微软重磅开源!22K星的 VibeVoice 再添新成员,60分钟音频 ASR 端到端统一输出!

微软重磅开源!22K星的 VibeVoice 再添新成员,60分钟音频 ASR 端到端统一输出!

开源星探
发布于 2026-03-16 19:40:52
发布于 2026-03-16 19:40:52
现在的 ASR(语音转文字)模型,像 OpenAI 的 Whisper,识别率确实已经很顶了。
但当你真正把它们用到长达一小时的会议录音,或者七嘴八舌的播客访谈时,你就会发现一个致命的问题:它听得懂字,但听不懂“局”。
比如一个 1 小时的会议,模型会把它切成 120 个 30 秒的片段。这样做的问题显而易见:
- • 断章取义: 如果一句话跨越了切分点,前半句和后半句就被割裂了,识别率直线下降。
- • 说话人错乱: 第 1 个片段里的“说话人A”和第 10 个片段里的“说话人A”,模型根本不知道是同一个人,导致全局复盘时人物对应不上。
但最近,微软出手了。正式开源了 VibeVoice-ASR,一个拥有 90 亿参数(9B)的统一语音识别模型。

它最离谱的能力在于:拒绝切片,拒绝拼凑,它能在一个 64K 的超长上下文窗口内,一次性“吞下”整整 60 分钟的音频,并直接吐出完美的结构化结果。
它实现了 ASR 领域的“三位一体”:Who(谁说的)+ When(什么时候说的)+ What(说了啥)。
还能自定义热词,提前告诉模型一些专业术语、人名之类的, 识别准确率能大幅提升。
随着 VibeVoice-ASR 的补齐,GitHub 狂揽 22K+ Star 的 VibeVoice 生态终于集齐了 TTS、ASR、RealTime 三大能力。
主要特点
- • 60 分钟单次处理:可接受长达 60 分钟的连续音频输入,每个音频片段长度为 64K。这确保了整整一小时内说话人追踪的一致性和语义连贯性。
- • 自定义热词:用户可以提供自定义热词(例如,特定名称、技术术语或背景信息)来指导识别过程,从而显著提高特定领域内容的识别准确率。
- • 丰富的转录(谁、何时、什么):该模型联合执行 ASR、人声分割和时间戳功能,生成结构化的输出,指示谁在何时说了什么。
- • 多语言和语码切换支持:支持超过 50 种语言,无需显式语言设置,并原生处理语句内和语句间的语码切换。
模型架构
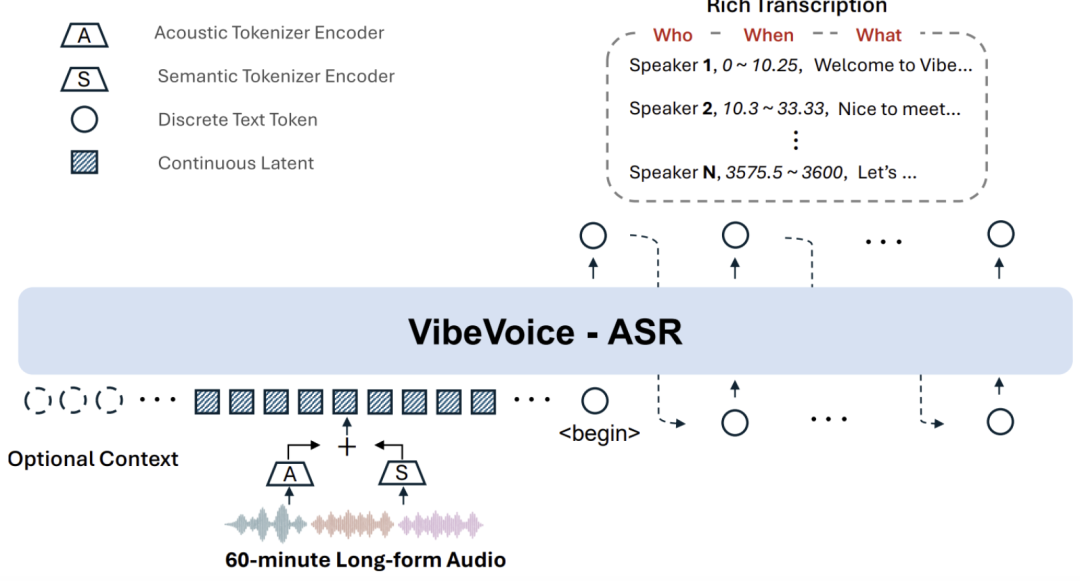
它的底层架构非常有意思,实际上是一个多模态的 LLM。而之所以这么强,是因为它有一个强大的“底座”。
- • 基座:基于 Qwen2 Decoder(28 层,3584 隐藏维度)。这保证了它极强的语言理解和文本生成能力。
- • 双编码器:同时引入声学编码器(听声音细节)和语义编码器(懂上下文逻辑)。
- • 训练策略:在一个统一的框架下,通过多任务学习,让模型学会把声波特征直接映射为带有说话人标签的文本序列。
- • 语言支持:完美支持中文和英文,不仅能听懂,还能处理中英夹杂的情况。
它采用 MIT 协议。这意味着你可以免费商用,可以魔改,可以集成到你自己的 SaaS 产品里而不必担心版权大棒。
核心能力
VibeVoice-ASR 的核心还是 Who + When + What 三合一输出。
在过去,如果想把一段会议录音变成结构化的纪要,通常需要一条复杂的 Pipeline(流水线):
- 1. 先跑 VAD(语音活动检测)。
- 2. 再跑 ASR(转文字)。
- 3. 再跑 Diarization(说话人分离)。
最后写脚本把这些拼起来。这中间任何一个环节出错,结果就崩了,既慢又容易累积误差。
VibeVoice-ASR 实现了 End-to-End(端到端)的统一输出。
[00:15 - 00:20] : 今天的会议主要讨论 Q3 财报。 [00:21 - 00:25] : 好的,我已经把数据准备好了。
一次推理,搞定三件事:
- • Who(谁在说): 自动区分说话人 ID,全程追踪。
- • When(什么时候说): 精确的时间戳标注。
- • What(说了啥): 高精度的语音转文字。
这样直接省去了繁琐的后处理步骤。
快速入手
源码下载:
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
# 安装依赖
pip install -e .用法也及其简单,启动 Gradio 演示:
apt update && apt install ffmpeg -y # for demo
python demo/vibevoice_asr_gradio_demo.py --model_path microsoft/VibeVoice-ASR --share或者直接用脚本文件+参数直接推断:
python demo/vibevoice_asr_inference_from_file.py --model_path microsoft/VibeVoice-ASR --audio_files [add a audio path here] 典型应用场景
- • 长会议转录:多人发言、自动区分角色、直接生成可用纪要
- • 播客/访谈处理:谁在说一目了然,可直接生成节目文稿
- • 客服质检:说话人角色天然区分,时间线清晰,方便追溯
- • 在线课程:自动字幕,讲师&学员声音分离
写在最后
VibeVoice-ASR 并不是一个孤立模型,而是正式补齐了微软 VibeVoice 体系的一个重要拼图。
- • TTS
- • ASR(就是这次)
- • Real-Time 实时能力
这下 VibeVoice 体系,终于齐活了,实现了从“听”到“说”,从“离线”到“实时”的完整语音能力闭环。
对于一直苦于 Whisper 限制的开发者来说,这绝对是一个值得立刻尝试的替代方案。
开源地址:
模型:https://huggingface.co/microsoft/VibeVoice-ASR GitHub:https://github.com/microsoft/VibeVoice

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号