deepseek-ocr及其他ocr模型衍生应用的思考

deepseek-ocr及其他ocr模型衍生应用的思考

山行AI
发布于 2026-03-13 18:46:29
发布于 2026-03-13 18:46:29
关于deepseek-ocr相关的应用,一个最直观的能力应该是在前端界面上操作可以指定模型完成文档、图表、图像的识别、图像的标注等功能。本文将重点介绍一款比较好的前端开源实现和一款可同时支持DeepSeek-OCR / PaddleOCR-VL / DotsOCR的后端开源实现,并思考将二者整合的可能性。
前端UI
🔍 DeepSeek-OCR-WebUI
DeepSeek-OCR-WebUI 是一个基于 DeepSeek-OCR 模型的智能图像识别 Web 应用,提供直观的用户界面和强大的识别功能。
GitHub - neosun100/DeepSeek-OCR-WebUI: 🎨 Ready-to-use DeepSeek-OCR Web UI | Modern Interface | 7 Recognition Modes | Batch Processing | Real-time Logging | Fully Responsive[1]
✨ 核心亮点
•🎯 7 种识别模式 - 文档、OCR、图表、查找、自定义等•🖼️ 边界框可视化 - Find 模式自动标注位置•📦 批量处理 - 支持多张图片逐一识别•📄 PDF 支持 - 上传 PDF 文件,自动转换为图片•🎨 现代化 UI - 炫酷的渐变背景和动画效果•🌐 多语言支持 - 简体中文、繁体中文、英语、日语•🍎 Apple Silicon 支持 - Mac M1/M2/M3/M4 原生 MPS 加速•🐳 Docker 部署 - 一键启动,开箱即用•⚡ GPU 加速 - 基于 NVIDIA GPU 的高性能推理•🌏 ModelScope 自动切换 - HuggingFace 不可用时自动切换
7 种识别模式
模式 | 图标 | 说明 | 适用场景 |
|---|---|---|---|
文档转Markdown | 📄 | 保留格式和布局 | 合同、论文、报告 |
通用OCR | 📝 | 提取所有可见文字 | 图片文字提取 |
纯文本提取 | 📋 | 纯文本不保留格式 | 简单文本识别 |
图表解析 | 📊 | 识别图表和公式 | 数据图表、数学公式 |
图像描述 | 🖼️ | 生成详细描述 | 图片理解、无障碍 |
查找定位 ⭐ | 🔍 | 查找并标注位置 | 发票字段定位 |
自定义提示 ⭐ | ✨ | 自定义识别需求 | 灵活的识别任务 |
📄 PDF 支持(v3.2 新功能)
DeepSeek-OCR-WebUI 现已支持 PDF 文件上传!上传 PDF 文件后,系统会自动将每一页转换为独立的图片,并保持后续的所有处理逻辑(OCR识别、批量处理等)。
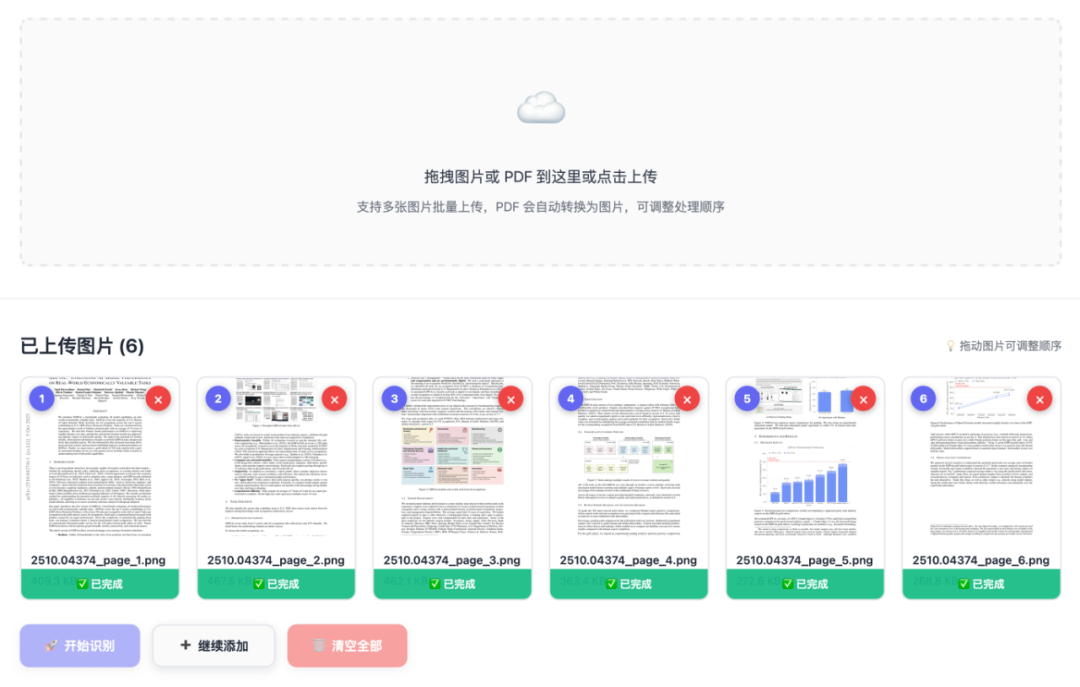
PDF 上传并自动转换为图片 - 每页成为独立的图片进行处理
核心功能:
•多页 PDF 转换:自动将每页转换为独立的图片•实时进度显示:逐页显示转换进度•拖拽上传:支持拖拽上传 PDF 文件•Find 模式支持:Find 模式支持 PDF(自动使用第一页)•格式验证:自动文件类型检测和错误提示•无缝集成:转换后的图片与普通图片遵循相同的处理流程
🎨 Find 模式特色
左右分栏布局:
┌──────────────────────┬─────────────────────────────┐
│左侧:操作面板│右侧:结果展示│
├──────────────────────┼─────────────────────────────┤
│📤图片上传│🖼️结果图片(带边界框)│
│🎯查找词输入│📊统计信息│
│🚀操作按钮│📝识别文本│
││📦匹配项列表│
└──────────────────────┴─────────────────────────────┘边界框可视化:
•🟢 彩色霓虹边框自动标注•🎨 6 种颜色循环显示•📍 精确的坐标定位•🔄 响应式自动重绘
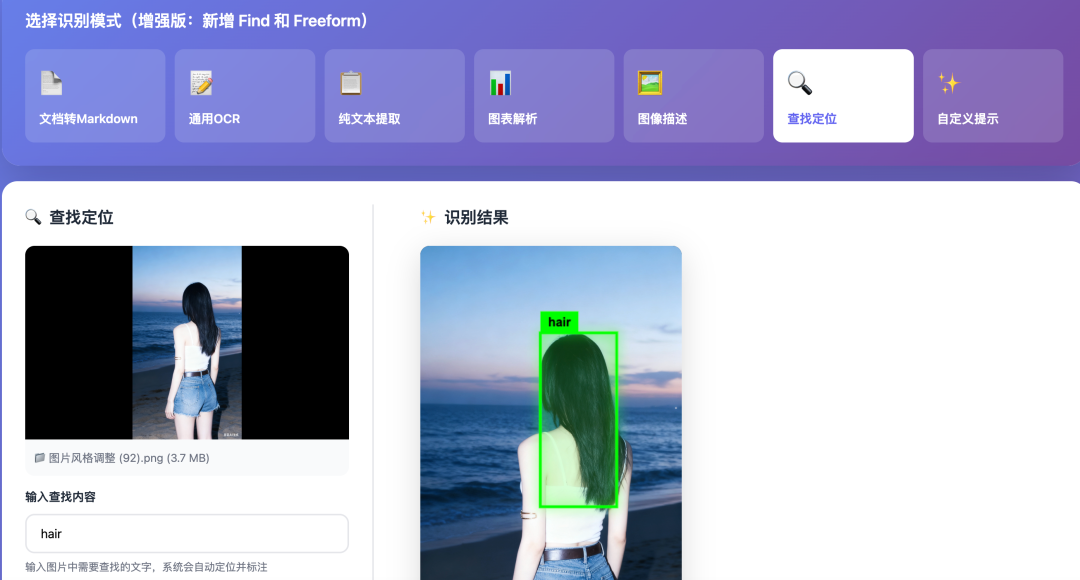
DeepSeek-OCR-WebUI本身是具有自己的前端和后端的,也就是说直接使用该项目是可以实现对deepseek-ocr的部署和使用的。那么,为什么我还要强调,只使用它的前端部分呢?因为,我找到了更好的后端部署管理的方式。
后端部署管理
deepseek-ocr.rs 🚀
Rust 实现的 DeepSeek-OCR 推理栈,提供快速 CLI 与 OpenAI 兼容的 HTTP Server,统一打包多种 OCR 后端、视觉输入预处理、提示词工具与服务端能力,方便在本地 CPU、Apple Metal 或 NVIDIA CUDA GPU(alpha) 上构建文档理解工作流。
英文文档请参见 README.md。
想直接下载可执行文件?访问 Github Actions[2],下载最新一次成功运行生成的 macOS(含 Metal)或 Windows 压缩包。
模型选择指南 🔬
模型 | 内存占用* | 最佳硬件 | 适用场景 |
|---|---|---|---|
DeepSeek‑OCR | ≈6.3GB FP16 权重,含激活/缓存约 13GB(512 token) | Apple Silicon + Metal、24GB VRAM NVIDIA、32GB+ RAM 桌面 | 追求最高准确率、多视角文档、对延迟不敏感。SAM+CLIP 视觉 + DeepSeek‑V2 MoE(3B 参数,单 token 激活 ≈570M)。 |
PaddleOCR‑VL | ≈4.7GB FP16 权重,含激活/缓存约 9GB | 16GB 笔电、CPU-only 节点、中端 GPU | 更快冷启动,dense Ernie decoder(0.9B)+ SigLIP 视觉,适合批量作业与轻量部署。 |
DotsOCR | ≈9GB FP16 权重,但高分辨率图像通常需要 30–50GB RAM/VRAM(视觉 token 数极大) | Apple Silicon + Metal BF16、≥24GB CUDA、或 64GB RAM CPU 工作站 | DotsVision + Qwen2 统一 VLM,在版面、阅读顺序、grounding、多语种公式等任务表现最好,代价是显著的内存和延迟。 |
*默认 FP16 safetensors 容量;实际资源与序列长度、是否启用 KV Cache 相关。
选择建议:
•有 16–24GB 以上 VRAM / RAM、追求极致质量? 选 DeepSeek‑OCR,SAM+CLIP 全局+局部视野、DeepSeek‑V2 MoE 解码能在复杂版式中保持更高还原度,但代价是更大的显存和更高延迟。•硬件预算有限或需要低延迟 / 高吞吐? 选 PaddleOCR‑VL,SigLIP + dense Ernie(18 层、hidden 1024)在 10GB 以内即可运行,CPU 模式也更易部署。•手头有充裕显存/内存,重视阅读顺序、grounding、复杂多语种 PDF? 选 DotsOCR,在 Metal/CUDA 上配合 --dtype bf16(或 CUDA 下 --dtype f16)能获得更稳定的推理速度,但需接受 40 tok/s 左右预填充与数+ GB RSS 的成本。
为什么选择 Rust?💡
官方 DeepSeek-OCR 依赖 Python + Transformers,部署体积大、依赖多,嵌入原生系统成本高。Rust 重写后的优势:
•无需 Python 运行时或 conda,产物更小、更易嵌入。•内存安全、线程友好,可直接融入现有 Rust 服务。•CLI 与 Server 共用一套核心逻辑,避免重复维护。•依旧兼容 OpenAI 客户端,同时聚焦单轮 OCR 场景确保输出稳定。
技术栈 ⚙️
•Candle:Rust 深度学习框架,支持 Metal/CUDA(alpha) 与 FlashAttention。•Rocket:异步 HTTP 框架,提供 /v1/responses、/v1/chat/completions 等 OpenAI 兼容路由。•tokenizers:上游模型提供的 Tokenizer,通过 crates/assets 在 Hugging Face / ModelScope 镜像间缓存与校验。•纯 Rust 视觉/Prompt 管线:CLI 与 Server 复用,减少重复逻辑。
相比 Python 实现的优势 🥷
•Apple Silicon 冷启动更快、内存占用更低,且提供原生二进制分发。•资产下载/校验由 Rust crate 统一托管,可在 Hugging Face 与 ModelScope 之间自动切换。•自动折叠多轮会话,仅保留最近一次 user 提示,确保 OCR 场景稳定。•与 Open WebUI 等 OpenAI 客户端“即插即用”,无需额外适配层。
项目亮点 ✨
•一套代码,两种入口:批处理友好的 CLI 与兼容 /v1/responses、/v1/chat/completions 的 Rocket Server。•开箱即用:首次运行自动从 Hugging Face 或 ModelScope(取决于实时延迟)拉取配置、Tokenizer 与权重。•Apple Silicon 友好:Metal + FP16 加速让笔记本也能实时 OCR。•NVIDIA GPU(α 测试):构建时附加 --features cuda 并以 --device cuda --dtype f16 运行,可在 Linux/Windows 上尝鲜 CUDA 加速。•Intel MKL(预览):安装 Intel oneMKL 后,构建时附加 --features mkl 以提升 x86 CPU 上的矩阵运算速度。•OpenAI 客户端即插即用:Server 端自动折叠多轮对话,只保留最新 user 指令,避免 OCR 模型被多轮上下文干扰。
模型矩阵 📦
本仓库当前暴露 3 个基础模型 ID,以及 DeepSeek‑OCR / PaddleOCR‑VL 的 DSQ 量化变体:
Model ID | Base Model | Precision | 建议使用场景 |
|---|---|---|---|
deepseek-ocr | deepseek-ocr | FP16(通过 --dtype 选择实际精度) | 完整 DeepSeek‑OCR 管线(SAM+CLIP + MoE 解码),在 Metal/CUDA/大内存 CPU 上追求最高质量时使用。 |
deepseek-ocr-q4k | deepseek-ocr | Q4_K | 显存非常紧张、本地离线批处理等场景,在牺牲一定精度的前提下压缩模型体积。 |
deepseek-ocr-q6k | deepseek-ocr | Q6_K | 常规工程环境下的折中选择,在质量与体积之间取得平衡。 |
deepseek-ocr-q8k | deepseek-ocr | Q8_0 | 希望尽量接近全精度质量,同时仍获得一定压缩收益。 |
paddleocr-vl | paddleocr-vl | FP16(通过 --dtype 选择实际精度) | 默认推荐的轻量后端:0.9B Ernie + SigLIP,在 CPU/16GB 笔电等硬件上也能流畅运行。 |
paddleocr-vl-q4k | paddleocr-vl | Q4_K | 面向大规模、强压缩的文档/表格场景,对精度要求相对较低。 |
paddleocr-vl-q6k | paddleocr-vl | Q6_K | 通用推荐,适合绝大多数工程部署。 |
paddleocr-vl-q8k | paddleocr-vl | Q8_0 | 更偏向准确率、仍比 FP16 更节省显存。 |
dots-ocr | dots-ocr | FP16 / BF16(运行时 --dtype 决定) | DotsVision + Qwen2 统一 VLM,用于复杂版面、多语种、阅读顺序与 grounding 场景;高分辨率时内存占用可达 30–50GB。 |
dots-ocr-q4k | dots-ocr | Q4_K | 在已接受 DotsOCR 内存 profile 的前提下,通过 DSQ snapshot 对权重做强压缩;适合极端显存/内存预算。 |
dots-ocr-q6k | dots-ocr | Q6_K | 推荐的折中量化档位:在大幅节省权重占用的同时尽量贴近 FP16/BF16 质量。 |
dots-ocr-q8k | dots-ocr | Q8_0 | 偏向精度的量化版本,在全精度基础上做温和压缩。 |
量化模型的元数据来源于 crates/assets/src/lib.rs:40-120 中的 QUANTIZED_MODEL_ASSETS,并由 crates/dsq-models/src/adapters 下的适配器导出。DotsOCR 现在提供 dots-ocr-q4k / dots-ocr-q6k / dots-ocr-q8k 三个 DSQ 变体,这些 .dsq 文件都是基于原始 safetensors 的“补丁”,推理时仍然需要同时存在 baseline 权重与 snapshot。
总结
以 deepseek-ocr.rs 为支持多种ocr模型的稳固后端、以 DeepSeek-OCR-WebUI 为成熟前端,构建“一个入口,多后端,多形态”的新产品应当是具备明确可行性的。目前笔者已经实现了大部分功能,有想法的可以一起探讨。
References
[1] GitHub - neosun100/DeepSeek-OCR-WebUI: 🎨 Ready-to-use DeepSeek-OCR Web UI | Modern Interface | 7 Recognition Modes | Batch Processing | Real-time Logging | Fully Responsive: https://github.com/neosun100/DeepSeek-OCR-WebUI
[2] Github Actions: https://github.com/TimmyOVO/deepseek-ocr.rs/actions/workflows/build-binaries.yml
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号