5.6K Star!原本付费现在开源!本地版“ElevenLabs”,视频翻译+声音克隆全免费!

5.6K Star!原本付费现在开源!本地版“ElevenLabs”,视频翻译+声音克隆全免费!

开源星探
发布于 2026-03-16 19:56:34
发布于 2026-03-16 19:56:34
今天要分享的项目绝对是视频创作者和出海玩家的“年度福音”!
如果你做过视频本地化,你一定知道这个流程有多痛苦: 你要先分离音轨,再用 ASR 识别字幕,然后翻译,最后用 TTS 配音。
中间还会用到一些 API 高质量的服务,结果下来是不仅花费巨大,且费时。
有没有一种方案,既能拥有顶级的语音识别和克隆效果,又能完全免费、无限量地使用呢?
今天就给大家按头安利这个 GitHub 上开源的神器:Voice-Pro。
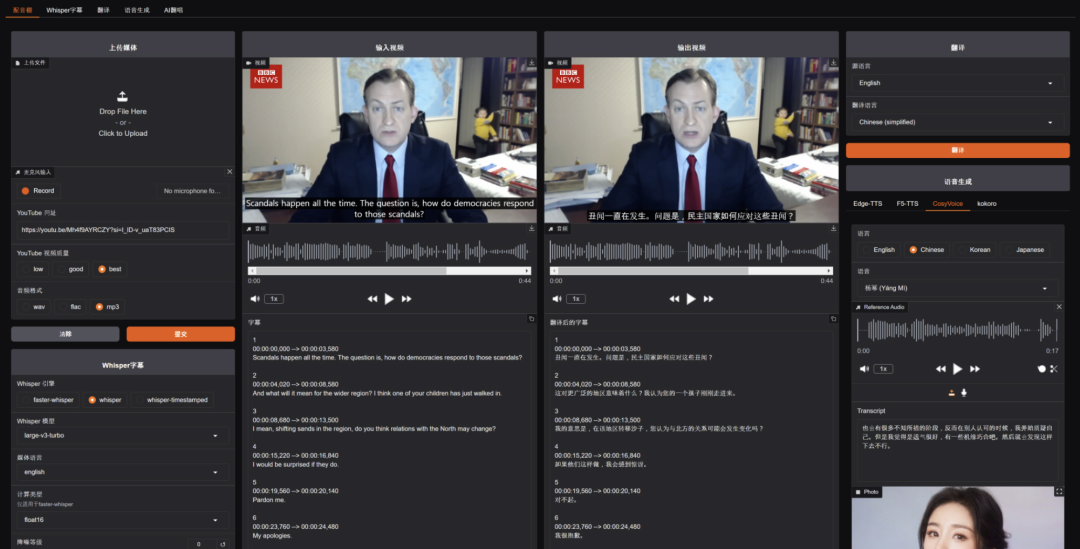
它整合了目前开源界最强的语音模型,把 “视频下载 -> 人声分离 -> 字幕识别 -> 文本翻译 -> 声音克隆配音 -> 视频合成” 这一整套流程,打包成了一个本地软件。
这意味着,你在自己的 Windows 电脑上,就部署了一套私有的 ElevenLabs。
从付费到开源:Voice-Pro 的前世今生
Voice-Pro 原本是由韩国一个小型创业团队开发的一款商业付费软件。但是由于新项目的开发,无法完全管理 Voice-Pro,索性直接将其彻底开源了。

这对于开源社区来说,简直就是捡到了宝。你不需要写一行 Python 代码,就能享受到商业软件级别的体验。
它不仅仅是一个工具,它是一个集大成者。它把 AI 语音领域最先进的几个模型(WhisperX, F5-TTS, CosyVoice)完美地缝合在了一起。
你可以把它理解成:
- • 免费版 ElevenLabs + HeyGen + YTB 翻译工具
- • 而且:不按字符收费、不传视频到云端、声音可零样本克隆
支持在 Windows、Mac、Linux 等主流PC平台运行。
核心能力
- • 顶级语音识别: Whisper, Faster-Whisper, Whisper-Timestamped, WhisperX
- • 零样本语音克隆: F5-TTS, E2-TTS, CosyVoice
- • 多语言文本转语音: Edge-TTS, kokoro (付费版包括 Azure TTS)
- • YTB 视频处理与音频提取: yt-dlp
- • 超过100种语言的即时翻译: Deep-Translator (付费版包括 Azure Translator)
可作为ElevenLabs的强大替代方案,Voice-Pro为播客主持人、开发者和创作者提供高级语音解决方案。
主要功能
1、配音工作室
- • YTB视频下载与音频提取
- • 使用Demucs进行声音分离
- • 支持100多种语言的语音识别与翻译
2、语音技术
- • 语音转文本: Whisper, Faster-Whisper, Whisper-Timestamped, WhisperX
- • 文本转语音:
- •
Edge-TTS: 100多种语言,400多种声音 - •
E2-TTS, F5-TTS, CosyVoice: 零样本克隆 - •
kokoro: 在HuggingFace TTS竞技场中排名第2
- •
3、实时翻译
- • 即时语音识别
- • 实时多语言翻译
- • 可定制的音频输入
Web可视化界面
1、配音工作室
- • 集成中心:YouTube下载、降噪、字幕、翻译、TTS
- • 支持所有ffmpeg兼容格式
- • 输出选项:WAV、FLAC、MP3
- • 支持100多种语言的字幕和识别
- • 可调节TTS的速度、音量、音调
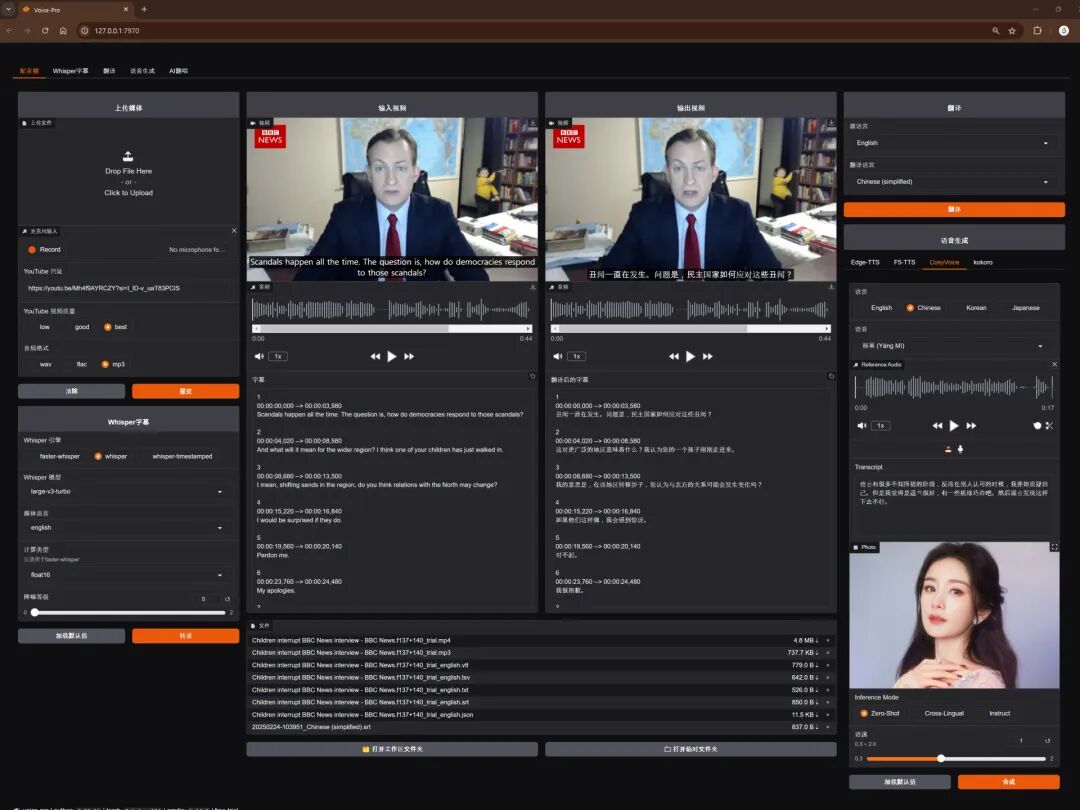
2、Whisper字幕
- • 专用字幕:90多种语言
- • 视频集成字幕显示
- • 单词级高亮和降噪选项
3、翻译
- • 100多种语言翻译
- • 支持字幕文件(ASS、SSA、SRT等)
- • 实时语音识别和翻译
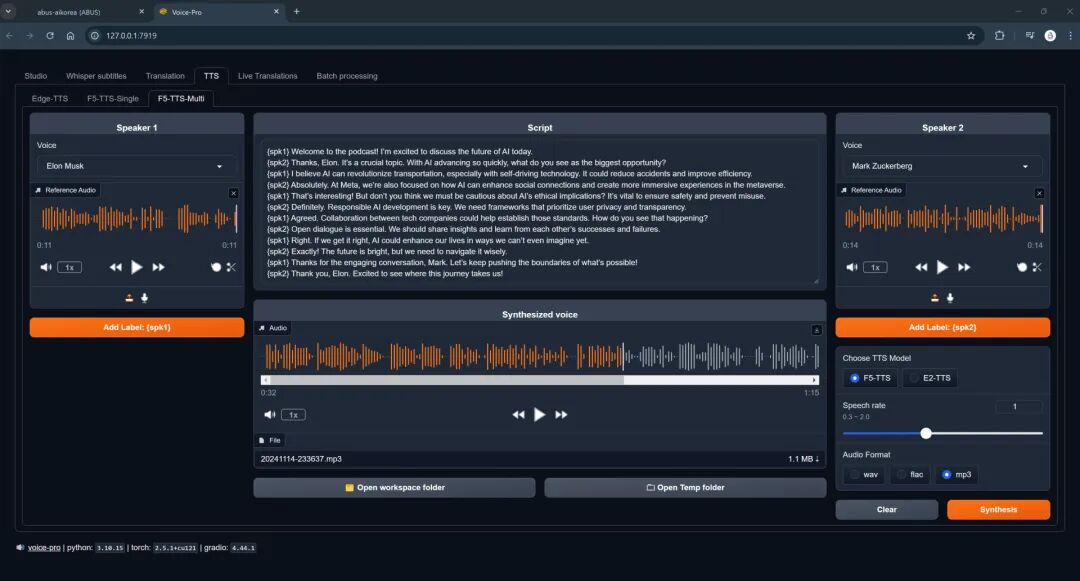
4、语音生成
- • 选项:Edge-TTS、F5-TTS、CosyVoice、kokoro
- • 使用名人声音制作播客和多语言支持
快速入手
Voice-Pro 其实是个 Python 项目,跟 RVC 很相似,前端使用 Gradio 实现,所以安装也都大同小异。
首先克隆项目
git clone https://github.com/abus-aikorea/voice-pro.git然后使用 configure.bat 和 start.bat 就可轻松安装 Voice-Pro。
Mac/Linux上使用configure.sh和start.sh
其中运行 configure.bat 会安装git、ffmpeg、CUDA等工具,只需要首次运行一次即可;整个过程需要等待,不要关闭命令窗口。
而 start.bat 会启动 Voice-Pro 网页界面,首次运行时会安装依赖,只需等待成功启动即可,后续再次使用就会一键启动了。
在项目的最后,大家会发现 Voice-Pro 鸣谢了许多开源项目,而大部分都是我们所熟悉的,所以也是真的可以本地免费使用起来。
写在最后
Voice-Pro 是开源社区对商业软件的又一次「降维打击」。
它把原本付费的 AI 技能工作流,变成了每个人电脑里都能运行的普通工具。虽然本地部署对显卡有一定要求,但相比于长期租用商业 API 的费用,还是好很多的。
如果你正在做视频、多语言内容、AI 配音 — 那这个项目,值得你花一个周末认真跑一遍。
GitHub:
https://github.com/abus-aikorea/voice-pro

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号