 0.084 11.718 0.000 0.920 0.719
## PSD5 1.113 0.080 13.882 0.000 1.036 0.859
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## anx ~
## sos 0.790 0.126 6.287 0.000 0.590 0.590
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .PHD1 1.684 0.144 11.686 0.000 1.684 0.777
## .PHD2 1.240 0.107 11.587 0.000 1.240 0.741
## .PHD3 1.959 0.167 11.702 0.000 1.959 0.783
## .PHD4 0.576 0.061 9.513 0.000 0.576 0.384
## .PHD5 0.435 0.050 8.665 0.000 0.435 0.321
## .PHD6 0.406 0.047 8.714 0.000 0.406 0.325
## .PHD7 1.142 0.101 11.355 0.000 1.142 0.670
## .PSD1 0.800 0.076 10.579 0.000 0.800 0.480
## .PSD2 0.685 0.065 10.585 0.000 0.685 0.481
## .PSD3 0.408 0.045 9.033 0.000 0.408 0.322
## .PSD4 0.792 0.075 10.601 0.000 0.792 0.484
## .PSD5 0.381 0.048 8.012 0.000 0.381 0.262
## sos 0.484 0.119 4.064 0.000 1.000 1.000
## .anx 0.565 0.086 6.536 0.000 0.652 0.652
##
## R-Square:
## Estimate
## PHD1 0.223
## PHD2 0.259
## PHD3 0.217
## PHD4 0.616
## PHD5 0.679
## PHD6 0.675
## PHD7 0.330
## PSD1 0.520
## PSD2 0.519
## PSD3 0.678
## PSD4 0.516
## PSD5 0.738
## anx 0.348
结果和验证性因子分析的结果解读一致。只有一个地方需要注意,那就是结果中多了一个Regressions部分,这个结果就是结构模型的结果,展示的是因子之间的关系。
输出结果包括3个部分,第一部分是前9行,主要包含以下信息:
lavaan的版本号- 优化是否正常结束,以及需要多少次迭代
- 使用的估计方法,ML即最大似然法
- 使用的优化器,这里是NLMINB
- 模型参数数量,这里是25
- 分析中实际使用的观测数量,这里是295
- 模型的检验统计量(卡方值)、自由度、P值
第二部分是模型的参数估计。
首先是潜变量和观测变量之间的因子载荷系数,P值小于0.05且载荷系数越大,说明因子(也就是潜变量)和观测变量之间的相关性越强。各列的含义如下:
Estimate:非标准化的载荷系数(和回归分析中的变量系数类似)Std.Err:标准误z-value:Z值P(>|z|):P值Std.lv:标准化的载荷系数,只有潜变量被标准化Std.all:标准化的载荷系数,潜变量和观测变量都被标准化,又被称为“完全标准化解”
然后是3个因子(即潜变量)之间协方差的结果,展示因子与因子之间的相关性。P值小于0.05且Estimate(非标准化的系数)越大说明两个因子相关性越大。
最后是误差的方差(Variances)。其中Estimate是每个观测变量的非标准化误差方差估计值,误差方差代表了观测变量中不能被潜在因子解释的部分,也就是观测变量的变异中无法由模型所设定的潜在因子结构来解释的那部分。较小的误差方差意味着观测变量能较好地被潜在因子解释。剩余3列分别是标准误、Z值和P值。
注意,在Variances部分,观测变量名称之前有一个点。这是因为它们是因变量(或内生变量)(由潜在变量预测),因此,输出中打印的方差值是残差方差(即未被预测变量解释的剩余方差)的估计值。潜变量名称之前没有点,因为在这个模型中它们是外生变量(没有单箭头指向它们),这里的方差值是潜变量的估计总方差。
最后一部分是每个观测变量的R2,这部分结果与书中也是完全一致的。
查看拟合指数:
fitMeasures(fit, fit.measures = c("chisq","df","aic","gfi","rmsea","cfi"))
## chisq df aic gfi rmsea cfi
## 161.889 53.000 10261.913 0.908 0.083 0.932
绘制路径图(注意箭头指向,说明了因果关系):
library(semPlot)
# 换个样式
semPaths(fit,what = 'est' ,whatLabels = 'std' ,style = "lisrel")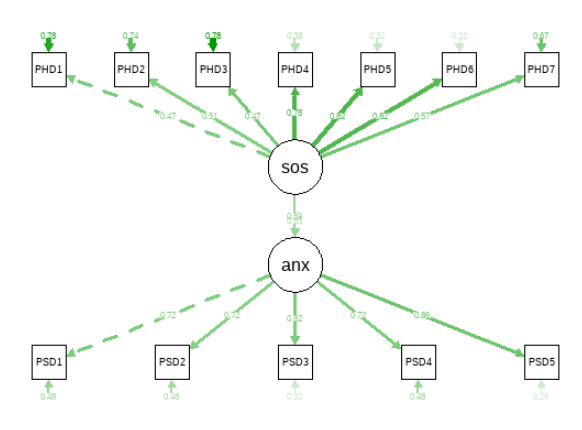
示例2
下面再介绍孙振球医学统计学第5版例23-4。
某一理论模型假设脑卒中患者躯体不适可以引起焦虑(ANX),并间接引起抑郁(DEP)和回避(AVO)。试采用结构方程模型验证此理论假设。以脑卒中患者生理领域的躯体症状(SOS)、认知功能(COG)两个维度和心理领域的焦虑(ANX)、抑郁(DEP)、回避(AVO)三个维度采用最大似然估计法构建结构方程模型。
library(lavaan) # 做SEM
library(haven) # 读取spss格式的数据
df23_4 <- haven::read_sav("datasets/例23-04.sav")
dim(df23_4)
## [1] 295 25
首先还是要搞清楚该研究的假设是什么,然后根据假设写出公式即可。
# 写好公式,谁测量谁...
# 部分公式也是根据书中结果反推的,
# 因为只根据题干没办法得到这么多信息...
sem_models <- ' sos =~ PHD1+PHD2+PHD3+PHD4+PHD5+PHD6+PHD7
cog =~ PHD8+PHD9+PHD10+PHD11
anx =~ PSD1+PSD2+PSD3+PSD4+PSD5
dep =~ PSD6+PSD7+PSD8+PSD9+PSD10
avo =~ PSD11+PSD12+PSD13+PSD14
anx ~ sos
dep ~ anx + avo + cog
avo ~ anx +cog '
后续的结果解读就是和之前一样的了,不再赘述。
fit <- sem(sem_models,data = df23_4)
summary(fit,standardized=T,rsquare = T)
## lavaan 0.6-19 ended normally after 41 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 57
##
## Number of observations 295
##
## Model Test User Model:
##
## Test statistic 747.369
## Degrees of freedom 268
## P-value (Chi-square) 0.000
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## sos =~
## PHD1 1.000 0.691 0.469
## PHD2 0.970 0.151 6.438 0.000 0.670 0.518
## PHD3 1.084 0.178 6.092 0.000 0.749 0.473
## PHD4 1.386 0.177 7.851 0.000 0.957 0.781
## PHD5 1.376 0.173 7.977 0.000 0.950 0.817
## PHD6 1.313 0.165 7.954 0.000 0.907 0.811
## PHD7 1.112 0.161 6.908 0.000 0.768 0.588
## cog =~
## PHD8 1.000 0.933 0.736
## PHD9 1.129 0.088 12.858 0.000 1.053 0.818
## PHD10 1.067 0.086 12.388 0.000 0.996 0.780
## PHD11 0.781 0.084 9.267 0.000 0.728 0.579
## anx =~
## PSD1 1.000 0.918 0.711
## PSD2 0.928 0.080 11.593 0.000 0.852 0.714
## PSD3 1.017 0.076 13.383 0.000 0.933 0.829
## PSD4 1.012 0.086 11.769 0.000 0.928 0.725
## PSD5 1.123 0.082 13.749 0.000 1.031 0.854
## dep =~
## PSD6 1.000 0.851 0.767
## PSD7 1.098 0.070 15.686 0.000 0.934 0.855
## PSD8 1.085 0.079 13.668 0.000 0.923 0.762
## PSD9 0.991 0.080 12.388 0.000 0.843 0.700
## PSD10 1.040 0.067 15.508 0.000 0.885 0.847
## avo =~
## PSD11 1.000 1.003 0.883
## PSD12 0.963 0.052 18.547 0.000 0.966 0.846
## PSD13 0.871 0.059 14.693 0.000 0.873 0.729
## PSD14 0.799 0.063 12.740 0.000 0.801 0.660
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## anx ~
## sos 0.832 0.129 6.440 0.000 0.626 0.626
## dep ~
## anx 0.342 0.058 5.910 0.000 0.369 0.369
## avo 0.371 0.058 6.420 0.000 0.437 0.437
## cog 0.224 0.047 4.797 0.000 0.246 0.246
## avo ~
## anx 0.609 0.071 8.634 0.000 0.557 0.557
## cog 0.356 0.063 5.626 0.000 0.331 0.331
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## sos ~~
## cog 0.401 0.071 5.666 0.000 0.622 0.622
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .PHD1 1.690 0.144 11.716 0.000 1.690 0.780
## .PHD2 1.223 0.106 11.586 0.000 1.223 0.731
## .PHD3 1.942 0.166 11.706 0.000 1.942 0.776
## .PHD4 0.585 0.060 9.711 0.000 0.585 0.389
## .PHD5 0.449 0.050 9.014 0.000 0.449 0.332
## .PHD6 0.429 0.047 9.164 0.000 0.429 0.343
## .PHD7 1.115 0.098 11.337 0.000 1.115 0.654
## .PHD8 0.739 0.076 9.738 0.000 0.739 0.459
## .PHD9 0.550 0.069 8.007 0.000 0.550 0.332
## .PHD10 0.638 0.071 8.940 0.000 0.638 0.391
## .PHD11 1.052 0.094 11.138 0.000 1.052 0.665
## .PSD1 0.825 0.076 10.841 0.000 0.825 0.495
## .PSD2 0.698 0.065 10.816 0.000 0.698 0.490
## .PSD3 0.396 0.043 9.294 0.000 0.396 0.312
## .PSD4 0.777 0.072 10.726 0.000 0.777 0.474
## .PSD5 0.393 0.045 8.649 0.000 0.393 0.270
## .PSD6 0.507 0.047 10.682 0.000 0.507 0.412
## .PSD7 0.320 0.034 9.321 0.000 0.320 0.269
## .PSD8 0.617 0.057 10.731 0.000 0.617 0.420
## .PSD9 0.740 0.066 11.168 0.000 0.740 0.510
## .PSD10 0.308 0.032 9.514 0.000 0.308 0.283
## .PSD11 0.283 0.038 7.522 0.000 0.283 0.220
## .PSD12 0.370 0.042 8.831 0.000 0.370 0.284
## .PSD13 0.672 0.063 10.703 0.000 0.672 0.468
## .PSD14 0.831 0.074 11.172 0.000 0.831 0.564
## sos 0.477 0.118 4.043 0.000 1.000 1.000
## cog 0.871 0.126 6.902 0.000 1.000 1.000
## .anx 0.512 0.080 6.408 0.000 0.608 0.608
## .dep 0.146 0.026 5.658 0.000 0.202 0.202
## .avo 0.438 0.057 7.705 0.000 0.436 0.436
##
## R-Square:
## Estimate
## PHD1 0.220
## PHD2 0.269
## PHD3 0.224
## PHD4 0.611
## PHD5 0.668
## PHD6 0.657
## PHD7 0.346
## PHD8 0.541
## PHD9 0.668
## PHD10 0.609
## PHD11 0.335
## PSD1 0.505
## PSD2 0.510
## PSD3 0.688
## PSD4 0.526
## PSD5 0.730
## PSD6 0.588
## PSD7 0.731
## PSD8 0.580
## PSD9 0.490
## PSD10 0.717
## PSD11 0.780
## PSD12 0.716
## PSD13 0.532
## PSD14 0.436
## anx 0.392
## dep 0.798
## avo 0.564
# fitMeasures(fit, fit.measures = c("chisq","df","aic","gfi","rmsea","cfi"))
画图:
library(semPlot)
semPaths(fit, 'std','std',style = "lisrel",exoCov = F)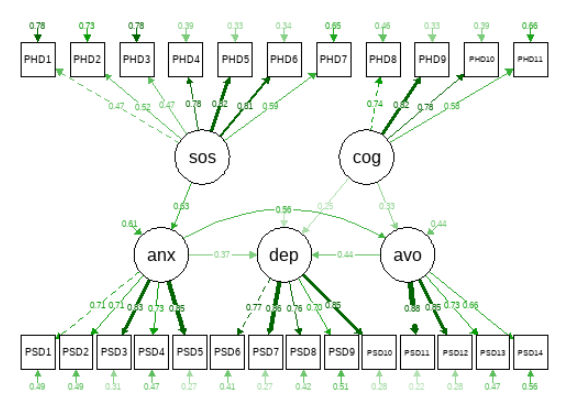
参考资料
- 孙振球《医学统计学》第4版和第5版
- 结构方程模型是什么?一文轻松读懂!
- Using R for Social Work Research
- R语言医学多元统计分析,赵军、戴静毅
- lavaan包官方tutorial
- http://sachaepskamp.com/files/semPlot.pdf
医学和生信笔记,专注R语言在医学中的使用!

三连一下,感谢支持
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号