开源本地文档翻译神器,完美保留原格式,还能自动生成术语表(带一键安装包)

开源本地文档翻译神器,完美保留原格式,还能自动生成术语表(带一键安装包)

开源星探
发布于 2026-03-16 20:37:39
发布于 2026-03-16 20:37:39
对于需要处理国际文献的研究员、撰写技术文档的工程师、或是阅读海外产品的运营人员来说,文档翻译是一个高频且痛苦的需求。
我们真正渴望的,不仅仅是将A语言转换成B语言,而是一份在格式、术语和专业性上都与原作媲美的译稿。
最近发现了一款开源项目,可完美地帮助我们达到这一效果——DocuTranslate,一款开源的、本地运行的智能文档翻译工具。

它能在保留原格式的前提下,高质量翻译 PDF、Word、Excel、Markdown 等多种文件类型。
更厉害的是,支持精确识别PDF中的表格、公式和代码块,并进行准确翻译。同时,支持大部分主流的AI模型供应商平台,允许自定义提示词,以及并发高性能AI翻译。
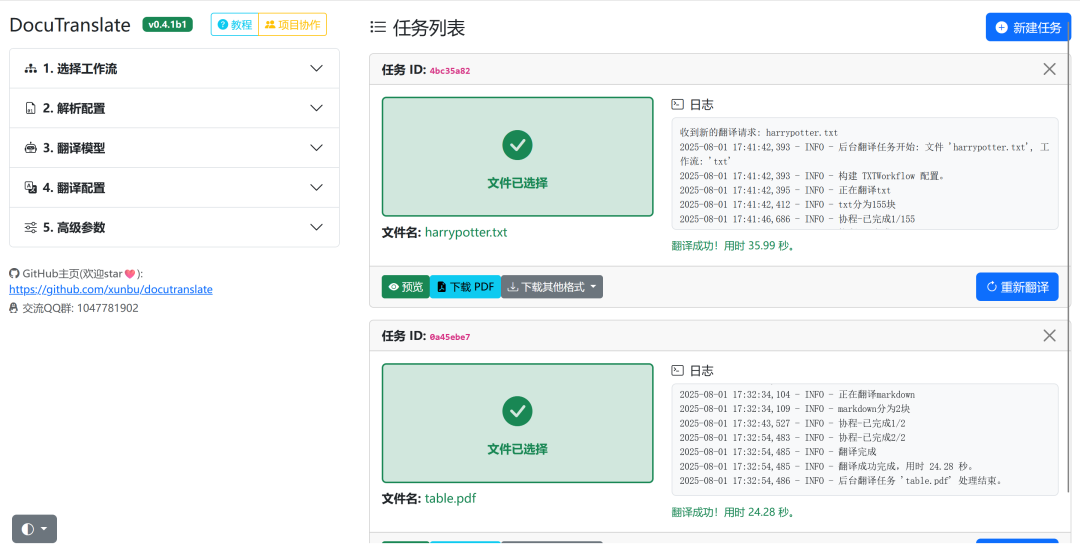

提供Windows、Mac整合包直接下载使用,也可通过pip安装,在局域网内还可以多人同时使用。
核心功能
- • 支持多种格式:能翻译 pdf、docx、xlsx、md、txt、json、epub、srt 、ass等多种文件。
- • 自动生成术语表:支持自动生成术语表实现术语的对齐。
- • PDF表格、公式、代码识别:凭借docling、minerupdf解析引擎实现对学术论文中经常出现的表格、公式、代码的识别与翻译
- • json翻译:支持通过json路径(jsonpath-ng语法规范)指定json中需要被翻译的值。
- • Word/Excel保持格式翻译:支持docx、xlsx文件(暂不支持doc、xls文件)保持原格式进行翻译。
- • 多AI平台支持:支持绝大部分的ai平台,可以实现自定义提示词的并发高性能ai翻译。
- • 异步支持:专为高性能场景设计,提供完整的异步支持,实现了可以多任务并行的服务接口。
- • 局域网、多人使用支持:支持在局域网中多人同时使用。
- • 交互式Web界面:提供开箱即用的 Web UI 和 RESTful API,方便集成与使用。
- • 小体积、多平台懒人包支持:不到40M的windows、mac懒人包(不使用docling本地解析pdf的版本)。
快速上手
DocuTranslate安装简单,支持Windows/Mac整合包一键下载安装,也可使用pip命令通过API集成。
整合包下载
打开项目Release页面,下载DMG/EXE格式文件,一键安装,然后填入你的AI平台API-Key即可开始使用。
如有下载问题,可公众号内回复“DocuTranslate”获取小编准备好的安装包。
注意:
- DocuTranslate: 标准版,使用在线的 minerU 引擎解析PDF文档,如果不需要本地解析pdf选这个版本(推荐)。
- DocuTranslate_full: 完整版,内置 docling 本地PDF解析引擎,需要本地解析pdf选这个版本。
pip安装
# 基础安装
pip install docutranslate
# 如需使用 docling 本地解析PDF
pip install docutranslate[docling]启动 Web UI 和 API 服务
# 启动服务,默认监听 8010 端口
docutranslate -i
# 指定端口启动
docutranslate -i -p 8011
# 也可以通过环境变量指定端口
export DOCUTRANSLATE_PORT=8011
docutranslate -i- 交互式界面: 启动服务后,请在浏览器中访问
http://127.0.0.1:8010(或您指定的端口)。 - API 文档: 完整的 API 文档(Swagger UI)位于
http://127.0.0.1:8010/docs。
使用方式
比如:翻译一个 PDF 文件 (使用 MarkdownBasedWorkflow)
import asyncio
from docutranslate.workflow.md_based_workflow import MarkdownBasedWorkflow, MarkdownBasedWorkflowConfig
from docutranslate.converter.x2md.converter_mineru import ConverterMineruConfig
from docutranslate.translator.ai_translator.md_translator import MDTranslatorConfig
from docutranslate.exporter.md.md2html_exporter import MD2HTMLExporterConfig
async def main():
# 1. 构建翻译器配置
translator_config = MDTranslatorConfig(
base_url="https://open.bigmodel.cn/api/paas/v4", # AI 平台 Base URL
api_key="YOUR_ZHIPU_API_KEY", # AI 平台 API Key
model_id="glm-4-air", # 模型 ID
to_lang="English", # 目标语言
chunk_size=3000, # 文本分块大小
concurrent=10, # 并发数
# glossary_generate_enable=True, # 启用自动生成术语表
# glossary_dict={"Jobs":"乔布斯"}, # 传入术语表
# system_proxy_enable=True,# 启用系统代理
)
# 2. 构建转换器配置 (使用 minerU)
converter_config = ConverterMineruConfig(
mineru_token="YOUR_MINERU_TOKEN", # 你的 minerU Token
formula_ocr=True # 开启公式识别
)
# 3. 构建主工作流配置
workflow_config = MarkdownBasedWorkflowConfig(
convert_engine="mineru", # 指定解析引擎
converter_config=converter_config, # 传入转换器配置
translator_config=translator_config, # 传入翻译器配置
html_exporter_config=MD2HTMLExporterConfig(cdn=True) # HTML 导出配置
)
# 4. 实例化工作流
workflow = MarkdownBasedWorkflow(config=workflow_config)
# 5. 读取文件并执行翻译
print("开始读取和翻译文件...")
workflow.read_path("path/to/your/document.pdf")
await workflow.translate_async()
# 或者使用同步的方式
# workflow.translate()
print("翻译完成!")
# 6. 保存结果
workflow.save_as_html(name="translated_document.html")
workflow.save_as_markdown_zip(name="translated_document.zip")
workflow.save_as_markdown(name="translated_document.md") # 嵌入图片的markdown
print("文件已保存到 ./output 文件夹。")
# 或者直接获取内容字符串
html_content = workflow.export_to_html()
html_content = workflow.export_to_markdown()
# print(html_content)
if __name__ == "__main__":
asyncio.run(main())还有更多使用示例及参考参数也在项目主页文档中查看学习。
适用场景
- • 学术论文翻译:识别公式、引用格式不丢失
- • 技术文档本地化:保留代码块与API结构
- • 数据报告:表格、图表内容精准对齐
- • 多人协作项目:术语表共享,保持一致性
- • 企业内部资料:离线翻译,安全合规
写在最后
DocuTranslate 解决的不仅仅是翻译问题,它解决的是信息跨语言流动时的保真度问题。
它不仅能看懂 PDF,更能理解表格、公式与代码的语义结构,在翻译准确度、格式还原度和隐私保护上,都达到了极高水平。
对科研工作者、开发者、技术写作者来说——这可能是你见过最懂文档的开源AI翻译工具之一。
GitHub 项目地址:https://github.com/xunbu/docutranslate

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号