Agent Skill真的能统一AI编码工具吗?一场被低估的标准化革命

Agent Skill真的能统一AI编码工具吗?一场被低估的标准化革命

前端达人
发布于 2026-03-12 14:15:47
发布于 2026-03-12 14:15:47

你有没有想过这个问题:为什么我用Claude Code写出的代码技巧,在Cursor里就用不了了?
最近在开发者社区里,关于Agent Skill Standard的讨论越来越多。有人说它会改变整个AI编码工具的生态,有人觉得这只是另一个"看起来很美"的标准,最终会被市场淘汰。但如果你认真看了GitHub上那些开源的Agent Skill,你可能会发现,这场革命比想象中来得更快、更彻底。
今天,我想从一个程序员的角度,拆解Agent Skill Standard到底在做什么,为什么它真的有可能改变我们的工作方式。
你一定经历过这个场景
想象一下你的日常:
你用Claude Code写了个超好用的"代码审查Skill",它能自动帮你检查安全漏洞、性能问题,还会给出优化建议。用了两个月,它已经成了你工作的一部分。
有一天,同事说:"我用Cursor,你那个Skill我能不能用上?"
你的回答只能是:"抱歉,Cursor不支持Claude Code的Skill。"
于是,你的同事又花了两周时间,在Cursor里从头重新写了一遍同样的逻辑。
这看起来很荒唐,对吧?但这就是过去几年开发工具生态里的常态。
现状(没有Agent Skill Standard):
Claude Code Cursor GitHub Copilot
↓ ↓ ↓
Skill写法A Skill写法B Skill写法C
↓ ↓ ↓
Claude专用 Cursor专用 Copilot专用
↓ ↓ ↓
知识无法流转 × 知识无法流转 × 知识无法流转 ×
结果:开发者被迫重复创建相同的轮子
这就是问题所在。
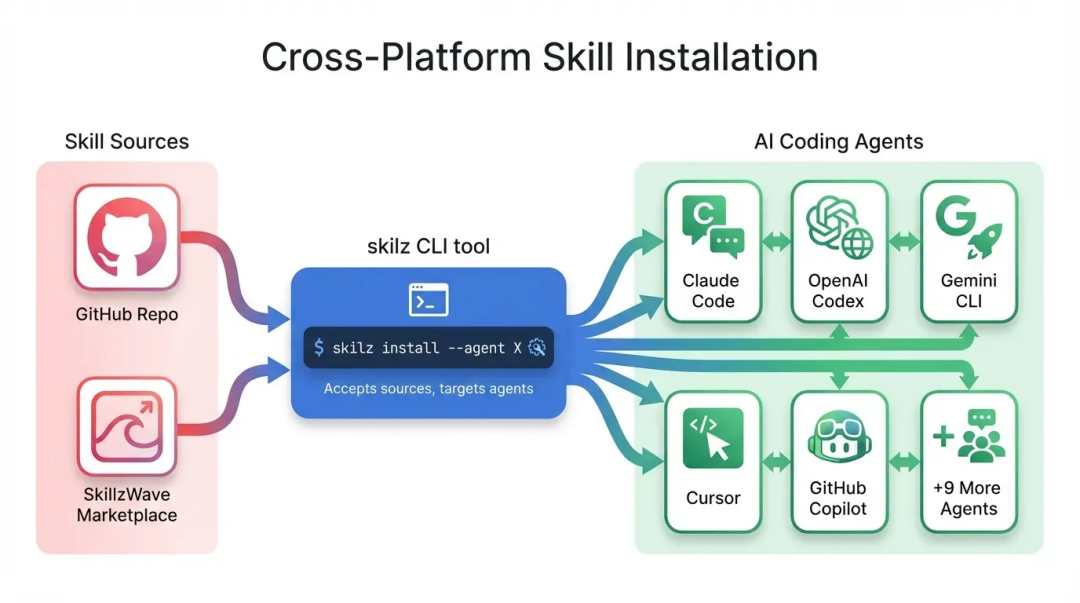
Agent Skill Standard想干什么?
如果用一句话说,Agent Skill Standard做的事情,就像npm对JavaScript、pip对Python一样——建立一套统一的标准,让知识资产可以跨越工具流动。
让我们从技术角度看它的本质。
什么是Agent Skill?
说白了,Agent Skill就是一个文件夹,里面最核心的是一个叫SKILL.md的Markdown文件。
project-memory/
├── SKILL.md # 这是核心,定义Skill的一切
├── references/
│ ├── bugs_template.md
│ ├── decisions_template.md
│ └── key_facts_template.md
└── README.md
这个SKILL.md文件有两部分:
第一部分:YAML Frontmatter(触发器)
---
name:project-memory
description:Setupandmaintainastructuredprojectmemorysystem
indocs/project_notes/thattracksbugswithsolutions,
architecturaldecisions,keyprojectfacts,andworkhistory.
Usethisskillwhenaskedto"set up project memory",
"track our decisions","log a bug fix","update project memory".
---
这部分告诉AI:"我是谁,什么时候应该被激活"。
第二部分:Markdown指令体
## When to Use This Skill
Invoke this skill when:
- Starting a new project that will accumulate knowledge over time
- The project already has recurring bugs or decisions documented
- The user asks to "set up project memory" or "track decisions"
## Core Capabilities
1. Initial Setup - Create Memory Infrastructure
2. Configure CLAUDE.md - Memory-Aware Behavior
3. Searching Memory Files
4. Updating Memory Files
这部分告诉AI:"我能做什么,应该怎么做"。
没有一行代码。完全是纯文本。
为什么不用代码,而非要用Markdown?
这里是关键洞察。
传统的IDE插件(比如VSCode插件)需要用JavaScript写,JetBrains插件需要用Kotlin写,Sublime插件需要用Python写。每次你想在不同的IDE里实现同样的功能,就得重新用那个IDE的编程语言写一遍。
但Agent Skill不同。它用Markdown写,而Markdown是跨平台的——任何支持Agent Skill Standard的工具,都能读懂同一份Markdown文件。
传统IDE插件的模式:
VSCode 插件 ──写成──> JavaScript
JetBrains 插件 ──写成──> Kotlin
Sublime 插件 ──写成──> Python
同样的功能,三套代码,维护三倍工作量
─────────────────────────────────
Agent Skill的模式:
Claude Code ┐
Cursor ├─ 都读这一份 SKILL.md
GitHub Copilot ┘
同样的功能,一份代码,全部适配
这个看似简单的改变,背后的意义是深刻的。
激活机制:Progressive Disclosure
理解Agent Skill如何工作,需要了解它的三阶段激活模式。这是设计上最聪明的地方。
阶段1:Discovery(发现)
你安装了一个Agent Skill后,AI工具会扫描你的skill目录。但它只读取YAML frontmatter部分(name + description),不加载完整的SKILL.md。
为什么?性能。你可能装了100个Skill,但不可能同时用100个。只读metadata很快。
AI工具启动
↓
扫描 ~/.claude/skills/ 和 .claude/skills/
↓
读取所有Skill的 frontmatter(只是name + description)
↓
建立索引 [完成,用时<100ms]
阶段2:Matching(匹配)
当你说一句话时,AI检查你的语句是否与某个Skill的description匹配。
关键是,这个匹配是语义匹配,不是关键词匹配。
比如,你说"我想追踪项目的决策",而某个Skill的description里说"track decisions",AI能够理解这两句话的语义相似,从而激活这个Skill。
用户输入:"我们应该记录一下架构决策"
↓
AI分析语义
↓
搜索已加载的Skill索引
↓
发现 project-memory Skill 的 description 包含"decisions"
↓
计算匹配度 = 87%(语义相似)
↓
触发激活
阶段3:Execution(执行)
这才是加载完整SKILL.md并执行的时刻。
匹配成功
↓
加载 ~/.claude/skills/project-memory/SKILL.md
↓
AI读取 markdown 指令
↓
按照指令执行操作
↓
用户看到结果
这样设计的好处是什么?
第一,性能最优。你有1000个Skill也没关系,因为只会加载需要的那一个。
第二,发现最优。用户不需要记住精确的命令,只需要用自然语言表达需求。
第三,维护最优。修改一个Skill就是改Markdown文本,Git diff清晰,协作简单。
对标:IDE插件生态的历史教训
为了理解Agent Skill Standard的意义,我们得看看IDE插件生态的演变。
VSCode的成功和失败
2015年,微软推出VSCode。一开始,它被认为是一个"新手编辑器"。为什么?因为性能差、功能不全。
但它有一个关键优势:开放的插件生态。
任何开发者都能用JavaScript写插件。不需要深度学习Vim的脚本语言,也不需要研究Emacs的Lisp。门槛低,生态就爆炸式增长。
今天,VSCode占据了全球开发者的40%以上,理由很简单:
- 插件足够好(质量高)
- 插件足够多(选择多)
- 切换成本低(容易学)
但这里有个隐藏的问题:VSCode赢了,但这不是一个健康的市场。
为什么?因为开发者被锁定了。
我用VSCode的 Prettier 插件
↓
我熟悉了 VSCode 的 UI
↓
我买了 VSCode 的键位配置
↓
我写了10个自定义插件
↓
现在,即使 JetBrains 的 IDE 好100倍,我也不想迁移
(迁移成本太高了)
↓
结果:创新停滞,价格上升,用户体验难以改进
这叫"用户锁定",是所有垄断市场的症状。
Agent Skill Standard的反垄断设计
Agent Skill Standard想解决的,正是这个问题。
想象一个新的未来:
我用Claude Code写了一个超好用的 Skill
↓
我把它发布到 SkillzWave marketplace
↓
世界各地的开发者用 skilz CLI 安装它
↓
这个 Skill 在 Claude Code, Cursor, GitHub Copilot, Codex 里都能用
↓
我不需要为每个工具重写一遍
↓
知识真正流动了
更关键的是:
今天我用Claude Code,因为它的Skill生态最好
明天,如果Cursor推出了更好的功能,我可以无缝迁移
(因为我的Skill资产可以带走)
↓
工具厂商之间的竞争变得激烈
↓
他们必须靠功能和体验取胜,而不是靠用户锁定
这才是一个健康的市场应该的样子。
现实情况:这场革命已经开始了
你可能觉得这只是理论。但数据说明,这个生态正在快速成长。
SkillzWave marketplace的成长
在我写这篇文章时,SkillzWave上已经有了1000+个开源Agent Skill,覆盖:
- 代码生成:TypeScript类型生成、测试代码生成、接口代码生成
- 代码审查:安全审查、性能审查、代码质量检查
- 知识管理:项目记忆、决策记录、工作日志
- 文档写作:API文档生成、Markdown规范化、注释生成
- 企业集成:JIRA集成、Confluence集成、Notion集成
- 开发工具链:Git规范、提交信息指南、部署检查
关键数据点:
- 支持的AI工具从3个增长到现在的14个
- 每周有平均100+个新Skill发布
- 最受欢迎的Skill(project-memory)在GitHub上有5000+ stars
这意味着什么?
意味着开发者不再相信单一工具的生态承诺。他们在投资一个跨平台的未来。
国内开发者的机遇
有意思的是,国际化Skill生态中,中文Skill的比例仍然很低(约8%)。
这意味着什么?
意味着国内开发者有巨大的机会。
想象这样的场景:
阿里的开发者写了一个"阿里巴巴编码规范Skill",上传到marketplace。全世界使用同样规范的公司都能用上。
腾讯的工程师贡献了一个"微信小程序最佳实践Skill"。所有做小程序开发的人都能受益。
这不仅仅是代码层面的贡献,而是把中国的技术经验推向全球。
深度思考:Agent Skill Standard能成功吗?
现在,让我说一些可能有争议的话。
成功的条件
Agent Skill Standard要取得成功,需要满足几个条件:
第一:门槛要低
好消息是,写Agent Skill不需要编程能力。你只需要能写Markdown。
我见过最复杂的Skill,也只是用自然语言描述了AI应该做什么。没有一行代码。
这个门槛,比写IDE插件低100倍。
第二:工具要真的支持
这不仅仅需要Claude Code、Cursor、Copilot支持。还需要这些工具在内部积极推动Agent Skill的使用。
目前的信号不错。OpenAI、Google、Anthropic都表态支持这个标准。大公司通常不会在标准上说谎。
第三:必须解决现实问题
Agent Skill Standard不能只是一个"好的想法"。它必须真的让开发者的生活变得更容易。
从我看到的案例来说,确实有效。project-memory这个Skill,帮助开发者自动管理项目决策和bug解决方案,节省了大量时间。这不是虚拟价值。
第四:社区要参与
最关键的是,不能由大公司单独推动。必须由社区主导。
目前看,GitHub上已经有很多社区维护的高质量Skill。这是好信号。
可能的失败风险
但我也要说实话,有些风险不能忽视。
风险1:标准碎片化
历史上,"统一标准"最常见的失败原因,就是标准本身的碎片化。
XML时代,每个公司都说自己支持XML,但实现方式完全不同。最后XML变得一点用都没有。
Agent Skill Standard能避免这个吗?
目前看,agentskills.io的规范定义得很清晰。只要大家都严格遵循,就能避免碎片化。但这需要时间验证。
风险2:安全问题
如果任何人都能写Agent Skill,那开源社区中的恶意Skill怎么办?
比如,有人写了一个看起来很有用的"性能优化Skill",但实际上在窃取你的代码。
这是真实的风险。解决方案需要:社区review、签名验证、沙箱执行等多个层面的保护。
目前的机制还不够完善。
风险3:工具厂商的兴趣衰减
假设,今年Claude Code、Cursor、Copilot都支持Agent Skill。
但两年后呢?
如果某个工具发现,跨平台Skill生态反而威胁了它的垄断地位,它可能会放弃支持。
这取决于这些公司是否真的相信开放生态的长期价值。
我倾向于相信他们会坚持,但也不是100%确定。
这场革命对你意味着什么?
好,理论讲了一堆。现在的问题是:Agent Skill Standard的出现,对你作为开发者意味着什么?
如果你只用一个工具(比如只用Claude Code)
你获得的直接收益可能不大。毕竟,Agent Skill在任何单一工具内都能工作。
但长期来看,你的知识资产变得更有价值了。
现在,你写的Skill可以在任何支持Agent Skill Standard的工具上运行。这意味着,即使哪天你想换工具,这些Skill都能带走。
你从单一工具的"用户"变成了一个"投资者"——在跨平台的生态里投资。
如果你的团队用多个工具
这是Agent Skill Standard最大的价值所在。
想象你的团队:
- 前端开发者用Cursor
- 后端开发者用Claude Code
- DevOps工程师用GitHub Copilot
过去,每个人都得用自己工具的Skill生态,造成了巨大的知识碎片化。
现在,你可以写一个统一的"团队代码规范Skill",在所有工具中使用。
代码审查、提交信息格式、安全检查——这些可以统一。
这个价值有多大?
在有100人的大公司,可能节省每年1000小时以上的沟通成本。
对国内开发者的特殊意义
这是我想特别强调的。
国内开发者一直在跟随国外的技术浪潮。npm、pip、Docker……我们大多数时候都是消费者,而不是创造者。
但Agent Skill不同。
这个生态刚刚成形,国内开发者可以从一开始就参与。
想象这样的场景:
2025年,你写了一个"遵循阿里巴巴Java编码规范的Skill",在SkillzWave上有了10万次下载。
你不需要创建公司,不需要融资,就可以输出全球影响力。
这几年,随着中国AI能力的提升(ChatGPT出现后,国内出现了通义千问、文心一言等),国内AI编码工具(如通义灵码)也在快速发展。
如果Agent Skill Standard真的成为了全球标准,那国内开发者的Skill贡献,就能服务全球用户。
反过来,全球开发者也能学到中国的最佳实践。
这才是真正意义上的"技术输出"。
对比:Agent Skill vs npm包 vs IDE插件
你可能会问:Agent Skill和npm包有什么区别?为什么不直接用npm包呢?
这个问题很好,值得深入讨论。
npm包 IDE插件 Agent Skill
───────────────────────────────────────────────────────────
写法 JavaScript JavaScript Markdown
/Kotlin/Python
门槛 中等 高 低
(需要学JS) (需要学各种语言) (只需学Markdown)
跨平台 否 否 是
(npm生态内) (IDE专用) (通用标准)
学习成本 中 高 低
维护难度 中 高 低
自动激活 否 无 是
(需要手动import) (需要手动菜单) (语义匹配自动激活)
可发现性 中 中 高
(需要npm官网) (需要IDE官网) (Marketplace推荐)
本质的区别在于:
- npm包是库(库能做什么、怎么调用)
- IDE插件是工具扩展(IDE的功能增强)
- Agent Skill是知识编码(把你的经验转化为AI可理解的指令)
一个npm包,需要开发者主动了解它、学习它的API、在代码里调用它。
一个Agent Skill,只需要你告诉Claude你要做什么,Claude自动发现并应用这个Skill。
这听起来像个小差别,但实际上改变了一切。
因为它把"技能发现"从被动变成了主动。
技术细节:为什么选Markdown?
我想深入讨论一个技术问题:为什么Agent Skill用Markdown而不用JSON或YAML?
这涉及到设计者对"可读性"和"执行能力"的权衡。
Markdown的优势
优势1:人类可读性最高
比如,你要告诉AI"检查代码中是否有SQL注入",用Markdown你可以这样写:
## Check for SQL Injection Vulnerabilities
When reviewing code, look for patterns like:
- Directly concatenating user input into SQL queries
- Missing parameterized queries
- Direct string interpolation in database commands
Example of vulnerable code:
```python
user_input = request.GET['username']
query = f"SELECT * FROM users WHERE name = '{user_input}'" # ❌ Vulnerable
Example of safe code:
user_input = request.GET['username']
cursor.execute("SELECT * FROM users WHERE name = ?", (user_input,)) # ✅ Safe
用JSON或YAML,你需要把这些内容转义成字符串,可读性大幅下降。
**优势2:版本控制友好**
Markdown文件在Git中的diff非常清晰。
```diff
- Check for hardcoded passwords
+ Check for hardcoded credentials
vs JSON中需要处理引号、转义等麻烦。
优势3:扩展灵活
Markdown本身很灵活,你可以加入:
- 标题和分级(# ## ###)
- 列表( - 或 1.)
- 代码块(```)
- 表格(| | |)
- 链接和引用等
这给了设计者足够的表达空间。
为什么不用其他格式
为什么不用代码(Python/JavaScript)?
因为这样就退化成IDE插件了。每个工具都需要不同的语言。
为什么不用JSON/YAML?
因为可读性差。YAML虽然比JSON好,但如果要写复杂的指令,嵌套层数会很深。
为什么不用XML?
亲,这是2024年。
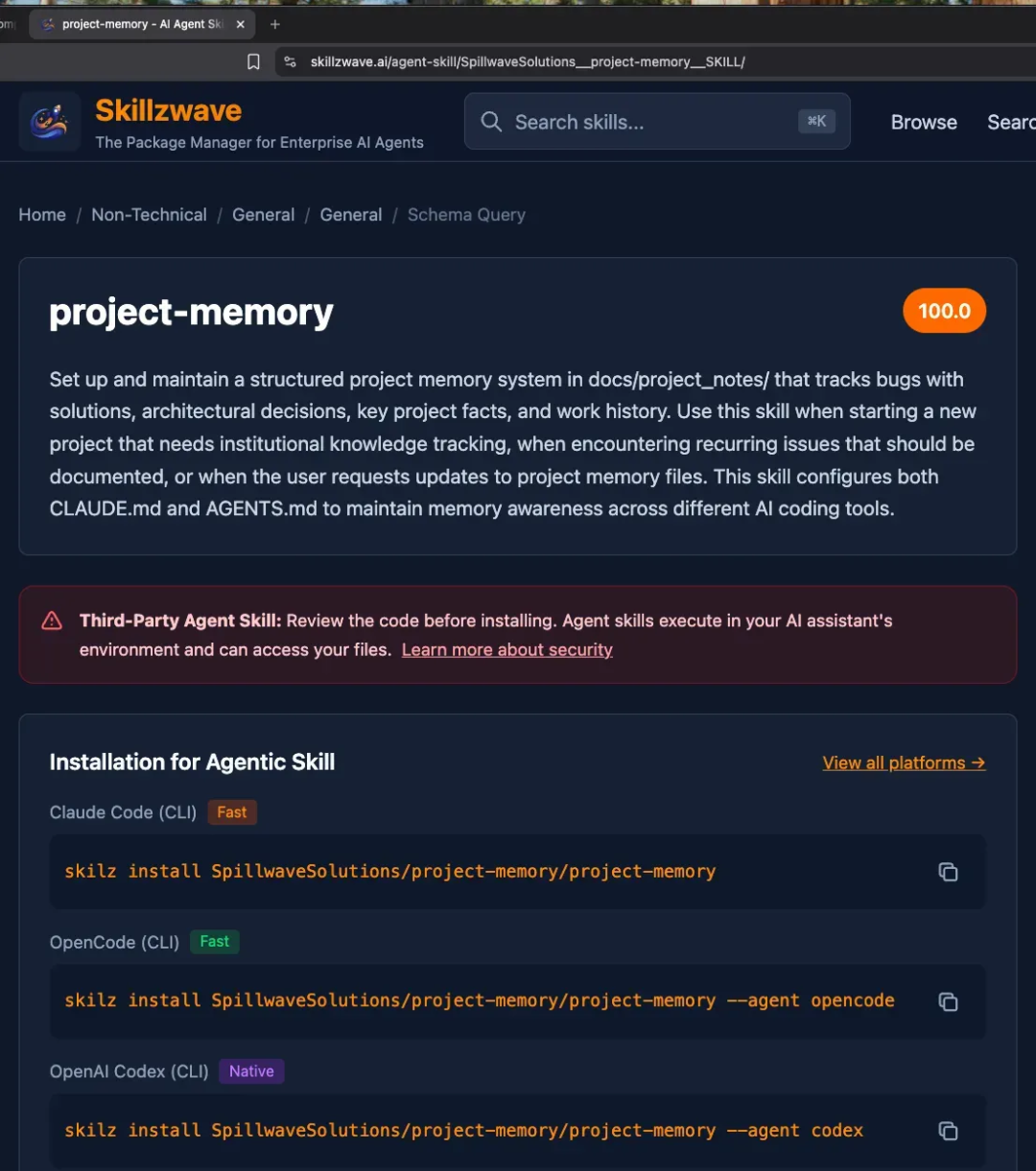
一个具体的例子:project-memory Skill
说了那么多理论,让我们看一个真实的例子。
项目记忆(project-memory)是SkillzWave上最受欢迎的Skill。它的核心思想很简单:
AI总是忘记项目的决策。我们能不能让AI记住?
问题的提出
你肯定经历过这个:
Week 1: "我们用D3.js做数据可视化吧"
├─ 花了2天评估
├─ 花了1天写POC
└─ 最终决定:用D3.js(因为团队有经验)
Week 3: 新需求来了,又需要图表
开发者:"Claude,帮我生成一个bar chart"
Claude:"好的,我用Chart.js给你写"
结果:
├─ 项目多了一个依赖(Chart.js)
├─ 代码风格不一致
├─ 之前的决策被无视了
└─ 周末加班重写 ❌
为什么会这样?
因为Claude没有"记忆"。每次新对话,它都是从0开始。你之前做过的决策、解决过的问题,都被它忘了。
project-memory Skill的解决方案
project-memory这个Skill说:我们创建一个文件夹结构来记录这些知识。
docs/project_notes/
├── decisions.md # 架构决策记录
├── bugs.md # Bug日志和解决方案
├── key_facts.md # 项目配置和常数
└── issues.md # 工作日志
然后,在SKILL.md里告诉Claude:
## Memory-Aware Protocols
**Before proposing architectural changes:**
- Check `docs/project_notes/decisions.md` for existing decisions
- Verify the proposed approach doesn't conflict with past choices
**When proposing UI libraries or tools:**
- Always check `decisions.md` first
- Follow documented choices to maintain consistency
现在,当你说"帮我生成bar chart"时,这个Skill会:
- 首先检查decisions.md
- 发现"ADR-001: Use D3.js for all charts"
- 用D3.js而不是Chart.js生成代码
- 自动保持了一致性
现在的流程:
开发者:"帮我生成bar chart"
↓
Claude激活 project-memory Skill
↓
自动检查 docs/project_notes/decisions.md
↓
发现:"我们决定用D3.js"
↓
用D3.js生成代码
↓
完全符合团队的技术栈 ✅
这就是Agent Skill的力量:**让AI不只是聪明,而是"有记忆"**。
这个Skill带来的收益
在一个100人的工程团队:
- 时间节省:不再重复讨论"应该用什么库"。每周节省约10小时
- 一致性提升:代码风格、技术选择、命名规范自动统一
- 知识沉淀:架构决策被记录,新人可以快速学习
- 信任建立:AI的建议有据可查,不是凭空想象
年度计算:
时间节省:10小时/周 × 50周 = 500小时
金钱价值:500小时 × 200元/小时 = 100,000元
这只是一个Skill。如果你用10个Skill...
为什么现在是学习Agent Skill的好时机
我想给你一些实用的建议。
窗口期很短
标准刚成形时,参与的门槛最低。
现在学习Agent Skill和创建自己的Skill,成本最低。6个月后,当这变成"标准技能"时,你已经是专家了。
知识资产的价值
你写的Skill,会在全球开发者的机器上运行。
这不只是代码复用,而是思想复用。
你把自己的经验编码成Skill,就能帮助世界各地的开发者。这种成就感,和写开源项目一样。
国内开发者的机遇
前面提到了,现在国内Skill的比例很低。
这意味着机会。
早期的贡献者,会获得社区的关注。在开源生态中,被看见的成本很低,回报却很高。
开始行动:你的第一个Agent Skill
如果你被说服了,想试试看,这里是最小化的开始步骤。
第一步:安装skilz CLI工具
pip install skilz
第二步:安装一个现存的Skill试试
skilz install https://github.com/SpillwaveSolutions/project-memory
第三步:在Claude Code中测试
说:"set up project memory for this project"
Claude应该会自动:
- 创建docs/project_notes文件夹
- 创建4个模板文件
- 配置CLAUDE.md让后续自动检查记忆文件
如果这个工作了,那你就体验到了Agent Skill的力量。
第四步:看看Skill的代码
打开SKILL.md,读一遍。
你会发现,一个有用的、被5000人使用的Skill,其实只是一个精心组织的Markdown文件。
第五步:想想你自己的问题
写下来:
- 我每周重复做的事情是什么?
- 我有什么团队规范需要自动化执行?
- 我的项目里有什么经验值得编成Skill?
选择其中最简单的一个,尝试写你自己的Skill。
不需要完美,不需要发布。就是试试看,这个过程会改变你看待"代码复用"的方式。
最后的话
Agent Skill Standard可能不会改变世界。
但它已经在改变一些程序员的工作方式。
我第一次看到project-memory这个Skill时,我的第一反应是:"这就是把自然语言当代码用。"
但用了两个月后,我意识到:这可能是比写代码更高级的工程思想。
因为它说的是:代码的目的是让电脑做事,但更高级的目的是让电脑理解你的意图。
Agent Skill就是在尝试做这件事。不是通过更复杂的API设计,而是通过更自然的语言指令。
这个方向是对的吗?
我不能100%确定。但看着这个生态快速成长,看着越来越多的高质量Skill出现,看着国际社区的积极参与……
我倾向于相信,这不仅仅是一场"标准化",而是开发工具思想的一次进化。
从"学会工具的API"进化到"告诉AI你想要什么"。
这个进化能否成功,取决于早期参与者(你?)是否真的相信并投入。
推荐阅读:
如果你对Agent Skill的技术细节感兴趣,下一篇文章我会深入讲解Agent Skill的架构设计和触发机制。敬请关注《前端达人》。
如果这篇文章对你有帮助,请:
- 👍 点赞,让算法知道这个内容对你有价值
- 💬 评论分享你对Agent Skill的看法(你是支持还是怀疑?为什么?)
- 🔁 分享给正在用Claude Code、Cursor或GitHub Copilot的朋友们
- ⭐ 关注《前端达人》,下周一我们讨论Agent Skill的实战应用
你对Agent Skill标准化的看法是什么?会不会成为下一个npm时刻?留言告诉我吧!
#AgentSkill
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号