R语言实战验证性因子分析


数据简介
结合一个具体的例子说明(孙振球医学统计学第5版例23-1)。
某课题组采用脑卒中患者报告临床结局量表(下文简述Stroke-PRO量表)调查了295例脑卒中患者,用于评估其治疗结局。Stroke-PRO量表中,生理领域包含4个维度、20个条目;心理领域包含3个维度、14个条目;社会领域包含2个维度、7个条目;治疗领域包含1个维度、5个条目。量表结构如下:
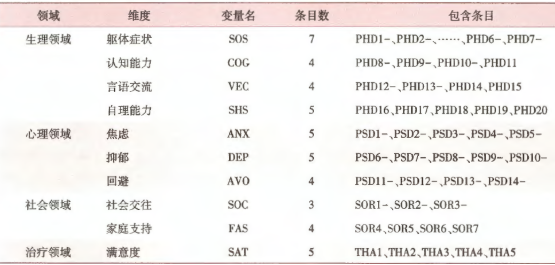
上表中每个条目是一个观测变量,每个维度是一个潜变量。
以生理领域中躯体症状(SOS)这一维度为例,患者的躯体症状无法直接测量,需通过一些相关条目获取,如采用Likert5级计分,维度与条目信息如下:
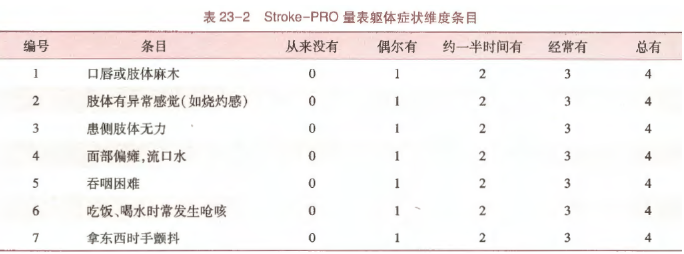
假如我们需要探讨脑卒中患者生理领域的躯体症状、认知能力和心理领域的焦虑、抑郁、回避之间的相互作用关系,将上述维度作为潜变量,各条目作为观测变量,可以从以下两方面着手分析:
- 采用验证性因子分析评价量表的结构效度;
- 采用结构方程模型分析不同维度间的关联关系。
验证性因子分析
验证性因子分析本质上是结构方程模型中的测量模型,常用于评价某个测验或者量表的结构效度(construct validity),又称为构念效度。
构念是指在科学研究中,研究者为了描述、解释和预测现象而构建的抽象概念,如智力、焦虑、工作满意度等。构念本身无法直接观察和测量,需要通过一些可观测的指标(如题目、行为表现等)来间接测量。构念效度指的是测量工具能够准确测量理论上的构念或特质的程度。简单来说,就是看我们所使用的测量工具(如问卷、测试等)是不是真的在测量我们想要测量的那个抽象概念。比如,我们想测量一个人的 “创造力”,那么所设计的测量工具是否真的能准确地把这个人的创造力水平反映出来,而不是测到了其他无关的东西,这就是构念效度要解决的问题。
用验证性因子分析评价Stroke-PRO量表生理领域即其躯体症状(SOS)、认知能力(COG)、言语交流(VEC)及自理能力(SHS)的结构效度。
先读取数据和加载R包:
library(lavaan) # 做SEM
library(haven) # 读取spss格式的数据
df23_2 <- haven::read_sav("datasets/例23-02.sav")
dim(df23_2)
[1] 295 20
#df23_2 <- haven::zap_formats(df23_2)
df23_2[1:4,1:4] # 展示前4行和前4列
# A tibble: 4 × 4
PHD1 PHD2 PHD3 PHD4
<dbl> <dbl> <dbl> <dbl>
1 5 5 5 5
2 4 4 4 5
3 5 5 5 5
4 5 4 5 5
数据结构如上,每一行是一个患者,每一列是一个条目,其中的数字是评分。
首先是构建模型,把潜变量和显变量之间的关系用公式的形式写出来。在这个示例中潜变量就是躯体症状(SOS)、认知能力(COG)、言语交流(VEC)及自理能力(SHS),显变量就是各自对应的条目,所以公式有4个:
# 验证性因子分析只有测量模型,没有结构模型
cfa_models <- ' sos =~ PHD1+PHD2+PHD3+PHD4+PHD5+PHD6+PHD7
cog =~ PHD8+PHD9+PHD10+PHD11
vec =~ PHD12+PHD13+PHD14+PHD15
shs =~ PHD16+PHD17+PHD18+PHD19+PHD20 '
使用cfa函数拟合验证性因子分析模型即可:
fit <- cfa(cfa_models, data = df23_2)
结果解读及画图
查看拟合结果(结果和书中基本是一样的):
summary(fit, standardized=T, rsquare = T)
lavaan 0.6-19 ended normally after 46 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 46
Number of observations 295
Model Test User Model:
Test statistic 630.894
Degrees of freedom 164
P-value (Chi-square) 0.000
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
sos =~
PHD1 1.000 0.675 0.458
PHD2 0.975 0.156 6.259 0.000 0.658 0.508
PHD3 1.088 0.184 5.925 0.000 0.734 0.464
PHD4 1.415 0.185 7.647 0.000 0.955 0.779
PHD5 1.433 0.183 7.811 0.000 0.966 0.831
PHD6 1.363 0.175 7.785 0.000 0.920 0.822
PHD7 1.121 0.167 6.721 0.000 0.756 0.579
cog =~
PHD8 1.000 0.931 0.734
PHD9 1.107 0.087 12.723 0.000 1.031 0.800
PHD10 1.088 0.086 12.635 0.000 1.013 0.794
PHD11 0.804 0.084 9.554 0.000 0.749 0.595
vec =~
PHD12 1.000 1.000 0.724
PHD13 0.965 0.081 11.942 0.000 0.965 0.737
PHD14 0.659 0.065 10.068 0.000 0.659 0.621
PHD15 0.779 0.071 11.018 0.000 0.779 0.680
shs =~
PHD16 1.000 1.031 0.737
PHD17 1.233 0.080 15.470 0.000 1.271 0.873
PHD18 1.394 0.090 15.562 0.000 1.437 0.878
PHD19 1.390 0.088 15.706 0.000 1.432 0.885
PHD20 1.407 0.085 16.493 0.000 1.450 0.926
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
sos ~~
cog 0.372 0.068 5.477 0.000 0.592 0.592
vec 0.474 0.082 5.792 0.000 0.702 0.702
shs 0.210 0.053 3.921 0.000 0.302 0.302
cog ~~
vec 0.737 0.096 7.682 0.000 0.792 0.792
shs 0.263 0.068 3.893 0.000 0.274 0.274
vec ~~
shs 0.653 0.093 7.057 0.000 0.634 0.634
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.PHD1 1.712 0.146 11.739 0.000 1.712 0.790
.PHD2 1.240 0.107 11.612 0.000 1.240 0.742
.PHD3 1.964 0.167 11.726 0.000 1.964 0.785
.PHD4 0.590 0.061 9.725 0.000 0.590 0.393
.PHD5 0.418 0.048 8.631 0.000 0.418 0.309
.PHD6 0.406 0.046 8.863 0.000 0.406 0.324
.PHD7 1.132 0.100 11.370 0.000 1.132 0.664
.PHD8 0.742 0.075 9.853 0.000 0.742 0.461
.PHD9 0.597 0.069 8.622 0.000 0.597 0.360
.PHD10 0.603 0.069 8.778 0.000 0.603 0.370
.PHD11 1.022 0.092 11.087 0.000 1.022 0.646
.PHD12 0.907 0.088 10.255 0.000 0.907 0.476
.PHD13 0.783 0.078 10.088 0.000 0.783 0.457
.PHD14 0.692 0.062 11.111 0.000 0.692 0.614
.PHD15 0.708 0.066 10.704 0.000 0.708 0.538
.PHD16 0.892 0.079 11.328 0.000 0.892 0.457
.PHD17 0.504 0.051 9.894 0.000 0.504 0.238
.PHD18 0.614 0.063 9.784 0.000 0.614 0.229
.PHD19 0.567 0.059 9.594 0.000 0.567 0.216
.PHD20 0.349 0.044 7.899 0.000 0.349 0.142
sos 0.455 0.116 3.935 0.000 1.000 1.000
cog 0.867 0.126 6.909 0.000 1.000 1.000
vec 1.000 0.146 6.847 0.000 1.000 1.000
shs 1.062 0.146 7.277 0.000 1.000 1.000
R-Square:
Estimate
PHD1 0.210
PHD2 0.258
PHD3 0.215
PHD4 0.607
PHD5 0.691
PHD6 0.676
PHD7 0.336
PHD8 0.539
PHD9 0.640
PHD10 0.630
PHD11 0.354
PHD12 0.524
PHD13 0.543
PHD14 0.386
PHD15 0.462
PHD16 0.543
PHD17 0.762
PHD18 0.771
PHD19 0.784
PHD20 0.858
输出结果包括3个部分,第一部分是前9行,主要包含以下信息:
lavaan的版本号- 优化是否正常结束,以及需要多少次迭代
- 使用的估计方法,ML即最大似然法
- 使用的优化器,这里是NLMINB
- 模型参数数量,这里是46
- 分析中实际使用的观测数量,这里是295
- 模型的检验统计量(卡方值)、自由度、P值
第二部分是模型的参数估计。
首先是潜变量和观测变量之间的因子载荷系数,P值小于0.05且载荷系数越大,说明因子(也就是潜变量)和观测变量之间的相关性越强。各列的含义如下:
Estimate:非标准化的载荷系数(和回归分析中的变量系数类似)Std.Err:标准误z-value:Z值P(>|z|):P值Std.lv:标准化的载荷系数,只有潜变量被标准化Std.all:标准化的载荷系数,潜变量和观测变量都被标准化,又被称为“完全标准化解”
然后是3个因子(即潜变量)之间协方差的结果,展示因子与因子之间的相关性。P值小于0.05且Estimate(非标准化的系数)越大说明两个因子相关性越大。
最后是误差的方差(Variances)。其中Estimate是每个观测变量的非标准化误差方差估计值,误差方差代表了观测变量中不能被潜在因子解释的部分,也就是观测变量的变异中无法由模型所设定的潜在因子结构来解释的那部分。较小的误差方差意味着观测变量能较好地被潜在因子解释。剩余3列分别是标准误、Z值和P值。
注意,在Variances部分,观测变量名称之前有一个点。这是因为它们是因变量(或内生变量)(由潜在变量预测),因此,输出中打印的方差值是残差方差(即未被预测变量解释的剩余方差)的估计值。潜变量名称之前没有点,因为在这个模型中它们是外生变量(没有单箭头指向它们),这里的方差值是潜变量的估计总方差。
最后一部分是每个观测变量的R2,这部分结果与书中也是完全一致的。
通过以下代码可查看拟合指数(个别值与书中有差别):
# fit.measures = "all"可查看所有拟合指数
fitMeasures(fit, fit.measures = c("chisq","df","aic","gfi","rmsea","cfi"))
chisq df aic gfi rmsea cfi
630.894 164.000 17132.886 0.812 0.098 0.867
summary(fit)给出的因子载荷系数是非标准化的,可通过以下方式输出标准化的结果:
std_res <- standardizedSolution(fit)
std_res # est.std就是标准化的载荷
lhs op rhs est.std se z pvalue ci.lower ci.upper
1 sos =~ PHD1 0.458 0.050 9.218 0 0.361 0.556
2 sos =~ PHD2 0.508 0.047 10.833 0 0.416 0.600
3 sos =~ PHD3 0.464 0.049 9.393 0 0.367 0.561
4 sos =~ PHD4 0.779 0.028 28.190 0 0.725 0.833
5 sos =~ PHD5 0.831 0.024 35.304 0 0.785 0.877
6 sos =~ PHD6 0.822 0.024 33.908 0 0.775 0.870
7 sos =~ PHD7 0.579 0.043 13.620 0 0.496 0.663
8 cog =~ PHD8 0.734 0.033 22.471 0 0.670 0.798
9 cog =~ PHD9 0.800 0.028 28.742 0 0.746 0.855
10 cog =~ PHD10 0.794 0.028 28.033 0 0.738 0.849
11 cog =~ PHD11 0.595 0.043 13.984 0 0.512 0.679
12 vec =~ PHD12 0.724 0.033 22.224 0 0.660 0.788
13 vec =~ PHD13 0.737 0.032 23.324 0 0.675 0.799
14 vec =~ PHD14 0.621 0.040 15.513 0 0.543 0.699
15 vec =~ PHD15 0.680 0.036 18.944 0 0.609 0.750
16 shs =~ PHD16 0.737 0.028 26.007 0 0.682 0.793
17 shs =~ PHD17 0.873 0.016 54.662 0 0.842 0.904
18 shs =~ PHD18 0.878 0.016 56.550 0 0.847 0.908
19 shs =~ PHD19 0.885 0.015 59.683 0 0.856 0.914
20 shs =~ PHD20 0.926 0.011 83.441 0 0.904 0.948
21 PHD1 ~~ PHD1 0.790 0.046 17.348 0 0.701 0.879
22 PHD2 ~~ PHD2 0.742 0.048 15.539 0 0.648 0.835
23 PHD3 ~~ PHD3 0.785 0.046 17.120 0 0.695 0.875
24 PHD4 ~~ PHD4 0.393 0.043 9.119 0 0.308 0.477
25 PHD5 ~~ PHD5 0.309 0.039 7.903 0 0.233 0.386
26 PHD6 ~~ PHD6 0.324 0.040 8.135 0 0.246 0.402
27 PHD7 ~~ PHD7 0.664 0.049 13.474 0 0.568 0.761
28 PHD8 ~~ PHD8 0.461 0.048 9.610 0 0.367 0.555
29 PHD9 ~~ PHD9 0.360 0.045 8.070 0 0.272 0.447
30 PHD10 ~~ PHD10 0.370 0.045 8.237 0 0.282 0.458
31 PHD11 ~~ PHD11 0.646 0.051 12.742 0 0.546 0.745
32 PHD12 ~~ PHD12 0.476 0.047 10.082 0 0.383 0.568
33 PHD13 ~~ PHD13 0.457 0.047 9.798 0 0.365 0.548
34 PHD14 ~~ PHD14 0.614 0.050 12.357 0 0.517 0.712
35 PHD15 ~~ PHD15 0.538 0.049 11.036 0 0.443 0.634
36 PHD16 ~~ PHD16 0.457 0.042 10.922 0 0.375 0.538
37 PHD17 ~~ PHD17 0.238 0.028 8.521 0 0.183 0.292
38 PHD18 ~~ PHD18 0.229 0.027 8.417 0 0.176 0.283
39 PHD19 ~~ PHD19 0.216 0.026 8.246 0 0.165 0.268
40 PHD20 ~~ PHD20 0.142 0.021 6.921 0 0.102 0.183
41 sos ~~ sos 1.000 0.000 NA NA 1.000 1.000
42 cog ~~ cog 1.000 0.000 NA NA 1.000 1.000
43 vec ~~ vec 1.000 0.000 NA NA 1.000 1.000
44 shs ~~ shs 1.000 0.000 NA NA 1.000 1.000
45 sos ~~ cog 0.592 0.048 12.352 0 0.498 0.686
46 sos ~~ vec 0.702 0.042 16.625 0 0.620 0.785
47 sos ~~ shs 0.302 0.059 5.146 0 0.187 0.416
48 cog ~~ vec 0.792 0.037 21.314 0 0.719 0.865
49 cog ~~ shs 0.274 0.061 4.488 0 0.154 0.394
50 vec ~~ shs 0.634 0.045 14.210 0 0.546 0.721
# 或者使用:
#summary(fit,standardized = T)
summary(fit)中支持的参数非常多,比如也可以直接输出系数的可信区间、拟合指数等,大家可以参考该函数的帮助文档。
绘制路径图(结果与书中一致),这个semPlot功能很强大,以后再详细介绍:
library(semPlot)
semPaths(fit
,what = 'col' # 线条用不同的颜色表示
,groups = "latents" # 根据潜变量上色
,pastel = TRUE # 选颜色
,whatLabels = 'std' # 显示标准化的载荷
,style = "lisrel" # 使用lisrel软件的风格
,rotation = 2 # 旋转方向
,edge.label.cex = 1 # 载荷字体大小
,mar = c(1, 6, 1, 6) # 控制图形边距
)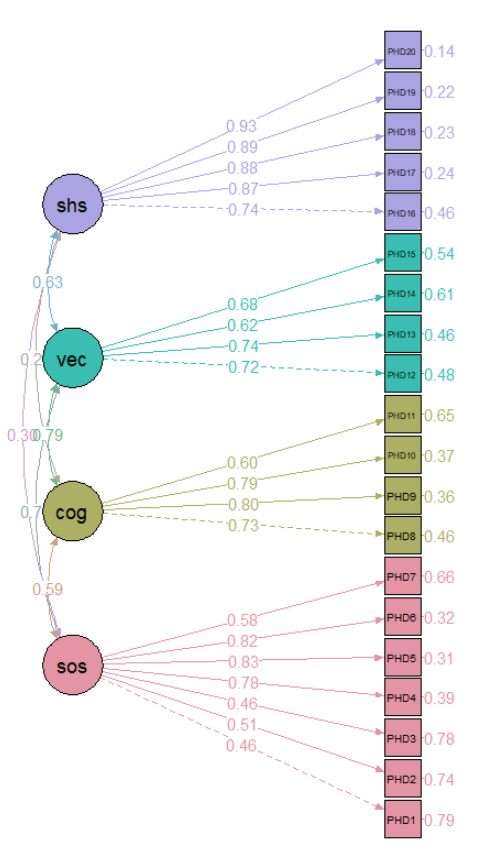
如果只看文字和数字很难看出结果,但是一个图形就能展示所有结果,而且非常直观,不仅展示了潜变量、显变量之间的关系,还标注了因子载荷、相关系数等各种信息(注意上图中展示的载荷系数都是标准化的)。
结论:潜变量于各条目之间的关系可通过因子载荷反应,所有维度与条目间的因子载荷均有统计学意义。拟合指数结果提示拟合效果尚可接受。所有因子载荷均大于0.4,介于0.46到0.93之间。由潜变量之间的相关系数可知,认知(COG)和语言交(VEC)流具有较强相关,认知(COG)和自理能力(SHS)相关性较弱。
医学和生信笔记,专注R语言在医学中的使用!

三连一下,感谢支持
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号