如何构建一个简单的图谱式 RAG 应用-上篇

如何构建一个简单的图谱式 RAG 应用-上篇

山行AI
发布于 2026-03-13 20:49:03
发布于 2026-03-13 20:49:03
👉该应用与笔记本的配套代码可见 这里[1]。
知识图谱( KGs)和大语言模型(LLMs)可谓是天作之合。这两种技术之间的互补性,但简而言之就是, LLM 的一些主要弱点,比如它们是黑箱模型、在事实知识方面表现不佳,恰恰是知识图谱最擅长的领域。知识图谱本质上是“事实的集合”,而且完全可解释。
什么是 Graph RAG?
本文的核心在于如何构建一个简单的 Graph RAG 应用?
RAG(Retrieval-Augmented Generation,检索增强生成)是指检索相关信息来补充发送给 LLM 的提示内容,以便生成更准确、更有上下文的回答。而 Graph RAG,则是指使用“知识图谱”作为检索部分的增强手段。
如果你没听说过 Graph RAG,或者需要复习一下,可以观看 这个视频[2]。
为何要使用 Graph RAG?
与其直接把提示词送入一个未接触过你数据的 LLM,不如先从相关数据中检索出信息,用这些信息补充你的提示词。
一个常用的例子是:
我将职位描述和我的简历一起复制到 ChatGPT 中,请它帮我写一封求职信。 有了这些上下文,LLM 回答“写一封求职信”这个提示词时,就能生成更贴合、相关性更强的内容。
知识图谱正是用来存储结构化知识的利器,特别适合用于补充 LLM 的上下文信息,从而提升生成结果的准确度和相关性。
Graph RAG 的应用场景
Graph RAG 技术在许多行业都有广泛应用,包括但不限于:
•客户服务机器人[3]•新药研发(药物发现)[4]•生命科学行业的自动合规报告生成[5]•人力资源中的人才获取与管理 [6]•法律研究与文书撰写[7]•财富管理顾问助手[8]
由于这项技术能够大幅提升 LLM 工具的性能,Graph RAG 近年来迅速走红。
以下是一张基于 Google 搜索趋势绘制的图表,展示了公众对该技术兴趣的增长:
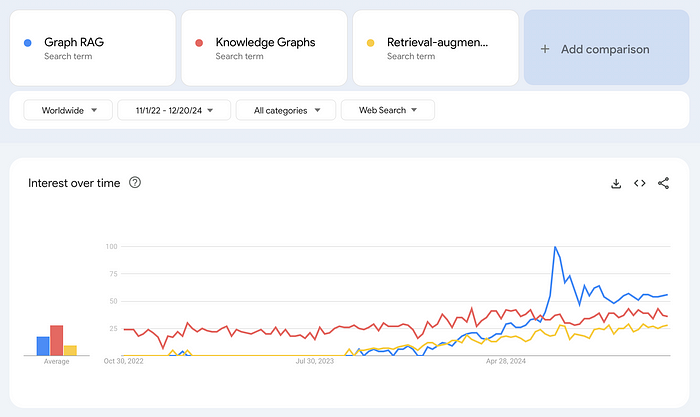
Graph RAG 的热度正在飙升
Graph RAG 的搜索热度出现了激增,甚至超过了“知识图谱”和“检索增强生成(Retrieval-Augmented Generation)”等术语。需要注意的是,Google Trends 测量的是相对搜索兴趣,而非绝对搜索次数。2024 年 7 月 Graph RAG 搜索量的激增,恰逢微软宣布其 GraphRAG 应用将在 GitHub 上开放获取 的那一周。
这股 Graph RAG 的热潮并不止于微软。以下是行业中的几个关键事件:
📌 三星收购 RDFox
2024 年 7 月,三星收购了知识图谱公司 RDFox。虽然宣布收购的文章并未直接提到 Graph RAG,但在 2024 年 11 月《福布斯》的文章中,一位三星发言人表示:
“我们计划发展知识图谱技术,这将成为个性化 AI 的核心技术之一,并与生成式 AI 有机融合,以支持面向用户的定制化服务。”
📌 Ontotext 与 Semantic Web 公司合并,组建 Graphwise
2024 年 10 月,领先的图数据库公司 Ontotext 与知识图谱平台 PoolParty 的开发商 Semantic Web 公司完成合并,成立了 Graphwise。
根据新闻稿,这次合并的目标是:
“推动 Graph RAG 作为一个独立技术类别的普及和发展。”
这不仅是风口,更是实际落地的转型。虽然 Graph RAG 的热度部分受益于聊天机器人和生成式 AI 的整体热潮,但它的核心反映出一种真实且深刻的技术演进 —— 知识图谱在解决复杂现实问题中的新角色。
✅ 实战案例:LinkedIn 提升客服支持效率
LinkedIn 就使用 Graph RAG 改进了其技术客服系统。
•Graph RAG 能够从以往的工单记录中检索出相关内容(如已解决的相似问题),并用于补充 LLM 的回答输入。•因此,客服回答的准确性大幅提升,平均问题处理时间从 40 小时降至 15 小时。
如何构建一个简单的 Graph RAG 实例应用?
接下来我将带你搭建一个非常简单,但具有代表性的 Graph RAG 应用示例,演示这一技术如何在实际中工作。最终产出将是一个非技术用户也能直接使用的应用。我会使用来自 PubMed 的医学期刊文章作为数据集。设想这是一个供医疗领域人员进行文献综述的工具。当然,这些原理也可以被灵活地应用到许多其他场景中,这正是 Graph RAG 令人激动的原因所在。
本篇文章和我们将要构建的应用,其结构如下所示:
第0步:准备数据
我们将在下文详细解释数据准备的步骤,但总体目标包括 向量化原始数据 ,将原始数据转化为 RDF 知识图谱。
只要我们在向量化前保持每篇文章的 URI 与文章绑定,就可以在文章构建的知识图谱与文章所在的向量空间之间进行导航。
然后,我们可以按以下步骤操作:
1.文章检索:使用向量数据库的能力,根据搜索词对相关医学文章进行初步搜索。我们将通过向量相似度来检索那些与搜索词最相似的文章向量。2.术语精炼:探索 MeSH(医学主题词表) 的生物医学词汇系统,从中选择合适的术语,以用于筛选第一步中得到的文章。MeSH 是一个标准化控制词汇表,包含医学术语、同义词、更窄的概念、以及丰富的语义属性与关系。3.筛选与摘要生成:使用 MeSH 术语对文章进行进一步筛选,防止“上下文污染(context poisoning)”。然后将筛选后的文章连同提示词(例如 “用项目符号列出摘要”)一并发送给 LLM 生成总结。
在正式开始前,这里有几点说明:
•知识图谱只用于元数据管理。我们在这个应用中将知识图谱专门用于结构与语义管理,这是因为我们的每篇文章都已被标注为属于某个控制词汇系统。向量数据库用于基于“语义相似度”的检索。知识图谱用于“语义关系的结构化管理”。
向量数据库可以告诉我们 “食管癌” 和 “口腔癌” 在语义上是相似的, 而知识图谱则可以告诉我们这两个病症之间到底是什么关系。
•我们所用的数据集来自 PubMed,包含表格结构(structured/tabular),每篇文章的摘要文本 ,使用 MeSH 控制词汇 进行了标注。我们称这个项目为 “Graph RAG for Medicine”,是因为它处理的是医学领域的数据。
⚠️ 但请注意:这一结构与方法完全可以迁移到其他领域,并不局限于医学。
•通过这个应用和教程,我想说明一个核心观点,如果你在 RAG 应用中引入知识图谱作为检索步骤的一部分,你将能显著提升 准确性(accuracy) 与 可解释性(explainability)。具体地说,知识图谱能以两种方式改进 RAG 应用:1. 提供一个清晰的上下文筛选机制,确保只将最相关的信息提供给 LLM ;2. 通过使用领域专家维护的控制词汇体系,利用其丰富的语义关系进行高质量过滤。下一步我们将开始应用构建过程,逐步实现上述结构。
• 本教程和应用没有直接展示的,是知识图谱(KGs)提升 RAG 应用的另外两种重要方式:治理、访问控制与合规性;以及效率与可扩展性。在治理方面,KG 不仅可以通过过滤相关内容来提高准确性 —— 它们还能执行数据治理策略。例如,如果某个用户没有权限访问某些内容,这些内容可以被从其 RAG 流程中排除。在效率与可扩展性方面,KG 可确保 RAG 应用不会“胎死腹中”。虽然构建一个令人惊艳的单次性 RAG 应用很容易(本教程正是这样一个例子),但许多公司却面临大量缺乏统一框架、结构或平台的零散 POC,这些应用往往难以长期存续。一个由 KG 支持的元数据层可以打破数据孤岛,为构建、扩展和维护 RAG 应用提供基础。使用如 MeSH 这类丰富的控制词汇作为文章的元数据标签,是确保此 Graph RAG 应用能集成入其他系统并避免孤立化的有效手段。
第 0 步:准备数据
用于准备数据的代码见本Notebook[9]。
如前所述,我再次选用了来自 PubMed 数据库的 50,000 篇研究文章的数据集[10](许可协议:CC0 公共领域)。该数据集包含文章标题、摘要,以及一个用于元数据标签的字段。这些标签来自 MeSH(医学主题词表)控制词汇表。实际上,这些 PubMed 文章只是关于文章的元数据 —— 每篇文章都有摘要,但不包含全文。数据本身已经是表格格式,并且打上了 MeSH 标签。
我们可以直接对这个表格数据集进行向量化。也可以在向量化前将其转为图结构(RDF),但在本应用中我没有这么做,也不确定这样是否对这种数据类型的最终结果有帮助。向量化原始数据的关键步骤是:先为每篇文章添加唯一资源标识符[11](URI)。URI 是在 RDF 数据中进行导航的唯一 ID,只有这样我们才能在向量空间和图谱实体之间进行切换。此外,我们还将在向量数据库中为 MeSH 术语创建一个独立集合。这样用户即使不了解该控制词汇表,也能搜索到相关术语。下图展示了我们在数据准备阶段所做的事情:
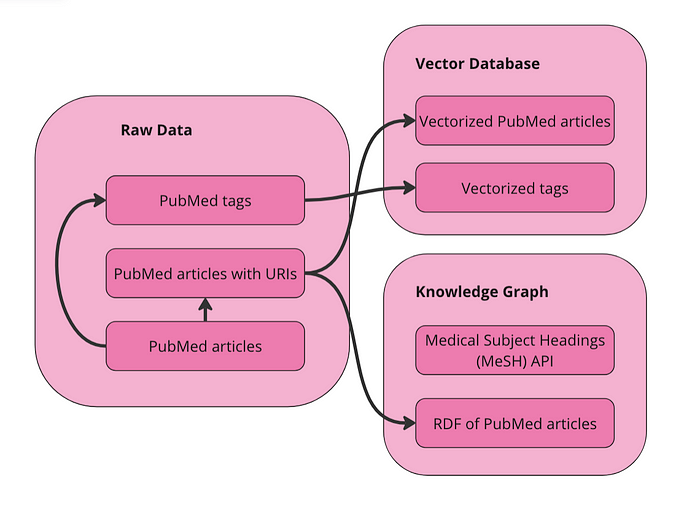
我们在向量数据库中有两个集合可供查询:articles(文章) 和 terms(术语)。 同时,我们也将数据以 RDF 格式表示成了图结构。由于 MeSH 提供了 API,因此我会直接通过调用 API 来获取术语的替代名称和更窄的概念。
在 Weaviate 中向量化数据
首先导入所需的包,并设置 Weaviate 客户端:
import weaviate
from weaviate.util import generate_uuid5
from weaviate.classes.init importAuth
import os
import json
import pandas as pd
client = weaviate.connect_to_weaviate_cloud(
cluster_url="XXX",# 替换为你的 Weaviate Cloud URL
auth_credentials=Auth.api_key("XXX"),# 替换为你的 Weaviate Cloud 密钥
headers={'X-OpenAI-Api-key':"XXX"}# 替换为你的 OpenAI API 密钥
)读取 PubMed 期刊文章数据。我是在 Databricks 上运行这个 notebook 的,如果你在其他环境运行,可能需要做些调整。目标是将数据加载为一个 pandas 的 DataFrame。
df = spark.sql("SELECT * FROM workspace.default.pub_med_multi_label_text_classification_dataset_processed").toPandas()如果你在本地运行,只需使用:
df = pd.read_csv("PubMed Multi Label Text Classification Dataset Processed.csv")接下来对数据做一些清洗处理:
import numpy as np
# 将无穷值替换为 NaN,并将 NaN 替换为空字符串
df.replace([np.inf,-np.inf], np.nan, inplace=True)
df.fillna('', inplace=True)
# 将列转换为字符串类型
df['Title']= df['Title'].astype(str)
df['abstractText']= df['abstractText'].astype(str)
df['meshMajor']= df['meshMajor'].astype(str)现在我们需要为每篇文章创建一个 URI,并将其作为新列添加到 DataFrame 中。这非常重要,因为 URI 是连接文章的向量表示与知识图谱表示的关键。
import urllib.parse
from rdflib importGraph, RDF, RDFS,Namespace,URIRef,Literal
# 创建合法 URI 的函数
def create_valid_uri(base_uri, text):
if pd.isna(text):
returnNone
# 对文本进行转义,适用于 URI
sanitized_text = urllib.parse.quote(
text.strip().replace(' ','_')
.replace('"','')
.replace('<','')
.replace('>','')
.replace("'","_")
)
returnURIRef(f"{base_uri}/{sanitized_text}")
# 为文章创建合法 URI
def create_article_uri(title, base_namespace="http://example.org/article/"):
"""
通过替换非单词字符并进行 URL 编码,为文章创建 URI。
参数:
title (str):文章标题
base_namespace (str): URI 的命名空间
返回:
URIRef:格式化后的文章 URI
"""
if pd.isna(title):
returnNone
# 替换非单词字符为下划线
sanitized_title = re.sub(r'\W+','_', title.strip())
# 合并多个下划线为一个
sanitized_title = re.sub(r'_+','_', sanitized_title)
# URL 编码
encoded_title = quote(sanitized_title)
# 拼接 URI
uri = f"{base_namespace}{encoded_title}"
returnURIRef(uri)
# Add a new column to the DataFrame for the article URIs
df['Article_URI']= df['Title'].apply(lambda title: create_valid_uri("http://example.org/article", title))我们还需要创建一个包含所有用于标注文章的 MeSH 术语 的 DataFrame,这在后续执行类似术语搜索时会非常有帮助。
# 用于清洗和解析 MeSH 术语的函数
def parse_mesh_terms(mesh_list):
if pd.isna(mesh_list):
return[]
return[
term.strip().replace(' ','_')
for term in mesh_list.strip("[]'").split(',')
]
# 创建合法 MeSH 术语 URI 的函数
def create_valid_uri(base_uri, text):
if pd.isna(text):
returnNone
sanitized_text = urllib.parse.quote(
text.strip()
.replace(' ','_')
.replace('"','')
.replace('<','')
.replace('>','')
.replace("'","_")
)
return f"{base_uri}/{sanitized_text}"
# 提取并处理所有 MeSH 术语
all_mesh_terms =[]
for mesh_list in df["meshMajor"]:
all_mesh_terms.extend(parse_mesh_terms(mesh_list))
# 去重术语
unique_mesh_terms = list(set(all_mesh_terms))
# 创建包含 MeSH 术语及其 URI 的 DataFrame
mesh_df = pd.DataFrame({
"meshTerm": unique_mesh_terms,
"URI":[create_valid_uri("http://example.org/mesh", term)for term in unique_mesh_terms]
})
# 显示结果
print(mesh_df)向量化文章 DataFrame:
from weaviate.classes.config importConfigure
# 定义 Article 集合
articles = client.collections.create(
name ="Article",
vectorizer_config=Configure.Vectorizer.text2vec_openai(),# 如果设置为 "none",你必须手动提供向量。也可以使用其他 "text2vec-*" 模型。
generative_config=Configure.Generative.openai(),# 确保使用 generative-openai 模块来支持生成式查询
)
# 获取集合对象
articles = client.collections.get("Article")
# 批量添加对象
with articles.batch.dynamic()as batch:
for index, row in df.iterrows():
batch.add_object({
"title": row["Title"],
"abstractText": row["abstractText"],
"Article_URI": row["Article_URI"],
"meshMajor": row["meshMajor"],
})向量化 MeSH 术语:
# 定义 term 集合
terms = client.collections.create(
name ="term",
vectorizer_config=Configure.Vectorizer.text2vec_openai(),# 如果设置为 "none",你必须手动提供向量。也可以使用其他 "text2vec-*" 模型。
generative_config=Configure.Generative.openai(),# 确保使用 generative-openai 模块来支持生成式查询
)
# 获取集合对象
terms = client.collections.get("term")
# 批量添加对象
with terms.batch.dynamic()as batch:
for index, row in mesh_df.iterrows():
batch.add_object({
"meshTerm": row["meshTerm"],
"URI": row["URI"],
})你可以在这个阶段直接对向量化后的数据集运行语义搜索、相似度搜索和 RAG。我在这里不会逐一展示这些操作,但你可以查看我配套的 notebook[12] 中的代码来实现这些功能。
将数据转化为知识图谱
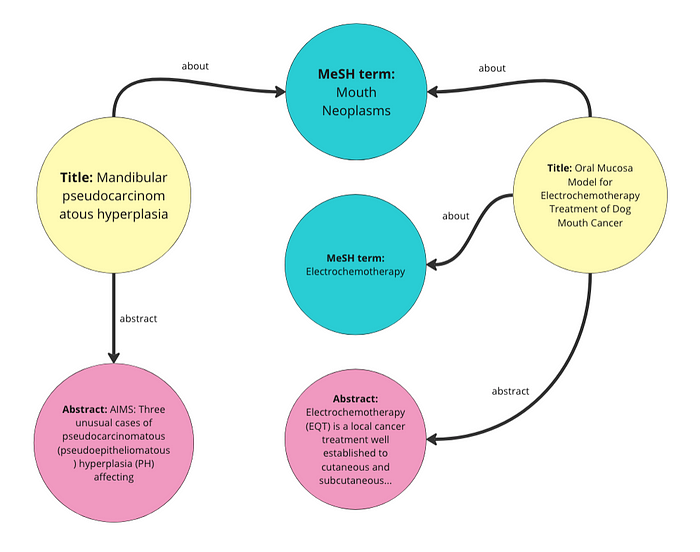
我们基本上是将数据中的每一行转化为知识图谱中的一个 “Article(文章)” 实体。然后我们为每篇文章添加以下属性:标题(title)、摘要(abstract)和 MeSH 术语。我们同时也将每一个 MeSH 术语本身转化为一个实体。这段代码还为每篇文章添加了两个额外属性,一个叫做 date published 的属性,值是随机日期;一个叫做 access 的属性,值是 1 到 10 的随机数字。这两个属性在本演示中不会被使用。下面是我们根据这些数据创建的图谱的可视化结构示意图:
下面是如何遍历 DataFrame 并将其转换为 RDF 数据的过程:
from rdflib importGraph, RDF, RDFS,Namespace,URIRef,Literal
from rdflib.namespaceimport SKOS, XSD
import pandas as pd
import urllib.parse
import random
from datetime import datetime, timedelta
import re
from urllib.parse import quote
# --- 初始化 ---
g =Graph()
# 定义命名空间
schema =Namespace('http://schema.org/')
ex =Namespace('http://example.org/')
prefixes ={
'schema': schema,
'ex': ex,
'skos': SKOS,
'xsd': XSD
}
for p, ns in prefixes.items():
g.bind(p, ns)
# 定义类和属性
Article=URIRef(ex.Article)
MeSHTerm=URIRef(ex.MeSHTerm)
g.add((Article, RDF.type, RDFS.Class))
g.add((MeSHTerm, RDF.type, RDFS.Class))
title =URIRef(schema.name)
abstract=URIRef(schema.description)
date_published =URIRef(schema.datePublished)
access =URIRef(ex.access)
g.add((title, RDF.type, RDF.Property))
g.add((abstract, RDF.type, RDF.Property))
g.add((date_published, RDF.type, RDF.Property))
g.add((access, RDF.type, RDF.Property))
# 解析 MeSH 术语的函数
def parse_mesh_terms(mesh_list):
if pd.isna(mesh_list):
return[]
return[term.strip()for term in mesh_list.strip("[]'").split(',')]
# MeSH 术语转换为合法 URI 的增强函数
def convert_to_uri(term, base_namespace="http://example.org/mesh/"):
if pd.isna(term):
returnNone# 处理 NaN 或 None 情况
# 第一步:去除首尾的非单词字符(包括下划线)
stripped_term = re.sub(r'^\W+|\W+$','', term)
# 第二步:将非单词字符替换为下划线
formatted_term = re.sub(r'\W+','_', stripped_term)
# 第三步:将多个连续下划线合并为一个
formatted_term = re.sub(r'_+','_', formatted_term)
# 第四步:URL 编码
encoded_term = quote(formatted_term)
# 第五步:添加单个前后下划线
term_with_underscores = f"_{encoded_term}_"
# 第六步:拼接命名空间
uri = f"{base_namespace}{term_with_underscores}"
returnURIRef(uri)
# 生成最近五年内随机日期的函数
def generate_random_date():
start_date = datetime.now()- timedelta(days=5*365)
random_days = random.randint(0,5*365)
return start_date + timedelta(days=random_days)
# 生成 1 到 10 之间随机访问级别的函数
def generate_random_access():
return random.randint(1,10)
# 创建文章 URI 的函数
def create_article_uri(title, base_namespace="http://example.org/article"):
if pd.isna(title):
returnNone
sanitized_text = urllib.parse.quote(
title.strip().replace(' ','_').replace('"','').replace('<','').replace('>','').replace("'","_")
)
returnURIRef(f"{base_namespace}/{sanitized_text}")
# 遍历 DataFrame 的每一行并生成 RDF 三元组
for index, row in df.iterrows():
article_uri = create_article_uri(row['Title'])
if article_uri isNone:
continue
# 添加 Article 实体
g.add((article_uri, RDF.type,Article))
g.add((article_uri, title,Literal(row['Title'], datatype=XSD.string)))
g.add((article_uri,abstract,Literal(row['abstractText'], datatype=XSD.string)))
# 添加随机发布日期和访问级别
random_date = generate_random_date()
random_access = generate_random_access()
g.add((article_uri, date_published,Literal(random_date.date(), datatype=XSD.date)))
g.add((article_uri, access,Literal(random_access, datatype=XSD.integer)))
# 添加 MeSH 术语
mesh_terms = parse_mesh_terms(row['meshMajor'])
for term in mesh_terms:
term_uri = convert_to_uri(term, base_namespace="http://example.org/mesh/")
if term_uri isNone:
continue
# 添加 MeSH 实体
g.add((term_uri, RDF.type,MeSHTerm))
g.add((term_uri, RDFS.label,Literal(term.replace('_',' '), datatype=XSD.string)))
# 将文章与 MeSH 术语关联
g.add((article_uri, schema.about, term_uri))
# 保存为 Turtle 格式文件
# 保存路径
file_path ="/Workspace/PubMedGraph.ttl"
# 序列化保存
g.serialize(destination=file_path, format='turtle')
print(f"文件已保存至 {file_path}")现在我们已经拥有了数据的向量化版本和图谱(RDF)版本。每个向量都关联了一个 URI,该 URI 对应于知识图谱中的一个实体,因此我们可以在这两种数据格式之间进行来回切换。
构建应用
我决定使用 Streamlit[13] 来构建这个 Graph RAG 应用的用户界面。 与上一篇博客一样,我保留了相同的用户流程:
1.文章检索:首先,用户使用搜索词进行文章检索。这个过程完全依赖于向量数据库。用户的搜索词被发送至向量数据库,然后返回与该词在向量空间中最近的十篇文章。2.术语精炼:接下来,用户选择用于筛选文章的 MeSH 术语。由于我们也对 MeSH 术语进行了向量化,用户可以输入自然语言提示,来获取最相关的 MeSH 术语。我们还允许用户展开术语,查看其替代名称和更窄的概念,并让用户从中自由选择多个术语,作为筛选条件。3.筛选与摘要生成:用户将选定的 MeSH 术语应用于第一步返回的十篇期刊文章上,进行筛选。这一步之所以可行,是因为 PubMed 文章已被 MeSH 术语标注过。最后,用户可以输入一个附加提示词,我们将该提示词与筛选后的文章一起发送给 LLM,执行生成任务。这就是 RAG 应用中的生成式步骤(generative step)。
接下来我们逐步讲解这些步骤。完整的应用和代码你可以在我的 GitHub 上查看,下面是该应用的结构概要:
-- app.py(主程序文件,用于驱动整个应用并按需调用其他函数)
-- query_functions(一个包含查询相关Python文件的文件夹)
-- rdf_queries.py(包含 RDF 查询的Python文件)
-- weaviate_queries.py(包含Weaviate查询的Python文件)
--PubMedGraph.ttl(以 RDF Turtle格式存储的PubMed数据文件)搜索文章
首先,我们要实现的是 Weaviate 的向量相似度搜索功能。由于我们的文章已经被向量化,因此可以将一个搜索词发送给向量数据库, 然后返回与该搜索词相似的文章。
主函数位于 app.py 中,负责在向量数据库中搜索相关期刊文章:
# --- TAB 1: Search Articles ---
with tab_search:
st.header("搜索文章(向量查询)")
query_text = st.text_input("请输入你的向量搜索词(例如:Mouth Neoplasms):", key="vector_search")
if st.button("搜索文章", key="search_articles_btn"):
try:
client = initialize_weaviate_client()
article_results = query_weaviate_articles(client, query_text)
# 提取 URI
article_uris =[
result["properties"].get("article_URI")
for result in article_results
if result["properties"].get("article_URI")
]
# 将 article_uris 存入 session 状态
st.session_state.article_uris = article_uris
st.session_state.article_results =[
{
"Title": result["properties"].get("title","N/A"),
"Abstract":(result["properties"].get("abstractText","N/A")[:100]+"..."),
"Distance": result["distance"],
"MeSH Terms":", ".join(
ast.literal_eval(result["properties"].get("meshMajor","[]"))
if result["properties"].get("meshMajor")else[]
),
}
for result in article_results
]
client.close()
exceptExceptionas e:
st.error(f"文章搜索过程中发生错误:{e}")
if st.session_state.article_results:
st.write("**文章搜索结果:**")
st.table(st.session_state.article_results)
else:
st.write("目前尚未找到文章。")该函数使用 weaviate_queries 中的查询函数来初始化 Weaviate 客户端(initialize_weaviate_client),并执行文章查询(query_weaviate_articles)。之后,系统会以表格形式展示返回的文章内容,包括:标题,摘要(前 100 个字符),向量距离(与搜索词的相似度),MeSH 术语标签。
weaviate_queries.py 中实际用于查询 Weaviate 的函数如下(即将介绍):
# 查询 Weaviate 中 Article 集合的函数
def query_weaviate_articles(client, query_text, limit=10):
# 对 Article 集合执行向量搜索
response = client.collections.get("Article").query.near_text(
query=query_text,
limit=limit,
return_metadata=MetadataQuery(distance=True)
)
# 解析返回结果
results =[]
for obj in response.objects:
results.append({
"uuid": obj.uuid,
"properties": obj.properties,
"distance": obj.metadata.distance,
})
return results如你所见,我在这里将结果数量限制为 10 个,以简化操作,但你可以根据需要修改这个值。这段代码只是使用 Weaviate 的向量相似度搜索功能,来返回相关的文章结果。
最终在应用中的显示效果如下图所示:
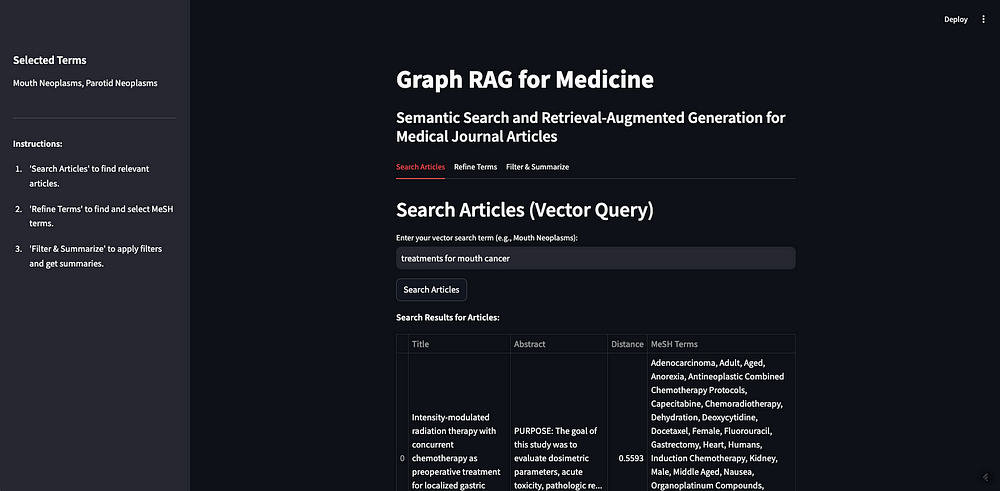
作为演示,我搜索了术语 “treatments for mouth cancer(口腔癌的治疗方法)”。如你所见,返回了 10 篇文章,且大多数都是相关的。这很好地展示了基于向量的检索方法的优点与不足。
优点在于,我们可以非常轻松地为数据构建语义搜索功能。正如你在上面看到的,我们所做的只是初始化客户端,并将数据发送到向量数据库中。一旦数据被向量化,我们就可以执行 语义搜索 、 相似度搜索 、RAG(检索增强生成)。我在本篇配套的 Notebook 中已经实现了部分功能,更多内容可以参考 Weaviate[14] 的官方文档。
👉未完待续!
更多信息
本文由笔者翻译整理自:https://medium.com/data-science/how-to-build-a-graph-rag-app-b323fc33ba06,如对你有帮助,请帮忙点赞、转发、评论,谢谢!
References
[1] 这里:https://github.com/SteveHedden/kg_llm/tree/main/graphRAGapp
[2]这个视频:https://www.youtube.com/watch?v=knDDGYHnnSI
[3]客户服务机器人:https://arxiv.org/pdf/2404.17723
[4]新药研发(药物发现):https://blog.biostrand.ai/integrating-knowledge-graphs-and-large-language-models-for-next-generation-drug-discovery
[5]生命科学行业的自动合规报告生成:https://www.weave.bio/
[6]人力资源中的人才获取与管理 :https://beamery.com/resources/news/beamery-announces-talentgpt-the-world-s-first-generative-ai-for-hr
[7]法律研究与文书撰写:https://legal.thomsonreuters.com/blog/retrieval-augmented-generation-in-legal-tech/
[8]财富管理顾问助手:https://www.cnbc.com/amp/2023/03/14/morgan-stanley-testing-openai-powered-chatbot-for-its-financial-advisors.html
[9]本Notebook:https://github.com/SteveHedden/kg_llm/blob/main/graphRAGapp/VectorVsKG_updated.ipynb
[10]数据集:https://creativecommons.org/publicdomain/zero/1.0/
[11]资源标识符:https://en.wikipedia.org/wiki/Uniform_Resource_Identifier
[12]notebook:https://github.com/SteveHedden/kg_llm/tree/main/graphRAGapp
[13]Streamlit:https://streamlit.io/
[14]Weaviate: https://weaviate.io/developers/weaviate
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号