我很笨--学习PG Vector 1个小时我懂得了为什么用HNSW不用IVFFlat (系列 3 )

我很笨--学习PG Vector 1个小时我懂得了为什么用HNSW不用IVFFlat (系列 3 )

AustinDatabases
发布于 2026-03-12 18:36:08
发布于 2026-03-12 18:36:08
❝开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, OceanBase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,可以解决你的问题。加群请联系 liuaustin3 ,(共3400人左右 1 + 2 + 3 + 4 +5 + 6 + 7 + 8 +9)(1 2 3 4 5 6 7 8群已经爆满 9群 300+,开10群PolarDB专业学习群110+)
我很笨--学习PG Vector 1个小时我懂得了索引 基本原理--要不你也试试!! (系列 2 )
我很笨--学习PGVector的 1个小时我懂得了AI 基本的原理--要不你也试试!!
我们接着上期,在使用PostgreSQL Vector 进行向量学习的过程中,上期我们提出的IVFFlat的查询的案例和基本的原理。
随着查询的维度也就是大模型的维度加大如OPENAI 1536个维度,索引会变得巨大,导致内存溢出,并触发大量的磁盘交换,所以在这里建议使用半精度的方式来,因为这样可以立即节省50%的内存和磁盘空间,就是將vector类型换成halfvec 16位的浮点数,
但这里也有人说,IVFFlat使用的空间换时间,而HNSW是逻辑换时间的方式。IVVFlat是需要先进行训练,然后将数据插入到bucket中,查询扫描一部分bucket,其中核心的点就是数据分布变动,导致精度不稳定,高并发下需要扫描更多的lists才能稳定recall.
所以高维对IVFFlat查询是一个非常不好的查询选择,一句话解释,本来10个人住10个房子,我们进行分类分成10类就好,但是现在1000个人要住10个房子,分类将变得模糊,数据的准确度会降低。

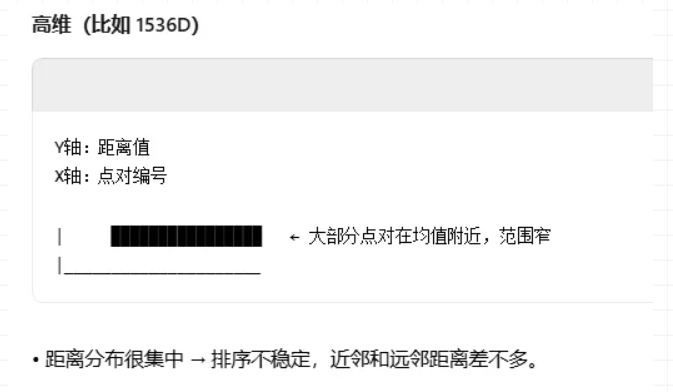
这就导致
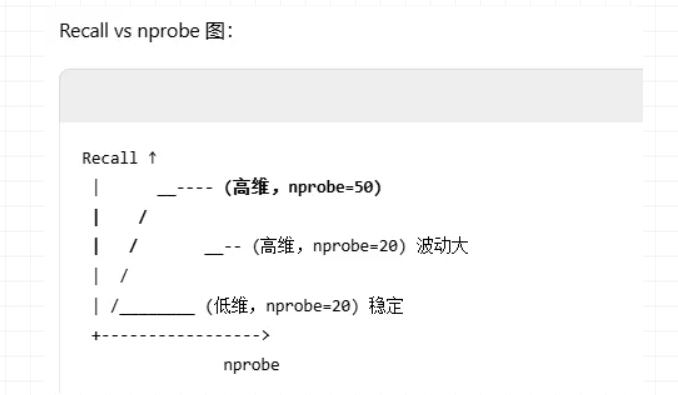

所以维度越高,则IVFFLat的方案越不行,我们需要更换成HNSW的方案,使用 halfvec的方案。
-- 在 halfvec 类型上创建 HNSW 索引
CREATE INDEX ON items USING hnsw (embedding halfvec_l2_ops) WITH (m = 16, ef_construction = 64);
下面我们模拟一下IVFFlat 和 HNSW 建立索引的不同,下面的案例可以看出为什么在大部分情况,尤其维度比较高的情况下,在PostgreSQL vector 中我们选择的是HNSW,因为在维度较高的情况下,需要更多的内存支持,否则就无法通过 IVFFlat建立索引。
IVFFlat 适合的场景是冷数据,静态数据,批量离线构建,以及内存可以给的足够大的情况适合IVFFLAT建立索引。
CREATE TABLE items_half (
id bigserial PRIMARY KEY,
embedding halfvec(1536)
);
INSERT INTO items_half (embedding)
SELECT array_agg(random())::halfvec(1536)
FROM generate_series(1,1000000) AS g(id)
CROSS JOIN LATERAL generate_series(1,1536) AS d(dim)
GROUP BY g.id;
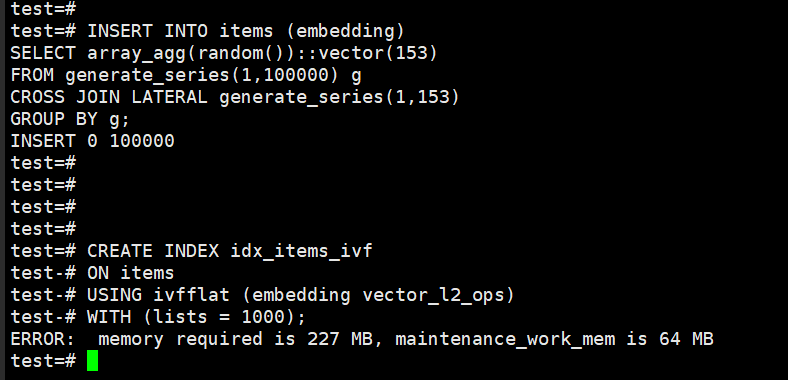
CREATE INDEX idx_items_ivf
ON items
USING ivfflat (embedding vector_l2_ops)
WITH (lists = 1000);
SET ivfflat.probes = 10;
SELECT *
FROM items
ORDER BY embedding <-> '[...]'
LIMIT 10;
HNSW
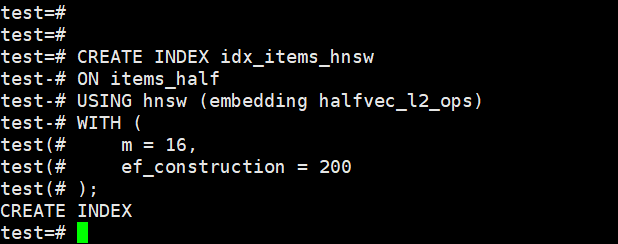
CREATE INDEX idx_items_hnsw
ON items_half
USING hnsw (embedding halfvec_l2_ops)
WITH (
m = 16,
ef_construction = 200
);
SET hnsw.ef_search = 100;
SELECT *
FROM items_half
ORDER BY embedding <-> '[...]'
LIMIT 10;
image
image

image
image
通过上面的简单的训练,我们今天得出一个结论,在向量数据查询中,大部分情况我们应该选择的方式是通过HNSW的方式来构建向量的索引。
这两种索引的特点
1 IVFFlat
需要大量内存,依赖 maintenance_work_mem,数据分布改变后需要重建 工作模式: 抽样,KMeans 训练,生成 centroids,分桶
2 HNSW
从顶层开始,贪心搜索,建立局部连边,插入到底层 工作模式: 无训练阶段,内存峰值低,可持续在线插入
这里有一个建议,当你的维度超过768,你的数据量大于100万,同时需要在线更新数据,并且有高并发的情况,那么你需要选择HNSW,其他的情况还是可以选择IVFFlat。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-01,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 AustinDatabases 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号