8.8K Star!真正的本地实时 Whisper 开源神器,彻底干翻云端 STT!

8.8K Star!真正的本地实时 Whisper 开源神器,彻底干翻云端 STT!

开源星探
发布于 2026-03-16 20:25:51
发布于 2026-03-16 20:25:51
在项目里想做一个真正实时的语音转文字系统,一般只有两条路。
一是上云端 API:延迟低、断句好,但贵,而且隐私敏感场景根本不敢用。
二是本地跑 Whisper:虽然免费,但延迟高、断句不自然。
结果这两年大家几乎都在问同一个问题:
有没有可能在本地就做出云端级别的实时 ASR 体验?
我最近在 GitHub 上挖到一个宝:WhisperLiveKit。
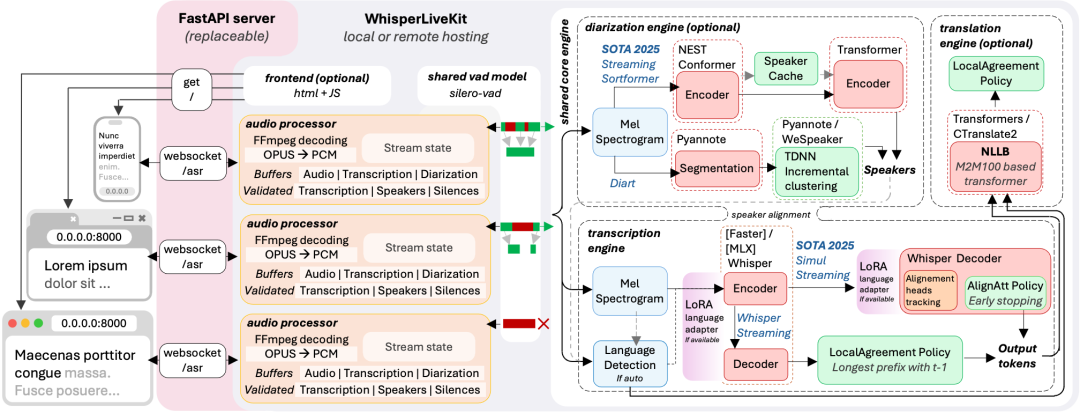
它不是简单的 Whisper 包装,而是一套专门为本地流式语音识别优化的全栈解决方案,真正把 Whisper 流式延迟高的痛点给干碎了。
GitHub:https://github.com/QuentinFuxa/WhisperLiveKit
主要功能
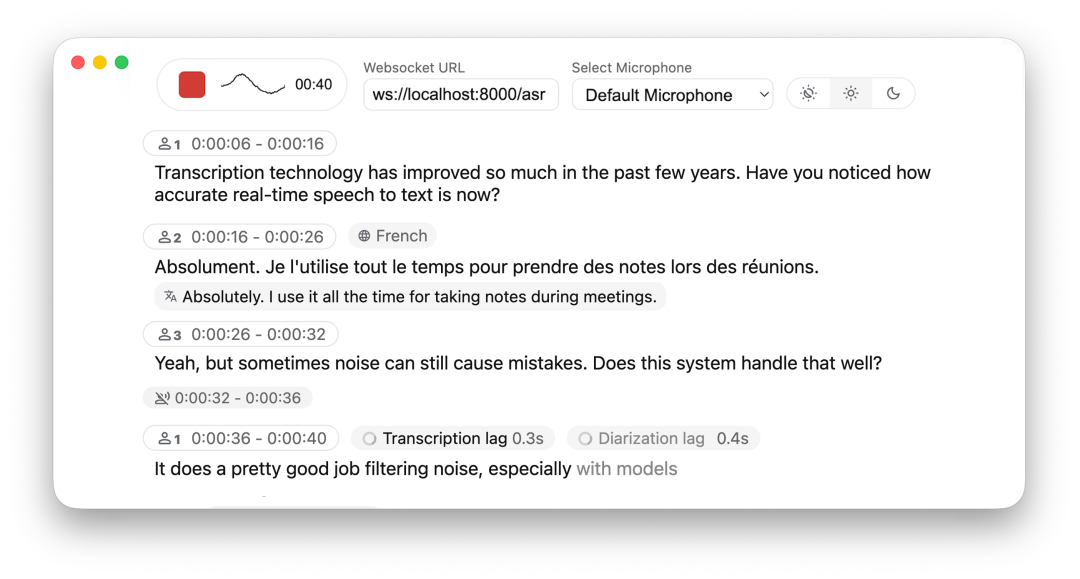
- • 极速流式处理:通过优化的 VAD(语音活动检测)和音频切片逻辑,大幅降低延迟。
- • 说话人区分:内置说话人跟踪、说话人切换检测、自动标注,对团队会议、访谈录音、用户访谈特别有用。
- • 多引擎支持:支持 NVIDIA 显卡的 faster-whisper,也支持苹果 M 芯片的 mlx-whisper。
- • 实时翻译:集成了 NLLB 模型,支持 200 种语言的实时互译。
- • 开箱即用:提供了完整的服务端(Python)和客户端(Web/React)示例。
快速入手
WhisperLiveKit 是一个开源的 Python 工具包,使用 pip 命令即可一键安装。
pip install whisperlivekit安装成功后,命令行就会有 wlk 命令可使用。
启动转录服务器
wlk --model base --language en然后打开浏览器并访问http://localhost:8000。开始说话,即可实时观看你的话语!
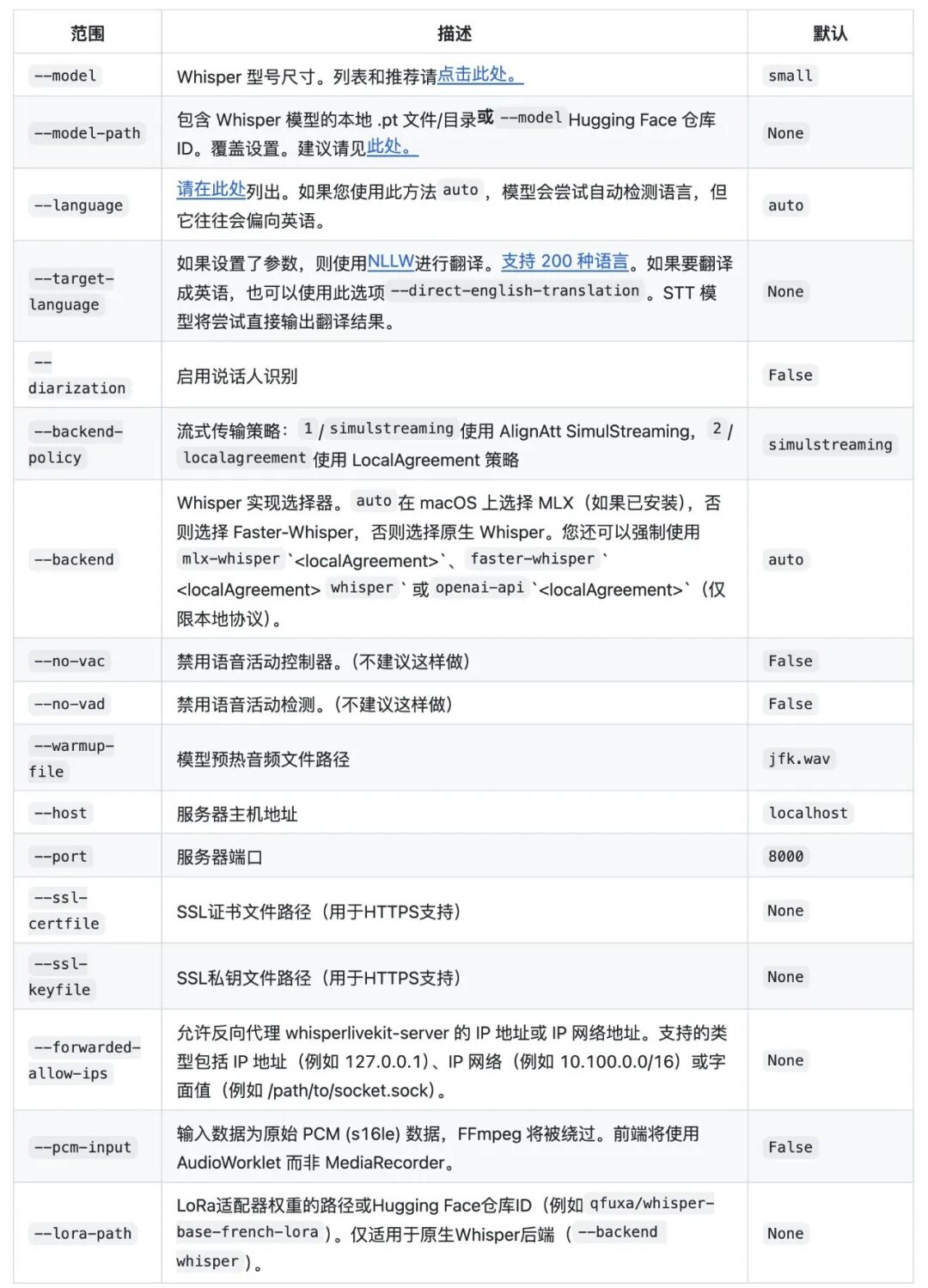
wlk 支持各种参数启动,部署参数如下:
Python API集成
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from whisperlivekit import AudioProcessor, TranscriptionEngine, parse_args
transcription_engine = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global transcription_engine
transcription_engine = TranscriptionEngine(model="medium", diarization=True, lan="en")
yield
app = FastAPI(lifespan=lifespan)
async def handle_websocket_results(websocket: WebSocket, results_generator):
async for response in results_generator:
await websocket.send_json(response)
await websocket.send_json({"type": "ready_to_stop"})
@app.websocket("/asr")
async def websocket_endpoint(websocket: WebSocket):
global transcription_engine
# Create a new AudioProcessor for each connection, passing the shared engine
audio_processor = AudioProcessor(transcription_engine=transcription_engine)
results_generator = await audio_processor.create_tasks()
results_task = asyncio.create_task(handle_websocket_results(websocket, results_generator))
await websocket.accept()
while True:
message = await websocket.receive_bytes()
await audio_processor.process_audio(message) 适用项目
- • 会议纪要系统:自动分角色、自动断句、自动翻译。
- • 教室/直播实时字幕:隐私不上云,延迟极低。
- • 本地同声传译:国外视频会议秒变中文。
- • AI 客服语音识别:可集成到你的 Agent Pipeline 里。
写在最后
WhisperLiveKit 是我见过的开源项目中,将 Whisper 模型工程化落地做的非常优秀的项目之一。
它没有去卷“谁的模型分更高”,而是踏踏实实解决了“怎么让模型在实际业务中跑得顺畅”的问题。
VAD 截断、流式传输、后端加速,这三板斧直接把本地语音识别的门槛降到了地板上。
如果你受够了云厂商按分钟计费的账单,或者受够了本地部署时的卡顿和延迟,WhisperLiveKit 绝对值得你投入时间去尝试。
开源地址:https://github.com/QuentinFuxa/WhisperLiveKit

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号