腾讯又放大招!开源原生端到端 OCR 模型,1B 参数吊打PaddleOCR!

腾讯又放大招!开源原生端到端 OCR 模型,1B 参数吊打PaddleOCR!

开源星探
发布于 2026-03-16 20:28:04
发布于 2026-03-16 20:28:04
最近 OCR 圈又被腾讯狠狠震了一下。
腾讯混元刚把一个全新的原生端到端 OCR 大模型:HunyuanOCR 开源了。

虽只有 1B 体量,却在权威基准 OmniDocBench 拿下 94.1 的高分,直接超越 DeepSeek-OCR、PaddleOCR-VL同类能力。
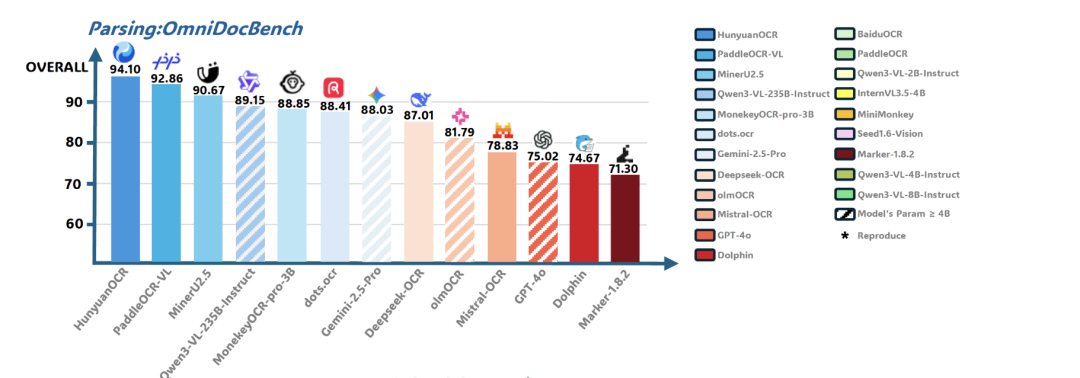
这分数真的有点恐怖。
该模型精通复杂多语种文档解析,同时在文字检测识别、开放字段信息抽取、视频字幕识别、拍照翻译等全场景实用技能中表现出色。
这意味着:「轻量级模型」也能实现「旗舰级」文档解析效果。
核心特点
- • 轻量化架构:基于混元原生多模态架构与训练策略,打造仅1B参数的OCR专项模型,大幅降低部署成本。
- • 全场景功能:单一模型覆盖文字检测和识别、复杂文档解析、卡证票据字段抽取、字幕提取等OCR经典任务,更支持端到端拍照翻译与文档问答。
- • 极致易用:深度贯彻大模型"端到端"理念,单一指令、单次推理直达SOTA结果,较业界级联方案更高效便捷。
- • 多语种支持:支持超过100种语言,在单语种和混合语言场景下均表现出色。
效果展示
1、文字检测识别


2、复杂文档解析
对多语种文档扫描件或拍摄图像进行电子化,具体地,是将图片中出现的文本内容按照阅读顺序进行组织、公式采用Latex格式、复杂表格采用HTML格式表达。







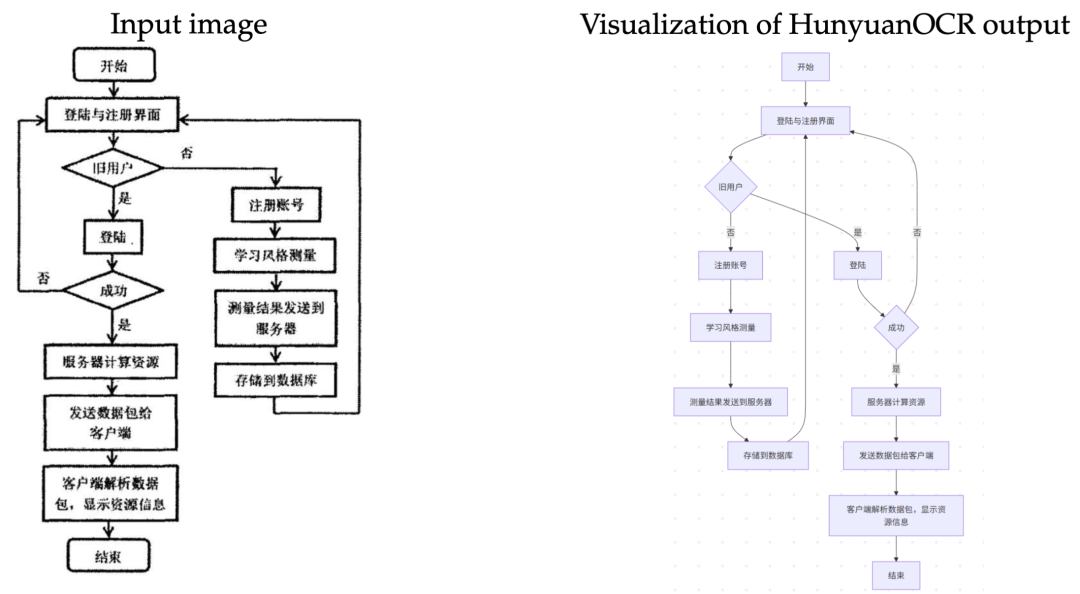

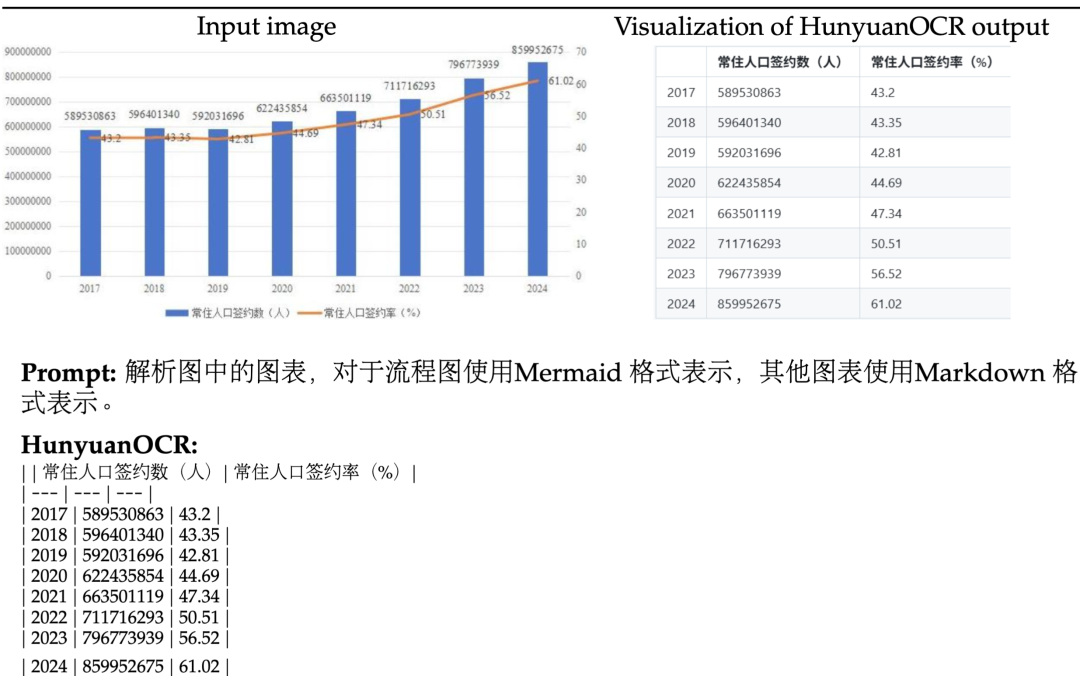
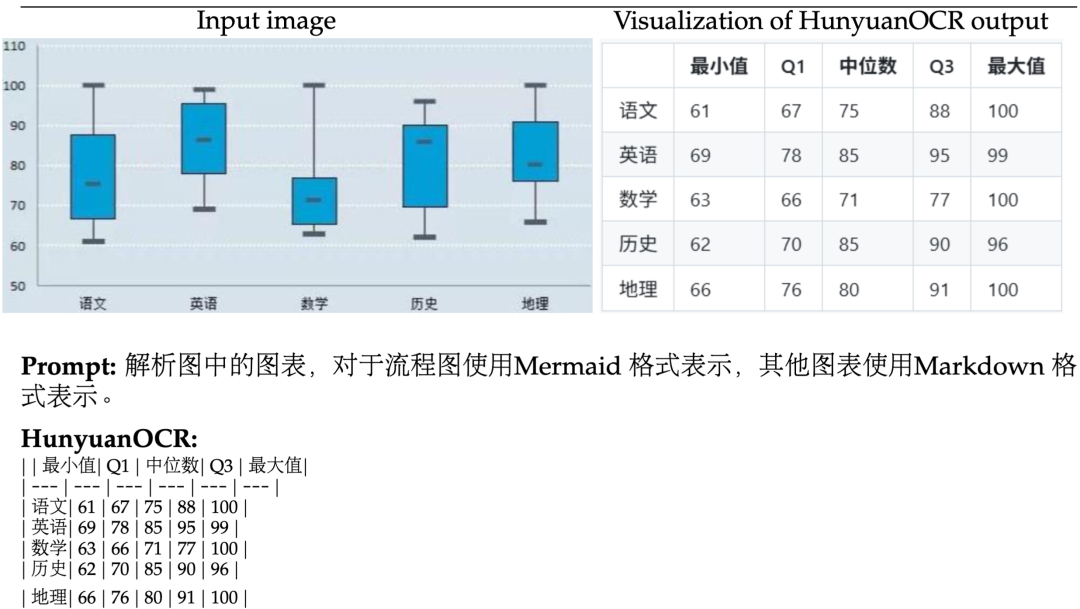
3、开放字段信息提取
对常见卡证和票据的感兴趣字段(如姓名/地址/单位等),采用标准的json格式解析。


Prompt: 提取图片中的:['单价', '上车时间', '发票号码', '省前缀', '总金额', '发票代码', '下车时间', '里程数']的字段内容,并且按照JSON格式返回。
Response:
{
"单价": "3.00",
"上车时间": "09:01",
"发票号码": "42609332",
"省前缀": "陕",
"总金额": "¥77.10元",
"发票代码": "161002018100",
"下车时间": "09:51",
"里程数": "26.1km"
}4、视频字幕提取
能够对视频的字幕实现自动化抽取,包括双语字幕。



5、图片翻译功能
对拍照或者字典文档的多语种图片能够进行端到端翻译成中文或英文的文本格式输出,目前主要支持14种高频应用小语种。

HunyuanOCR 为什么值得关注?
因为它是真·端到端,不靠流水线、不靠一堆子模块拼凑。
从图像 → 文本一条龙输出,并且覆盖场景非常极致。
官方列了 4 大核心亮点,我直接给你总结重点👇
1、文本检测(极其全面)
支持各种现实场景,包括:
- • 街景招牌、店铺招牌
- • 手写内容(纸张、白板)
- • 艺术字(海报、banner、文创字体)
- • 广告图、宣传物料
- • 票据、账单、合同
- • 截屏、界面文本(UI OCR)
覆盖面直接拉满。
2、复杂文档处理
真正难的不是识别文本,而是处理结构化内容。
HunyuanOCR 原生支持:
- • 表格 → HTML 输出(结构完全保留)
- • 数学公式 → LaTeX 输出
- • 段落结构、标题层级
- • 排版关系(多栏、多段落)
在办公、财务、教育行业非常刚需。
这类能力通常只有商业付费 OCR 才能做到,现在免费开源了。
3、视频字幕提取(直接用)
直接支持视频帧自动提取,提取视频字幕。
这对视频号、短视频创作者、字幕组来说非常刚需。
4、端到端照片翻译(14 种语言)
拍照一键翻译,支持 14 个语种。
关键是不是分步翻译,而是端到端理解并生成目标语言文本,跨语言场景辨析更精准。
如何使用?
腾讯这次是真开源,GitHub 和 Hugging Face 全部上线。
更有现成在线 Demo 可直接体验,只需上传图片 + 输入问题即可使用。
在线Demo:https://huggingface.co/spaces/tencent/HunyuanOCR
如果需要本地部署,对于环境要求会偏高,GPU建议20G显存,具体可参考项目文档教程安装。
官方也给了一套推荐的OCR任务提示词,可参考此类方式应用于各场景:

写在最后
HunyuanOCR 的开源,其实释放了一个很重要的信号:大模型正在从「通用炫技」走向「垂直落地」。
腾讯混元这次没有去卷体量更大的通用大模型,而是盯着 OCR 这个看似不起眼但极其重要的基础设施猛攻,并且做到了极致的小和强。
对于我们普通用户来说,这意味着未来的办公软件、笔记软件、翻译软件,都将迎来一波体验上的飞跃。
也许不久后,你微信里的“提取文字”功能,就会悄悄升级成这个 1B 的大杀器,也说不准。
如果你也受够了 PDF 里复制出来的乱码,受够了手动敲公式的痛苦,不妨去 GitHub 上关注一下这个项目。
GitHub:https://github.com/Tencent-Hunyuan/HunyuanOCR
HF 模型地址:https://huggingface.co/tencent/HunyuanOCR
👇 关注我,每天分享一个硬核开源工具,带你用技术搞定工作,用 AI 搞定生活!

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号