20M小模型的数学公式OCR,复杂公式截图秒转LaTeX代码!

20M小模型的数学公式OCR,复杂公式截图秒转LaTeX代码!

开源星探
发布于 2026-03-16 20:32:01
发布于 2026-03-16 20:32:01
对于常写文档、做数学研究、准备学术论文的同学来说,数学公式 LaTeX 化几乎是绕不开的痛点。
不过最近我发现了一个非常轻量、却非常强大的开源数学公式 OCR 模型 — Texo。

一个只有 20M 参数的小模型,识别准确度却能达到 BLEU 0.85+,关键是还能直接在浏览器中运行,零成本在线使用。
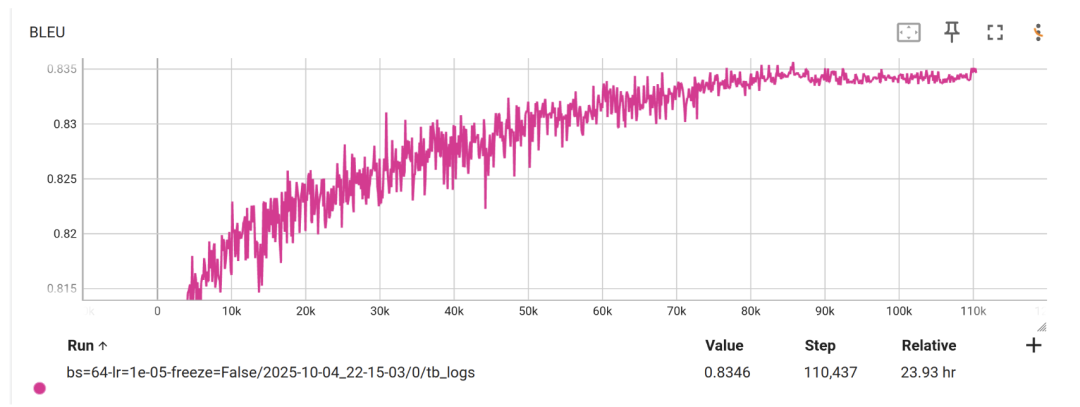
对于一个 OCR 公式识别模型来说,这是相当夸张的表现。
核心亮点
- • 极速推理:模型仅 20M 参数,推理极快。
- • 识别精度高:识别精度媲美百兆级模型,输出 LaTeX 几乎无需二次修改。
- • 直接运行:支持浏览器直接运行,无需后端服务器。
- • 本地部署:支持本地部署及多种运行方式。
快速入手
Texo上手零门槛,浏览器直用或本地部署。
官方直接上线有 Demo 版本,可以直接在浏览输入以下地址使用,上传图片即可。
https://texocr.netlify.app/ocr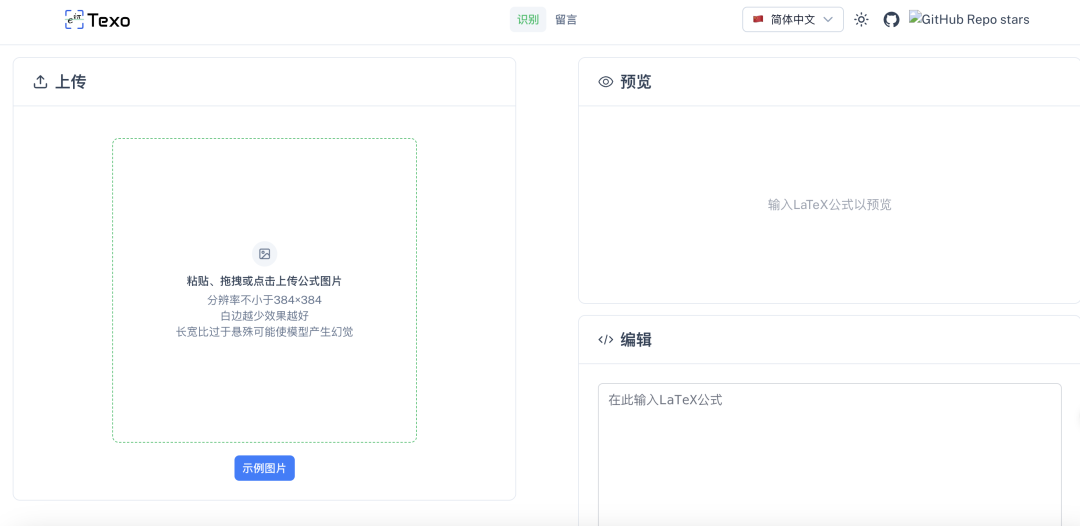
配置环境
git clone https://github.com/alephpi/Texo
uv sync下载模型
# model only
python scripts/python/hf_hub.py pull为什么 20M 模型能做到这么强?
按经验来说,OCR + 数学公式解析是一项非常复杂的任务:
- • 公式符号多
- • 结构嵌套深
- • 上下标位置重要
- • 语义依赖长距离
理论上,小模型很难完成,但 Texo 居然做到了。
原因大概包含以下几点:
- • 任务本身是结构化的,不是完全自由文本。不像自然语言,公式的组合方式是有限的。
- • 训练数据高质量、结构明确。数学 OCR 有大量高质量的 LaTeX 渲染数据可用。
- • 针对公式任务优化的 Transformer 结构。
- • 符号密集型任务对模型鲁棒性要求更低
总之,Texo 的强大不是偶然,而是合理的技术路线 + 轻量化设计的优势结合。
实际使用场景
- • 写论文(LaTeX):PDF 里的公式截图 → Texo → LaTeX → 直接粘贴。
- • 做课堂笔记:把书本、PDF、黑板、老师投影的内容快速转为LaTeX。
- • 开发者:想给自己的应用加入公式识别
写在最后
如果你经常与数学公式、LaTeX 打交道,那么你真的应该收藏 Texo。
它的优势非常明显:不仅轻量、准确度高、浏览器直跑,还开源、易集成。
真正把高难度的数学公式 OCR 技术拉到了大众可用的层级。
GitHub 项目地址:https://github.com/alephpi/Texo

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号