用 OpenAI Functions 从文本构建知识图谱实战篇

用 OpenAI Functions 从文本构建知识图谱实战篇

山行AI
发布于 2026-03-13 21:05:15
发布于 2026-03-13 21:05:15
引言
从非结构化数据(如文本)中提取结构化信息,这项技术已经存在有一段时间了,并不是什么新鲜事。然而,大型语言模型(LLMs)为信息提取领域带来了重大变革。
如果说以前你需要一个机器学习专家团队来整理数据集和训练自定义模型,如今只需要接入一个大型语言模型即可。进入门槛大幅降低,使得原本仅限于领域专家的操作,现在连非技术人员也能轻松上手。
信息提取管道的目标
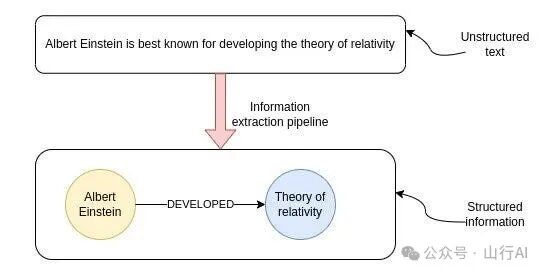
信息提取管道的目标是从非结构化文本中提取结构化信息。图示描述了非结构化文本如何被转化为结构化信息的过程。该过程被称为“信息提取管道”,最终结果是一种图结构形式的信息。图中的节点表示关键实体,连线则代表实体之间的关系。
知识图谱(Knowledge Graph)在以下场景中非常有用:
•多跳问答(Multi-hop Question Answering)•实时分析(Real-time Analytics)•在单一数据库中结合结构化与非结构化数据
虽然借助 LLM 提取结构化信息变得更容易,但这绝不是一个已经完全解决的问题。
在本篇文章中,我们将结合 OpenAI 的函数功能与 LangChain,从一个示例 Wikipedia 页面构建一个知识图谱。在这个过程中,我们将探讨一些最佳实践,并讨论当前 LLM 的一些局限性。
Neo4j 环境配置
你需要配置一个 Neo4j 实例以便运行本文中的示例。
方式一:使用 Neo4j Aura 启动云端数据库实例
Neo4j Aura 提供免费的云实例,是最便捷的方式。
方式二:本地安装 Neo4j
1.下载并安装 Neo4j Desktop 应用2.创建本地数据库实例
以下是一个用于连接 Neo4j 数据库的 LangChain 包装器代码示例:
# 示例代码将在后续提供
连接示例代码:
```python
from langchain.graphs import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username = "neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)📥 信息抽取流程
一个典型的信息提取流程通常包含以下几个步骤:
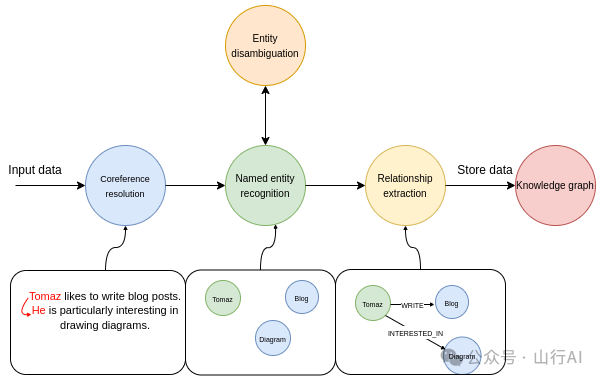
多步信息提取流程示意图
1. 指代消解(Coreference Resolution)
在第一步中,我们将输入文本输入到一个指代消解模型中。指代消解任务的目标是找出所有指向同一实体的表达方式。简单来说,就是将所有代词链接到其所指代的具体实体上。
2. 命名实体识别(Named Entity Recognition)
在信息提取流程的实体识别部分,我们尝试从文本中提取出所有被提及的实体。
示例中提到的实体包括:
•Tomaz•Blog•Diagram
3. 实体消歧(Entity Disambiguation)
下一步是实体消歧(Entity Disambiguation),这是信息提取流程中一个非常关键但常常被忽视的环节。
实体消歧的任务是准确识别并区分名称相似或引用模糊的实体,以确保在特定上下文中识别出正确的对象。
4. 实体关系识别(Relation Extraction)
在最后一步中,模型会尝试识别实体之间的各种关系。
例如,它可能识别出 Tomaz 与 Blog 之间存在 LIKES(喜欢)关系。
使用 OpenAI Functions 提取结构化信息
OpenAI Functions 是从自然语言中提取结构化信息的极佳工具。其核心理念是:由 LLM 生成一个预定义的 JSON 对象,并填充相应的值。这个预定义的 JSON 对象可以作为输入传递给其他函数(如 RAG 应用中的函数),也可以用于从文本中提取特定的结构化信息。
在 LangChain 框架中,你可以使用 Pydantic 类 来定义所需的 JSON 数据结构,并作为 OpenAI Functions 的描述输入。因此,我们的第一步是定义我们希望从文本中提取的结构信息结构。幸运的是,LangChain 已经定义好了用于表示**实体节点(Nodes)和实体关系(Relationships)**的 Pydantic 类,我们可以直接复用这些类。接下来可以进入代码部分,演示如何构建这些类并实现信息提取功能。
class Node(Serializable):
"""Represents a node in a graph with associated properties.
Attributes:
id (Union[str, int]): A unique identifier for the node.
type (str): The type or label of the node, default is "Node".
properties (dict): Additional properties and metadata associated with the node.
"""
id: Union[str, int]
type: str = "Node"
properties: dict = Field(default_factory=dict)
class Relationship(Serializable):
"""Represents a directed relationship between two nodes in a graph.
Attributes:
source (Node): The source node of the relationship.
target (Node): The target node of the relationship.
type (str): The type of the relationship.
properties (dict): Additional properties associated with the relationship.
"""
source: Node
target: Node
type: str
properties: dict = Field(default_factory=dict)遗憾的是,目前 OpenAI Functions 并不支持将字典对象作为值(value)。因此,我们需要重写属性(properties)的定义,以符合 Functions 接口的限制条件。也就是说,在定义结构化信息的 JSON 输出格式时,不能直接使用嵌套的字典结构,而需要使用 OpenAI Functions 支持的扁平化数据结构格式。
from langchain.graphs.graph_document import (
Node as BaseNode,
Relationship as BaseRelationship
)
from typing import List, Dict, Any, Optional
from langchain.pydantic_v1 import Field, BaseModel
# 属性类:表示一个 key-value 属性
class Property(BaseModel):
"""一个由 key 和 value 构成的单个属性"""
key: str = Field(..., description="属性名")
value: str = Field(..., description="属性值")
# 重写 Node 类,使用属性列表替代字典
class Node(BaseNode):
properties: Optional[List[Property]] = Field(
None, description="节点属性列表")
# 重写 Relationship 类,使用属性列表替代字典
class Relationship(BaseRelationship):
properties: Optional[List[Property]] = Field(
None, description="关系属性列表")在这里,我们将 properties 的值从字典改写为 Property 类的列表,以克服 OpenAI Functions 接口的限制。由于该 API 只允许传递一个对象,我们将所有的节点(nodes)和关系(relationships)组合进一个名为 KnowledgeGraph 的单一类中。通过这种方式,我们可以在不违反 API 要求的前提下,同时传递完整的结构化信息。
class KnowledgeGraph(BaseModel):
"""用于生成包含实体和关系的知识图谱的结构定义"""
nodes: List[Node] = Field(
..., description="知识图谱中的节点列表")
rels: List[Relationship] = Field(
..., description="知识图谱中的关系列表")最后只剩下一件事要做,那就是进行一些提示词工程(Prompt Engineering),然后我们就可以开始运行了。
1.用自然语言反复优化提示词以改善输出结果2.如果某些表达没有达到预期效果,就请 ChatGPT 帮忙重新表述任务,使其对 LLM 更加清晰可理解3.当提示词包含了所有必要的指令后,再请 ChatGPT 将这些指令总结为 Markdown 格式,这样可以节省 token,并有可能使指令更加清晰。
我之所以特别选择使用 Markdown 格式,是因为我在某处看到过:OpenAI 的模型对提示词中的 Markdown 语法响应更好。从我的实际经验来看,这一点是有道理的,至少是合理的猜测。
在反复迭代提示词工程后,我设计出了以下这个用于信息提取流程的系统提示词(System Prompt):
llm = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)
def get_extraction_chain(
allowed_nodes: Optional[List[str]] = None,
allowed_rels: Optional[List[str]] = None
):
prompt = ChatPromptTemplate.from_messages([
(
"system",
f"""# GPT-4 知识图谱构建说明
## 1. 总览(Overview)
你是一个顶尖的算法,用于从自然语言中提取结构化信息,并构建知识图谱。
- **节点(Nodes)** 表示实体和概念,类似维基百科词条;
- 构建目标是简洁明了、结构清晰,方便大众理解和使用。
## 2. 节点标注规范(Labeling Nodes)
- **一致性**:节点标签应统一使用基本类型。
- 例如:人物统一标记为 `"person"`,不要使用 `"mathematician"` 或 `"scientist"` 这类更具体的术语;
- **节点 ID 规范**:禁止使用纯数字作为 ID,应使用文本中出现的名称或可读标识符。
{'- **允许的节点标签(Allowed Node Labels):** ' + ", ".join(allowed_nodes) if allowed_nodes else ""}
{'- **允许的关系类型(Allowed Relationship Types):** ' + ", ".join(allowed_rels) if allowed_rels else ""}
## 3. 数值与日期处理(Handling Numerical Data and Dates)
- 年龄等数值信息应作为节点属性嵌入;
- **禁止将日期/数值作为独立节点**,应直接作为属性附加到相关节点;
- **属性格式**:必须为键值对(key-value)形式;
- **引号使用规范**:属性值中不得包含转义的引号(`\'` 或 `\"`);
- **命名风格**:属性键使用驼峰命名(如:`birthDate`)。
## 4. 指代消解(Coreference Resolution)
- **保持实体一致性**:如果一个实体在文本中多次出现且使用不同称呼(如 “John Doe”、“Joe”、“he”),应统一使用最完整的名称(如 “John Doe”)作为节点 ID;
- 确保整个知识图谱中实体引用一致、清晰、可读。
## 5. 严格遵守规范(Strict Compliance)
必须严格按照以上规则操作;
若不符合要求,将终止处理任务。
"""
),
("human", "使用上述格式,从以下输入中提取信息:{input}"),
("human", "提示:请确保使用正确格式进行输出")
])
return create_structured_output_chain(KnowledgeGraph, llm, prompt, verbose=False)我们在这里使用的是 GPT-3.5 的 16k 版本,主要原因在于 OpenAI Functions 的输出是结构化的 JSON 对象,而 JSON 的语法结构会显著增加 token 消耗。换句话说,为了获得结构化输出的便利性,我们需要付出更多的 token 空间作为代价。
除了常规指令外,我还添加了一个可选项,可以限制从文本中提取哪些类型的实体或关系。 在后续的示例中你会看到,这一功能在很多场景下都非常实用。
此时,我们已经完成了 Neo4j 连接配置 和 LLM 提示词设置,接下来可以将整个信息提取流程封装为一个单一函数进行调用。
def extract_and_store_graph(
document: Document,
nodes: Optional[List[str]] = None,
rels: Optional[List[str]] = None
) -> None:
# 使用 OpenAI Functions 进行图谱信息抽取
extract_chain = get_extraction_chain(nodes, rels)
data = extract_chain.run(document.page_content)
# 构造图谱文档对象(包含节点和关系)
graph_document = GraphDocument(
nodes=[map_to_base_node(node) for node in data.nodes],
relationships=[map_to_base_relationship(rel) for rel in data.rels],
source=document
)
# 将信息写入 Neo4j 图数据库
graph.add_graph_documents([graph_document])这个函数接收一个 LangChain 的 Document 文档对象,以及两个可选参数:nodes 和 relationships,用于限制我们希望 LLM 识别和提取的对象类型。
大约在一个月前,我们在 Neo4j 的图对象中新增了一个方法:add_graph_documents,
这个方法可以在这里派上用场,用于无缝导入知识图谱数据,大大简化了处理流程。
评估
我们将从 沃尔特·迪士尼(Walt Disney) 的 Wikipedia 页面中提取信息,并构建一个知识图谱,以测试信息提取流程的效果。
在这个过程中,我们将使用 LangChain 提供的 Wikipedia 加载器 和 文本分块模块 来处理数据。
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import TokenTextSplitter
# 读取 Wikipedia 文章
raw_documents = WikipediaLoader(query="Walt Disney").load()
# 定义文本分块策略
text_splitter = TokenTextSplitter(chunk_size=2048, chunk_overlap=24)
# 仅取前三个文档进行处理
documents = text_splitter.split_documents(raw_documents[:3])你可能注意到了,我们设置了一个相对较大的 chunk_size 值,这是因为我们希望在每个文本块中提供尽可能多的上下文信息,以确保指代消解(coreference resolution) 部分的效果尽可能好。
请记住:指代消解只有在实体及其代词引用出现在同一个文本块中时才会生效,否则 LLM 无法获取足够的信息来建立它们之间的联系。
from tqdm import tqdm
for i, d in tqdm(enumerate(documents), total=len(documents)):
extract_and_store_graph(d)整个处理过程大约需要 5 分钟左右,相对来说是比较慢的。因此,在生产环境中,你可能会希望采用并行调用 API 的方式来解决这个问题,以实现一定程度的可扩展性(scalability)。
接下来,让我们先看看 LLM 所识别出的 节点(Nodes) 和 关系(Relationships) 类型。
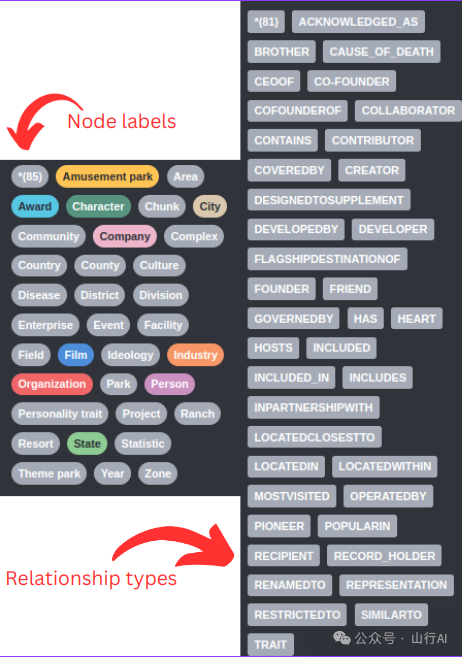
由于我们没有预先提供图谱的结构定义(schema),LLM 会在运行时动态决定使用哪些节点标签(node labels)和关系类型(relationship types)。例如,我们可以观察到生成的图谱中同时存在 Company 和 Organization 两种节点标签。这两者在语义上可能是相似或等同的,因此在实际项目中,我们通常更希望用一个统一的节点标签来表示这两种实体。
对于任何更为严肃或正式的项目,建议你预先定义好节点标签和关系类型,并明确指定 LLM 应该提取哪些类型的信息。幸运的是,我们已经为提示词增加了一个功能:你可以通过传入额外参数来限制 LLM 提取的节点和关系类型,从而避免上述类型不一致的问题。
# 指定 LLM 可抽取的节点标签类型
allowed_nodes = ["Person", "Company", "Location", "Event", "Movie", "Service", "Award"]
# 运行抽取流程,仅保留指定节点类型
for i, d in tqdm(enumerate(documents), total=len(documents)):
extract_and_store_graph(d, allowed_nodes)在这个示例中,我只限制了节点标签(node labels),但你也可以通过向 extract_and_store_graph 函数传入另一个参数,轻松限制关系类型(relationship types) 的提取范围。
提取出的子图在可视化后具有如下结构:
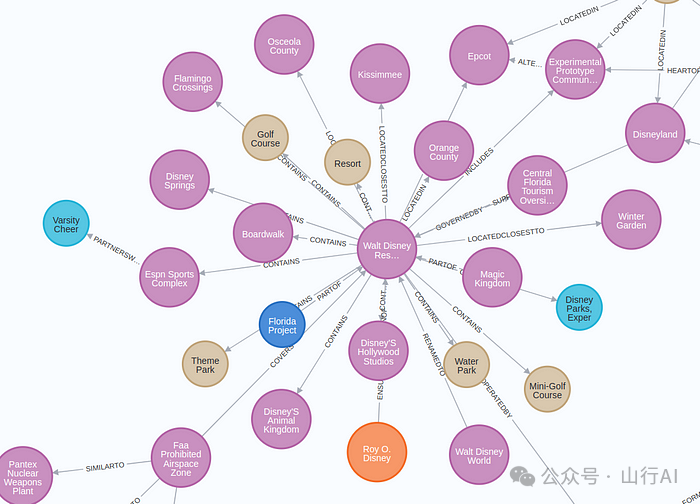
最终生成的图谱比预期效果更好(经过了 5 次迭代 😄)。尽管在可视化中我没能完整展示整张图谱,但你可以在 Neo4j Browser 或其他图数据库工具中自行进行交互式探索。
实体消歧说明
有一点需要特别说明:在本次流程中,我们部分跳过了实体消歧步骤。尽管我们使用了较大的文本块(chunk size),并在系统提示词中添加了专门针对指代消解与实体消歧的指令,但由于每个文本块是独立处理的,导致我们无法保证不同块之间实体的一致性。举个例子,你可能会看到图谱中出现了两个代表同一个人物的节点,这正是由于不同文本块未能统一实体识别所造成的。
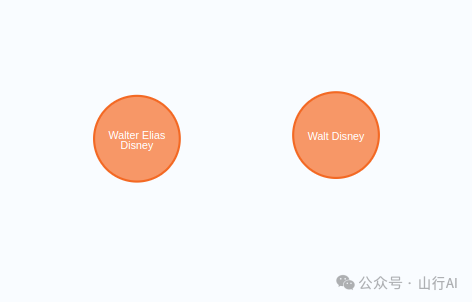
在本示例中,“Walt Disney” 和 “Walter Elias Disney” 实际上指的是同一个现实中的人物。 这正是实体消歧(Entity Disambiguation)问题的典型案例。
这个问题并不新颖,已经有多种方法被提出用于解决它,例如:
•✅ 使用实体链接(Entity Linking)或实体消歧的自然语言处理模型•✅ 对文本进行第二轮处理,通过 LLM 执行全局实体消歧任务•✅ 使用**图结构方法(Graph-based Approaches)**进行实体对齐和合并
你应该根据具体的应用场景和领域需求来决定使用哪种方案。不过请务必牢记:实体消歧不应被忽视,它对于提升 RAG 应用的准确性与效果具有至关重要的作用。
RAG 应用示例
最后一部分,我们将展示如何通过构造 Cypher 查询语句 来浏览知识图谱中的信息。Cypher 是一种用于图数据库的结构化查询语言,其作用类似于 SQL 在关系型数据库中的作用。通过 Cypher,你可以对图中的节点、关系进行灵活的查询与分析。
LangChain 提供了一个名为 GraphCypherQAChain 的组件, 它可以:
•自动读取图谱的结构(schema)•根据用户输入智能构造相应的 Cypher 查询语句•实现图谱问答(Graph-based QA)功能
通过这一组件,用户无需掌握 Cypher 的语法细节,也能实现对图谱的自然语言问答交互。
# 在 RAG 应用中查询知识图谱
from langchain.chains import GraphCypherQAChain
# 刷新图谱结构,确保查询时使用最新 schema
graph.refresh_schema()
# 初始化 Cypher 问答链
cypher_chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=ChatOpenAI(temperature=0, model="gpt-4"), # 生成 Cypher 查询语句的模型
qa_llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"), # 回答最终问题的模型
validate_cypher=True, # 验证 Cypher 中关系方向的正确性
verbose=True # 打印调试信息
)
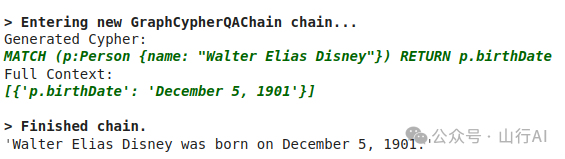
# 执行查询:Walter Elias Disney 是何时出生的?
cypher_chain.run("When was Walter Elias Disney born?")查询结果展示:
总结
当你的 RAG 应用需要同时处理结构化数据与非结构化数据时,**知识图谱(Knowledge Graphs)**是非常理想的选择。在本篇文章中,你学习了如何使用 OpenAI Functions,从任意文本中提取信息并在 Neo4j 中构建知识图谱。OpenAI Functions 提供了结构清晰的输出形式, 因此在执行结构化信息提取任务时非常高效、便捷。
提升构建体验的建议:
•✅ 在开始构建前,尽可能详细地定义图谱的 Schema(结构)•✅ 在信息提取完成后,加入实体消歧步骤,以确保图谱节点的准确性与一致性
通过这些优化措施,你可以获得更高质量、更可控的图谱构建体验。
更多信息
本文由笔者翻译整理自:https://bratanic-tomaz.medium.com/constructing-knowledge-graphs-from-text-using-openai-functions-096a6d010c17,如对您有帮助,请帮忙点赞、转发,谢谢!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号